Deep learning with Python 学习笔记(6)
本节介绍循环神经网络及其优化
循环神经网络(RNN,recurrent neural network)处理序列的方式是,遍历所有序列元素,并保存一个状态(state),其中包含与已查看内容相关的信息。在处理两个不同的独立序列(比如两条不同的 IMDB 评论)之间,RNN 状态会被重置,因此,你仍可以将一个序列看作单个数据点,即网络的单个输入。真正改变的是,数据点不再是在单个步骤中进行处理,相反,网络内部会对序列元素进行遍历,RNN 的特征在于其时间步函数
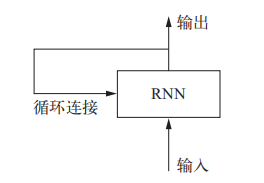
Keras 中的循环层
from keras.layers import SimpleRNN
它接收形状为 (batch_size, timesteps, input_features) 的输入
与 Keras 中的所有循环层一样,SimpleRNN 可以在两种不同的模式下运行:一种是返回每个时间步连续输出的完整序列,即形状为 (batch_size, timesteps, output_features)的三维张量;另一种是只返回每个输入序列的最终输出,即形状为 (batch_size, output_features) 的二维张量。这两种模式由return_sequences 这个构造函数参数来控制。为了提高网络的表示能力,将多个循环层逐个堆叠有时也是很有用的。在这种情况下,你需要让所有中间层都返回完整的输出序列,即将return_sequences设置为True
简单Demo with SimpleRNN
from keras.datasets import imdb
from keras.preprocessing import sequence
from keras.layers import Dense, Embedding, SimpleRNN
from keras.models import Sequential
import matplotlib.pyplot as plt
max_features = 10000
maxlen = 500
batch_size = 32
(input_train, y_train), (input_test, y_test) = imdb.load_data(num_words=max_features, path='E:\\study\\dataset\\imdb.npz')
print(len(input_train), 'train sequences')
print(len(input_test), 'test sequences')
print('Pad sequences (samples x time)')
input_train = sequence.pad_sequences(input_train, maxlen=maxlen)
input_test = sequence.pad_sequences(input_test, maxlen=maxlen)
print('input_train shape:', input_train.shape)
print('input_test shape:', input_test.shape)
# 用 Embedding 层和 SimpleRNN 层来训练模型
model = Sequential()
model.add(Embedding(max_features, 32))
model.add(SimpleRNN(32))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(input_train, y_train, epochs=10, batch_size=128, validation_split=0.2)
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
结果
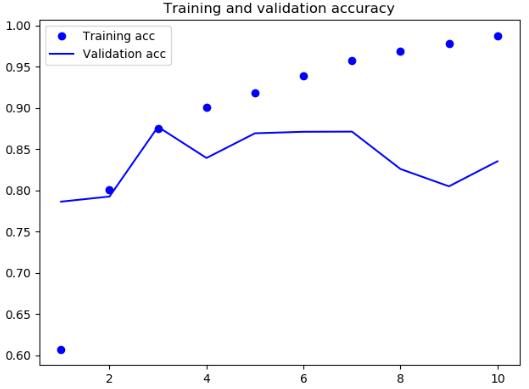
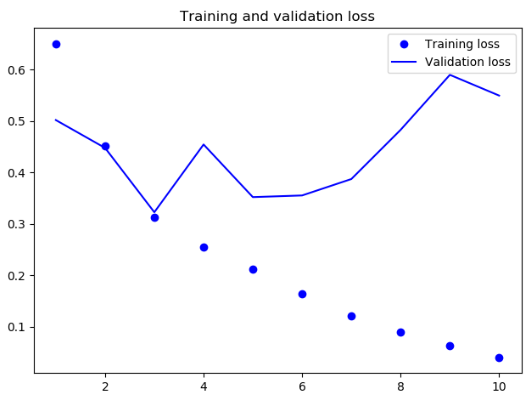
Keras同时还内置了另外两个循环层:**LSTM **和 GRU
SimpleRNN 的最大问题不能学到长期依赖,其原因在于梯度消失问题。LSTM 层和 GRU 层都是为了解决这个问题而设计的
LSTM(long short-term memory)层是 SimpleRNN 层的一种变体,它增加了一种携带信息跨越多个时间步的方法,保存信息以便后面使用,从而防止较早期的信号在处理过程中逐渐消失
