Hadoop 2.0完全分布式集群搭建方法(CentOS7+Hadoop 2.7.7)
本文详细介绍搭建4个节点的完全分布式Hadoop集群的方法,Linux系统版本是CentOS 7,Hadoop版本是2.7.7,JDK版本是1.8。
一、准备环境
1. 在VMware workstations上创建4个Linux虚拟机,并配置其静态IP。
有关【创建Linux虚拟机及配置网络】,请参考这里。
2. 配置DNS(每个节点)
编辑配置文件,添加主节点和从节点的映射关系。
#vim /etc/hosts
192.168.44.3 hadoop01
192.168.44.4 hadoop02
192.168.44.5 hadoop03
192.168.44.6 hadoop04
3. 关闭防火墙(每个节点)
#关闭服务
[root@hadoop01 opt]# systemctl stop firewalld
#关闭开机自启动
[root@hadoop01 opt]# systemctl disable firewalld
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
4. 配置免密码登录
有关【配置免密码登录方法】,请参考这里。
5. 配置Java环境(每个节点)
有关【配置java环境方法】,请参考这里。
二、搭建Hadoop完全分布式集群
在各个节点上安装与配置Hadoop的过程都基本相同,因此可以在每个节点上安装好Hadoop后,在主节点master上进行统一配置,然后通过scp 命令将修改的配置文件拷贝到各个从节点上即可。
1. 下载Hadoop安装包,解压,配置Hadoop环境变量
有关【Hadoop安装包下载方法】,请参考这里。
本文下载的Hadoop版本是2.7.7,指定一个目录(比如:/opt),使用rz命令上传Hadoop安装包到Linux系统,解压到指定目录,配置Hadoop环境变量,并使其生效。实现命令如下:
#解压到/opt目录
[root@hadoop01 opt]# tar -zxvf hadoop-2.7.7.tar.gz
#链接/opt/hadoop-2.7.7到/opt/hadoop,方便后续配置
[root@hadoop01 opt] #ln -s hadoop-2.7.7 hadoop
#配置Hadoop环境变量
[root@hadoop02 opt]# vim /etc/profile
#Hadoop
export HADOOP_HOME=/opt/hadoop # 该目录为解压安装目录
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop #保存后,使profile生效
[root@hadoop02 opt]# source /etc/profile
2. 配置Hadoop环境脚本文件中的JAVA_HOME参数
#进入Hadoop安装目录下的etc/hadoop目录
[root@hadoop01 ~]#cd /opt/hadoop/etc/hadoop #分别在hadoop-env.sh、mapred-env.sh、yarn-env.sh文件中添加或修改如下参数:
[root@hadoop01 hadoop]# vim hadoop-env.sh
[root@hadoop01 hadoop]# vim mapred-env.sh
[root@hadoop01 hadoop]# vim yarn-env.sh
export JAVA_HOME="/opt/jdk" # 路径为jdk安装路径
3. 修改Hadoop配置文件
Hadoop安装目录下的etc/hadoop目录中,需修改core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、slaves(3.0之后为workers)文件,根据实际情况修改配置信息。
(1)core-site.xml
<configuration>
<property>
<!-- 配置hdfs地址 -->
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<!-- 保存临时文件目录,需先在/opt/hadoop-2.7.7下创建tmp目录 -->
