mysql内存优化
一.环境说明:
操作系统:CentOS 6.5 x86_64
数据库:Mysql 5.6.22
服务器:阿里云VPS,32G Mem,0 swap
二.问题情况:
1.某日发现公司线上系统的Mysql某个实例的从库长时间内存占用达到60%如下图
2.于是开始按照以下步骤排查:
(1).查看mysql里的线程,观察是否有长期运行或阻塞的sql:
show full processlist
经查看,没有发现相关线程,可排除该原因
(2).疑似mysql连接使用完成后没有真正释放内存,查看mysql内存,缓存的相关配置,使用如
show global variables like '%sort_buffer_size%';
查看相关的配置项,结果列表汇总如下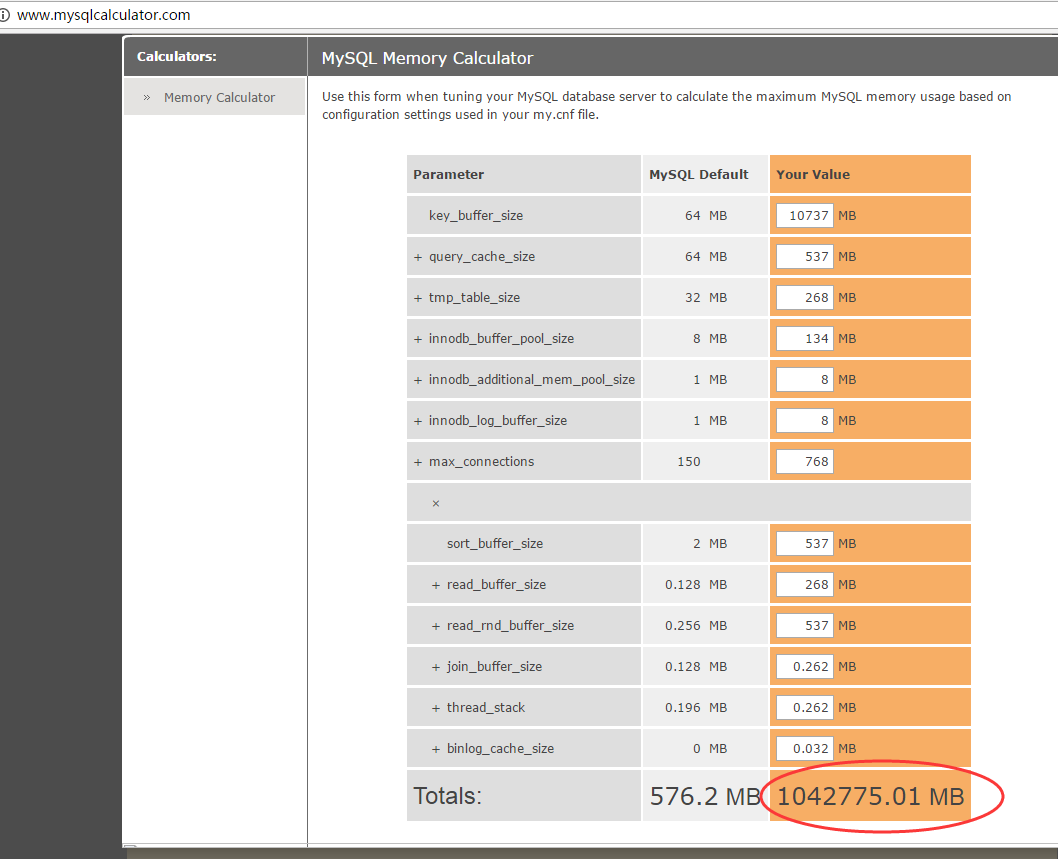
( 注:上图为mysql使用内存计算器,具体地址为http://www.mysqlcalculator.com/ )
其中左列为mysql默认配置,右列为当前数据库的配置,可见预期内存使用最大值足足达到了1T,不符合当前系统负载量,说明当前配置不合理,需要进行调整
(3).其中
key_buffer_size = 32M //key_buffer_size指定索引缓冲区的大小,它决定索引处理的速度,尤其是索引读的速度。只对MyISAM表起作用。即使你不使用MyISAM表,但是内部的临时磁盘表是MyISAM表,也要使用该值。由于我的数据库引擎为innodb,大部分表均为innodb,此处取默认值一半32M。
query_cache_size = 64M //查询缓存大小,当打开时候,执行查询语句会进行缓存,读写都会带来额外的内存消耗,下次再次查询若命中该缓存会立刻返回结果。默认改选项为关闭,打开则需要调整参数项query_cache_type=ON。此处采用默认值64M。
tmp_table_size = 64M //范围设置为64-256M最佳,当需要做类似group by操作生成的临时表大小,提高联接查询速度的效果,调整该值直到created_tmp_disk_tables / created_tmp_tables * 100% <= 25%,处于这样一个状态之下,效果较好,如果网站大部分为静态内容,可设置为64M,如果为动态页面,则设置为100M以上,不宜过大,导致内存不足I/O堵塞。此处我们设置为64M。
innodb_buffer_pool_size = 8196M //这个参数主要作用是缓存innodb表的索引,数据,插入数据时的缓冲。专用mysql服务器设置的大小: 操作系统内存的70%-80%最佳。由于我们的服务器还部署有其他应用,估此处设置为8G。此外,这个参数是非动态的,要修改这个值,需要重启mysqld服务。设置的过大,会导致system的swap空间被占用,导致操作系统变慢,从而减低sql查询的效率。
innodb_additional_mem_pool_size = 16M //用来存放Innodb的内部目录,这个值不用分配太大,系统可以自动调。不用设置太高。通常比较大数据设置16M够用了,如果表比较多,可以适当的增大。如果这个值自动增加,会在error log有中显示的。此处我们设置为16M。
innodb_log_buffer_size = 8M //InnoDB的写操作,将数据写入到内存中的日志缓存中,由于InnoDB在事务提交前,并不将改变的日志写入到磁盘中,因此在大事务中,可以减轻磁盘I/O的压力。通常情况下,如果不是写入大量的超大二进制数据(a lot of huge blobs),4MB-8MB已经足够了。此处我们设置为8M。
max_connections = 800 //最大连接数,根据同时在线人数设置一个比较综合的数字,最大不超过16384。此处我们根据系统使用量综合评估,设置为800。
