Spark SQL概念学习系列之Spark SQL概述
很多人一个误区,Spark SQL重点不是在SQL啊,而是在结构化数据处理!
Spark SQL结构化数据处理
概要:
01 Spark SQL概述
02 Spark SQL基本原理
03 Spark SQL编程
04 分布式SQL引擎
05 用户自定义函数
06 性能调优
Spark SQL概述
Spark SQL是什么?
Spark SQL is a Spark module for structured data processing
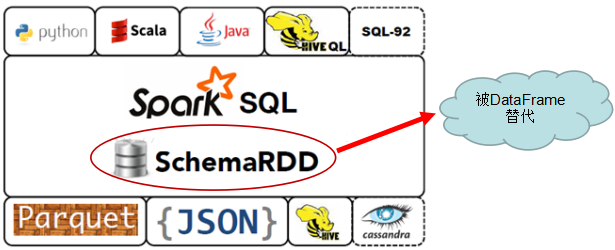
特别注意:.3.0 及后续版本中,SchemaRDD 已经被DataFrame 所取代。所以,我们以后的重点是DataFrame,各位博友们!
何为结构化数据
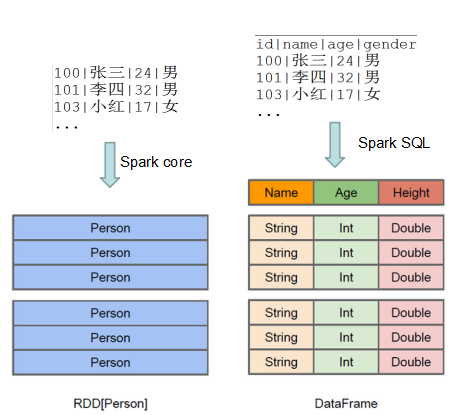
SparkSQL 与 Spark Core的关系
Spark SQL构建在Spark Core之上,专门用来处理结构化数据(不仅仅是SQL)。
Spark SQL在Spark Core的基础上针对结构化数据处理进行很多优化和改进,
简单来讲:
Spark SQL 支持很多种结构化数据源,可以让你跳过复杂的读取过程,轻松从各种数据源中读取数据
当你使用SQL查询这些数据源中的数据并且只用到了一部分字段时,SparkSQL可以智能地只扫描这些用到的字段,而不是像SparkContext.hadoopFile中那样简单粗暴地扫描全部数据.
Spark SQL前世今生:由Shark发展而来

Spark SQL前世今生:可以追溯到Hive
由facebook 开源, 最初用于解决海量结构化的日志数据统计问题的ETL(Extraction-Transformation-Loading) 工具
构建在Hadoop上的数据仓库平台,设计目标是使得可以用传统SQL操作Hadoop上的数据,让熟悉SQL编程的人员也能拥抱Hadoop。
1.使用HQL 作为查询接口
2.使用HDFS 作为底层存储
3.使用MapRed 作为执行层
现已成为Hadoop平台上的标配。
曾在一段时间之内成为SQL on Hadoop的唯一选择!
http://hive.apache.org/ https://cwiki.apache.org/confluence/display/Hive/Home https://cwiki.apache.org/confluence/display/Hive/LanguageManual
Spark SQL前世今生:Hive 到 Shark(在Hive上做改进)
背景:Spark出现之后,社区开始考虑基于Spark提供SQL解决方案,这就是诞生的背景
基于Hive的代码库,修改了Hive的后端引擎使其运行在Spark上(在Hive上做改进)。

导致社区放弃Shark的主要原因:
和Spark程序的集成有诸多限制
Hive的优化器不是为Spark而设计的,计算模型的不同,使得Hive的优化器来优化Spark程序遇到了瓶颈。
Spark SQL前世今生:Shark 到 Spark SQL(彻底摆脱但是兼容Hive)

Spark SQL前世今生:Hive 到 Hive on Spark
Spark SQL诞生的同时,Hive还在继续发展,一些深耕Hive的用户意识到迁移还是需要成本的,于是Hive社区提出了Hive on Spark的计划
从Hive 1.1+开始可用,还在发展过程中
Spark SQL前世今生

