Linux Kafka源码环境搭建
本文主要讲述的是如何搭建Kafka的源码环境,主要针对的Linux操作系统下IntelliJ IDEA编译器,其余操作系统或者IDE可以类推。
1.安装和配置JDK
确认JDK版本至少为1.7,最好是1.8及以上。使用java -version命令来查看当前JDK的版本,示例如下:
lenmom@M1701:~/workspace/software/hadoop-2.7./bin$ java -version
java version "1.8.0_191"
Java(TM) SE Runtime Environment (build 1.8.0_191-b12)
Java HotSpot(TM) -Bit Server VM (build 25.191-b12, mixed mode)
2.下载并安装配置Gradle
下载地址为:https://gradle.org/releases/,本人使用的版本是5.2.1(官方在kafka2.1.0的源码中使用的是4.10.2版本,本人在linux上使用5.2.1版本是成功的,但是在windows上是失败的,如果在windows上进行搭建,建议采用4.10.2版本)。一般只需要将下载的包解压,然后再将$GRADLE_HOME/bin的路径添加到环境变量Path中即可,其中$GRADLE_HOME指的是Gradle的根目录。可以使用gradle -v命令来验证Gradle是否已经配置完成,示例如下:
wget https://downloads.gradle.org/distributions/gradle-5.2.1-bin.zip
unzip gradle-5.2.-bin.zip -C /home/lenmom/software/
配置环境变量
vim /etc/profile
添加以下内容
export GRADLE_HOME=/home/lenmom/software/grandle-5.2.
export PATH=$GRADLE_HOME/bin:$PATH
保存退出,source /etc/profile使环境变量生效
3.下载并安装配置Scala
下载地址为:http://www.scala-lang.org/download/all.html,目前最新的版本是2.12.8,不过笔者这里使用的版本是2.11.8。如Gradle一样,只需要解压并将$SCALA_HOME/bin的路径添加到环境变量Path即可,其中$SCALA_HOME指的是Scala的根目录。可以使用scala -version命令来验证scala是否已经配置完成,示例如下:
lenmom@M1701:~/workspace/software/hadoop-2.7./bin$ scala -version
Scala code runner version 2.11. -- Copyright -, LAMP/EPFL
4. 构建Kafka源码环境
Kafka下载地址为:http://kafka.apache.org/downloads,目前最新的版本是2.10。将下载的压缩包解压,并在Kafka的根目录执行gradle idea命令进行构建,如果你使用的是Eclipse,则只需采用gradle eclipse命令构建即可。构建细节如下所示:
lenmom@M1701:~/workspace/open-source/kafka-2.1.-src$ gradle idea
Starting a Gradle Daemon (subsequent builds will be faster) > Configure project :
Building project 'core' with Scala version 2.11.
Building project 'streams-scala' with Scala version 2.11. > Task :idea
Generated IDEA project at file:///home/lenmom/workspace/open-source/kafka-2.1.0-src/kafka-2.1.0-src.ipr Deprecated Gradle features were used in this build, making it incompatible with Gradle 6.0.
Use '--warning-mode all' to show the individual deprecation warnings.
