C# NetCore使用AngleSharp爬取周公解梦数据
这一章详细讲解编码过程
那么接下来就是码代码了,GO
新建NetCore WebApi项目 空的就可以
NuGet安装
Install-Package AngleSharp
或者界面安装

using。。
默认本地装有mysql或者有远程开放的mysql数据库,如何安装mysql,园区有很多文章都详细说明。
配置文件添加mysql连接 appsettings.json
{
"Logging": {
"LogLevel": {
"Default": "Warning"
}
},
"AllowedHosts": "*",
"ConnectionStrings": {
"MySql": "server=localhost;user id=root;pwd=root;database=dreaminfo;"
}
}
新建实体类,这里由于比较简单,所以创建到一起,实际工作中最好不要这样,可读性较差
using System;
using System.Collections.Generic;
using System.ComponentModel.DataAnnotations;
using System.ComponentModel.DataAnnotations.Schema;
using System.Linq;
using System.Threading.Tasks; namespace WebAPI.Models
{
public class Dream
{
[Key, DatabaseGenerated(DatabaseGeneratedOption.Identity)]
public int Id { get; set; }
public string Name { get; set; }
public string Url { get; set; }
public string Summary { get; set; }
public string CateName { get; set; }
public DateTime? CreateTime { get; set; }
}
public class DreamInfo
{
[Key, DatabaseGenerated(DatabaseGeneratedOption.Identity)]
public int Id { get; set; }
public int FkDreamId { get; set; }
public string DreamName { get; set; }
public string Name { get; set; }
public string Content { get; set; }
public DateTime? CreateTime { get; set; }
}
}
安装,mysql的ef支持
Install-Package Pomelo.EntityFrameworkCore.MySql
创建DBContext
using Microsoft.EntityFrameworkCore;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks; namespace WebAPI.Models
{
public class MainDBContext : DbContext
{
public MainDBContext(DbContextOptions<MainDBContext> options) : base(options)
