Python+Selenium笔记(十一):配置selenium Grid
(一) 前言
Selenium Grid可以将测试分布在若干个物理或虚拟机器上,从而实现分布方式或并行方式执行测试。
这个链接是官方的相关说明。
https://github.com/SeleniumHQ/selenium/wiki/Grid2
(二) Selenium Grid
大概就是这个意思(一个中心节点(HUB),N个子节点(NODE,操作系统+浏览器))
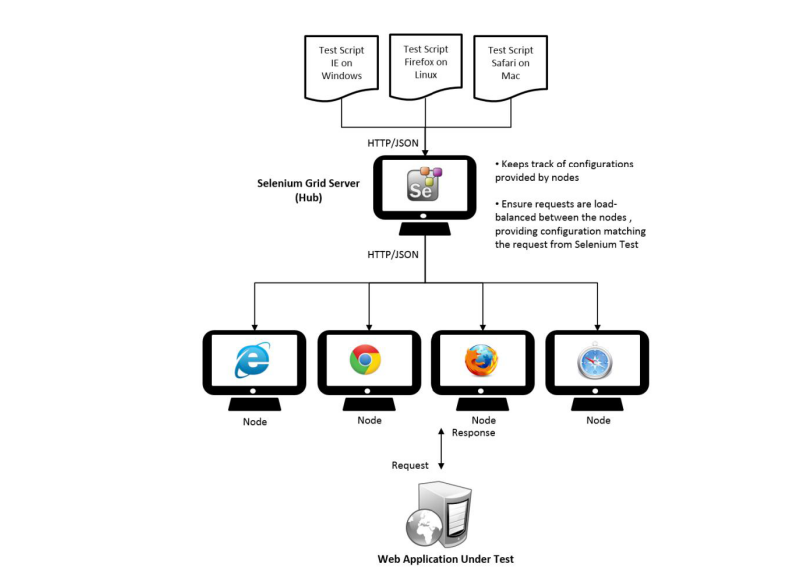
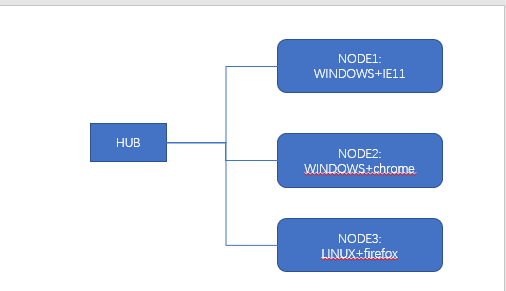
(三) 环境配置
1. 前提:已经配置相应的 JDK环境(LINUX自带JDK环境(我装的LINUX自带的是1.8),WINDOWS要自己配置JDK环境(我装的是1.9))
2. https://docs.seleniumhq.org/download/ 下载 Selenium Standalone Server
3. 启动Selenium Grid server(hub)
Selenium Grid server(hub,作为中心节点的电脑),切换到Selenium Standalone所在的目录(直接在Selenium Standalone所在的文件夹shift+鼠标右键,选择在此处打开命令窗口,或者CD 路径),然后执行下面的命令
java -jar selenium-server-standalone-<version>.jar -role hub例如:java -jar selenium-server-standalone-3.9.1.jar -role hub
可以加 -port 指定端口号,默认4444
http://localhost:4444/grid/console 启动后用这个地址访问

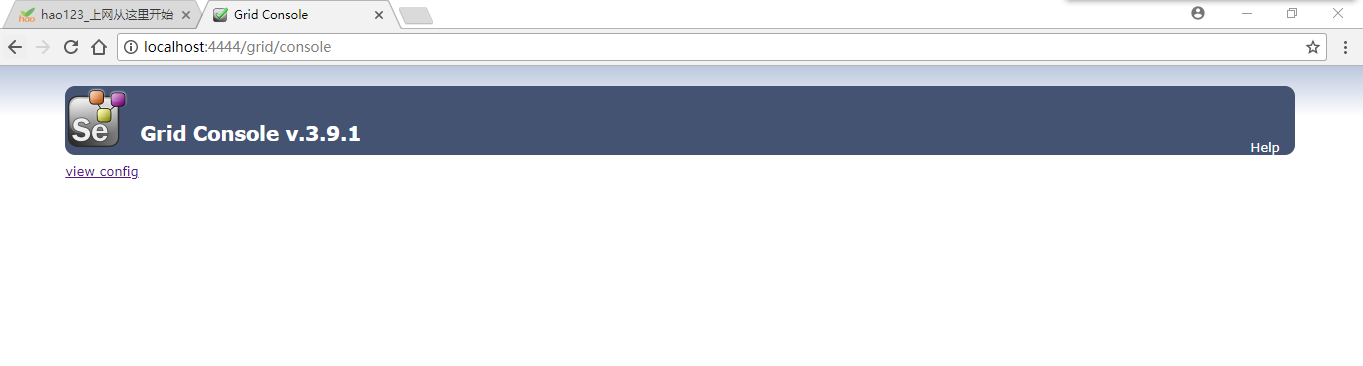
4. 配置node(节点)
(1) Node(也就是其他电脑或虚拟机环境,也可以直接将hub所在的那台电脑添加为node),在系统变量path中加上相应的驱动文件的路径。(例如:将chromedriver所在的路径添加到path中,之前已经说过火狐、IE、谷歌浏览器环境的配置)
(2) 执行下面的命令
java -jar selenium-server-standalone-3.9.1.jar -role node -browser "browserName=firefox,version=62,maxSession=3,platform=WINDOWS" -hub http://192.168.4.196:4444/grid/register -port 5555
说明:
browserName:浏览器名称
Version:浏览器版本
maxSession:支持并发浏览器实例的数量
platform:操作系统
-hub:http:// (Selenium Grid server(hub)的IP)+启动时设置的端口号/ grid/register
-port :指定端口号
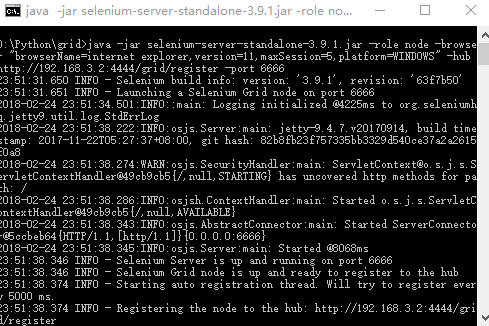
(3) 要在同一电脑(或虚拟机)添加其他节点,再打开一个CMD窗口,运行上面的命令就行了(记得修改浏览器信息),记得同一电脑上端口号别重复。
(四) 环境配置好后如下图所示(我电脑开着一个linux的虚拟机太卡了,有点浪费时间的感觉,不想弄了,不过应该和windows上的差距不会太大,有环境的可以试下添加path变量、在终端执行相关命令添加节点)

