python爬取股票信息
import requests
from bs4 import BeautifulSoup
import traceback
import re def getHTMLText(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "" def getStockList(lst, stockURL):
html = getHTMLText(stockURL)
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']
lst.append(re.findall(r"[s][hz]\d{6}", href)[0])
except:
continue def getStockInfo(lst, stockURL, fpath):
for stock in lst:
url = stockURL + stock + ".html"
html = getHTMLText(url)
try:
if html == "":
continue
infoDict = {}
soup = BeautifulSoup(html, 'html.parser')
stockInfo = soup.find('div', attrs={'class': 'stock-bets'}) name = stockInfo.find_all(attrs={'class': 'bets-name'})[0]
infoDict.update({'股票名称': name.text.split()[0]}) keyList = stockInfo.find_all('dt')
valueList = stockInfo.find_all('dd')
for i in range(len(keyList)):
key = keyList[i].text
val = valueList[i].text
infoDict[key] = val with open(fpath, 'a', encoding='utf-8') as f:
f.write(str(infoDict) + '\n')
except:
traceback.print_exc()
continue def main():
stock_list_url = 'http://quote.eastmoney.com/stocklist.html'
stock_info_url = 'http://gupiao.baidu.com/stock/'
output_file = 'D:/BaiduStockInfo.txt'
slist = []
getStockList(slist, stock_list_url)
getStockInfo(slist, stock_info_url, output_file) main()
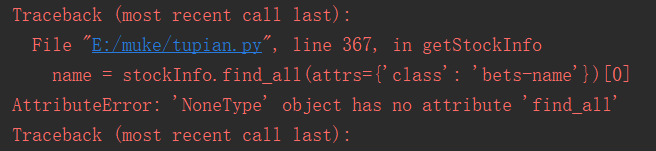
这是慕课上的源代码,直接粘贴的,不知道为什么运行一直报错。以下是错误。如果有人解决了,麻烦说一声,谢谢啦。
下面是慕课中修改的代码,也是源代码,直接粘贴的,但是是可以运行出来的。
import requests
from bs4 import BeautifulSoup
import traceback
import re def getHTMLText(url, code="utf-8"):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = code
return r.text
except:
return "" def getStockList(lst, stockURL):
html = getHTMLText(stockURL, "GB2312")
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']
lst.append(re.findall(r"[s][hz]\d{6}", href)[0])
except:
continue def getStockInfo(lst, stockURL, fpath):
count = 0
for stock in lst:
url = stockURL + stock + ".html"
html = getHTMLText(url)
try:
if html=="":
continue
infoDict = {}
soup = BeautifulSoup(html, 'html.parser')
stockInfo = soup.find('div',attrs={'class':'stock-bets'}) name = stockInfo.find_all(attrs={'class':'bets-name'})[0]
infoDict.update({'股票名称': name.text.split()[0]}) keyList = stockInfo.find_all('dt')
valueList = stockInfo.find_all('dd')
for i in range(len(keyList)):
key = keyList[i].text
val = valueList[i].text
infoDict[key] = val with open(fpath, 'a', encoding='utf-8') as f:
f.write( str(infoDict) + '\n' )
count = count + 1
print("\r当前进度: {:.2f}%".format(count*100/len(lst)),end="")
except:
count = count + 1
print("\r当前进度: {:.2f}%".format(count*100/len(lst)),end="")
continue def main():
stock_list_url = 'http://quote.eastmoney.com/stocklist.html'
stock_info_url = 'http://gupiao.baidu.com/stock/'
output_file = 'D:/BaiduStockInfo.txt'
slist=[]
getStockList(slist, stock_list_url)
getStockInfo(slist, stock_info_url, output_file) main()
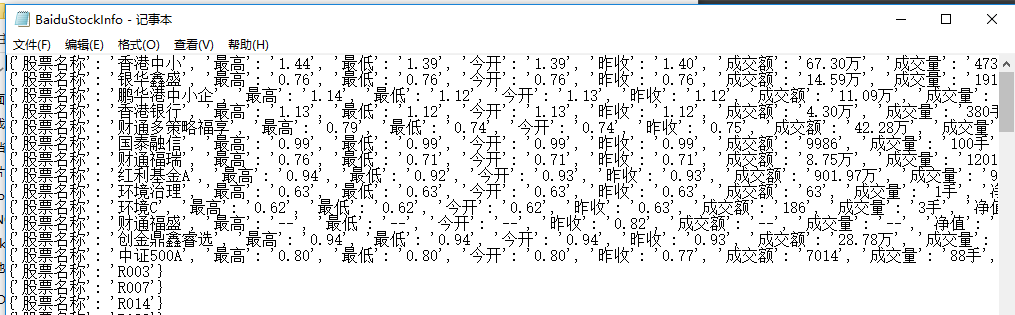
至于为什么,本人也不是特别清楚,代码主题部分是一样的,具体原因不清楚。我把编码方式删去了,和原先一样。但是程序依然可以运行。我不知道为什么,加了进度条,程序就可以运行了。
这是别人的代码分析 ,个人觉得还是很好的,很仔细:https://segmentfault.com/a/1190000010520835
python爬取股票信息的更多相关文章
- Python爬取股票信息,并实现可视化数据
前言 截止2019年年底我国股票投资者数量为15975.24万户, 如此多的股民热衷于炒股,首先抛开炒股技术不说, 那么多股票数据是不是非常难找, 找到之后是不是看着密密麻麻的数据是不是头都大了? 今 ...