简单Demo with LSTM
from keras.datasets import imdb
from keras.preprocessing import sequence
from keras.layers import Dense, Embedding, LSTM
from keras.models import Sequential
import matplotlib.pyplot as plt
max_features = 10000
maxlen = 500
batch_size = 32
(input_train, y_train), (input_test, y_test) = imdb.load_data(num_words=max_features, path='E:\\study\\dataset\\imdb.npz')
print(len(input_train), 'train sequences')
print(len(input_test), 'test sequences')
print('Pad sequences (samples x time)')
input_train = sequence.pad_sequences(input_train, maxlen=maxlen)
input_test = sequence.pad_sequences(input_test, maxlen=maxlen)
print('input_train shape:', input_train.shape)
print('input_test shape:', input_test.shape)
model = Sequential()
model.add(Embedding(max_features, 32))
model.add(LSTM(32))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(input_train, y_train, epochs=10, batch_size=128, validation_split=0.2)
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
结果
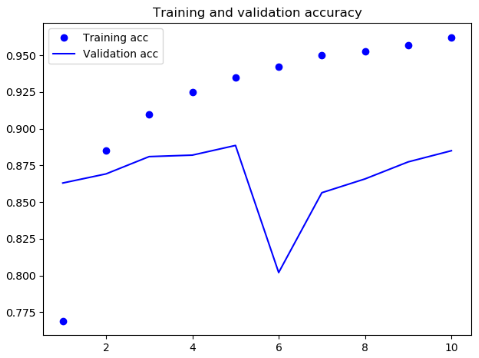
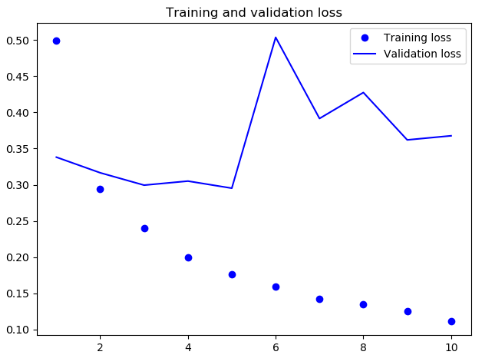
可见此次结果比SimpleRNN网络要好一些,主要是因为LSTM 受梯度消失问题的影响要小得多
LSTM适用于评论分析全局的长期性结构
可以提高循环神经网络的性能和泛化能力的三种高级技巧
- **循环 **dropout(recurrent dropout)。这是一种特殊的内置方法,在循环层中使用 dropout 来降低过拟合
- 堆叠循环层(stacking recurrent layers)。这会提高网络的表示能力(代价是更高的计算负荷)
- 双向循环层(bidirectional recurrent layer)。将相同的信息以不同的方式呈现给循环网络,可以提高精度并缓解遗忘问题
门控循环单元(GRU,gated recurrent unit)层的工作原理与 LSTM 相同。但它做了一些简化,因此运
行的计算代价更低(虽然表示能力可能不如 LSTM),GRU层通常更善于记住最近的数据,而不是久远的数据
使用以上三种种方式来进行温度预测
import os
import numpy as np
from matplotlib import pyplot as plt
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
from keras import models
data_dir = 'E:\\study\\dataset'
fname = os.path.join(data_dir, 'jena_climate_2009_2016.csv')
f = open(fname)
data = f.read()
f.close()
lines = data.split('\n')
header = lines[0].split(',')
lines = lines[1:]
print(header)
print(len(lines))
# 将数据转换成一个 Numpy 数组
float_data = np.zeros((len(lines), len(header) - 1))
