高斯判别分析模型( Gaussian discriminant analysis)及Python实现
高斯判别分析模型( Gaussian discriminant analysis)及Python实现
1.模型
高斯判别分析模型是一种生成模型,而之前所提到的逻辑回归是一种判别模型,生成模型和判别模型的详细了解可参考这篇文章:
http://blog.sciencenet.cn/home.php?mod=space&uid=248173&do=blog&id=227964
简单的来说,我们的目标都是p(y|x),判别模型是构造一个函数f(x)去逼近p(y|x),而对于生成模型则是通过贝叶斯公式p(y|x) = p(x|y)p(y)/p(x),求得p(x|y)和p(y)来间接得到p(y|x)。
首先,高斯判别分析模型对变量x和y有如下假设:
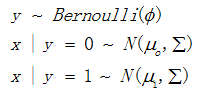
这样,可以给出概率密度函数:

2.评价
该模型的对数似然函数如下:

3.优化
对各个参数进行求导后令等式为0,得到:

Φ是训练样本中结果 y=1 占有的比例。
μ0是 y=0 的样本中特征均值。
μ1是 y=1 的样本中特征均值。
Σ是样本特征方差均值。
4.python代码实现
# -*- coding: utf-8 -*-
"""
Created on Tue Mar 08 16:16:36 2016 @author: SumaiWong
""" import numpy as np
import pandas as pd
from numpy import dot
from numpy.linalg import inv iris = pd.read_csv('D:\iris.csv')
dummy = pd.get_dummies(iris['Species']) # 对Species生成哑变量
iris = pd.concat([iris, dummy], axis =1 )
iris = iris.iloc[0:100, :] # 截取前一百行样本 X = iris.ix[:, 0:4]
Y = iris['setosa'].reshape(len(iris), 1) #整理出X矩阵 和 Y矩阵 def GDA(Y, X):
theta1 = Y.mean() #类别1的比例
theta0 = 1-Y.mean() #类别2的比例
mu1 = X[Y==1].mean() #类别1特征的均值向量
mu0 = X[Y==0].mean() #类别2特征的均值向量 X_1 = X[Y==1]
X_0 = X[Y==0]
A = dot(X_1.T, X_1) - len(Y[Y==1])*dot(mu1.reshape(4,1), mu1.reshape(4,1).T)
B = dot(X_0.T, X_0) - len(Y[Y==0])*dot(mu0.reshape(4,1), mu0.reshape(4,1).T)
sigma = (A+B)/len(X) #sigma = X'X-n(X.bar)X.bar'=X'[I-1/n 1 1]X
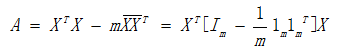
return theta1, theta0, mu1, mu0, sigma
高斯判别分析模型( Gaussian discriminant analysis)及Python实现的更多相关文章
- 高斯判别分析 Gaussian Discriminant Analysis
如果在我们的分类问题中,输入特征xx是连续型随机变量,高斯判别模型(Gaussian Discriminant Analysis,GDA)就可以派上用场了. 以二分类问题为例进行说明,模型建立如下: ...
- Gaussian Discriminant Analysis
如果在我们的分类问题中,输入特征$x$是连续型随机变量,高斯判别模型(Gaussian Discriminant Analysis,GDA)就可以派上用场了. 以二分类问题为例进行说明,模型建立如下: ...
- Gaussian discriminant analysis 高斯判别分析
高斯判别分析(附Matlab实现) 生成学习算法 高斯判别分析(Gaussian Discriminant analysis,GDA),与之前的线性回归和Logistic回归从方法上讲有很大的不同,G ...
- 生成式学习算法(三)之----高斯判别分析模型(Gaussian Discriminant Analysis ,GDA)
高斯判别分析模型(Gaussian Discriminant Analysis ,GDA) 当我们分类问题的输入特征$x $为连续值随机变量时,可以用高斯判别分析模型(Gaussian Discrim ...
- 机器学习理论基础学习3.4--- Linear classification 线性分类之Gaussian Discriminant Analysis高斯判别模型
一.什么是高斯判别模型? 二.怎么求解参数?
- [Scikit-learn] 1.2 Dimensionality reduction - Linear and Quadratic Discriminant Analysis
Ref: http://scikit-learn.org/stable/modules/lda_qda.html Ref: http://bluewhale.cc/2016-04-10/linear- ...
- 线性判别分析(Linear Discriminant Analysis, LDA)算法初识
LDA算法入门 一. LDA算法概述: 线性判别式分析(Linear Discriminant Analysis, LDA),也叫做Fisher线性判别(Fisher Linear Discrimin ...
- 线性判别分析(Linear Discriminant Analysis,LDA)
一.LDA的基本思想 线性判别式分析(Linear Discriminant Analysis, LDA),也叫做Fisher线性判别(Fisher Linear Discriminant ,FLD) ...
- 线性判别分析(Linear Discriminant Analysis, LDA)算法分析
原文来自:http://blog.csdn.net/xiazhaoqiang/article/details/6585537 LDA算法入门 一. LDA算法概述: 线性判别式分析(Lin ...
随机推荐
- NOIP模拟 Pyramid - 斜率优化DP
题目大意: 给一个金字塔图(下面的宽度大于等于上面的宽度),每层的高度为1,从中选取k个互不重叠的矩形,使面积最大. 题目分析: \(f[i][j]\)表示选到第i层,选择了j个矩形的最优方案. 转移 ...
- LUOGU 1137 - 拓扑排序
传送门 题目分析 拓扑排序:将图从度为0的点不断的剥掉外层的点,即可得到拓扑序,再按照拓扑序进行一遍简单的dp. code #include<bits/stdc++.h> using na ...
- Spring Boot with JSP and Tiles3
Spring Boot with JSP and Tiles3 Using tiles and jsp on a Spring Boot 1.2.7 project file: pom.xml und ...
- 数学类网站、代码(Matlab & Python & R)
0. math & code COME ON CODE ON | A blog about programming and more programming. 1. 中文 统计学Computa ...
- 【转】mysql的SQL_NO_CACHE(在查询时不使用缓存)和sql_cache用法
转自:http://www.169it.com/article/5994930453423417575.html 为了测试sql语句的效率,有时候要不用缓存来查询. 使用 SELECT SQL_NO_ ...
- 图像处理与计算机视觉的 topics
光学图像(optical image): the apparent reproduction of an object, formed by a lens or mirror system from ...
- python 教程 第十六章、 正则表达式
第十六章. 正则表达式 1) 匹配多个表达式 记号 re1|re2 说明 匹配正则表达式re1或re2 举例 foo|bar 匹配 foo, bar 记号 {N} 说明 匹配前面出 ...
- 【C语言学习】C语言功能
代码,功能为了更好地实现模块化编程.那么,什么是函数的性质?在函数中定义的变量(全局变量.局部变量.静态变量)如何存储?为什么范围和全局变量和局部变量的寿命是不一样的?只是有一个更深入的了解的功能.能 ...
- 升级phpstudy2018默认mysql版本到5.7
原文:升级phpstudy2018默认mysql版本到5.7 版权声明:在那最初的相遇中,我们都曾经为彼此心动过... https://blog.csdn.net/weixin_36185028/ar ...
- 推荐几个js的好链接
JavaScript 之美 其一:http://fxck.it/post/72326363595 其二:http://fxck.it/post/73513189448