k-means和iosdata聚类算法在生活案例中的运用
引言:聚类是将数据分成类或者簇的过程,从而使同簇的对象之间具有很高的相似度,而不同的簇的对象相似度则存在差异。聚类技术是一种迭代重定位技术,在我们的生活中也得到了广泛的运用,比如:零件分组、数据评价、数据分析等很多方面;具体的比如对市场分析人员而言,聚类可以帮助市场分析人员从消费者数据库中分出不同的消费群体来,并且可以分析出每一类消费者的消费习惯等,从而帮助市场人员对销售做出更好的决策。
所以,本篇博客主要是对生活中的案例,运用k-means算法和isodata聚类算法进行数据评价和分析。本文是对“中国男足近几年在亚洲处于几流水平?”的问题进行分析。
首先,先让我们了解什么是k-means和iosdata聚类算法:
一、k-means算法
K-means算法是典型的基于距离的聚类算法,即对各个样本集采用距离作为相似性的评价指标,若两个样本集的距离越近,其相似度就越大。按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,且让簇间的距离尽量的大。最后把得到紧凑且独立的簇作为最终的目标。
实现过程如下:
(1)随机选取K个初始质心
(2)分别计算所有样本到这K个质心的距离
(3)如果样本离某质心Ki最近,那么这个样本属于Ki点群;如果到多个质心的距离相等,则可划分到任意组中
(4)按距离对所有样本分完组之后,计算每个组的均值(最简单的方法就是求样本每个维度的平均值),作为新的质心
(5)重复(2)(3)(4)直到新的质心和原质心相等,算法结束
二、iosdata聚类算法
算法思想:输入N个样本,预选Nc个初始聚类中心{z1,z2,…zNc},它可以不等于所要求的聚类中心的数目,其初始位置可以从样本中任意选取。K为预期的聚类中心数目;θN为每一聚类域中最少的样本数目,若少于此数即不作为一个独立的聚类;θS为一个聚类域中样本距离分布的标准差;θc为两个聚类中心间的最小距离,若小于此数,两个聚类需进行合并;L为在一次迭代运算中可以合并的聚类中心的最多对数;I为迭代运算的次数。当某两类聚类中心距离θc小于阙值则归为一类,否则为不同类,某类样本数θN小于阙值,则将其删掉。
三、K-means算法和iosdata算法的不同:
1、iosdata算法每次把全部样本都调整完毕之后重新计算一次样本的均值;
2、iosdata算法会自动进行类的“合并”和“分裂”,从而得到聚类数较为合理的各个聚类。
四、动态聚类算法的3个要点:
1、 选定某种距离度量作为样本间的相似度量;
2、 确定某个评价聚类结果的准则函数;
3、 给定某个初始分类,然后用迭代算法找出是准则函数取极值的最好聚类结果。
五、案例分析
我要进行分析的数据是采集了亚洲16只球队在2006-2018年间大型的比赛战绩。数据进行了如下预处理:对于世界杯,进入决赛则取其最终排名,没有进入决赛的但打入预选赛十强赛赋予40,预选赛小组未出线的赋予50。对于亚洲杯,前四名取其排名,八强赋予5,十六强赋予9,预选赛没有出现的赋予17.数据如下
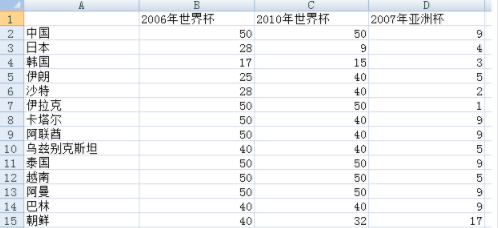
对数据进行[0,1]规格化:
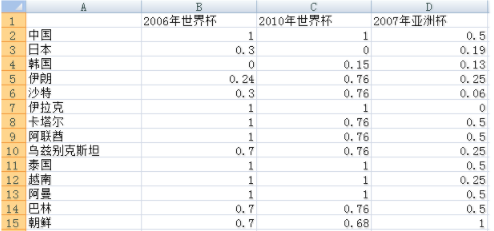
1.用k-means算法进行聚类。设k=3,即将这14支球队分成三个集团。
2.抽取日本、巴林和泰国的值作为三个簇的种子,即初始化三个簇的中心为A:{0.3, 0, 0.19},B:{0.7, 0.76, 0.5}和C:{1, 1, 0.5},即分别对应第2、13,和10条记录。
3.计算所有球队分别对三个中心点的相异度,以欧氏距离度量。
第一次聚类结果:
A:日本,韩国,伊朗,沙特;
B:乌兹别克斯坦,巴林,朝鲜;
C:中国,伊拉克,卡塔尔,阿联酋,泰国,越南,阿曼。
