通过mapreduce把mysql的数据读取到hdfs
前面讲过了怎么通过mapreduce把mysql的一张表的数据放到另外一张表中,这次讲的是把mysql的数据读取到hdfs里面去
具体怎么搭建环境我这里就不多说了。参考
通过mapreduce把mysql的一张表的数据导到另外一张表中
也在eclipse里面创建一个mapreduce工程

具体的实现代码
package com.gong.mrmysql; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Iterator; import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.lib.IdentityReducer;
import org.apache.hadoop.mapred.lib.db.DBConfiguration;
import org.apache.hadoop.mapred.lib.db.DBInputFormat;
import org.apache.hadoop.mapred.lib.db.DBOutputFormat;
import org.apache.hadoop.mapred.lib.db.DBWritable; /**
* Function: 测试 mr 与 mysql 的数据交互,此测试用例将一个表中的数据复制到另一张表中
* 实际当中,可能只需要从 mysql 读,或者写到 mysql 中。
* date: 2013-7-29 上午2:34:04 <br/>
* @author june
*/
public class Mysql2Mr {
// DROP TABLE IF EXISTS `hadoop`.`studentinfo`;
// CREATE TABLE studentinfo (
// id INTEGER NOT NULL PRIMARY KEY,
// name VARCHAR(32) NOT NULL); public static class StudentinfoRecord implements Writable, DBWritable {
int id;
String name; //构造方法
public StudentinfoRecord() { } //Writable接口是对数据流进行操作的,所以输入是DataInput类对象
public void readFields(DataInput in) throws IOException {
this.id = in.readInt(); //输入流中的读取下一个整数,并返回
this.name = Text.readString(in);
} public String toString() {
return new String(this.id + " " + this.name);
} //DBWritable负责对数据库进行操作,所以输出格式是PreparedStatement
//PreparedStatement接口继承并扩展了Statement接口,用来执行动态的SQL语句,即包含参数的SQL语句
@Override
public void write(PreparedStatement stmt) throws SQLException {
stmt.setInt(, this.id);
stmt.setString(, this.name);
} //DBWritable负责对数据库进行操作,输入格式是ResultSet
// ResultSet接口类似于一张数据表,用来暂时存放从数据库查询操作所获得的结果集
@Override
public void readFields(ResultSet result) throws SQLException {
this.id = result.getInt();
this.name = result.getString();
} //Writable接口是对数据流进行操作的,所以输出是DataOutput类对象
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(this.id);
Text.writeString(out, this.name);
}
} // 记住此处是静态内部类,要不然你自己实现无参构造器,或者等着抛异常:
// Caused by: java.lang.NoSuchMethodException: DBInputMapper.<init>()
// http://stackoverflow.com/questions/7154125/custom-mapreduce-input-format-cant-find-constructor
// 网上脑残式的转帖,没见到一个写对的。。。
public static class DBInputMapper extends MapReduceBase implements
Mapper<LongWritable, StudentinfoRecord, LongWritable, Text> {
public void map(LongWritable key, StudentinfoRecord value,
OutputCollector<LongWritable, Text> collector, Reporter reporter) throws IOException {
collector.collect(new LongWritable(value.id), new Text(value.toString()));
}
} public static class MyReducer extends MapReduceBase implements
Reducer<LongWritable, Text, StudentinfoRecord, Text> {
@Override
public void reduce(LongWritable key, Iterator<Text> values,
OutputCollector<StudentinfoRecord, Text> output, Reporter reporter) throws IOException {
String[] splits = values.next().toString().split(" ");
StudentinfoRecord r = new StudentinfoRecord();
r.id = Integer.parseInt(splits[]);
r.name = splits[];
output.collect(r, new Text(r.name));
}
} public static void main(String[] args) throws IOException {
JobConf conf = new JobConf(Mysql2Mr.class);
DistributedCache.addFileToClassPath(new Path("hdfs://192.168.241.13:9000/mysqlconnector/mysql-connector-java-5.1.38-bin.jar"), conf); conf.setMapOutputKeyClass(LongWritable.class);