for i, line in enumerate(lines):
values = [float(x) for x in line.split(',')[1:]]
float_data[i, :] = values
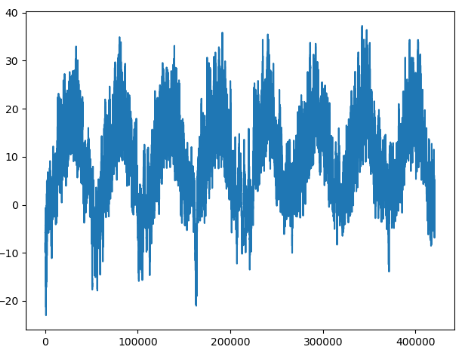
# 温度
temp = float_data[:, 1]
plt.plot(range(len(temp)), temp)
plt.show()
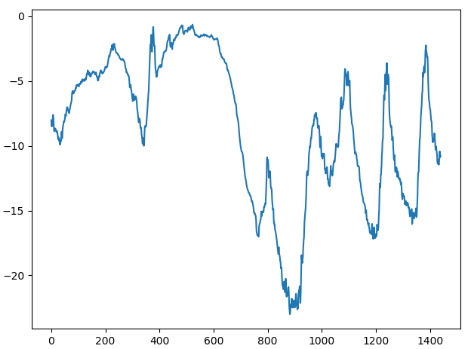
# 前 10 天的温度时间序列
plt.plot(range(1440), temp[:1440])
plt.show()
# 数据标准化
# 将使用前200 000 个时间步作为训练数据
mean = float_data[:200000].mean(axis=0)
float_data -= mean
std = float_data[:200000].std(axis=0)
float_data /= std
# 生成时间序列样本及其目标的生成器
def generator(data, lookback, delay, min_index, max_index, shuffle=False, batch_size=128, step=6):
"""
:param data: 浮点数数据组成的原始数组
:param lookback: 输入数据应该包括过去多少个时间步
:param delay: 目标应该在未来多少个时间步之后
:param min_index: 数组中的索引
:param max_index: 数组中的索引
:param shuffle: 是打乱样本,还是按顺序抽取样本
:param batch_size: 每个批量的样本数
:param step: 数据采样的周期
:return:
"""
if max_index is None:
max_index = len(data) - delay - 1
i = min_index + lookback
while 1:
if shuffle:
rows = np.random.randint(min_index + lookback, max_index, size=batch_size)
else:
if i + batch_size >= max_index:
i = min_index + lookback
rows = np.arange(i, min(i + batch_size, max_index))
i += len(rows)
samples = np.zeros((len(rows), lookback // step, data.shape[-1]))
targets = np.zeros((len(rows),))
for j, row in enumerate(rows):
indices = range(rows[j] - lookback, rows[j], step)
samples[j] = data[indices]
targets[j] = data[rows[j] + delay][1]
yield samples, targets
# 准备训练生成器、验证生成器和测试生成器
lookback = 1440
step = 6
delay = 144
batch_size = 128
train_gen = generator(float_data, lookback=lookback, delay=delay, min_index=0, max_index=200000, shuffle=True, step=step, batch_size=batch_size)
val_gen = generator(float_data, lookback=lookback, delay=delay, min_index=200001, max_index=300000, step=step, batch_size=batch_size)
test_gen = generator(float_data, lookback=lookback, delay=delay, min_index=300001, max_index=None, step=step, batch_size=batch_size)
# 查看,需要从 generate 中抽取多少次
val_steps = (300000 - 200001 - lookback) // batch_size