sort_buffer_size = 2M //是一个connection级参数,在每个connection第一次需要使用这个buffer的时候,一次性分配设置的内存。并不是越大越好,由于是connection级的参数,过大的设置+高并发可能会耗尽系统内存资源。官方文档推荐范围为256KB~2MB,这里我们设置为2M。
read_buffer_size = 2M //(数据文件存储顺序)是MySQL读入缓冲区的大小,将对表进行顺序扫描的请求将分配一个读入缓冲区,MySQL会为它分配一段内存缓冲区,read_buffer_size变量控制这一缓冲区的大小,如果对表的顺序扫描非常频繁,并你认为频繁扫描进行的太慢,可以通过增加该变量值以及内存缓冲区大小提高其性能,read_buffer_size变量控制这一提高表的顺序扫描的效率 数据文件顺序。此处我们设置得比默认值大一点,为2M。
read_rnd_buffer_size = 250K //是MySQL的随机读缓冲区大小,当按任意顺序读取行时(列如按照排序顺序)将分配一个随机读取缓冲区,进行排序查询时,MySQL会首先扫描一遍该缓冲,以避免磁盘搜索,提高查询速度,如果需要大量数据可适当的调整该值,但MySQL会为每个客户连接分配该缓冲区所以尽量适当设置该值,以免内存开销过大。表的随机的顺序缓冲 提高读取的效率。此处设置为跟默认值相似,250KB。
join_buffer_size = 250K //多表参与join操作时的分配缓存,适当分配,降低内存消耗,此处我们设置为250KB。
thread_stack = 256K //每个连接线程被创建时,MySQL给它分配的内存大小。当MySQL创建一个新的连接线程时,需要给它分配一定大小的内存堆栈空间,以便存放客户端的请求的Query及自身的各种状态和处理信息。Thread Cache 命中率:Thread_Cache_Hit = (Connections - Threads_created) / Connections * 100%;命中率处于90%才算正常配置,当出现“mysql-debug: Thread stack overrun”的错误提示的时候需要增加该值。此处我们配置为256K。
binlog_cache_size = 250K // 为每个session 分配的内存,在事务过程中用来存储二进制日志的缓存。作用是提高记录bin-log的效率。没有什么大事务,dml也不是很频繁的情况下可以设置小一点,如果事务大而且多,dml操作也频繁,则可以适当的调大一点。前者建议是1048576 --1M;后者建议是: 2097152 -- 4194304 即 2--4M。此处我们根据系统实际,配置为250KB。
调整后各项性能参数如下图,且经过图表计算,实例使用的内存将稳定在12G左右,符合当前系统负载情况

之后重启Mysql实例,发现内存占用量回落,并且长时间内没有再次发生占用过高情况,优化成功。
三.总结:
具体涉及到内存分配,缓存的参数及其具体作用在此不一一赘述,后续可自行查阅相关资料,只有多次根据实际观测结果调优,才能得到符合当前业务系统运行的最佳配置。
---------------------
原文:https://blog.csdn.net/dc666/article/details/78901341
mysql内存优化的更多相关文章
- MYSQL进阶学习笔记十三:MySQL 内存优化!(视频序号:进阶_31)
知识点十四:MySQL 内存的优化(31) 一.优化MySQL SERVER 7组后台进程: masterthread:主要负责将脏缓存页刷新到数据文件,执行purge操作,触发检查点,合并插入缓冲区 ...
