【3】Kafka安装及部署
一、环境准备
- Linux操作系统
- Java运行环境(1.6或以上)
- zookeeper 集群环境,可参照Zookeeper集群部署 。
- 服务器列表:
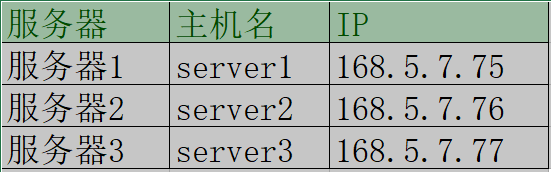
配置主机名映射。
vi /etc/hosts
##添加如下内容
168.5.7.75 server1
168.5.7.76 server2
168.5.7.77 server3
二、kafka集群部署及启动
2.1、介质准备
分别登录server1、server2、server3执行,操作、配置相同:
##更新或安装wget命令
yum -y install wget
##创建安装目录
mkdir -p /usr/local/services/kafka
##获取安装包kafka_2.11-2.3.0.tgz
wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.3.0/kafka_2.11-2.3.0.tgz
##解压缩kafka_2.11-2.3.0.tgz
tar -zxvf kafka_2.11-2.3.0.tgz
2.2、配置环境变量
分别登录server1、server2、server3执行,操作、配置相同:
export KAFKA_HOME=/usr/local/services/kafka/kafka_2.11-2.3.0
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile
说明:再任一路径下输入 kafka 按 Tab 键后会补全 Kafka 相关脚本.sh,即Kafka 环境变量配置成功。 因 Kafka 脚本运行时会加载 /config 路径下的相关配置文件,故当不在 Kafka 安装目录 bin 下执行相关脚本时, 需要指定配置文件绝对路径。
2.3、修改配置文件
登录server1执行操作:
cd $KAFKA_HOME/config
cp server.properties server.properties.$(date +%Y%m%d)
vi server.properties
##修改文件内配置如下
broker.id=1
log.dirs=/opt/data/kafka-logs
port=9093
zookeeper.connect=server1:2181,server2:2181,server3:2181
登录server2执行操作:
cd $KAFKA_HOME/config
cp server.properties server.properties.$(date +%Y%m%d)
vi server.properties
##修改文件内配置如下
broker.id=2
log.dirs=/opt/data/kafka-logs
port=9093
zookeeper.connect=server1:2181,server2:2181,server3:2181
登录server3执行操作:
cd $KAFKA_HOME/config
cp server.properties server.properties.$(date +%Y%m%d)
vi server.properties
##修改文件内配置如下
broker.id=3
log.dirs=/opt/data/kafka-logs
port=9093
zookeeper.connect=server1:2181,server2:2181,server3:2181
说明:broker.id 用于指定代理的 id,需保证同一个集群下 broker.id 要唯一;log.dirs 指定日志存储路径。
2.4、启动服务
分别登录server1、server2、server3执行,操作、配置相同:
cd $KAFKA_HOME/bin
## -daemon :守护进程方式启动
kafka-server-start.sh -daemon ../config/server.properties
连接测试
#登录 ZooKeeper
cd /usr/local/services/zookeeper/zookeeper-3.4.13/bin
./zkCli.sh -server server1:2181
ls /
日志查看
##查看 KafkaServer 启动 日志
cat $KAFKA_HOME/logs/server.log
参考资料
参考书籍:Kafka入门与实践
DeepInThought
出处:
https://www.cnblogs.com/DeepInThought
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
【3】Kafka安装及部署的更多相关文章
- Kafka安装及部署
安装及部署 一.环境配置 操作系统:Cent OS 7 Kafka版本:0.9.0.0 Kafka官网下载:请点击 JDK版本:1.7.0_51 SSH Secure Shell版本:XShell 5 ...
- kafka安装和部署
阅读目录 一.环境配置 二.操作过程 Kafka介绍 安装及部署 回到顶部 一.环境配置 操作系统:Cent OS 7 Kafka版本:0.9.0.0 Kafka官网下载:请点击 JDK版本:1.7. ...
