批量下载,多文件压缩打包zip下载
0、写在前面的话
1、先叨叨IO
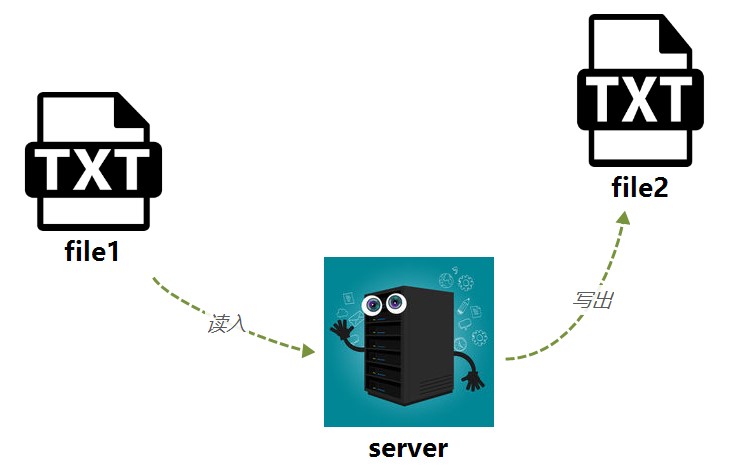
outputStream = new FileOutputStream(file);
byte[] temp = new byte[1024];
int size = -1;
while ((size = inputStream.read(temp)) != -1) { // 每次读取1KB,直至读完
outputStream.write(temp, 0, size);
}outputStream = new FileOutputStream(file);
byte[] temp = new byte[1024];
int size = -1;
while ((size = inputStream.read(temp)) != -1) { // 每次读取1KB,直至读完
outputStream.write(temp, 0, size);
}
2、再叨叨ajax
3、正儿八经的批量下载实现
<dependency>
<groupId>ant</groupId>
<artifactId>ant</artifactId>
<version>1.6.5</version>
</dependency><dependency>
<groupId>ant</groupId>
<artifactId>ant</artifactId>
<version>1.6.5</version>
</dependency>
/**
* 批量下载
*
* @param idxs 图片的id拼接字符串,用逗号隔开
*/
public String downloadBatch(String idxs) {
String[] ids = idxs.split(",");
try {
HttpServletResponse response = ServletActionContext.getResponse();
OutputStream out = setDownloadOutputStream(response, String.valueOf(new Date().getTime()), "zip");
ZipOutputStream zipOut = new ZipOutputStream(out);
for (int i = 0; i < ids.length; i++) {
Picture picture = Picture.get(Picture.class, Long.parseLong(ids[i]));
byte[] data = picture.getData();
zipOut.putNextEntry(new ZipEntry(i + "_" + picture.getName() + "." + picture.getFormat().getValue()));
writeBytesToOut(zipOut, data, BUFFER_SIZE);
zipOut.closeEntry();
}
zipOut.flush();
zipOut.close();
} catch (IOException e) {
e.printStackTrace();
log.warn("下载失败:" + e.getMessage());
}
return null;
}/**
* 批量下载
*
* @param idxs 图片的id拼接字符串,用逗号隔开
*/
public String downloadBatch(String idxs) {
String[] ids = idxs.split(",");
try {
HttpServletResponse response = ServletActionContext.getResponse();
OutputStream out = setDownloadOutputStream(response, String.valueOf(new Date().getTime()), "zip");
ZipOutputStream zipOut = new ZipOutputStream(out);
for (int i = 0; i < ids.length; i++) {
Picture picture = Picture.get(Picture.class, Long.parseLong(ids[i]));
byte[] data = picture.getData();
zipOut.putNextEntry(new ZipEntry(i + "_" + picture.getName() + "." + picture.getFormat().getValue()));
writeBytesToOut(zipOut, data, BUFFER_SIZE);
zipOut.closeEntry();
}
zipOut.flush();
zipOut.close();
} catch (IOException e) {
e.printStackTrace();
log.warn("下载失败:" + e.getMessage());
}
return null;
}
/**
* 设置文件下载的response格式
*
* @param response 响应
* @param fileName 文件名称
* @param fileType 文件类型
* @return 设置后响应的输出流OutputStream
* @throws IOException
*/
private static OutputStream setDownloadOutputStream(HttpServletResponse response, String fileName, String fileType) throws IOException {
fileName = new String(fileName.getBytes(), "ISO-8859-1");
response.setHeader("Content-Disposition", "attachment;filename=" + fileName + "." + fileType);