- 十八、mysql 内存优化 之 myisam
.key_buffer 索引块大小 set global hot_cache.key_buffer_size = ; //设置大小 show variables like 'key_buffer_si ...
- mySQL内存及虚拟内存优化设置[转]
mySQL内存及虚拟内存优化设置 . 数据库mySQL内存优化G-LB 为了装mysql环境测试,装上后发现启动后mysql占用了很大的虚拟内存,达8百多兆.网上搜索了一下,得到高人指点my.ini ...
- 4G内存服务器的MySQL配置优化
公司网站访问量越来越大(日均超10万PV),MySQL自然成为瓶颈,关于 MySQL 的优化,最基本的是 MySQL 系统参数的优化. MySQL对于web架构性能的影响最大,也是关键的核心部分.My ...
- 「mysql优化专题」详解引擎(InnoDB,MyISAM)的内存优化攻略?(9)
注意:以下都是在MySQL目录下的my.ini文件中改写(技术文). 一.InnoDB内存优化 InnoDB用一块内存区域做I/O缓存池,该缓存池不仅用来缓存InnoDB的索引块,而且也用来缓存Inn ...
- Mysql的内存优化
老师 vi mysqld_safe# executing mysqld_safe 后面增加export LD_PRELOAD=/usr/local/lib/libtcmalloc.so 可以做一 ...
- MySQL性能优化-内存参数配置
Mysql对于内存的使用,可以分为两类,一类是我们无法通过配置参数来配置的,如Mysql服务器运行.解析.查询以及内部管理所消耗的内存:另一类如缓冲池所用的内存等. Mysql内存参数的配置及重要,设 ...
- 试试SQLSERVER2014的内存优化表
试试SQLSERVER2014的内存优化表 SQL Server 2014中的内存引擎(代号为Hekaton)将OLTP提升到了新的高度. 现在,存储引擎已整合进当前的数据库管理系统,而使用先进内存技 ...
- Mysql性能优化三(分表、增量备份、还原)
接上篇Mysql性能优化二 对表进行水平划分 如果一个表的记录数太多了,比如上千万条,而且需要经常检索,那么我们就有必要化整为零了.如果我拆成100个表,那么每个表只有10万条记录.当然这需要数据在逻 ...
随机推荐
- 函数柯里化与偏函数+bind
简单理解: 1,函数柯里化就是把多参数函数分解为多return的单参数函数: 举个例子(伪代码): function func (a, b, c){ return } 柯里化为 function fu ...
- 整个系统禁用复制功能下,js实现部分数据的复制功能
需求背景:整个系统禁止复制,列表页操作栏新增按钮来复制数据列的手机号功能 感受下是怎么回事?看下效果 (GIF有点点烂)
- iReport 3.7.6 jasperreport 生成PDF汉字不显示问题的解决
1.下载iTextAsian.jar 下载地址:https://www.oschina.net/action/code/download?code=51668&id=75706 2.在Irep ...
- LeetCode 76. 最小覆盖子串(Minimum Window Substring)
题目描述 给定一个字符串 S 和一个字符串 T,请在 S 中找出包含 T 所有字母的最小子串. 示例: 输入: S = "ADOBECODEBANC", T = "ABC ...
- 用Python写一个将Python2代码转换成Python3代码的批处理工具
之前写过一篇如何在windows操作系统上给.py文件添加一个快速处理的右键功能的文章:<一键将Python2代码自动转化为Python3>,作用就是为了将Python2的文件升级转换成P ...
- Java访问Oracle服务器
Java访问Oracle服务器--orcl数据库---emp表 private static String driver = "oracle.jdbc.driver.Orac ...
- 002-tomcat目录简介、应用部署【自动部署 ② 控制台部署 ③ 自定义部署】
一.目录及功能 主目录下有bin,conf,lib,logs,temp,webapps,work 7个文件夹 1.1.bin目录[重要] bin目录主要是用来存放tomcat的命令,主要有两大类,一类 ...
- CentOS8 安装 simple-scan 的方法
CentOS8删除了很多软件包,解决的思路一般是从CentOS7或EPEL7的软件仓库中寻找,并解决依赖关系. 比如找到EPEL7中有 simple-scan 软件包,但安装时发现其又依赖 gnome ...
- centos7.2 apollo1.7.1的搭建
1.准备工作 第一步:linux系统中配置好java环境安装参考地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-down ...
- 【CSS】聊一聊css的选择器
对于css来说,他的基本语法就是 选择器 { K:V; K:V; K:V } 所以css的学习就分为两个部分: * 1 选择器 ...