Radix Sort
为了完成二维数据快速分类,最先使用的是hash分类。
前几天我突然想,既然基数排序的时间复杂度也不高,而且可能比hash分类更稳定,所以不妨试一下。
在实现上我依次实现:
1、一维数组基数排序
基本解决主要问题,涵盖排序,包含改进的存储分配策略。
如果用链表来实现,大量的函数调用将耗费太多时间。
2、二维数组基数排序
主要是实现和原有程序的集成。
一、数据结构
下面是存储节点的主数据结构。
typedef struct tagPageList{
int * PagePtr;
struct tagPageList * next;
}PageList;
typedef struct tagBucket{
int * currentPagePtr;
int offset;
PageList pl;
PageList * currentPageListItem;
}Bucket;
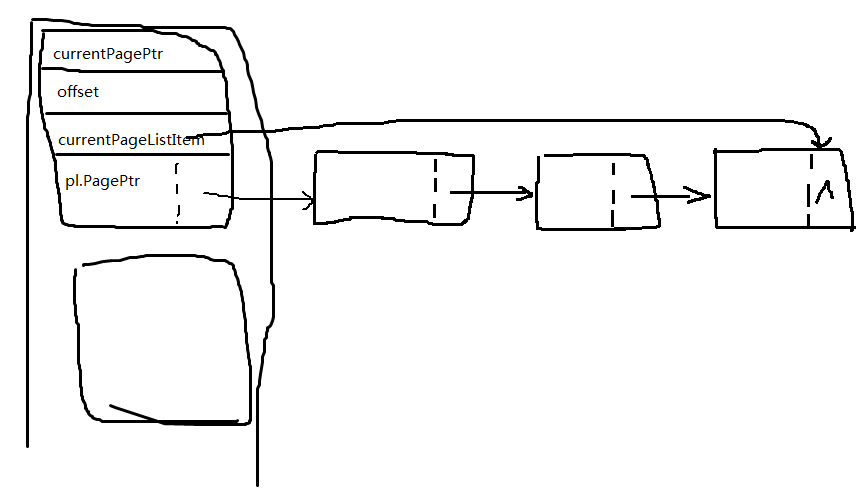
链表内是存储的一个4KB页面的指针。
每4KB页面可以存储最多1024个记录序号,如果是一维数组排序,那就直接存储数组元素了。
二、算法
基数排序可以分为MSD或者LSD。这里用的是LSD。
伪代码如下:
for i= to sizeof(sorted-element-type){
for each sorted-num{
cell = sorted-num
bucketIdx = (cell>>*i)&0xff
bucket[bucketIdx] = cell
}
combine linked list nodes to overwrite original array
}
C代码实现:
int main(){
HANDLE heap = NULL;
Bucket bucket[BUCKETSLOTCOUNT];
PageList * pageListPool;
int plpAvailable = ;
int * pages = NULL;
int * pagesAvailable = NULL;
int * objIdx;
unsigned short * s;
time_t timeBegin;
time_t timeEnd;
heap = HeapCreate(HEAP_NO_SERIALIZE|HEAP_GENERATE_EXCEPTIONS, *, );
if (heap != NULL){
pages = (int * )HeapAlloc(heap, , (TFSI/PAGEGRANULAR + BUCKETSLOTCOUNT + ) * );
pageListPool = (PageList *)HeapAlloc(heap, , (TFSI/PAGEGRANULAR + ) * sizeof(PageList));
s = (unsigned short *)HeapAlloc(heap, , TFSI*sizeof(unsigned short));
objIdx = (int *)HeapAlloc(heap, , TFSI * sizeof(int));
}
MakeSure(pages != NULL && pageListPool != NULL && objIdx != NULL);
for(int i=; i<TFSI; i++) objIdx[i]=i;
timeBegin = clock();
for (int i=; i<TFSI; i++) s[i] = rand();
timeEnd = clock();
printf("\n%f(s) consumed in generating numbers", (double)(timeEnd-timeBegin)/CLOCKS_PER_SEC);
timeBegin = clock();
for (int t=; t<sizeof(short); t++){
FillMemory(pages, (TFSI/PAGEGRANULAR + BUCKETSLOTCOUNT + ) * , 0xff);
SecureZeroMemory(pageListPool, (TFSI/PAGEGRANULAR + ) * sizeof(PageList));
pagesAvailable = pages;
plpAvailable = ;
for(int i=; i<; i++){
bucket[i].currentPagePtr = pagesAvailable;
bucket[i].offset = ;
bucket[i].pl.PagePtr = pagesAvailable;
bucket[i].pl.next = NULL;
pagesAvailable += PAGEGRANULAR;
bucket[i].currentPageListItem = &(bucket[i].pl);
}
int bucketIdx;
for (int i=; i<TFSI; i++){
bucketIdx = (s[objIdx[i]]>>t*)&0xff;
MakeSure(bucketIdx < );
//save(bucketIdx, objIdx[i]);