response.setContentType("multipart/form-data");
return response.getOutputStream();
}/**
* 设置文件下载的response格式
*
* @param response 响应
* @param fileName 文件名称
* @param fileType 文件类型
* @return 设置后响应的输出流OutputStream
* @throws IOException
*/
private static OutputStream setDownloadOutputStream(HttpServletResponse response, String fileName, String fileType) throws IOException {
fileName = new String(fileName.getBytes(), "ISO-8859-1");
response.setHeader("Content-Disposition", "attachment;filename=" + fileName + "." + fileType);
response.setContentType("multipart/form-data");
return response.getOutputStream();
}
/**
* 将byte[]类型的数据,写入到输出流中
*
* @param out 输出流
* @param data 希望写入的数据
* @param cacheSize 写入数据是循环读取写入的,此为每次读取的大小,单位字节,建议为4096,即4k
* @throws IOException
*/
private static void writeBytesToOut(OutputStream out, byte[] data, int cacheSize) throws IOException {
int surplus = data.length % cacheSize;
int count = surplus == 0 ? data.length / cacheSize : data.length / cacheSize + 1;
for (int i = 0; i < count; i++) {
if (i == count - 1 && surplus != 0) {
out.write(data, i * cacheSize, surplus);
continue;
}
out.write(data, i * cacheSize, cacheSize);
}
}/**
* 将byte[]类型的数据,写入到输出流中
*
* @param out 输出流
* @param data 希望写入的数据
* @param cacheSize 写入数据是循环读取写入的,此为每次读取的大小,单位字节,建议为4096,即4k
* @throws IOException
*/
private static void writeBytesToOut(OutputStream out, byte[] data, int cacheSize) throws IOException {
int surplus = data.length % cacheSize;
int count = surplus == 0 ? data.length / cacheSize : data.length / cacheSize + 1;
for (int i = 0; i < count; i++) {
if (i == count - 1 && surplus != 0) {
out.write(data, i * cacheSize, surplus);
continue;
}
out.write(data, i * cacheSize, cacheSize);
}
}
- 设置文件ContentType类型和文件头
- 读取文件数据为byte[]
- 将数据写入到响应response的输出流中
- ZipOutputStream zipOut = new ZipOutputStream(out);
- //把响应的输出流包装一下而已,便于使用相关压缩方法,就像多了个包装袋
- zipOut.putNextEntry(new ZipEntry(i + "_" + picture.getName() + "." + picture.getFormat().getValue()));
- zipOut.closeEntry();
- //压缩包中的多个文件,实际上每个就是这里的ZipEntry对象,每开始写入某个文件的内容时,必须先putNextEntry(new ZipEntry(String fileName)),然后才可以写入,写完这个文件,必须使用closeEntry()说明,已经写完了第一个文件。就好像putNextEntry是在说 “我要开始写压缩包的下一个文件啦”,而closeEntry则是在说“压缩包里的这个文件我已经写完啦”。循环反复,最终把所有文件写入这个“披着压缩输出流外壳的响应输出流”
- zipOut.flush();
- 写入完成后,刷一下即可。就像去超市买东西,购物车装好了,总得结一次帐才能把东西拿走吧。当然,最后别忘了close关闭。
4、参考链接
批量下载,多文件压缩打包zip下载的更多相关文章
- 打包zip下载
//首先引入的文件为org.apache的切记不是jdk的import org.apache.tools.zip.ZipOutputStream;import org.apache.tools.zip ...
- java实现将文件压缩成zip格式
以下是将文件压缩成zip格式的工具类(复制后可以直接使用): zip4j.jar包下载地址:http://www.lingala.net/zip4j/download.php package util ...
- Web端文件打包.zip下载
使用ant.jar包的API进行文件夹打包.直接上代码: String zipfilename = "test.zip"; File zipfile = new File(zipf ...