{ }
private string connection;
public MainDBContext(string connection) => this.connection = connection;
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
if (!string.IsNullOrWhiteSpace(connection))
optionsBuilder.UseMySql(connection);
}
public DbSet<Dream> Dream { get; set; }
public DbSet<DreamInfo> DreamInfo { get; set; }
}
}
配置服务
public void ConfigureServices(IServiceCollection services)
{
var mysqlCon = Configuration.GetSection("ConnectionStrings:MySql").Value;
services.AddDbContext<MainDBContext>(l => l.UseMySql(mysqlCon, b => b.MigrationsAssembly("Dream"))); //跳转查看
services.AddMvc().SetCompatibilityVersion(CompatibilityVersion.Version_2_1);
}
然后是数据库迁移 ,这里使用的是codefirst,所以创建好实体类之后在实体类及EF存在的程序集执行Add-Migration命令,我这里做的比较简单,有的如果是按照框架来设计,可能实体类被设计在单独的类库里
这里是直接在webapi里面
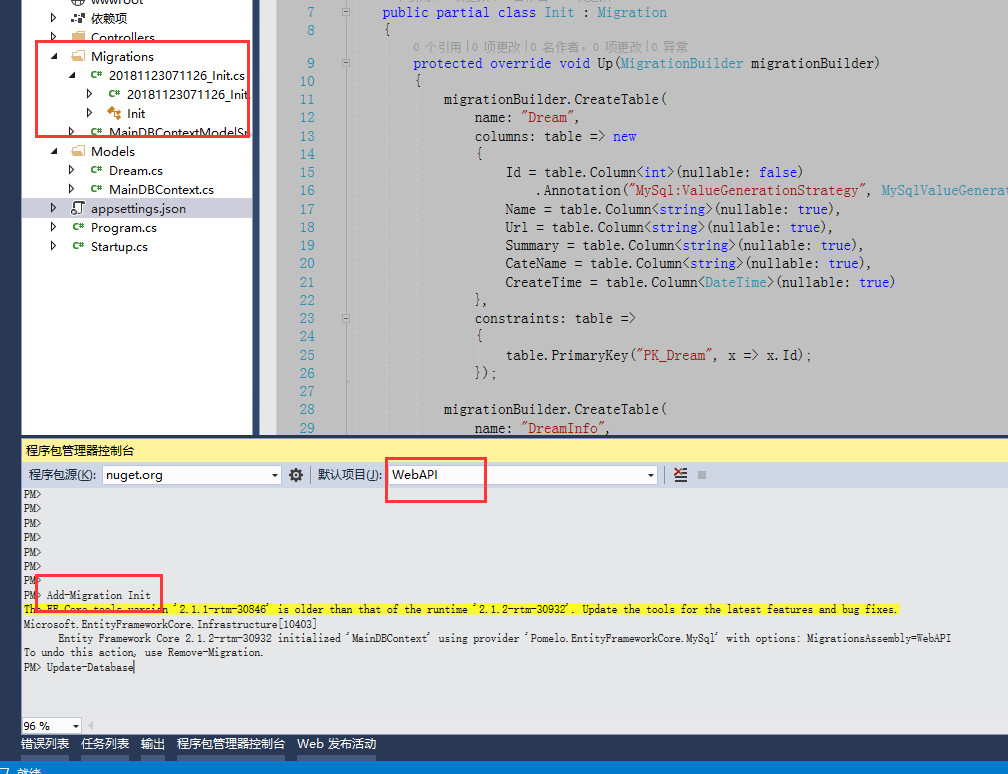
执行之后会多出来迁移的的文件,然后执行Update-Database就可以生成数据库拉。
后期如果数据库有变更还是同样的操作
工具》打开Nuget包管理器》程序包管理控制台 选中EF所在类库
Add-Migration Update-
//然后等待变更文件生成之后执行
Update-Database
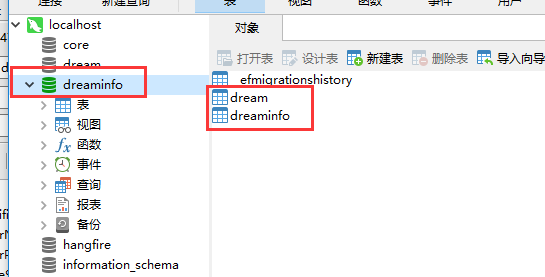
然后我们看下数据库

我们刷新下,数据库和对应的表都有了。
获取页面内容
新建一个空的API控制器DreamController
然后创建获取类别数据的方法
/// <summary>
/// 定义一个获取列表数据的方法,需要传递一个列表页面的url地址
/// </summary>
/// <param name="rul"></param>
public void GetData(string url)
{
//这个跟我之前使用的浏览器驱动类似,也是通过选择器和xpath来爬取数据
//区别在于那个是模拟真人操作,这个是通过通过HttpWebRequest直接请求
var html = GetHtml(url);
//创建一个(可重用)解析器前端
var parser = new HtmlParser();
var document = parser.Parse(html);
//找到一个页面有多少个dream信息
var mengList = document.QuerySelectorAll("#list > div.main > div.l-item > ul > li");
//循环获取梦的信息
for (var i = ; i < mengList.Length; i++)