4.根据第一次聚类结果,调整各个簇的中心点。
A簇的新中心点为:{(0.3+0+0.24+0.3)/4=0.21, (0+0.15+0.76+0.76)/4=0.4175, (0.19+0.13+0.25+0.06)/4=0.1575} = {0.21, 0.4175, 0.1575}
用同样的方法计算得到B和C簇的新中心点分别为{0.7, 0.7333, 0.4167},{1, 0.94, 0.40625}。
用调整后的中心点再次进行聚类,得到第二次迭代后的结果仍为:中国C,日本A,韩国A,伊朗A,沙特A,伊拉克C,卡塔尔C,阿联酋C,乌兹别克斯坦B,泰国C,越南C,阿曼C,巴林B,朝鲜B。
结果无变化,说明结果已收敛。于是,最终聚类结果为:
亚洲一流:日本,韩国,伊朗,沙特
亚洲二流:乌兹别克斯坦,巴林,朝鲜
亚洲三流:中国,伊拉克,卡塔尔,阿联酋,泰国,越南,阿曼
六、代码实现
>> a=[,,0.5;0.3,,0.19;,0.15,0.13;0.24,0.76,0.25;0.3,0.76,0.06;,,;,0.76,0.5;,0.76,0.5;0.7,0.76,0.25;,,0.5;,,0.25;,,0.5;0.7,0.76,0.5;0.7,0.68,;,,0.5]
a =
1.0000 1.0000 0.5000
0.3000 0.1900
0.1500 0.1300
0.2400 0.7600 0.2500
0.3000 0.7600 0.0600
1.0000 1.0000
1.0000 0.7600 0.5000
1.0000 0.7600 0.5000
0.7000 0.7600 0.2500
1.0000 1.0000 0.5000
1.0000 1.0000 0.2500
1.0000 1.0000 0.5000
0.7000 0.7600 0.5000
0.7000 0.6800 1.0000
1.0000 1.0000 0.5000
>> ind=[,,]
ind =
>> b=a(ind(:),:)
b =
0.3000 0.1900
0.7000 0.7600 0.5000
1.0000 1.0000 0.5000
result =
1.2594 0.3842
0.9131 1.2594
0.3407 0.9995 1.3636
0.7647 0.5235 0.8353
0.7710 0.5946 0.8609
1.2354 0.6306 0.5000
1.0787 0.3000 0.2400
1.0787 0.3000 0.2400
0.8609 0.2500 0.4584
1.2594 0.3842
1.2221 0.4584 0.2500
1.2594 0.3842
0.9131 0.3842
1.1307 0.5064 0.6651
1.2594 0.3842
k-means和iosdata聚类算法在生活案例中的运用的更多相关文章
- 聚类算法在 D2C 布局中的应用
1.摘要 聚类是统计数据分析的一门技术,在许多领域受到广泛的应用,包括机器学习.数据挖掘.图像分析等等.聚类就是把相似的对象分成不同的组别或者更多的子集,从而让每个子集的成员对象都有相似的一些属性. ...
- 聚类算法:K均值、凝聚层次聚类和DBSCAN
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- 常见聚类算法——K均值、凝聚层次聚类和DBSCAN比较
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- 数据聚类算法-K-means算法
深入浅出K-Means算法 摘要: 在数据挖掘中,K-Means算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法. K-Mea ...