bucket[bucketIdx].currentPagePtr[ bucket[bucketIdx].offset ] = objIdx[i];
bucket[bucketIdx].offset++;
if (bucket[bucketIdx].offset == PAGEGRANULAR){
bucket[bucketIdx].currentPageListItem->next = &pageListPool[plpAvailable];
plpAvailable++;
MakeSure(plpAvailable < TFSI/PAGEGRANULAR + );
bucket[bucketIdx].currentPageListItem->next->PagePtr = pagesAvailable;
bucket[bucketIdx].currentPageListItem->next->next = NULL;
bucket[bucketIdx].currentPagePtr = pagesAvailable;
bucket[bucketIdx].offset = ;
pagesAvailable += PAGEGRANULAR;
MakeSure(pagesAvailable < pages+(TFSI/PAGEGRANULAR + BUCKETSLOTCOUNT + ) * );
bucket[bucketIdx].currentPageListItem = bucket[bucketIdx].currentPageListItem->next;
}
}
//update objIdx index
int start = ;
for (int i=; i<; i++){
PageList * p;
p = &(bucket[i].pl);
while (p){
for (int t=; t<PAGEGRANULAR; t++){
int idx = p->PagePtr[t];
if (idx != TERMINATOR){
objIdx[start] = idx;
start++;
}
if (idx == TERMINATOR) break;
}
p = p->next;
}
}
}
timeEnd = clock();
printf("\n%f(s) consumed in generating results", (double)(timeEnd-timeBegin)/CLOCKS_PER_SEC);
//for (int i=0; i<TFSI; i++) printf("%d\n", s[objIdx[i]]);
HeapFree(heap, , pages);
HeapFree(heap, , pageListPool);
HeapFree(heap, , s);
HeapFree(heap, , objIdx);
HeapDestroy(heap);
return ;
}
三、测试结果。
i7 3632QM @2.2GHz ==>TB 3.2GHz/ 8G RAM/ win8 64bit/VS2012 win32 release
1024*1024*100,1亿个随机生成 short 型数据。
1.438000(s) consumed in generating random numbers
4.563000(s) consumed in radix sort
12.719000(s) consumed in qsort
7.641000(s) consumed in std::sort
1024*1024*5 500万随机生成 short 型数据。
0.078000(s) consumed in generating random numbers
0.172000(s) consumed in radix sort
0.656000(s) consumed in qsort
0.390000(s) consumed in std::sort
1024*500
0.000000(s) consumed in generating random numbers
0.015000(s) consumed in radix sort
0.063000(s) consumed in qsort
0.047000(s) consumed in std::sort
四、讨论
二维数据分类上,性能相当于hash分类 约 1/3 。
比库例程稍快,慢的主要原因还是存储器,如果只是解决一维数组的话,调整下可以更快。
但对于二维数组多个线程同时操作,排序是不可接受的。
Radix Sort的更多相关文章
- 基数排序(radix sort)
#include<iostream> #include<ctime> #include <stdio.h> #include<cstring> #inc ...
- 经典排序算法 - 基数排序Radix sort
经典排序算法 - 基数排序Radix sort 原理类似桶排序,这里总是须要10个桶,多次使用 首先以个位数的值进行装桶,即个位数为1则放入1号桶,为9则放入9号桶,临时忽视十位数 比如 待排序数组[ ...