See https://docs.gradle.org/5.2.1/userguide/command_line_interface.html#sec:command_line_warnings BUILD SUCCESSFUL in 19m 51s
actionable tasks: executed
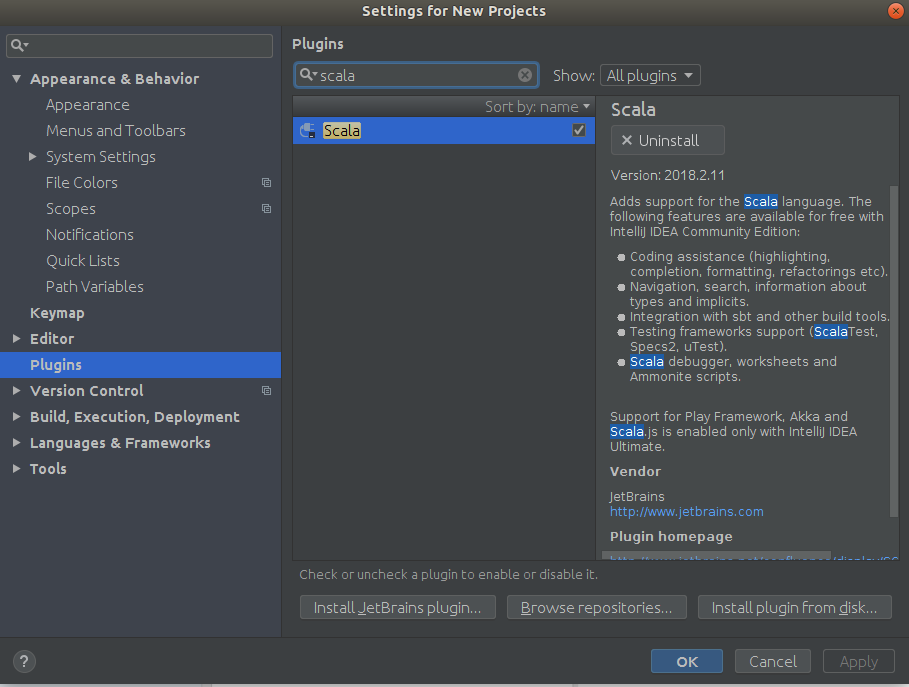
之后将Kafka导入到IDEA中即可。不过这样还没有结束,对于IDEA而言,还需要安装Scala插件,在Setting->Plugin中搜索scala并安装,可以参考下图,笔者这里是已经安装好的状态:
5. 修改kafka_source_home/ gradle.properties中的scala版本
vim /home/lenmom//workspace/open-source/kafka-2.1.0-src/gradle.properties
将其中的scalaVersion改为2.11.8,原来是2.11.11

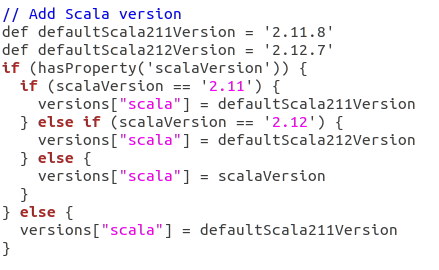
修改 /home/lenmom/workspace/open-source/kafka-2.1.0-src/gradle/dependencies.gradle scala版本
/home/lenmom/workspace/open-source/kafka-2.1.-src/gradle/dependencies.gradle
将其中的def defaultScala211Version = '2.11.11'改为def defaultScala211Version = '2.11.8'
如果更改了scalaVersion,需要重新执行gradle idea命令来重新构建。虽然很多时候在操作系统中安装其他版本的Scala也并没有什么问题,比如安装2.12.12版本。但是有些情况下运行Kafka时会出现一些异常,而这些异常却又是由于Scala版本不一致而引起的,比如会出现下面示例中的报错:
[2019-02-10 17:09:21,119] FATAL (kafka.Kafka$)
java.lang.NoSuchMethodError: scala.collection.TraversableOnce.$init$(Lscala/collection/TraversableOnce;)V
at kafka.message.MessageSet.<init>(MessageSet.scala:72)
at kafka.message.ByteBufferMessageSet.<init>(ByteBufferMessageSet.scala:129)
at kafka.message.MessageSet$.<init>(MessageSet.scala:32)
at kafka.message.MessageSet$.<clinit>(MessageSet.scala)
at kafka.server.Defaults$.<init>(KafkaConfig.scala:52)
at kafka.server.Defaults$.<clinit>(KafkaConfig.scala)
at kafka.server.KafkaConfig$.<init>(KafkaConfig.scala:686)
at kafka.server.KafkaConfig$.<clinit>(KafkaConfig.scala)
at kafka.server.KafkaServerStartable$.fromProps(KafkaServerStartable.scala:28)
at kafka.Kafka$.main(Kafka.scala:82)
at kafka.Kafka.main(Kafka.scala)
所以为了省去一些不必要的麻烦,还是建议读者在安装Scala版本之前先查看下Kafka源码中gradle.properties文件中配置的scalaVersion。
6. 配置Kafka源码环境
6.1 在确保了scalaVersion之后,需要将config目录下的log4j.properties文件拷贝到core/src/main/scala目录下,这样可以让Kafka在运行时能够输出日志信息
cp /home/lenmom/workspace/open-source/kafka-2.1.-src/config/log4j.properties /home/lenmom/workspace/open-source/kafka-2.1.-src/core/src/main/scala/