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.7/tmp</value>
</property> <property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
更多配置信息,请参考core-site.xml。
(2)hdfs-site.xml
<configuration>
<property>
<!-- 主节点地址 -->
<name>dfs.namenode.http-address</name>
<value>hadoop01:</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/dfs/data</value>
</property>
<property>
<!-- 备份份数 -->
<name>dfs.replication</name>
<value></value>
</property>
<property>
<!-- 第二节点地址 -->
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>配置为false后,可以允许不要检查权限就生成dfs上的文件,需防止误删操作</description>
</property>
</configuration>
更多配置信息,请参考hdfs-site.xml。
(3)mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:</value>
</property>
</configuration>
更多配置信息,请参考mapred-site.xml。
(4)yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop01:</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop01:</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop01:</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop01:</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop01:</value>
</property> <property>
<name>yarn.nodemanager.resource.memory-mb</name>
<!-- NodeManager中的配置,这里配置过小可能导致nodemanager启动不起来
大小应该大于 spark中 executor-memory + driver的内存 -->
<value></value>
</property>
<property>
<!-- RsourceManager中配置
大小应该大于 spark中 executor-memory + driver的内存 -->
<name>yarn.scheduler.maximum-allocation-mb</name>
<value></value>
</property>
<property>
<!-- 使用核数 -->
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value></value>
</property> <property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value></value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>忽略虚拟内存的检查,如果你是安装在虚拟机上,这个配置很有用,配上去之后后续操作不易出问题。</description>
</property>
<property>
<!-- 调度策略,设置为公平调度器 -->
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
</configuration>
更多配置信息,请参考yarn-site.xml。
(5)slaves文件