- kafka系列一、kafka安装及部署、集群搭建
一.环境准备 操作系统:Cent OS 7 Kafka版本:kafka_2.10 Kafka官网下载:请点击 JDK版本:1.8.0_171 zookeeper-3.4.10 二.kafka安装配置 ...
- Kafka的安装和部署及测试
1.简介 大数据分析处理平台包括数据的接入,数据的存储,数据的处理,以及后面的展示或者应用.今天我们连说一下数据的接入,数据的接入目前比较普遍的是采用kafka将前面的数据通过消息的方式,以数据流的形 ...
- Kafka安装部署
1.从官网下载安装包,并通过Xftp5上传到机器集群上 下载kafka_2.11-1.1.0.tgz版本,并通过Xftp5上传到hadoop机器集群的第一个节点node1上的/opt/uploa ...
- zookeeper与kafka安装部署及java环境搭建(发布订阅模式)
1. ZooKeeper安装部署 本文在一台机器上模拟3个zk server的集群安装. 1.1. 创建目录.解压 cd /usr/ #创建项目目录 mkdir zookeeper cd zookee ...
- Logstash安装及部署
安装及部署 一.环境配置 操作系统:Cent OS 7 Logstash版本:2.1.1.tar.gz JDK版本:1.7.0_51 SSH Secure Shell版本:XShell 5 二.操作过 ...
- Kafka集群部署
一. 关于kafka Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据. 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键 ...
- Zookeeper+Kafka集群部署(转)
Zookeeper+Kafka集群部署 主机规划: 10.200.3.85 Kafka+ZooKeeper 10.200.3.86 Kafka+ZooKeeper 10.200.3.87 Kaf ...
随机推荐
- Salesforce LWC学习(九) Quick Action in LWC
我们在lightning开发中,quick action是一个常用的功能,很可惜的是,lwc目前还不支持单独的custom quick action操作,只能嵌套在aura中使用才能发挥作用. 官方也 ...
- xhprof代码添加分析性能
<?php xhprof_enable( XHPROF_FLAGS_MEMORY, [ 'ignored_functions' => [ //'call_user_func', //'ca ...
- Go语言实现bitmap算法
有关bitmap算法的介绍资料网上很多,这里不赘述,各种语言的实现也不少,但是Go语言版的bitmap不多,本文就来写一个Go版的bitmap实现. 首先创建一个 bitmap.go 文件,定义一个b ...
- 【Qt开发】 QT:make: Nothing to be done for `first'和error:QtSql:No such file or directory
http://blog.csdn.NET/heqiuya/article/details/7774208 这是QT编程中常见的两个编译错误.可能你的代码在window下编译能正常通过,可是到到Linu ...
- 可执行jar包与依赖jar包
1.在IDEA的pom文件中有如下配置的,打包出来的是可执行jar包,可执行jar包不能作为依赖. <build> <plugins> <plugin> <g ...
- JS实现对数组进行自定义排序
/** * 数组排序 * @param source 待排序数组 * @param orders 排序字段数组 * @param type 升序-asc 倒序-desc * 调用:var res = ...
- SpringBoot:SpringBoot整合JdbcTemplate
个人其实偏向于使用类似于JdbcTemplate这种的框架,返回数据也习惯于接受Map/List形式,而不是转化成对象,一是前后台分离转成json方便,另外是返回数据格式,数据字段可以通过SQL控制, ...
- 局部内部类的final问题
局部内部类,如果希望访问所在方法的局部变量,那么这个局部变量就必须是final的(或者只赋值一次) 从Java8开始,只要局部变量事实不变那么final关键字可以省略 为什么需要保证变量为final, ...
- CSS3伪类与伪元素的区别及注意事项
CSS中伪类与伪元素的概念是很容易混淆的 今天就来谈谈伪类与伪元素之间的区别 定义 首先先来看看伪类与伪元素的定义 w3c中对于它们是这么解释的 伪类:用于向某些选择器添加特殊的效果 伪元素:用于将特 ...
- Python+requests重定向和追踪
Python+requests重定向和追踪 一.什么是重定向 重定向就是网络请求被重新定个方向转到了其它位置 二.为什么要做重定向 网页重定向的情况一般有:网站调整(如网页目录结构变化).网页地址改变 ...