{
var meng = new Dream();
meng.CateName = "人物";
//名称
meng.Name = mengList[i].QuerySelector("h3 > a").TextContent;
//简介
meng.Summary = mengList[i].QuerySelector("p").TextContent;
//连接
meng.Url = mengList[i].QuerySelector("h3 > a").GetAttribute("href");
meng.CreateTime = DateTime.Now;
_context.Dream.Add(meng);
_context.SaveChanges();//可以单个保存,也可以获取当前页数据之后保存一次,可优化的点有很多,这里不再详细描述
}
}
但是这里获取的都是单页的数据,我们继续上一章说的,使用选择器里面的.next来寻找翻页按钮附带的连接

然后看看最后一页是什么样式
发现最后一页就没有下一页样式了,就获取不到值了,好的 那么我们开始翻页
至于翻页 还有第二种思路,就是直接获取这种类别下的最后一页的页码,然后循环就行了,似乎比较简单,我们就用这一种
完善后的方法
/// <summary>
/// 定义一个获取列表数据的方法,需要传递一个列表页面的url地址
/// </summary>
/// <param name="rul"></param>
public void GetData(string url, int pageIndex)
{
var thisUrl = url + pageIndex + ".html";
var html = GetHtml(thisUrl);
//创建一个(可重用)解析器前端
var parser = new HtmlParser();
var document = parser.Parse(html);
var mengList = document.QuerySelectorAll("#list > div.main > div.l-item > ul > li");
//#list > div.main > div.pagelist > a.end
//获取最末页数据
if (!PageEnd.HasValue)
{
var pageEnd = document.QuerySelector("#list > div.main > div.pagelist > a.end")?.TextContent;
PageEnd = Convert.ToInt32(pageEnd);
}
var list = new List<Dream>();
for (var i = ; i < mengList.Length; i++)
{
var meng = new Dream();
meng.CateName = "其他";
//名称
meng.Name = mengList[i].QuerySelector("h3 > a").TextContent;
//简介
meng.Summary = mengList[i].QuerySelector("p").TextContent;
//连接
meng.Url = mengList[i].QuerySelector("h3 > a").GetAttribute("href");
meng.CreateTime = DateTime.Now;
_context.Dream.Add(meng);
_context.SaveChanges();
}