- [Algorithms] Radix Sort
Radix sort is another linear time sorting algorithm. It sorts (using another sorting subroutine) the ...
- 排序算法七:基数排序(Radix sort)
上一篇提到了计数排序,它在输入序列元素的取值范围较小时,表现不俗.但是,现实生活中不总是满足这个条件,比如最大整形数据可以达到231-1,这样就存在2个问题: 1)因为m的值很大,不再满足m=O(n) ...
- [MIT6.006] 7. Counting Sort, Radix Sort, Lower Bounds for Sorting 基数排序,基数排序,排序下界
在前6节课讲的排序方法(冒泡排序,归并排序,选择排序,插入排序,快速排序,堆排序,二分搜索树排序和AVL排序)都是属于对比模型(Comparison Model).对比模型的特点如下: 所有输入ite ...
- 基数排序(Radix Sort)
基数排序(Radix Sort) 第一趟:个位 收集: 第二趟:十位 第三趟:百位 3元组 基数排序--不是基于"比较"的排序算法 递增就是把收集的过程返过来 算法效率分析 需要r ...
- 【算法】基数排序(Radix Sort)(十)
基数排序(Radix Sort) 基数排序是按照低位先排序,然后收集:再按照高位排序,然后再收集:依次类推,直到最高位.有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序.最后的次序就 ...
- 学习算法-基数排序(radix sort)卡片分类(card sort) C++数组实现
基数排序称为卡片分类,这是一个比较早的时间越多,排名方法. 现代计算机出现之前,它已被用于排序老式打孔卡. 说下基数排序的思想.前面我有写一个桶式排序,基数排序的思想是桶式排序的推广. 桶式排序:ht ...
- [Algorithm] Radix Sort Algorithm
For example we have the array like this: [, , , , , ] First step is using Counting sort for last dig ...
随机推荐
- jquery 初步学习
首先 jQuery是一个轻量级的 JS框架,核心文件才几十KB 1. jquery 对象 var $variable=jquery对象 var variable = DOM对象 $variable[0 ...
- [2019BUAA软工]第一次团队作业
Team V1 团队启动 BUAA Team V1 于2019年3月正式成立,将开始为期四个月的合作. 队员介绍 Name Summary Sefie wxmwy V1-bug制造公司资深工程师精 ...
- js 获取非行间样式
1.getComputedStyle(nodeObj,false):该方法是BOM对象,第一个是要获取样式的节点对象:第二个可以写成任何的字符一般写成false或者null,这里最好是用false因为 ...
- SQL SERVER数据库 三种 恢复模式
SQL SERVER 2005 以后三种恢复模式: 简单(Sample),完全(Full),大批量(Bulk_Logged) 完全备份模型 完全备份模式是指在出现数据文件毁坏时丢失数据的风险最小.如果 ...
- OS---文件结构
1.概述 1.1 对于任何一个文件,都存在以下2种形式结构: 文件的逻辑结构: 从用户的角度出发所观察到的文件组织形式,独立于文件的物理特性: 文件的物理结构(文件存储结构): 文件在外存上的存储组织 ...
- Android官方架构组件介绍之应用(四)
讲一个项目常见的功能,友盟统计功能 例如一个项目有很多多modlue,每个里面modlue都有Activity,Activity需要友盟统一,Fragment也需要友盟统计.一般做法就是继承一个Bas ...
- java 开发体系参考学习
https://www.oschina.net/question/2663968_2283797
- 那些经历过的Bug Unity的Invoke方法
有一个游戏对象,上面挂着 3 个脚本,如下: using System.Collections; using System.Collections.Generic; using UnityEngine ...
- (转)Memcached用法--参数和命令详解
Memcached用法--参数和命令详解 1. memcached 参数说明: # memcached -h 1.1 memcached 的参数 常用参数 -p <num> 监听的TCP端 ...
- Jquery load()加载GB2312页面时出现乱码的解决方法
问题描述:jquery的字符集是utf-8,load方法加载完GB2312编码静态页面后,出现中文乱码. a.php <script language="javascript" ...