6.2 配置server.properties文件,一般只需要修改以下一些配置项
# 是否允许topic被删除,设置为true则topic可以被删除,
# 开启这个功能方便Kafka在运行一段时间之后,能够删除一些不需要的临时topic
delete.topic.enable=true
# 禁用自动创建topic的功能
auto.create.topics.enable=false
# 存储log文件的目录,默认值为/tmp/kafka-logs
# 示例是在Windows环境下运行,所以需要修改这个配置,注意这里的双反斜杠。
log.dir=/home/lenmom/workspace/open-source/kafka-2.1.-src/kafka-logs # 配置kafka依赖的zookeeper路径地址,这里的前提是在本地开启了一个zookeeper的服务
zookeeper.connect=localhost:
6.3 创建kafka日志保存目录
mkdir /home/lenmom/workspace/open-source/kafka-2.1.-src/kafka-logs
6.4 确保zookeeper已经启动
zookeeper的安装与启动请参见本人的前期博文
6.5 启动kafka
配置参数:
Main class:
kafka.Kafka VM options:
-Dkafka.logs.dir=/home/lenmom/workspace/open-source/kafka-2.1.-src/logs
-Dlog4j.configuration=file:/home/lenmom/workspace/open-source/kafka-2.1.-src/config/log4j.properties Program arguments:
/home/lenmom/workspace/open-source/kafka-2.1.-src/config/server.properties Enviroment variables:
JMX_PORT= Use classpath of module:
Core_main
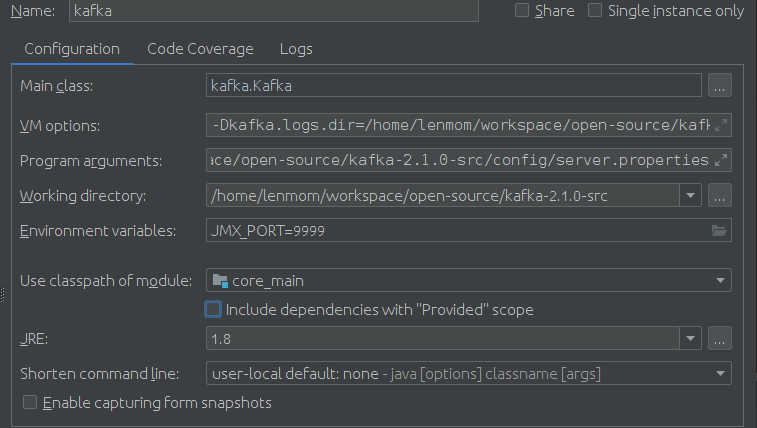
这里配置Main class为kafka.Kafka,并制定启动时所需要的配置文件地址,即:config/server.properties。配置JMX_PORT是为了方便搜集Kafka自身的Metrics数据。
如此便可以顺利的运行Kafka服务了(第一次启动时会有一个耗时较长的编译过程),部分启动日志如下:
zookeeper.session.timeout.ms =
zookeeper.set.acl = false
zookeeper.sync.time.ms =
(kafka.server.KafkaConfig)
[-- ::,] INFO [ThrottledChannelReaper-Fetch]: Starting (kafka.server.ClientQuotaManager$ThrottledChannelReaper)
[-- ::,] INFO [ThrottledChannelReaper-Produce]: Starting (kafka.server.ClientQuotaManager$ThrottledChannelReaper)
[-- ::,] INFO [ThrottledChannelReaper-Request]: Starting (kafka.server.ClientQuotaManager$ThrottledChannelReaper)
[-- ::,] INFO Loading logs. (kafka.log.LogManager)
[-- ::,] INFO Logs loading complete in ms. (kafka.log.LogManager)
[-- ::,] INFO Starting log cleanup with a period of ms. (kafka.log.LogManager)
[-- ::,] INFO Starting log flusher with a default period of ms. (kafka.log.LogManager)
[-- ::,] INFO Awaiting socket connections on 0.0.0.0:. (kafka.network.Acceptor)
[-- ::,] INFO [SocketServer brokerId=] Started acceptor threads (kafka.network.SocketServer)