- Linux文件压缩/打包/解压
在Linux日常维护中,经常需要备份同步一些比较重要的文件,而在传输过程中如果文件比较大往往会非常慢,而且还会非常占用空间,这时候就需要我们使用压缩工具对大文件进行压缩打包,下面我们来介绍一下常用的压 ...
- Linux中的文件压缩,打包和备份命令
压缩解压命令 gzip 文件 -c : 将压缩数据输出到屏幕,可用来重定向 -v 显示压缩比等信息 -d 解压参数 -t 用来检验一个压缩文件的一致性看看档案有没错 -数字 : 压 ...
- 文件压缩:zip
[root@localhost ~]# yum install -y zip unzip // 安装 zip 和 unzip [root@localhost ~]# ..txt // 压缩文件,要同时 ...
- Java实现多文件压缩打包的方法
package com.biao.test; import java.io.File; import java.io.FileInputStream; import java.io.FileOutpu ...
- [转]C#如何把文件夹压缩打包然后下载
public partial class _Default2 : System.Web.UI.Page{ protected void Page_Load(object sender, EventAr ...
- Java Springboot 根据图片链接生成图片下载链接 及 多个图片打包zip下载链接
现有一些图片在服务器上的链接,在浏览器中打开这些链接是直接显示在浏览器页面的形式. 现在需要生成这些图片的单独下载以及打包下载链接,即在浏览器中打开下载链接后弹出下载框提示下载.由于前端存在跨域问题, ...
随机推荐
- 设计模式(9)--Composite(组合模式)--结构型
1.模式定义: 组合模式属于对象的结构模式,有时又叫做“部分——整体”模式.组合模式将对象组织到树结构中,可以用来描述整体与部分的关系.组合模式可以使客户端将单纯元素与复合元素同等看待. 2.模式特点 ...
- 第三十三天- 线程创建、join、守护线程、死锁
1.线程,线程创建 概念:在传统操作系统中,每个进程有一个地址空间,而且默认就有一个控制线程,线程顾名思义,就是一条流水线工作的过程,一条流水线必须属于一个车间,一个车间的工作过程是一个进程,车间负责 ...
- bzoj1758Wc10重建计划——solution
1758: [Wc2010]重建计划 Time Limit: 40 Sec Memory Limit: 162 MBSubmit: 4707 Solved: 1200[Submit][Status ...
- JPA命名规则
jpa中方法的命名规则必须按照严格的要求来写.不能随便的命名方法名字,具体的方法操作如下. 参照方法地址:https://blog.csdn.net/csdnchen666666/article/de ...
- iOS 开发多线程 —— GCD(1)
本文是根据文顶顶老师的博客学习总结而来,如有不妥之处,还望指出.http://www.cnblogs.com/wendingding/p/3807716.html 概览: /* 纯c语言,提供了非常多 ...
- Unity Profiler GPU Usage(GPU使用情况)
一般情况下性能瓶颈都在CPU上,这儿也列举下几个常见的GPU耗时函数吧. 1 Render.Mesh 绘制网格面(没批处理的面) 2 Batch.DrawStatic 静态批处理 3 Batch.Dr ...
- cd mkdir mv cp rm 命令目录相关操作
切换目录: cd 家目录 cd. 当前目录 cd.. 当前上一级目录 cd../../当前目录的上上级目录 cd - 返回前一个目录 --------------------------------- ...
- SDN第五次上机作业--基于组表的简单负载均衡
0.作业链接 http://www.cnblogs.com/easteast/p/8125383.html 1.实验目的 1.搭建如下拓扑并连接控制器 2.下发相关流表和组表实现负载均衡 3.抓包分析 ...
- JVM各垃圾收集器对比
本随笔是<深入理解Java虚拟机 JVM高级特性与最佳实践>读书笔记. 1.JDK1.7之后的HotSpot虚拟机所包含的所有收集器如下: 解读: 1. 总共有7种垃圾收集器 2.Seri ...
- hdu 1754 I Hate It (线段树功能:单点更新和区间最值)
版权声明:本文为博主原创文章.未经博主同意不得转载.vasttian https://blog.csdn.net/u012860063/article/details/32982923 转载请注明出处 ...