test_steps = (len(float_data) - 300001 - lookback) // batch_size
def get_base_model_history():
model = Sequential()
model.add(layers.Flatten(input_shape=(lookback // step, float_data.shape[-1])))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(), loss='mae', metrics=['acc'])
history = model.fit_generator(train_gen, steps_per_epoch=500, epochs=20, validation_data=val_gen, validation_steps=val_steps)
return history
# 使用GRU 的模型
def get_gru_model_history():
model = Sequential()
model.add(layers.GRU(32, input_shape=(None, float_data.shape[-1])))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(), loss='mae', metrics=['acc'])
history = model.fit_generator(train_gen, steps_per_epoch=500, epochs=20, validation_data=val_gen, validation_steps=val_steps)
return history
# 使用 dropout 正则化的基于 GRU 的模型
def get_gru_model_with_dropout_history():
model = Sequential()
model.add(layers.GRU(32, dropout=0.2, recurrent_dropout=0.2, input_shape=(None, float_data.shape[-1])))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(), loss='mae', metrics=['acc'])
history = model.fit_generator(train_gen, steps_per_epoch=500, epochs=40, validation_data=val_gen, validation_steps=val_steps)
model.save('gru_model_with_dropout.h5')
return history
# 使用 dropout 正则化的堆叠 GRU 模型
def get_mul_gru_model_with_dropout_history():
model = Sequential()
model.add(layers.GRU(32, dropout=0.1, recurrent_dropout=0.5, return_sequences=True, input_shape=(None, float_data.shape[-1])))
model.add(layers.GRU(64, activation='relu', dropout=0.1, recurrent_dropout=0.5))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(), loss='mae', metrics=['acc'])
history = model.fit_generator(train_gen, steps_per_epoch=500, epochs=40, validation_data=val_gen, validation_steps=val_steps)
model.save('mul_gru_model_with_dropout')
return history
def draw_loss(history):
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
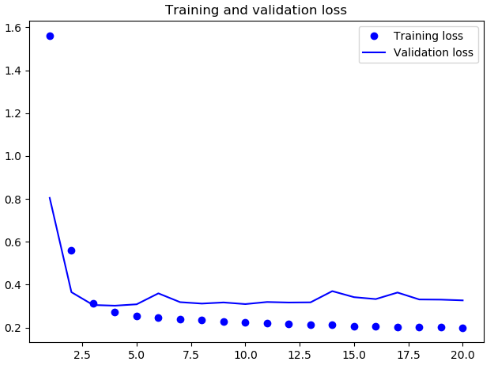
draw_loss(get_base_model_history())
