[转] caffe激活层及参数
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的。从bottom得到一个blob数据输入,运算后,从top输入一个blob数据。在运算过程中,没有改变数据的大小,即输入和输出的数据大小是相等的。
输入:n*c*h*w
输出:n*c*h*w
常用的激活函数有sigmoid, tanh,relu等,下面分别介绍。
1、Sigmoid
对每个输入数据,利用sigmoid函数执行操作。这种层设置比较简单,没有额外的参数。
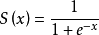
层类型:Sigmoid
示例:
layer {
name: "encode1neuron"
bottom: "encode1"
top: "encode1neuron"
type: "Sigmoid"
}
2、ReLU / Rectified-Linear and Leaky-ReLU
ReLU是目前使用最多的激活函数,主要因为其收敛更快,并且能保持同样效果。
标准的ReLU函数为max(x, 0),当x>0时,输出x; 当x<=0时,输出0
f(x)=max(x,0)
层类型:ReLU
可选参数:
negative_slope:默认为0. 对标准的ReLU函数进行变化,如果设置了这个值,那么数据为负数时,就不再设置为0,而是用原始数据乘以negative_slope
layer {
name: "relu1"
type: "ReLU"
bottom: "pool1"
top: "pool1"
}
RELU层支持in-place计算,这意味着bottom的输出和输入相同以避免内存的消耗。
3、TanH / Hyperbolic Tangent
利用双曲正切函数对数据进行变换。
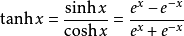
层类型:TanH
layer {
name: "layer"
bottom: "in"
top: "out"
type: "TanH"
}
4、Absolute Value
求每个输入数据的绝对值。
f(x)=Abs(x)
层类型:AbsVal
layer {
name: "layer"
bottom: "in"
top: "out"
type: "AbsVal"
}
5、Power
对每个输入数据进行幂运算
f(x)= (shift + scale * x) ^ power
层类型:Power
可选参数:
power: 默认为1
scale: 默认为1
shift: 默认为0

layer {
name: "layer"
bottom: "in"
top: "out"
type: "Power"
power_param {
power: 2
scale: 1
shift: 0
}
}
6、BNLL
binomial normal log likelihood的简称
f(x)=log(1 + exp(x))
层类型:BNLL
layer {
name: "layer"
bottom: "in"
top: "out"
type: “BNLL”
}
原文:http://www.cnblogs.com/denny402/p/5072507.html#3652385
目前大多数模型都是使用 RELU 激活函数,此外RELU支持原址( in-place)计算, 即它的底层 blob 和顶层 blob 可以是同一个以节省内存开销。
可以发现很多模型的RELU层内bottom和top为同一参数,但其他激活函数暂时不支持。
[转] caffe激活层及参数的更多相关文章
- 【转】Caffe初试(六)激活层及参数
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的.从bottom得到一个blob数据输入,运算后,从top输入一个blob数据.在运算过程中,没有改变数据的大小,即输入 ...
- 1、Caffe数据层及参数
要运行Caffe,需要先创建一个模型(model),每个模型由许多个层(layer)组成,每个层又都有自己的参数, 而网络模型和参数配置的文件分别是:caffe.prototxt,caffe.solv ...
- 【转】caffe数据层及参数
原文: 要运行caffe,需要先创建一个模型(model),如比较常用的Lenet,Alex等, 而一个模型由多个层(layer)构成,每一层又由许多参数组成.所有的参数都定义在caffe.proto ...
- 3、激活层(Activiation Layers)及参数
caffe激活层(Activiation Layers) 在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的.从bottom得到一个blob数据输入,运算后,从top输入 ...
- Caffe学习系列(4):激活层(Activiation Layers)及参数
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的.从bottom得到一个blob数据输入,运算后,从top输入一个blob数据.在运算过程中,没有改变数据的大小,即输入 ...
- 转 Caffe学习系列(4):激活层(Activiation Layers)及参数
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的.从bottom得到一个blob数据输入,运算后,从top输入一个blob数据.在运算过程中,没有改变数据的大小,即输入 ...
- caffe(4) 激活层(Activation Layers)及参数
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的.从bottom得到一个blob数据输入,运算后,从top输入一个blob数据.在运算过程中,没有改变数据的大小,即输入 ...
- Caffe学习系列(5):其它常用层及参数
本文讲解一些其它的常用层,包括:softmax_loss层,Inner Product层,accuracy层,reshape层和dropout层及其它们的参数配置. 1.softmax-loss so ...
- 转 Caffe学习系列(5):其它常用层及参数
本文讲解一些其它的常用层,包括:softmax_loss层,Inner Product层,accuracy层,reshape层和dropout层及其它们的参数配置. 1.softmax-loss so ...
随机推荐
- 【刷题】BZOJ 2151 种树
Description A城市有一个巨大的圆形广场,为了绿化环境和净化空气,市政府决定沿圆形广场外圈种一圈树.园林部门得到指令后,初步规划出n个种树的位置,顺时针编号1到n.并且每个位置都有一个美观度 ...
- 洛谷 P2146 [NOI2015]软件包管理器 解题报告
P2146 [NOI2015]软件包管理器 题目描述 Linux用户和OSX用户一定对软件包管理器不会陌生.通过软件包管理器,你可以通过一行命令安装某一个软件包,然后软件包管理器会帮助你从软件源下载软 ...
- (转)在Eclipse中用TODO标签管理任务(Task)
背景:eclipse是一款功能十分强大的编辑,如果能够熟练运用,必定事半功倍,但如果不求甚解,无疑是给自己制造麻烦. 1 标签的使用 1.1 起因 如上图所示,在程序中有很多todo的标签出现,但是却 ...
- svn cleanup
SVN 本地更新时,由于一些操作中断更新,如磁盘空间不够,用户取消. 可能会造成本地文件被锁定的情况.一般出现这种情况的解决方法: 1.可以使用SVN clean up来清除锁定. 2.如果不是本目录 ...
- RabbitMQ 客户端开发向导
准备工作:composer 引入 php-amqplib 说明:本文说明基于 Java(主要说明原理),实现使用 php RabbitMQ Java 客户端使用 com.rabbitmq.client ...
- mybatis与分布式事务的面试
mybatis的面试: https://www.cnblogs.com/huajiezh/p/6415388.html 本地事务与分布式事务: https://www.cnblogs.com/xcj2 ...
- 高性能网络编程(一):单台服务器并发TCP连接数到底可以有多少
高性能网络编程(一):单台服务器并发TCP连接数到底可以有多少 阅读(81374) | 评论(9)收藏16 淘帖1 赞3 JackJiang Lv.9 1 年前 | 前言 曾几何时我 ...
- Python 模块之shutil模块
#拷贝文件,可指定长度,fsrc和fdst都是一个文件对象 def copyfileobj(fsrc, fdst, length=16*1024) shutil.copyfileobj(open(&q ...
- Scala进阶之路-I/O流操作之文件处理
Scala进阶之路-I/O流操作之文件处理 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 说起Scala语言操作文件对象其实是很简单的,大部分代码和Java相同. 一.使用Scal ...
- Java基础-SSM之mybatis快速入门篇
Java基础-SSM之mybatis快速入门篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 其实你可能会问什么是SSM,简单的说就是spring mvc + Spring + m ...