#增加从节点地址(若配置了hosts,可直接使用主机名,亦可用IP地址)
[root@hadoop01 hadoop]# vim slaves
hadoop02
hadoop03
hadoop04
4. 将配置好的文件夹拷贝到其他从节点
[root@hadoop01 hadoop-2.7.]# scp -r /opt/hadoop-2.7. root@hadoop02:/opt/
[root@hadoop01 hadoop-2.7.7]# scp -r /opt/hadoop-2.7.7 root@hadoop03:/opt/
[root@hadoop01 hadoop-2.7.7]# scp -r /opt/hadoop-2.7.7 root@hadoop04:/opt/
5. 初始化 & 启动
#格式化
[root@hadoop01 hadoop-2.7.]# bin/hdfs namenode -format #启动
[root@hadoop01 hadoop-2.7.]# sbin/start-dfs.sh
[root@hadoop01 hadoop-2.7.]# sbin/start-yarn.sh
6. 验证Hadoop启动成功
#主节点
[root@hadoop01 hadoop-2.7.]# jps
Jps
ResourceManager
NameNode #从节点
[root@hadoop02 hadoop]# jps
SecondaryNameNode
DataNode
NodeManager
Jps [root@hadoop03 opt]# jps
DataNode
NodeManager
Jps [root@hadoop04 opt]# jps
NodeManager
Jps
DataNode
7. Hadoop Web端口访问
注:先开放端口或直接关闭防火墙
# 查看防火墙状态
firewall-cmd --state
# 临时关闭
systemctl stop firewalld
# 禁止开机启动
systemctl disable firewalld
在浏览器输入:http://hadoop01:8088,打开Hadoop Web管理页面。
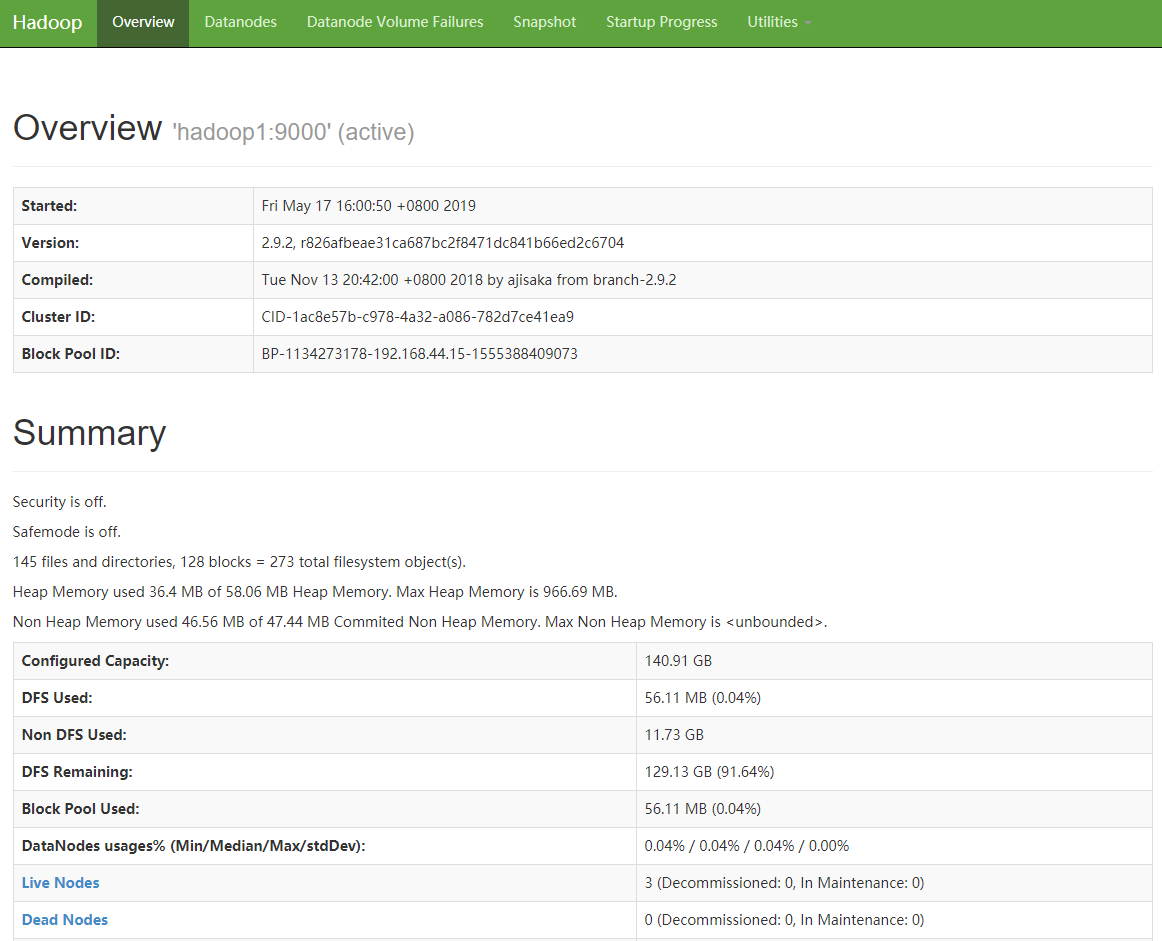
在浏览器输入:http://hadoop01:50070打开Hadoop Web页面。
注意:如果输入主节点名称无法打开Web页面,则需要配置Windows上的hosts,路径如下:
C:\Windows\System32\drivers\etc\hosts
192.168.44.5 hadooop01
192.168.44.6 hadooop02
192.168.44.7 hadooop03
192.168.44.8 hadooop04
Hadoop 2.0完全分布式集群搭建方法(CentOS7+Hadoop 2.7.7)的更多相关文章
- Hadoop 3.0完全分布式集群搭建方法(CentOS 7+Hadoop 3.2.0)
本文详细介绍搭建4个节点的完全分布式Hadoop集群的方法,Linux系统版本是CentOS 7,Hadoop版本是3.2.0,JDK版本是1.8. 一.准备环境 1. 在VMware worksta ...
- Hadoop上路-01_Hadoop2.3.0的分布式集群搭建
一.配置虚拟机软件 下载地址:https://www.virtualbox.org/wiki/downloads 1.虚拟机软件设定 1)进入全集设定 2)常规设定 2.Linux安装配置 1)名称类 ...
- 分布式实时日志系统(四) 环境搭建之centos 6.4下hbase 1.0.1 分布式集群搭建
一.hbase简介 HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为 Java.它是Apache软件基金会的Hadoop项目的一部分,运行 ...
- Hadoop2.7.3+Spark2.1.0完全分布式集群搭建过程
1.选取三台服务器(CentOS系统64位) 114.55.246.88 主节点 114.55.246.77 从节点 114.55.246.93 从节点 之后的操作如果是用普通用户操作的话也必须知道r ...
