LRN
转自https://blog.csdn.net/u011204487/article/details/76026537
LRN全称为Local Response Normalization,即局部响应归一化层,具体实现在CAFFE_ROOT/src/caffe/layers/lrn_layer.cpp和同一目录下lrn_layer.cu中。
为什么输入数据需要归一化(Normalized Data)?
归一化后有什么好处呢?原因在于神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们需要对数据都要做一个归一化预处理的原因。
对于深度网络的训练是一个复杂的过程,只要网络的前面几层发生微小的改变,那么后面几层就会被累积放大下去。一旦网络某一层的输入数据的分布发生改变,那么这一层网络就需要去适应学习这个新的数据分布,所以如果训练过程中,训练数据的分布一直在发生变化,那么将会影响网络的训练速度。
该层需要参数有:
norm_region: 选择对相邻通道间归一化还是通道内空间区域归一化,默认为ACROSS_CHANNELS,即通道间归一化;
local_size:两种表示(1)通道间归一化时表示求和的通道数;(2)通道内归一化时表示求和区间的边长;默认值为5;
alpha:缩放因子(详细见后面),默认值为1;
beta:指数项(详细见后面), 默认值为5;
局部响应归一化层完成一种“临近抑制”操作,对局部输入区域进行归一化。
在通道间归一化模式中,局部区域范围在相邻通道间,但没有空间扩展(即尺寸为 local_size x 1 x 1);
在通道内归一化模式中,局部区域在空间上扩展,但只针对独立通道进行(即尺寸为 1 x local_size xlocal_size);
每个输入值都将除以
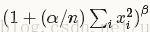
[写作时的 Caffe版本较旧,新版 Caffe已经增加参数 k,变为(k + (alpha / n) ……))]
其中n为局部尺寸大小local_size, alpha和beta前面已经定义。
求和将在当前值处于中间位置的局部区域内进行(如果有必要则进行补零)。
LRN的更多相关文章
- 深度学习原理与框架-Tensorflow卷积神经网络-cifar10图片分类(代码) 1.tf.nn.lrn(局部响应归一化操作) 2.random.sample(在列表中随机选值) 3.tf.one_hot(对标签进行one_hot编码)
1.tf.nn.lrn(pool_h1, 4, bias=1.0, alpha=0.001/9.0, beta=0.75) # 局部响应归一化,使用相同位置的前后的filter进行响应归一化操作 参数 ...
- LRN和Batch Norm
LRN LRN全称为Local Response Normalization,局部相应归一化层. message LRNParameter { optional uint32 local_size = ...
- LRN(local response normalization--局部响应标准化)
LRN全称为Local Response Normalization,即局部响应归一化层,LRN函数类似DROPOUT和数据增强作为relu激励之后防止数据过拟合而提出的一种处理方法.这个函数很少使用 ...
- 局部响应归一化(Local Response Normalization,LRN)
版权声明:本文为博主原创文章,欢迎转载,注明地址. https://blog.csdn.net/program_developer/article/details/79430119 一.LRN技术介 ...
- caffe Python API 之LRN
net.mylrn = caffe.layers.LRN(net.pool1,local_size=5,alpha=1e-4,beta=0.75) 输出: layer { name: "my ...
- 在AlexNet中LRN 局部响应归一化的理
在AlexNet中LRN 局部响应归一化的理 一.LRN技术介绍: Local Response Normalization(LRN)技术主要是深度学习训练时的一种提高准确度的技术方法.其中caffe ...
- caffe中的Local Response Normalization (LRN)有什么用,和激活函数区别
http://stats.stackexchange.com/questions/145768/importance-of-local-response-normalization-in-cnn ca ...
- java web学习总结(五) -------------------servlet开发(一)
一.Servlet简介 Servlet是sun公司提供的一门用于开发动态web资源的技术. Sun公司在其API中提供了一个servlet接口,用户若想用发一个动态web资源(即开发一个Java程序向 ...
- python读取caffemodel文件
caffemodel是二进制的protobuf文件,利用protobuf的python接口可以读取它,解析出需要的内容 不少算法都是用预训练模型在自己数据上微调,即加载"caffemodel ...
随机推荐
- SSIS 连接数据
通常情况下,ETL方案需要同时访问两个或多个数据源,并把结果合并为单个数据流,输出到目标表中.为了向目标表中提供统一的数据结构,需要把多个数据源连接在一起.数据连接的另外一种用法,就是根据现有的数据, ...
- R语言学习 第四篇:函数和流程控制
变量用于临时存储数据,而函数用于操作数据,实现代码的重复使用.在R中,函数只是另一种数据类型的变量,可以被分配,操作,甚至把函数作为参数传递给其他函数.分支控制和循环控制,和通用编程语言的风格很相似, ...
- OLEDB 命令转换组件的用法
在数据流任务组件中,OLEDB 命令转换组件对输入的每行数据调用TSQL,该组件能够把输入的数据作为参数,因此,该转换组件主要用于运行参数化的查询. 命令转换组件的配置十分简单,只有三个可编辑属性,位 ...
- NodeJS旅程 : express - nodejs MVC 中的王牌
express 正如ASP.NET MVC 在作为.net平台下最佳的 Mvc框架的地位一样,express在 node.js 环境也有着相同的重要性.在百度上 "nodejs expres ...
- JQ_One()函数特效
先看一个例子,当点击 p 元素时,增加该元素的文本大小,代码如下:<script type="text/javascript" src="http://keleyi ...
- 关于UNITY学习,给新生建议
没有不可能,只有不努力. 本人自学UNITY,实力不敢称最好,但绝对不是小白,自己独立做出过游戏,AR.(用C#) 1. 导入模型一定要注意坐标,否则会很麻烦.本人因为这个吃了很多盐 2. 学unit ...
- 290. Word Pattern【LeetCode by java】
今天发现LintCode页面刷新不出来了,所以就转战LeetCode.还是像以前一样,做题顺序:难度从低到高,每天至少一题. Given a pattern and a string str, fin ...
- PHP密码的六种加密方式
1. MD5加密 string md5 ( string $str [, bool $raw_output = false ] ) 参数 str -- 原始字符串. raw_output -- ...
- group by 和count的联合使用问题 [转]
group by 和count的联合使用问题 今天写查询语句遇到一个问题,就是用group by进行分组以后,用count统计分组以后的个数, 开始写的语句大体是: select count(m.fb ...
- linux第四章笔记
第四章 进程调度 调度程序负责决定将哪个进程投入运行,何时运行以及运行多长时间.进程调度程序可看做在可运行态进程之间分配有限的处理器时间资源的内核子系统. 最大限度利用处理器时间的原则:只要有可以执行 ...