[-- ::,] INFO [ExpirationReaper--Produce]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper)
[-- ::,] INFO [ExpirationReaper--Fetch]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper)
[-- ::,] INFO [ExpirationReaper--DeleteRecords]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper)
[-- ::,] INFO [LogDirFailureHandler]: Starting (kafka.server.ReplicaManager$LogDirFailureHandler)
[-- ::,] INFO Creating /brokers/ids/ (is it secure? false) (kafka.zk.KafkaZkClient)
[-- ::,] INFO Result of znode creation at /brokers/ids/ is: OK (kafka.zk.KafkaZkClient)
[-- ::,] INFO Registered broker at path /brokers/ids/ with addresses: ArrayBuffer(EndPoint(M1701,,ListenerName(PLAINTEXT),PLAINTEXT)) (kafka.zk.KafkaZkClient)
[-- ::,] INFO [ExpirationReaper--topic]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper)
[-- ::,] INFO [ExpirationReaper--Heartbeat]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper)
[-- ::,] INFO [ExpirationReaper--Rebalance]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper)
[-- ::,] INFO [GroupCoordinator ]: Starting up. (kafka.coordinator.group.GroupCoordinator)
[-- ::,] INFO [GroupMetadataManager brokerId=] Removed expired offsets in milliseconds. (kafka.coordinator.group.GroupMetadataManager)
[-- ::,] INFO [GroupCoordinator ]: Startup complete. (kafka.coordinator.group.GroupCoordinator)
[-- ::,] INFO [ProducerId Manager ]: Acquired new producerId block (brokerId:,blockStartProducerId:,blockEndProducerId:) by writing to Zk with path version (kafka.coordinator.transaction.ProducerIdManager)
[-- ::,] INFO [TransactionCoordinator id=] Starting up. (kafka.coordinator.transaction.TransactionCoordinator)
[-- ::,] INFO [Transaction Marker Channel Manager ]: Starting (kafka.coordinator.transaction.TransactionMarkerChannelManager)
[-- ::,] INFO [TransactionCoordinator id=] Startup complete. (kafka.coordinator.transaction.TransactionCoordinator)
[-- ::,] INFO [/config/changes-event-process-thread]: Starting (kafka.common.ZkNodeChangeNotificationListener$ChangeEventProcessThread)