Spark SQL概念学习系列之Spark SQL概述的更多相关文章
- Spark SQL概念学习系列之Spark SQL 架构分析(四)
Spark SQL 与传统 DBMS 的查询优化器 + 执行器的架构较为类似,只不过其执行器是在分布式环境中实现,并采用的 Spark 作为执行引擎. Spark SQL 的查询优化是Catalyst ...
- Spark SQL概念学习系列之分布式SQL引擎
不多说,直接上干货! parkSQL作为分布式查询引擎:两种方式 除了在Spark程序里使用Spark SQL,我们也可以把Spark SQL当作一个分布式查询引擎来使用,有以下两种使用方式: 1.T ...
- Spark RDD概念学习系列之Spark Hash Shuffle内幕彻底解密(二十)
本博文的主要内容: 1.Hash Shuffle彻底解密 2.Shuffle Pluggable解密 3.Sorted Shuffle解密 4.Shuffle性能优化 一:到底什么是Shuffle? ...
- Spark SQL概念学习系列之Spark SQL的简介(一)
Spark SQL提供在大数据上的SQL查询功能,类似于Shark在整个生态系统的角色,它们可以统称为SQL on Spark. 之前,Shark的查询编译和优化器依赖于Hive,使得Shark不得不 ...
- Spark SQL概念学习系列之Spark SQL 优化策略(五)
查询优化是传统数据库中最为重要的一环,这项技术在传统数据库中已经很成熟.除了查询优化, Spark SQL 在存储上也进行了优化,从以下几点查看 Spark SQL 的一些优化策略. (1)内存列式存 ...
- Spark SQL概念学习系列之Spark SQL入门
前言 第1章 为什么Spark SQL? 第2章 Spark SQL运行架构 第3章 Spark SQL组件之解析 第4章 深入了解Spark SQL运行计划 第5章 测试环境之搭建 第6章 ...
- Spark SQL概念学习系列之Spark SQL入门(八)
前言 第1章 为什么Spark SQL? 第2章 Spark SQL运行架构 第3章 Spark SQL组件之解析 第4章 深入了解Spark SQL运行计划 第5章 测试环境之搭建 第6章 ...
- Spark SQL概念学习系列之Spark SQL基本原理
Spark SQL基本原理 1.Spark SQL模块划分 2.Spark SQL架构--catalyst设计图 3.Spark SQL运行架构 4.Hive兼容性 1.Spark SQL模块划分 S ...
- Spark SQL概念学习系列之Spark生态之Spark SQL(七)
具体,见
随机推荐
- APNs推送
消息推送是可以指定声音的.譬如你可以对正面的反馈使用欢快的声音,对负面的反馈使用低沉一点的声音,都可以达到别出心裁让人眼前一亮的目的.你需要先放一些aiff.wav或者caf音频文件到app的资源文件 ...
- jQuery中文学习站点
jQuery是一个快速.简单的Javascript library,它简化了HTML文件的traversing,事件处理.动画.Ajax互动,从而方便了网页制作的快速发展.jQuery是为改变你编写J ...
- C++快速读取大文件
debug的时候需要等很长时间读模型,查资料发现了两种快速读取大文件的方法. test 1:每次读一个字符串 test 2.3一次读取整个文件 {//test 1 string buf; clock_ ...
- HDU 2199 Can you solve this equation?【二分查找】
解题思路:给出一个方程 8*x^4 + 7*x^3 + 2*x^2 + 3*x + 6 == Y,求方程的解. 首先判断方程是否有解,因为该函数在实数范围内是连续的,所以只需使y的值满足f(0)< ...
- Side effect (computer science)
In computer science, a function or expression is said to have a side effect if it modifies some stat ...
- Unity坐标系 左手坐标系 图
x轴:从左指向右 y轴:从下指向上 z轴:指向屏幕里的是左手坐标系,指向屏幕外的是右手坐标系 记忆小技巧:都是X轴朝右,Y轴向上,跟平时画坐标一模一样,区别只是Z的朝向.你用手试一下就知道了,当大拇指 ...
- node——文件写入,文件读取
ru //实行文件操作 //文件写入 //1.加载文件操作,fs模块 var fs = require('fs'); //2.实现文件写入操作 var msg='Hello world'; //调用f ...
- elementUI 上传.csv文件不成功 导入功能
前言:element上传excel文件 导入功能 目标:点击导入,将excel表格的数据填充到表格. <el-upload class="upload-demo" :ac ...
- freeswitch 编码协商
编辑 /usr/local/freeswitch/conf/sip_profiles/internal.xml 添加注释 <param name="inbound-zrtp-p ...
- Django REST Framework 数码宝贝 - 3步进化 - 混合类 -->
读了我这篇博客, 你会刷新对面对对象的认知, 之前的面对对象都是LJ~~~ 表结构 class Publisher(models.Model): name = models.CharField(max ...