draw_loss(history=get_gru_model_history())
draw_loss(history=get_gru_model_with_dropout_history())
draw_loss(history=get_mul_gru_model_with_dropout_history())
结果
原始数据
十天数据
基准
只使用gru的预测Loss
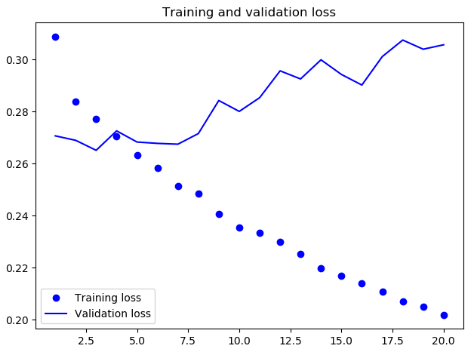
因为第一个和其它两个是分开训练的,所以因为draw_acc_and_loss函数中的history参数写成了'acc'得到了报错,而之前只保存了model,而没有保存history,所以画不出来,以下两个将引用原书中结果图,以后有空再补
使用 dropout 正则化的gru
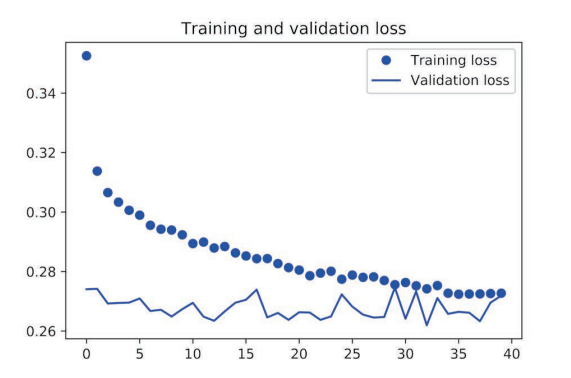
使用 dropout 正则化的堆叠 GRU 模型
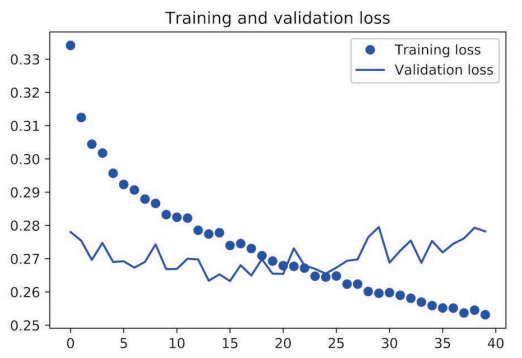
由以上可见,相对于基准模型,使用 GRU 稍微降低了 loss,但是很快过拟合了,然后使用带有 dropout 的 GRU,再次降低了 loss,但是最后在0.28左右变得平缓,说明遇到了性能瓶颈,最后我们使用带有 dropout 正则化的堆叠 GRU 模型,性能再次提高,但是依旧不是很好
注意:想要在循环网络中使用 dropout,你应该使用一个不随时间变化的 dropout 掩码与循环 dropout 掩码。这二者都内置于 Keras 的循环层中,所以你只需要使用循环层的 dropout 和 recurrent_dropout 参数即可
最后是双向 RNN,它常用于自然语言处理
RNN是特别依赖顺序或时间的,打乱时间步或反转时间步会完全改变RNN从序列中提取的表示。所以,如果顺序对问题很重要,RNN的表现会很好。双向RNN利用了RNN的顺序敏感性:它包含两个普通RNN,每个RNN分别沿一个方向对输入序列进行处理,然后将它们合并在一起。通过沿这两个方向处理序列,双向RNN能够捕捉到可能被单向RNN忽略的模式
逆序数据,情感分类 Demo(用于性能比较)
from keras.datasets import imdb
from keras.preprocessing import sequence
from keras import layers
from keras.models import Sequential
import tools
# 将画图的部分封装到了tools里面,依旧使用imdb数据(评论情感分类)
max_features = 10000
maxlen = 500
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features, path='E:\\study\\dataset\\imdb.npz')
# 逆序数据
x_train = [x[::-1] for x in x_train]
x_test = [x[::-1] for x in x_test]
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
model = Sequential()
model.add(layers.Embedding(max_features, 128))
model.add(layers.LSTM(32))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(x_train, y_train, epochs=10, batch_size=128, validation_split=0.2)
tools.draw_acc_and_loss(history)
结果
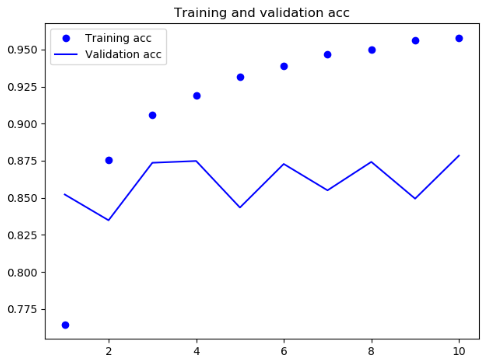
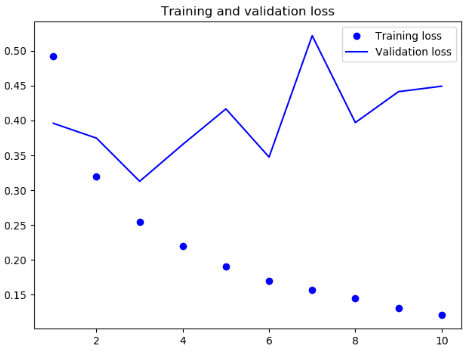
可见,逆序数据之后,模型的性能与正序几乎没有改变,这证明一个假设:虽然单词顺序对于理解语言很重要,但使用哪种顺序并不重要。重要的是,在逆序序列上训练的RNN学到的表示不同于在原始序列上学到的表示。在机器学习中,如果一种数据表示不同但有用,那么总是值得加以利用,这种表示与其他表示的差异越大越好,它们提供了查看数据的全新角度,抓住了数据中被其他方法忽略的内容,因此可以提高模型在某个任务上的性能