- 机器学习实战之 第10章 K-Means(K-均值)聚类算法
第 10 章 K-Means(K-均值)聚类算法 K-Means 算法 聚类是一种无监督的学习, 它将相似的对象归到一个簇中, 将不相似对象归到不同簇中.相似这一概念取决于所选择的相似度计算方法.K- ...
- 【机器学习实战】第 10 章 K-Means(K-均值)聚类算法
第 10 章 K-Means(K-均值)聚类算法 K-Means 算法 聚类是一种无监督的学习, 它将相似的对象归到一个簇中, 将不相似对象归到不同簇中.相似这一概念取决于所选择的相似度计算方法.K- ...
- 一步步教你轻松学K-means聚类算法
一步步教你轻松学K-means聚类算法(白宁超 2018年9月13日09:10:33) 导读:k-均值算法(英文:k-means clustering),属于比较常用的算法之一,文本首先介绍聚类的理 ...
- 【机器学习实战】第10章 K-Means(K-均值)聚类算法
第 十 章 K-Means(K-均值)聚类算法 K-Means 算法 聚类是一种无监督的学习, 它将相似的对象归到一个簇中, 将不相似对象归到不同簇中.相似这一概念取决于所选择的相似度计算方法.K-M ...
- 聚类(三)FUZZY C-MEANS 模糊c-均值聚类算法——本质和逻辑回归类似啊
摘自:http://ramsey16.net/%E8%81%9A%E7%B1%BB%EF%BC%88%E4%B8%89%EF%BC%89fuzzy-c-means/ 经典k-均值聚类算法的每一步迭代中 ...
随机推荐
- FlowPortal BPM 明细表中新添加的行一直排在最后的问题
明细表中的数据提交过之后再编辑时,添加的行不管在第几行添加都显示在最后一行的问题 Solution:明细表的数据库表中加字段OrderIndex,设为必填,系统会自动排序
- bootstrap 分页行数选择按钮失效
原因是bootstrap.js重复加载,button点击作用两次,导致没效果
- Memory Network
转自:https://www.jianshu.com/p/e5f2b20d95ff,感谢分享! 基础Memory-network 传统的RNN/LSTM等模型的隐藏状态或者Attention机制的记忆 ...
- win10关闭防火墙和其通知
Win10电脑在关闭防火墙后,防火墙的通知会不定期提醒,如果误点后,防火墙就悄悄的开启了,导致好多功能就用不了了,所以比较有效的方法是:关闭防火墙,并关闭防火墙通知 1.关闭防火墙 在控制面板中,选择 ...
- OpenGL ES on iOS --- 统一变量(Uniform)和统一变量块(UBO)
简介 Uniform是一种从CPU中的应用向GPU中的着色器发送数据的方式,但uniform和顶点属性有些不同. 首先,uniform是全局的(Global).全局意味着uniform变量必须在每个着 ...
- 用js刷剑指offer(重建二叉树)
题目描述 输入某二叉树的前序遍历和中序遍历的结果,请重建出该二叉树.假设输入的前序遍历和中序遍历的结果中都不含重复的数字.例如输入前序遍历序列{1,2,4,7,3,5,6,8}和中序遍历序列{4,7, ...
- jade过滤器
以上语法基本讲完了jade的语法,然后在jade里面并不仅仅局限于使用jade语法,同样可以使用其他的插件语言,这种机制在jade里面称为filter,在jade里面加入过滤器用冒号 markdown ...
- Web应用中的缓存一致性问题
上篇总结了缓存中出现频率比较高的一些问题,今天详细说说web应用中的缓存一致性问题. 主要说以下三个方面 数据库与缓存中数据不一致出现的情形 发生不一致时的优化思路 如何保证数据库与缓存的一致性 先来 ...
- duilib学习领悟(2)
再次强调,duilib只不过是一种思想! 在上一节中,我剖析了duilib中窗口类的注册,其中遗留两个小问题没有细说的? 第一个问题:过程函数中__WndProc()中有这么一小段代码: pThis ...
- centos7下redis和php-redis安装
centos7下redis安装和php-redis扩展安装 //一直yes就可以了 yum install redis //配置 whereis redis.conf vi /etc/redis.co ...