[-- ::,] INFO [SocketServer brokerId=] Started processors for acceptors (kafka.network.SocketServer)
[-- ::,] WARN Error while loading kafka-version.properties :null (org.apache.kafka.common.utils.AppInfoParser)
[-- ::,] INFO Kafka version : unknown (org.apache.kafka.common.utils.AppInfoParser)
[-- ::,] INFO Kafka commitId : unknown (org.apache.kafka.common.utils.AppInfoParser)
[-- ::,] INFO [KafkaServer id=] started (kafka.server.KafkaServer)
[-- ::,] WARN Client session timed out, have not heard from server in 4179ms for sessionid 0x1000144f4a50007 (org.apache.zookeeper.ClientCnxn)
[-- ::,] INFO Client session timed out, have not heard from server in 4179ms for sessionid 0x1000144f4a50007, closing socket connection and attempting reconnect (org.apache.zookeeper.ClientCnxn)
[-- ::,] INFO Opening socket connection to server localhost/127.0.0.1:. Will not attempt to authenticate using SASL (unknown error) (org.apache.zookeeper.ClientCnxn)
[-- ::,] INFO Socket connection established to localhost/127.0.0.1:, initiating session (org.apache.zookeeper.ClientCnxn)
[-- ::,] INFO Session establishment complete on server localhost/127.0.0.1:, sessionid = 0x1000144f4a50007, negotiated timeout = (org.apache.zookeeper.ClientCnxn)
如果出现:
Failed to load class "org.slf4j.impl.StaticLoggerBinder" 错误消息,解决办法为:
下载
log4j-1.2.17.jar
slf4j-api-1.7.25.jar
slf4j-log4j12-1.7.25.jar
并在File->Project Structure->Project Settings>Modules->core->core_main->Dependencies,添加这几个jar包为依赖项。
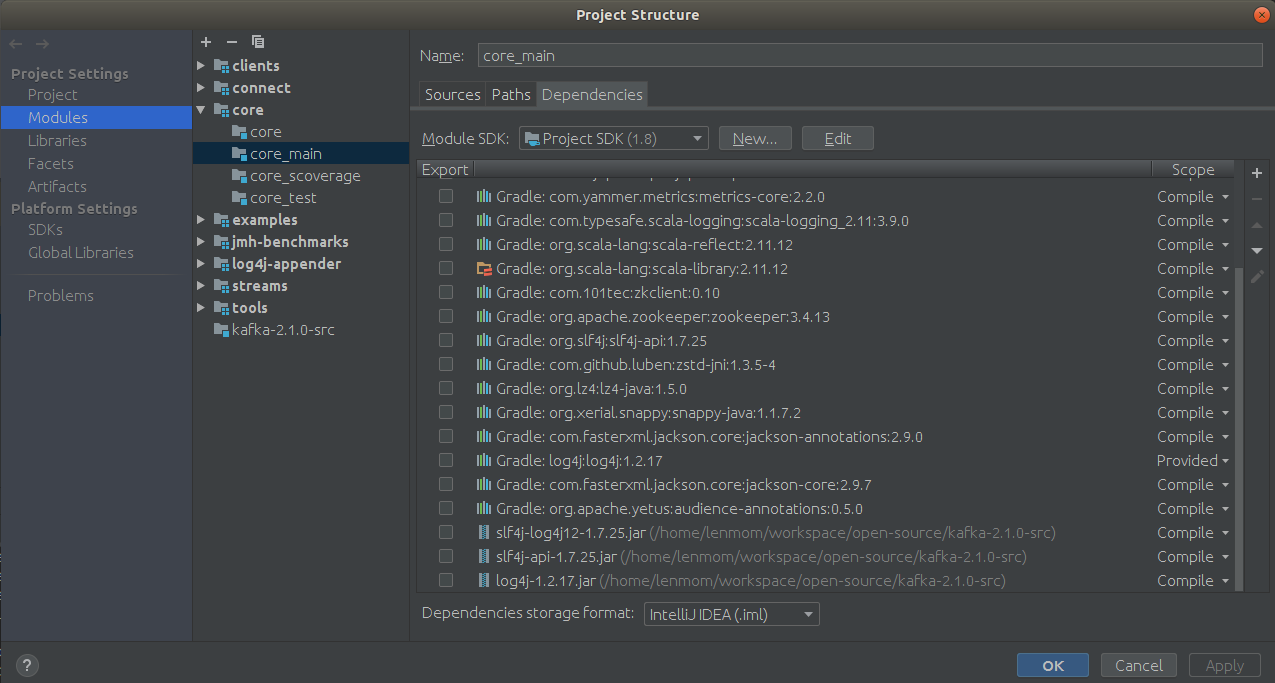
本人在windows上按照这个操作亦成功搭建起了调试环境

or using command line, which skip runing tests and checkstyle validation:
gradle build -x test -x checkstyleMain -x checkstyleTest -x checkstyleScoverage -x spotbugsMain
Linux Kafka源码环境搭建的更多相关文章
- Kafka源码环境搭建
github地址:https://github.com/apache/kafka clone下来之后可以看到这样的项目结构: 文件目录说明. 目录 描述 bin Windows 和 Linux 下 K ...
- 使用IntelliJ IDEA搭建kafka源码环境时遇到Output path错误解决办法
kafka源码环境搭建好之后,需要在IntelliJ IDEA开发工具中以debug方式启动kafka服务器来测试消息的生产和消费. 但是在启动kafka.Kafka类中的main方法(也就是运行 k ...