双向 RNN 正是利用这个想法来提高正序 RNN 的性能,它从两个方向查看数据,从而得到更加丰富的表示,并捕捉到仅使用正序 RNN 时可能忽略的一些模式

使用双向LSTM和双向GRU的方法
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
def get_bothway_lstm_history(max_features, x_train, y_train):
model = Sequential()
model.add(layers.Embedding(max_features, 32))
model.add(layers.Bidirectional(layers.LSTM(32)))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(x_train, y_train, epochs=10, batch_size=128, validation_split=0.2)
return history
def get_bothway_gru_history(float_data, train_gen, val_gen, val_steps):
model = Sequential()
model.add(layers.Bidirectional(layers.GRU(32), input_shape=(None, float_data.shape[-1])))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(), loss='mae')
history = model.fit_generator(train_gen, steps_per_epoch=500, epochs=40, validation_data=val_gen, validation_steps=val_steps)
return history
向函数中填充对应数据即可开始训练
书中给出的结果是: 双向LSTM的表现比普通的LSTM略好,这是可以理解的,毕竟情感分析与输入顺序是没有什么关系的,而使用双向的LSTM比单向的LSTM参数多了一倍
当使用双向GRU来预测温度时,并没有比普通的好,这也是可以理解的,GRU对于近期的记忆要好一些,但是对于远期的记忆表现的交叉,而温度预测是与时间相关的,当改变输入顺序,GRU必然会出现不好的预测,因此,使用双向GRU时,做出贡献的几乎都是正向的那个
在此,给一个建议,当你的model需要训练的时间很长的话,可以先使用只是一轮的训练来测试程序是否完全正确。然后,还可以在每次或每几次训练之后就保存一下模型,顺便保存一下history(如果需要的话)
Deep learning with Python 学习笔记(7)
Deep learning with Python 学习笔记(5)
Deep learning with Python 学习笔记(6)的更多相关文章
- Deep learning with Python 学习笔记(11)
总结 机器学习(machine learning)是人工智能的一个特殊子领域,其目标是仅靠观察训练数据来自动开发程序[即模型(model)].将数据转换为程序的这个过程叫作学习(learning) 深 ...
- Deep learning with Python 学习笔记(10)
生成式深度学习 机器学习模型能够对图像.音乐和故事的统计潜在空间(latent space)进行学习,然后从这个空间中采样(sample),创造出与模型在训练数据中所见到的艺术作品具有相似特征的新作品 ...
- Deep learning with Python 学习笔记(9)
神经网络模型的优化 使用 Keras 回调函数 使用 model.fit()或 model.fit_generator() 在一个大型数据集上启动数十轮的训练,有点类似于扔一架纸飞机,一开始给它一点推 ...
- Deep learning with Python 学习笔记(8)
Keras 函数式编程 利用 Keras 函数式 API,你可以构建类图(graph-like)模型.在不同的输入之间共享某一层,并且还可以像使用 Python 函数一样使用 Keras 模型.Ker ...
- Deep learning with Python 学习笔记(7)
介绍一维卷积神经网络 卷积神经网络能够进行卷积运算,从局部输入图块中提取特征,并能够将表示模块化,同时可以高效地利用数据.这些性质让卷积神经网络在计算机视觉领域表现优异,同样也让它对序列处理特别有效. ...