- Hadoop 2.2 YARN分布式集群搭建配置流程
搭建环境准备:JDK1.6,SSH免密码通信 系统:CentOS 6.3 集群配置:NameNode和ResourceManager在一台服务器上,三个数据节点 搭建用户:YARN Hadoop2.2 ...
- hadoop 3.x 完全分布式集群搭建/异常处理/测试
共计三台虚拟机分别为hadoop002(master,存放namenode),hadoop003(workers,datanode以及resourcemanage),hadoop004(workers ...
- hbase分布式集群搭建
hbase和hadoop一样也分为单机版.伪分布式版和完全分布式集群版本,这篇文件介绍如何搭建完全分布式集群环境搭建. hbase依赖于hadoop环境,搭建habase之前首先需要搭建好hadoop ...
- hbase完整分布式集群搭建
简介: hadoop的单机,伪分布式,分布式安装 hadoop2.8 集群 1 (伪分布式搭建 hadoop2.8 ha 集群搭建 hbase完整分布式集群搭建 hadoop完整集群遇到问题汇总 Hb ...
- kafka系列二:多节点分布式集群搭建
上一篇分享了单节点伪分布式集群搭建方法,本篇来分享一下多节点分布式集群搭建方法.多节点分布式集群结构如下图所示: 为了方便查阅,本篇将和上一篇一样从零开始一步一步进行集群搭建. 一.安装Jdk 具体安 ...
随机推荐
- python-Django收集主机信息
1.创建工程simplecmdb django-admin.py startproject simplecmdb 2.创建应用 cd simplecmdb python manage.py start ...
- PostgreSQL正则及模糊查询优化
1.带前缀的模糊查询 ~'^abc' 可以使用btree索引优化 create index idx_info on table_name(info) 2.带后缀的模糊查询 ~'abc$' 可以使用 ...
- 使用 py2exe 打包 Python 程序
上回在<使用 PyInstaller 打包 Python 程序>中,我们介绍了使用 PyInstaller 对 Python 程序进行打包,今天带大家认识一个新的工具:py2exe. 接下 ...
- ACM学习历程—HDU4969 Just a Joke(物理题)
Just a Joke Description Here is just a joke, and do not take it too seriously. Guizeyanhua is the pr ...
- chrome中的content script脚本文件
打开chrome的devtools工具,sources下有一个Content script: 1 chrome插件开发过程中难免会遇到使用content script来操作页面的dom,在chrome ...
- 【转】 Pro Android学习笔记(三五):Menu(6):XML方式 & PopUp菜单
目录(?)[-] 利用XML创建菜单 XML的有关属性 onClick事件 Pop-up菜单 利用XML创建菜单 在代码中对每个菜单项进行设置,繁琐且修改不灵活,不能适配多国语言的要求,可以利用资源进 ...
- 二、java 与 scala相互调用
介绍:scala 是简化的java,运行于jvm的脚步语言.Java和scala通过各自编译器编译过都是jvm能解析class文件.本文介绍java和scala如何互调 scala的源代码文件是以. ...
- 杂项-权限管理:RBAC
ylbtech-杂项-权限管理:RBAC 基于角色的权限访问控制(Role-Based Access Control)作为传统访问控制(自主访问,强制访问)的有前景的代替受到广泛的关注.在RBAC中, ...
- javaScript之this的五种情况
this一直是JavaScript研究的难题,特别是在笔试和面试中的各种程序分析问题中,也常常会被问到.下面来看一看this被运用的五中情况: (1) 纯粹的函数调用 函数最普通用法,此时 ...
- SpringMVC 学习笔记(文件的上传和下载)
在web项目中会遇到的问题:文件上传 文件上传在前端页面的设置:form表单 设置 input 类型 文件上传的请求方式要使用post,要将enctype设置为multipart/form-data ...