//翻页记录页码
pageIndex++;
if (pageIndex <= Convert.ToInt32(PageEnd))
{
Console.WriteLine(pageIndex + "/" + PageEnd);
//翻页完之前一直抓取
GetData(url, pageIndex);
}
}
定义接口,输出一下看看获取了多少页的数据
PageEnd是在控制器里面定义的
public class DreamController : ControllerBase
{
static int? PageEnd = null;
//other code
[HttpGet]
public async Task<IActionResult> GetMengXinfo()
{
GetData("http://www.xzw.com/jiemeng/lib/renwu/", );
return Ok(PageEnd);
}
调试走一波
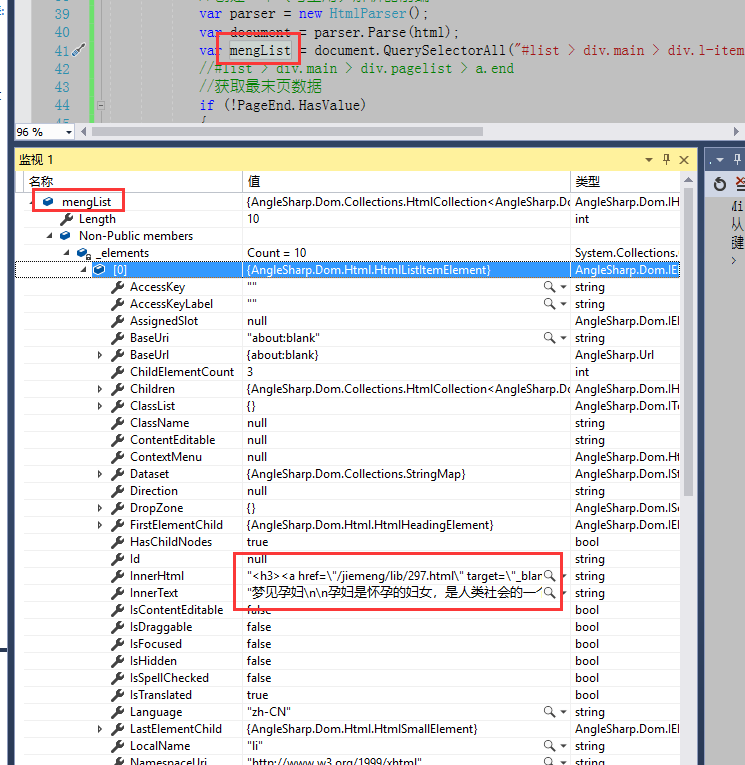
可以看到这里数据其实已经拿到了,那我们就开始往数据库保存
由于是演示,我们找一个数据量较少的分类来获取 使用“其他”分类获取,调用接口,看到返回值是45
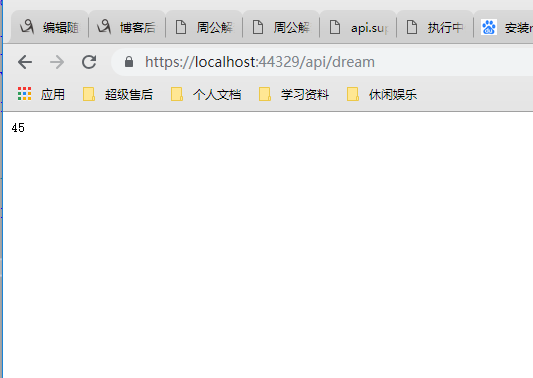
这个跟我们找到对应的数据是一样的

说明数据是ok的,我们看下数据库,dream表已经有数据了
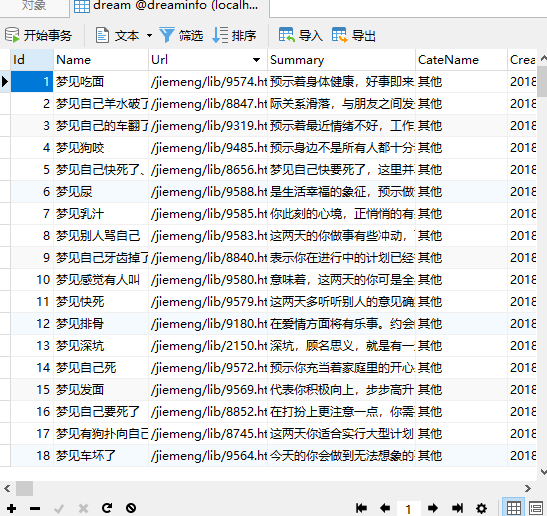
到这里 分类数据就获取到了,其他几个分类 可以使用一个数组,循环数组拼连接获取,也可以放到后台任务慢慢执行,比如Hangfire
详细信息获取
详细信息的页面我们其实是有的,就是dream表里面的url字段,拼接上domain之后就成了详细页面的连接,我们又可以使用AngleSharp来获取数据拉。。
其实AngleSharp是对获取到的文档进行解析,里面构建了很多C#和js习惯的语法,比如
document.QuerySelector(选择器)//选择器查询单个符合条件的数据
document.QuerySelectorAll("#list > div.main > div.l-item > ul > li");获取复合条件的元素集合
获取详情页面内容,并给实体对象赋值,这里有很多可以试探的方法,大家可以尝试一下,我这个只是简单的为了完成我想要的功能。
/// <summary>
/// 获取详情页的页面解析
/// </summary>
/// <param name="dreamId"></param>
/// <param name="url"></param>
public void GetDetailData(int dreamId, string url)
{
var html = GetHtml(url);
var parser = new HtmlParser();
var document = parser.Parse(html);
//#wraper > div.main-wrap > div.pleft.fl > div.viewbox.box > div.sbody
var sbody = document.QuerySelector("#wraper > div.main-wrap > div.pleft.fl > div.viewbox.box > div.sbody");
var dllist = sbody.QuerySelectorAll("dl");
var title = sbody.QuerySelector("h2").TextContent;//标题