- Deep learning with Python 学习笔记(5)
本节讲深度学习用于文本和序列 用于处理序列的两种基本的深度学习算法分别是循环神经网络(recurrent neural network)和一维卷积神经网络(1D convnet) 与其他所有神经网络一 ...
- Deep learning with Python 学习笔记(4)
本节讲卷积神经网络的可视化 三种方法 可视化卷积神经网络的中间输出(中间激活) 有助于理解卷积神经网络连续的层如何对输入进行变换,也有助于初步了解卷积神经网络每个过滤器的含义 可视化卷积神经网络的过滤 ...
- Deep learning with Python 学习笔记(3)
本节介绍基于Keras的使用预训练模型方法 想要将深度学习应用于小型图像数据集,一种常用且非常高效的方法是使用预训练网络.预训练网络(pretrained network)是一个保存好的网络,之前已在 ...
- Deep learning with Python 学习笔记(2)
本节介绍基于Keras的CNN 卷积神经网络接收形状为 (image_height, image_width, image_channels)的输入张量(不包括批量维度),宽度和高度两个维度的尺寸通常 ...
随机推荐
- 6、GNU makefile工程管理学习的一个例子
在之前我们已经学习了一个文件的编译过程,但是做过项目的都知道,一个工程中的源文件不计其数,其按类型.功能.模块会分别放在若干个目录中,而这些文件如何编译就需要有一个编译规则,虽然现在很多大型的项目都是 ...
- spark 中划分stage的思路
窄依赖指父RDD的每一个分区最多被一个子RDD的分区所用,表现为 一个父RDD的分区对应于一个子RDD的分区 两个父RDD的分区对应于一个子RDD 的分区. 宽依赖指子RDD的每个分区都要依赖于父RD ...
- VirtualBox 安装 CentOS6.5 教程
VirtualBox安装 CentOS6.5教程 1.选择第一个进行安装 2.选择右面的 skip 进入安装 3.点击next 4.选择中文简体 5.选择美式键盘 6.选择第一个 7.输入主机名 8. ...
- SpringMVC随笔之——@responsebody【引用snowolf博文】
首先说RESTful 风格是什么 :(RESTful 风格:把请求参数变成请求路径的一种风格.) OK,一句话总结完毕 @responsebody表示该方法的返回结果直接写入HTTP response ...
- Linux (rz、sz命令行)与本地电脑 命令行上传、下载文件
Linux 与本地电脑直接交互, 命令行上传.下载文件. 一.lrzsz命令行安装: 1.rpm安装:(链接: http://pan.baidu.com/s/1cBuTm2 密码: vijf) rpm ...
- 纸壳CMS主题增强,支持主题中加入模板
背景 在之前,纸壳CMS的主题仅仅只是CSS样式,并不支持在主题下使用模板来构建不同的HTML结构.现在我们对主题功能做了增强,可以在主题下添加各自的模板,这样在制作主题时,就会更加自由.不仅如此,新 ...
- Android--------------BroadcastReceiver的学习
一.广播的注册方式 发送广播: Intent mIntent = new Intent("com.simware.BroadcastReceiverDemo"); mIntent. ...
- Bash/Shell-脚本整理(长期更新)
轮询检测Apache状态并启用钉钉报警 #!/bin/bash shell_user="root" shell_domain="apache" shell_li ...
- Java并发编程总结3——AQS、ReentrantLock、ReentrantReadWriteLock
本文内容主要总结自<Java并发编程的艺术>第5章——Java中的锁. 一.AQS AbstractQueuedSynchronizer(简称AQS),队列同步器,是用来构建锁或者其他同步 ...
- Python 绝技 —— TCP服务器与客户端
i春秋作家:wasrehpic 0×00 前言 「网络」一直以来都是黑客最热衷的竞技场.数据在网络中肆意传播:主机扫描.代码注入.网络嗅探.数据篡改重放.拒绝服务攻击……黑客的功底越深厚,能做的就越多 ...