- Python 爬取所有51VOA网站的Learn a words文本及mp3音频
Python 爬取所有51VOA网站的Learn a words文本及mp3音频 #!/usr/bin/env python # -*- coding: utf-8 -*- #Python 爬取所有5 ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- python爬取某个网页的图片-如百度贴吧
python爬取某个网页的图片-如百度贴吧 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用告诉我 #coding:utf-8 import urllib imp ...
- Python:爬取乌云厂商列表,使用BeautifulSoup解析
在SSS论坛看到有人写的Python爬取乌云厂商,想练一下手,就照着重新写了一遍 原帖:http://bbs.sssie.com/thread-965-1-1.html #coding:utf- im ...
- 使用python爬取MedSci上的期刊信息
使用python爬取medsci上的期刊信息,通过设定条件,然后获取相应的期刊的的影响因子排名,期刊名称,英文全称和影响因子.主要过程如下: 首先,通过分析网站http://www.medsci.cn ...
- python爬取免费优质IP归属地查询接口
python爬取免费优质IP归属地查询接口 具体不表,我今天要做的工作就是: 需要将数据库中大量ip查询出起归属地 刚开始感觉好简单啊,毕竟只需要从百度找个免费接口然后来个python脚本跑一晚上就o ...
- Python爬取豆瓣指定书籍的短评
Python爬取豆瓣指定书籍的短评 #!/usr/bin/python # coding=utf-8 import re import sys import time import random im ...
- python爬取网页的通用代码框架
python爬取网页的通用代码框架: def getHTMLText(url):#参数code缺省值为‘utf-8’(编码方式) try: r=requests.get(url,timeout=30) ...
随机推荐
- PHP读取txt文件到数组
$file_path = "test.txt"; if(file_exists($file_path)){ $file_arr = file($file_path); for($i ...
- 1.如何在Cloud Studio上执行Python代码?
1.在python文件下新建python文件,输入文件名后按Enter键生成,比如: one.py . 2.简单输入python代码: print "haha" 3.打开左下角的终 ...
- 使用uni-app开发微信小程序之登录模块
从微信小程序官方发布的公告中我们可获知:小程序体验版.开发版调用 wx.getUserInfo 接口,将无法弹出授权询问框,默认调用失败,需使用 <button open-type=" ...
- <转载>AWS 基础知识
什么是AWS? Amazon Web Services (AWS) , 其实就是 亚马逊提供的专业云计算服务.其提供服务包括:亚马逊弹性计算网云(Amazon EC2).亚马逊简单储存服务(Amazo ...
- vmware使用vsphere的镜像
vsphere镜像导出后可以使用vmware station打开, vsphere镜像导出时需要关机,否则会提示失败,有文件不能导出.
- Android ADB 基本命令
ADB很强大,记住一些ADB命令有助于提高工作效率. 获取序列号: adb get-serialno 查看连接计算机的设备: adb devices 重启机器: adb reboot 重启到bootl ...
- js对象及元素复制拷贝
1.数组及对象拷贝: 浅拷贝var b=$.extend(false,{},a);//对象浅拷贝 var a={aa:111,bb:{bb1:22}}; var b=$.extend(false,{} ...
- liunx poi excel下载内容乱码本地tomcat正常
结论:在jsp中加上out.clear即可(前提保证生成的excel在服务器上是正确的,只是浏览器传输才出现乱码). dowload.jsp完整代码 <%@ page language=&quo ...
- Asp.Net前台调用后台变量
1.Asp.Net中几种相似的标记符号: < %=...%>< %#... %>< % %>< %@ %>解释及用法 答: < %#... %&g ...
- 深度学习原理与框架-神经网络-线性回归与神经网络的效果对比 1.np.c_[将数据进行合并] 2.np.linspace(将数据拆成n等分) 3.np.meshgrid(将一维数据表示为二维的维度) 4.plt.contourf(画出等高线图,画算法边界)
1. np.c[a, b] 将列表或者数据进行合并,我们也可以使用np.concatenate 参数说明:a和b表示输入的列表数据 2.np.linspace(0, 1, N) # 将0和1之间的数 ...