if (dllist.Length > )
{
foreach (var detail in dllist)
{
//#wraper > div.main-wrap > div.pleft.fl > div.viewbox.box > div.sbody > dl:nth-child(4) > dt > strong
var info = new DreamInfo();
info.FkDreamId = dreamId;
info.DreamName = title;
info.Name = detail.QuerySelector("dt > strong").TextContent;
info.Content = detail.QuerySelector("dd").TextContent; ;
info.CreateTime = DateTime.Now;
_context.DreamInfo.Add(info);
_context.SaveChanges();
} }
}
定义接口
[Route("detail")]
[HttpGet]
public async Task<IActionResult> GetDreamInfo()
{
var domain = "http://www.xzw.com";
//查询出其他分类的梦数据来解析详细内容
var dreamList = _context.Dream.Where(l => l.CateName == "其他").ToList();
foreach (var dream in dreamList)
{
GetDetailData(dream.Id, domain + dream.Url);
}
return Ok(PageEnd);
}
执行接口https://localhost:44329/api/dream/detail
这里不展示调试信息了,怕被说水内容
然后看数据库dreaminfo也有了数据
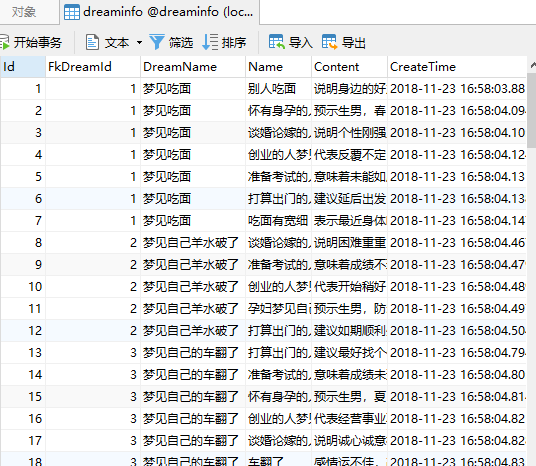
找到对应页面
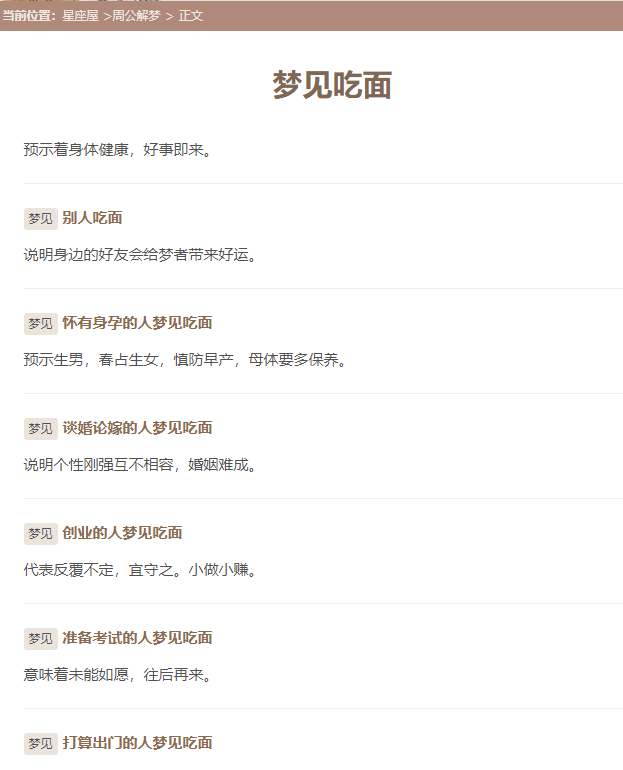
到这里,数据基本都可以获取到了,其他分类可以做计划任务来获取数据
总结
对自己感兴趣的东西,可能下决心投入的时间会更长一点,共勉。
排版较乱可能影响阅读,不过内容还是能看到的。。
GitHub:https://github.com/ermpark/dream.git
C# NetCore使用AngleSharp爬取周公解梦数据的更多相关文章
- C# NetCore使用AngleSharp爬取周公解梦数据 起因和页面数据拆解
起因 最近突然心血来潮想做个小程序,学习一下小程序开发流程,然后新手就想做个查询的就可以了,少点交互能力,这种思来想去还是周公解梦比较靠谱, 网上一搜,还真有小程序源码,但是这里面似乎数据都是取第三方 ...
- bert+seq2seq 周公解梦,看AI如何解析你的梦境?【转】
介绍 在参与的项目和产品中,涉及到模型和算法的需求,主要以自然语言处理(NLP)和知识图谱(KG)为主.NLP涉及面太广,而聚焦在具体场景下,想要生产落地的还需要花很多功夫. 作为NLP的主要方向,情 ...
- 基于爬取百合网的数据,用matplotlib生成图表
爬取百合网的数据链接:http://www.cnblogs.com/YuWeiXiF/p/8439552.html 总共爬了22779条数据.第一次接触matplotlib库,以下代码参考了matpl ...