(五) 示例(运行脚本会发现,直接在相匹配的环境中运行测试)
import sys
import unittest
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
class SearchTest(unittest.TestCase):
#定义2个全局属性,没有外部参数时,使用默认值
PLATFORM = "WINDOWS"
BROWSER = "firefox"
@classmethod
def setUpClass(cls):
#设置操作系统和浏览器
desired_caps = {}
desired_caps['platform'] = cls.PLATFORM
desired_caps['browserName'] = cls.BROWSER
#这里的IP就是HUB所在电脑的ip
cls.driver = webdriver.Remote('http://192.168.3.2:4444/wd/hub',desired_caps)
cls.driver.implicitly_wait(10)
cls.driver.maximize_window()
cls.driver.get("https://www.cnblogs.com/") def test_search_by_look(self):
seach_class = self.driver.find_element_by_xpath('//li/a[@href="/cate/2/"]')
#定位编程语言下的小类Python
seach_small =self.driver.find_element_by_xpath('//li/a[@href="/cate/python/"]')
ActionChains(self.driver).move_to_element(seach_class).perform()
seach_small.click()
#检查打开的网页标题是不是 Python - 网站分类 - 博客园
self.assertEqual(self.driver.title,"Python - 网站分类 - 博客园" ) @classmethod
def tearDownClass(cls):
cls.driver.quit() if __name__ == '__main__':
#使用命令行运行脚本时,如果添加了参数,PLATFORM和BROWSER使用外部参数
if len(sys.argv)>1:
SearchTest.PLATFORM = sys.argv.pop()
SearchTest.BROWSER = sys.argv.pop()
#加verbosity=2参数,在命令行中显示具体的测试方法
unittest.main(verbosity=2)
(六) 未解决的问题(单单配置环境是不够的)
1、 实现多环境并行运行同一测试脚本
2、 实现多个测试脚本并行运行(例如几百个测试脚本要是一个个运行的话,要用很长时间)
Python+Selenium笔记(十一):配置selenium Grid的更多相关文章
- PYTHON 爬虫笔记十:利用selenium+PyQuery实现淘宝美食数据搜集并保存至MongeDB(实战项目三)
利用selenium+PyQuery实现淘宝美食数据搜集并保存至MongeDB 目标站点分析 淘宝页面信息很复杂的,含有各种请求参数和加密参数,如果直接请求或者分析Ajax请求的话会很繁琐.所以我们可 ...
