手把手教你如何新建scrapy爬虫框架的第一个项目(下)
前几天小编带大家学会了如何在Scrapy框架下创建属于自己的第一个爬虫项目(上),今天我们进一步深入的了解Scrapy爬虫项目创建,这里以伯乐在线网站的所有文章页为例进行说明。
在我们创建好Scrapy爬虫项目之后,会得到上图中的提示,大意是让我们直接根据模板进行创建Scrapy项目。根据提示,我们首先运行“cd article”命令,意思是打开或者进入到article文件夹下,尔后执行命令“scrapy genspider jobbole blog.jobbole.com”,代表通过Scrapy中自带的basic模板进行创建Scrapy项目,如下图所示。
根据提示,该模板创建的位置为article.spiders.jobbole,此时再次输入tree /f命令可以查看到除了之前创建Scrapy爬虫项目的基础文件之外,在spiders文件夹下确实是多了一个jobbole.py文件,如下图所示。
当然了,爬虫模板不一定非得用Scrapy爬虫项目自带的模板,也可以自定义的进行创建,但是基本上Scrapy提供的模板是足够使用的了。
接下来,将整个爬虫项目导入到Pycharm中去,点击左上方“file”à“open”,找到爬虫项目创建的文件夹,点击确认即可。
如果在Pycharm中的spiders文件夹下看不到jobbole.py这个文件的话,则先选中spiders文件夹,尔后右键,点击“Synchronize spider”,代表与spiders文件夹进行同步的意思,尔后便可以看到jobbole.py就会被加载出来。
点击jobbole.py文件进行查看内容,如下图所示。可以看到该文件已经默认的填充了部分Python代码,其实是从源模板中进行复制创建的。
可以看到该文件中有当前Scrapy爬虫项目的名字name,Scrapy爬虫项目所允许的域名范围allowed_domains,以及Scrapy爬虫项目的起始URL,即start_urls。
接下来最后检查一下该项目的Python解释器,点击Pycharm的setting,然后输入“interpreter”,找到解释器所在的位置,如下图所示。
如果“Project Interpreter”显示出来的解释器不是当前项目下的虚拟环境,则点击“Project Interpreter”的右侧的设置按钮,如下图所示。
然后点击“Add local”,如下图所示。
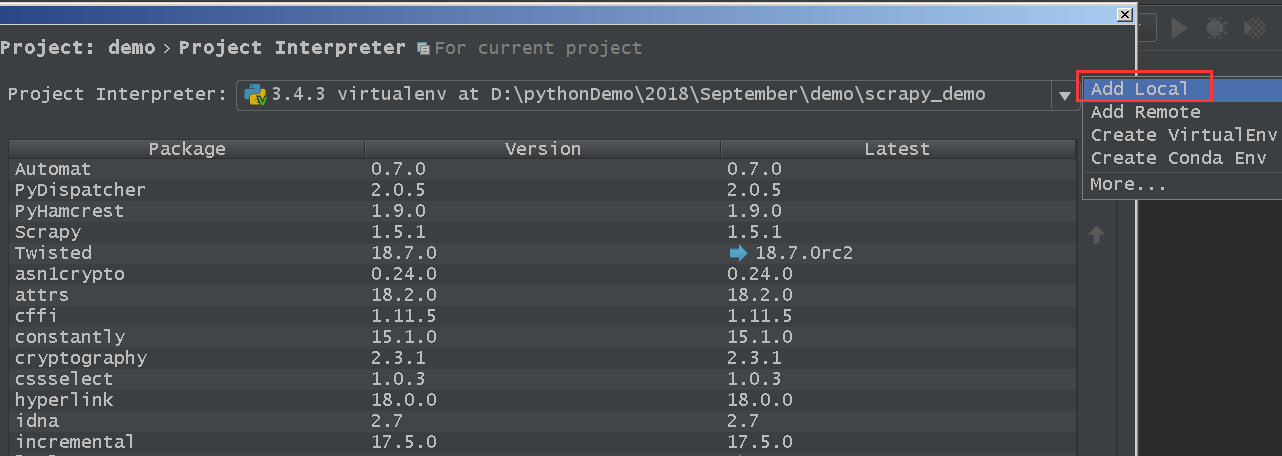

找到该项目对应的虚拟环境Python解释器,进行添加即可,如下图所示。
至此,Scrapy爬虫虚拟环境创建、Scrapy爬虫项目的创建以及Scrapy爬虫项目导入到Pycharm中以及解释器的配置已经完成,接下来我们要开始写入爬虫逻辑,以及数据提取等,敬请期待~~
对爬虫感兴趣的小伙伴,欢迎来Github:https://github.com/cassieeric,喜欢的话记得给个star噢~~
手把手教你如何新建scrapy爬虫框架的第一个项目(下)的更多相关文章
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
- 手把手教大家如何用scrapy爬虫框架爬取王者荣耀官网英雄资料
之前被两个关系很好的朋友拉入了王者荣耀的大坑,奈何技术太差,就想着做一个英雄的随查手册,这样就可以边打边查了.菜归菜,至少得说明咱打王者的态度是没得说的,对吧?大神不喜勿喷!!!感谢!!废话不多说,开 ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- 手把手教你写电商爬虫-第三课 实战尚妆网AJAX请求处理和内容提取
版权声明:本文为博主原创文章,未经博主允许不得转载. 系列教程: 手把手教你写电商爬虫-第一课 找个软柿子捏捏 手把手教你写电商爬虫-第二课 实战尚妆网分页商品采集爬虫 看完两篇,相信大家已经从开始的 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- scrapy爬虫框架学习笔记(一)