- Scrapy实战篇(八)之Scrapy对接selenium爬取京东商城商品数据
本篇目标:我们以爬取京东商城商品数据为例,展示Scrapy框架对接selenium爬取京东商城商品数据. 背景: 京东商城页面为js动态加载页面,直接使用request请求,无法得到我们想要的商品数据 ...
- 利用python爬取58同城简历数据
利用python爬取58同城简历数据 利用python爬取58同城简历数据 最近接到一个工作,需要获取58同城上面的简历信息(http://gz.58.com/qzyewu/).最开始想到是用pyth ...
- 使用Selenium爬取网站表格类数据
本文转载自一下网站:Python爬虫(5):Selenium 爬取东方财富网股票财务报表 https://www.makcyun.top/web_scraping_withpython5.html 需 ...
- jsoup爬取某网站安全数据
jsoup爬取某网站安全数据 package com.vfsd.net; import java.io.IOException; import java.sql.SQLException; impor ...
- python爬取豆瓣电影信息数据
题外话+ 大家好啊,最近自己在做一个属于自己的博客网站(准备辞职回家养老了,明年再战)在家里 琐事也很多, 加上自己 一回到家就懒了(主要是家里冷啊! 广东十几度,老家几度,躲在被窝瑟瑟发抖,) 由于 ...
- 几句简单的python代码完成周公解梦功能
<周公解梦>是靠人的梦来卜吉凶的一本于民间流传的解梦书籍,共有七类梦境的解述.这是非常传统的中国文化体系的一部分,但是如何用代码来获取并搜索周公解梦的数据呢?一般情况下,要通过爬虫获取数据 ...
随机推荐
- Python数据分析环境和工具
一.数据分析工作环境 Anaconda: Anaconda(水蟒)是一个科学计算软件发行版,集成了大量常用扩展包的环境,包含了 Python 解释器,conda 包管理工具,以及 NumPy.Pand ...
- 【Nutch2.2.1基础教程之6】Nutch2.2.1抓取流程 分类: H3_NUTCH 2014-08-15 21:39 2530人阅读 评论(1) 收藏
一.抓取流程概述 1.nutch抓取流程 当使用crawl命令进行抓取任务时,其基本流程步骤如下: (1)InjectorJob 开始第一个迭代 (2)GeneratorJob (3)FetcherJ ...
- [GraphQL] Write a GraphQL Mutation
In order to change the data that we can query for in a GraphQL Schema, we have to define what is cal ...
- Windows7系统下安装OpenSSL攻略
Windows7系统下安装OpenSSL攻略 http://blog.chinaunix.net/uid-20479991-id-216269.html http://my.oschina.net/s ...
- Html Vedio标签全屏
http://ask.csdn.net/questions/221701 http://www.zhangxinxu.com/wordpress/2010/03/every-browser-suppo ...
- 找不到头文件xxxxx.h file not found
项目里有该文件,但是还是显示找不到.或者是cocopods打开的项目. 原因:.h文件路径找不到.具体找不到的原因有很多种. 1.一般会设置 IOS引用三方framewrok的头文件出现'xxxxx/ ...
- ospf基本配置协议
OSPF(开放最短路径优先)协议是链路状态路由协议类.对于 IPv4 的 OSPF 当前版本号 OSPFv2,的版本号 John Moy 在 RFC 1247 中引入,并在 RFC 2328 中 ...
- 在这里23种经典设计模式UML类图汇总
创建型模式 1.FACTORY-追MM少不了请吃饭了,麦当劳的鸡翅和肯德基的鸡翅都是MM爱吃的东西,虽然口味有所不同,但不管你带MM去麦当劳或肯德基,只管向服务员说"来四个鸡翅"就 ...
- Network management system scheduling for low power and lossy networks
In one embodiment, a network management system (NMS) determines an intent to initialize a request-re ...
- ASP.NET中进度条的简单应用
<html xmlns="http://www.w3.org/1999/xhtml" id="mainWindow"> <head> & ...