- [Python爬虫] 之十一:Selenium +phantomjs抓取活动行中会议活动信息
一.介绍 本例子用Selenium +phantomjs爬取活动行(http://www.huodongxing.com/search?qs=数字&city=全国&pi=1)的资讯信息 ...
- [Python爬虫] 之三十一:Selenium +phantomjs 利用 pyquery抓取消费主张信息
一.介绍 本例子用Selenium +phantomjs爬取央视栏目(http://search.cctv.com/search.php?qtext=消费主张&type=video)的信息(标 ...
- python 学习笔记十一 SQLALchemy ORM(进阶篇)
SqlAlchemy ORM SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据A ...
- Python学习笔记十一:模块
标准库(内置模块) time与datetime 模块 时间表示方式 1.时间戳 2.格式化的字符串 3.元组形式 时间戳就是一个秒数 x=time.time(),从1970年1月1日0时0分0秒到现在 ...
- python学习笔记(十一)redis的介绍及安装
一.redis简介 1.redis是一个开源的.使用C语言编写的.支持网络交互的.可基于内存也可持久化的Key-Value数据库. 2.redis的官网地址,非常好记,是redis.io. ...
- python学习笔记十一:操作mysql
一.安装MySQL-python # yum install -y MySQL-python 二.打开数据库连接 #!/usr/bin/python import MySQLdb conn = MyS ...
- PYTHON 爬虫笔记十一:Scrapy框架的基本使用
Scrapy框架详解及其基本使用 scrapy框架原理 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
- Python学习笔记十一
1. 协程 并发的解决方案: 多进程 多线程 什么叫并发:看起来同时进行 如何实现并发:切换+保存状态 进程线程都是由操作系统调度的 协程:单线程下实现的并发,应用程序级别的切换, ...
- python学习笔记(十一)-python程序目录工程化
在一个程序当中,一般都会包含文件夹:bin.conf.lib.data.logs,以及readme文件. 所写程序存放到各自的文件夹中,如何进行串联? 首先,通过导入文件导入模块方式,引用其他人写好的 ...
随机推荐
- Android之密码的显示与隐藏
很多应用都是显示与隐藏密码的功能. 之前的项目都没这个功能要求,也没有专门研究这个.最近项目有加这个功能,我这里也刚好整理一下. 我的思路是设置EditText的InputType.代码如下: if ...
- Python爬取简书主页信息
主要学习如何通过抓包工具分析简书的Ajax加载,有时间再写一个Multithread proxy spider提升效率. 1. 关键点: 使用单线程爬取,未登录,爬取简书主页Ajax加载的内容.主要有 ...
- xshell 登陆堡垒机实现自动跳转
1, 正常使用用户密码登录堡垒机并保存登陆配置 2, 配置登陆脚本 添加第一个: expect 为空send :ssh root@ip 添加第二个: expect root@ip's password ...
- GOROOT、GOPATH和project目录说明
go env环境查看 用go env 可查看当前go环境变量. $ go env GOARCH="amd64" GOBIN="" GOEXE="&qu ...
- 让 markdown 生成带目录的 html 文件
安装 npm install -g i5ting_toc 用法 进入 markdown 文件所在的文件夹 举个栗子: 你的sample.md文件放在桌面上 cd /Users/dora/Desktop ...
- es6学习笔记4--数组
数组的扩展 Array.from() Array.from方法用于将两类对象转为真正的数组:类似数组的对象(array-like object)和可遍历(iterable)的对象(包括ES6新增的数据 ...
- PHP函数array_merge
今天因一个Bug重新审视了下array_merge()这个函数. 定义:array_merge — 合并一个或多个数组 规范:array array_merge(array $array1 [, ar ...
- Travelling Fee(Dijlstra——最短路问题变型)
题目链接: http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=2027 题目: Samball is going to trav ...
- C# winform 无边框 窗体的拖动
当船体设置为FormborderStyle='none' [DllImport("user32.dll")] public static extern bool ReleaseCa ...
- Oracle 图解安装
1.找到安装exe打开. 2. 3. 4. 5. 6. 7. 8.