scrapy爬虫框架学习笔记(一) 1.安装scrapy pip install scrapy 2.新建工程: (1)打开命令行模式 (2)进入要新建工程的目录 (3)运行命令: scrapy sta ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- 手把手教你写电商爬虫-第四课 淘宝网商品爬虫自动JS渲染
版权声明:本文为博主原创文章,未经博主允许不得转载. 系列教程: 手把手教你写电商爬虫-第一课 找个软柿子捏捏 手把手教你写电商爬虫-第二课 实战尚妆网分页商品采集爬虫 手把手教你写电商爬虫-第三课 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
随机推荐
- ssh: connect to host port 22: Connection refused
配置Linux的互信,互信完成后,连接需要+端口才可以已经将端口修改为7777,但依旧走的是默认的22端口修改方式:[root@yoon ssh]# vi /etc/servicesssh ...
- mac pro 安装 composer 失败
http://getcomposer.org/doc/00-intro.md#using-composer $ brew install josegonzalez/php/composer 出现错误: ...
- protocol 和delegate(协议和代理)的区别
定义 protocol:中文叫协议,一个只有方法体(没有具体实现)的类,Java中称作接口,实现协议的类必须实现协议中@required标记的方法(如果有的话): delegate:中文叫代理或委托, ...
- make 编译 linux 内核是单线程的任务 才用-j4命令使用4 线程加速
今天使用 make 编译 linux 内核,发现CPU只用了30%多一点,而我的电脑是4核的,所以如果没有意外的话,make 编译 linux 内核的任务是用单线程做的. 又了解到,使用-j4参数可以 ...
- js 数组 : 差集、并集、交集、去重
//input:[{name:'liujinyu'},{name:'noah'}] //output:['liujinyu','noah'] Array.prototype.choose = func ...
- Spring的ApplicationContextAware接口的作用
ApplicationContextAware接口: 当一个类实现了这个接口之后,这个类就可以方便地获得 ApplicationContext 中的所有bean.换句话说,就是这个类可以直接获取Spr ...
- 异构关系数据库(Sqlserver与MySql)之间的数据类型转换参考
一.SqlServer到MySql的数据类型的转变 编号 SqlServer ToMySql MySql 1 binary(50) LONGBLOB binary 2 bit CHAR(1) bit ...
- ubuntu设置PATH
试了好多遍,多无效.. 最后在/etc/enviroment下设置才有效. 不过让有一些未解问题 我使用sudo su 进入到root用户权限,设置完成的. 重新使用sudo -s进入root用户权限 ...
- (转)redis源代码分析 – event library
每个cs程序尤其是高并发的网络服务端程序都有自己的网络异步事件处理库,redis不例外. 事件库仅仅包括ae.c.ae.h,还有3个不同的多路复用(本文仅描述epoll)的wrapper文件,事件库封 ...
- ASP.NET-Router配置中MapRoute的参数
App_Start文件夹中的RouteConfig MapRoute(string name,string url); MapRoute(string name,string url,object d ...