- windows下IntelliJ IDEA搭建kafka源码环境
于kafka核心原理的资料,网上有很多,但是如果不自己研究其源码,永远是知其然而不知所以然.下面就来演示如何在windows环境下来编译kafka源码,并通过IntelliJ IDEA开发工具搭建ka ...
- 【ZooKeeper系列】3.ZooKeeper源码环境搭建
前文阅读: [ZooKeeper系列]1.ZooKeeper单机版.伪集群和集群环境搭建 [ZooKeeper系列]2.用Java实现ZooKeeper API的调用 在系列的前两篇文章中,介绍了Zo ...
- MyBatis源码环境搭建
之前研究mybatis都是参考前面学习的人的一些经验,并没有自己搭建源码环境进行.现在以mybatis3.4.6版本搭建,搭建过程中各种failed,下面大致记录环境搭建过程. 1.mybatis3. ...
- 1-web应用之LAMP源码环境搭建
目录 一.LAMP环境的介绍 1.LAMP环境的重要性 2.LAMP组件介绍 二.Apache源码安装 1.下载Apache以及相关依赖包 2.安装Apache以及相关 ...
- Hadoop源码学习笔记之NameNode启动场景流程一:源码环境搭建和项目模块及NameNode结构简单介绍
最近在跟着一个大佬学习Hadoop底层源码及架构等知识点,觉得有必要记录下来这个学习过程.想到了这个废弃已久的blog账号,决定重新开始更新. 主要分以下几步来进行源码学习: 一.搭建源码阅读环境二. ...
- 【一步一步】Spring 源码环境搭建
平时项目中基本上都会用到spring,但是源码还没有深入的了解过.趁这段时间稍微空闲点,开始研究下spring 源码.下面是spring 源码的环境搭建. 主要分为如下步骤: ①安装jdk,gradl ...
- Spring源码阅读 源码环境搭建(一)
ring 源码阅读的搭建(一) 一 下载spring源码 进入官方网页:https://spring.io/projects/spring-framework 进入相关的github位置,下载zip包 ...
随机推荐
- zsh:no matches found 问题解决
解决方法: ~/.zshrc 文件加入: setopt no_nomatch 之后,更新配置 source ~/.zshrc
- html+css常用总结
一,HTML结构: 1,DOCTYPE 2,head: title:网站的标题 meta charset 3,body: 二,HTML标签: 块状元素和内联元素: 常见的块级元素有:div.p.add ...
- SimpleEntity
项目地址 : https://github.com/kelin-xycs/SimpleEntity SimpleEntity 一个 用 C# 实现的 简单的 持久层 Entity 实现 . 这是一个 ...
- linux 自总结常用命令(centos系统)
查看apache2的命令 httpd -V 其中HTTPD_ROOT和SERVER_CONFIG_FILE 就可以确定httpd.conf(Apache配置文件)的路径了 apache启动.停止.重 ...
- 从Excel文件中读取内容
从Excel文件中读取内容 global::System.Web.HttpPostedFileBase file = Request.Files["txtFile"]; strin ...
- Centos 使用find查找
CentOS查找目录或文件 find / -name svn 查找目录:find /(查找范围) -name '查找关键字' -type d查找文件:find /(查找范围) -name 查找关键字 ...
- ByteType字符串中判断是否英文
ByteType('123你好吗',1)=mbSingleByte//单字节ByteType('123你好吗',4)=mbLeadByte//双字节字符的第一个字符ByteType('123你好吗', ...
- IO练习文件读取
import java.io.*; public class CheckFile { private File f ; private BufferedReader bdr; private char ...
- html框内文字垂直居中的方法
由于无法知道框内文字的高度,很难确定垂直空间的位置.vertical-align:middle仅对td元素有效,无论单行和多行均可实现垂直居中.
- elasticsearch mapping demo
curl -XPUT localhost:9200/local -d '{ "settings" : { "analysis" : { "analyz ...