conf.setMapOutputValueClass(Text.class);
conf.setOutputKeyClass(LongWritable.class);
conf.setOutputValueClass(Text.class); // conf.setOutputFormat(DBOutputFormat.class);
conf.setInputFormat(DBInputFormat.class); // mysql to hdfs
conf.set("fs.defaultFS", "hdfs://192.168.241.13:9000");//在配置文件conf中指定所用的文件系统---HDFS
conf.setReducerClass(IdentityReducer.class);
Path outPath = new Path("hdfs://192.168.241.13:9000/student/out1");
FileSystem.get(conf).delete(outPath, true);
FileOutputFormat.setOutputPath(conf, outPath); DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver", "jdbc:mysql://192.168.241.13:3306/mrtest",
"root", "");
String[] fields = { "id", "name" };
// 从 t 表读数据
DBInputFormat.setInput(conf, StudentinfoRecord.class, "t", null, "id", fields); // mapreduce 将数据输出到 t2 表
//DBOutputFormat.setOutput(conf, "t2", "id", "name"); // FileOutputFormat.setOutputPath(conf, new Path("hdfs://192.168.241.13:9000/student/out1")); conf.setMapperClass(org.apache.hadoop.mapred.lib.IdentityMapper.class);
conf.setMapperClass(DBInputMapper.class);
// conf.setReducerClass(MyReducer.class); JobClient.runJob(conf);
}
}
特别要主要的是在主函数里面添加这么一句话

如果不添加这句话的话就不能识别你的hdfs路径了,除了这个方法之外还,不想添加这句话的话还可以把集群的core-site.xml文件直接拷贝一份放到工程的src目录下
这样也是可以的
运行程序
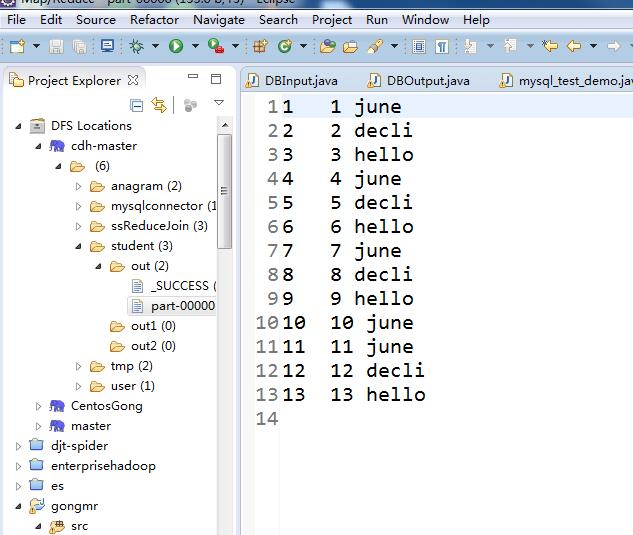
可以看到hdfs的文件上面已经有mysql数据库表的内容了
通过mapreduce把mysql的数据读取到hdfs的更多相关文章
- Mysql遍历大表(Mysql大量数据读取内存溢出的解决方法)
mysql jdbc默认把select的所有结果全部取回,放到内存中,如果是要遍历很大的表,则可能把内存撑爆. 一种办法是:用limit,offset,但这样你会发现取数据的越来越慢,原因是设置了of ...
- MySQL的数据读取过程
本文来自:http://blog.chinaunix.net/uid-20785090-id-4759476.html 对于build-in的innodb的架构,每次当发布IO请求时,究竟是mysql ...
- MYSQL 的数据读取方式
例子: create table T(X bit(8)); insert into T (X) values(b'11111111'); select X from T; 这个时候会发现这个X 是乱码 ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- 使用Sqoop从MySQL导入数据到Hive和HBase 及近期感悟
使用Sqoop从MySQL导入数据到Hive和HBase 及近期感悟 Sqoop 大数据 Hive HBase ETL 使用Sqoop从MySQL导入数据到Hive和HBase 及近期感悟 基础环境 ...
- 五.hadoop 从mysql中读取数据写到hdfs
目录: 目录见文章1 本文是基于windows下来操作,linux下,mysql-connector-java-5.1.46.jar包的放置有讲究. mr程序 import java.io.DataI ...
- pandas读取MySql/SqlServer数据 (转)
在 Anacondas环境中,conda install pymssql ,一直报包冲突,所以采用先在 https://www.lfd.uci.edu/~gohlke/pythonlibs/#nump ...
- 通过mapreduce把mysql的一张表的数据导到另外一张表中
怎么安装hadoop集群我在这里就不多说了,我这里安装的是三节点的集群 先在主节点安装mysql 启动mysql 登录mysql 创建数据库,创建表格,先把数据加载到表格 t ,表格t2是空的 mys ...
- 如何实现MySQL表数据随机读取?从mysql表中读取随机数据
文章转自 http://blog.efbase.org/2006/10/16/244/如何实现MySQL表数据随机读取?从mysql表中读取随机数据?以前在群里讨论过这个问题,比较的有意思.mysql ...
随机推荐
- 持续集成--Jenkins--1
持续集成之Jenkins安装部署 1.安装JDK Jenkins是Java编写的,所以需要先安装JDK,这里采用yum安装,如果对版本有需求,可以直接在Oracle官网下载JDK. [root@l ...
- c++获取键盘输入cin、scanf使用详解
cin是c++标准,scanf是在c中使用的 #include<cstdio> #include<iostream> #include<cstring> using ...
- C# Json数组序列化和反序列总结
1.创建json数组,例: JArray arrFile = new JArray(); arrFile.Add(new JObject() { new JProperty("FilePat ...
- mysql程序之mysqld_safe详解
mysqld_safe命令 mysqld_safe是在Unix上启动mysqld服务器的推荐方法.mysqld_safe增加了一些安全特性,例如在发生错误时重新启动服务器,并将运行时信息记录到错误日志 ...
- 【转】利用Psyco提升Python运行速度
转自:http://www.leeon.me/a/use-Psyco-to-improve-Python-speed Psyco 是严格地在 Python 运行时进行操作的.也就是说,Python 源 ...
- 【java】函数重载
重载概念(Overloading): 在同一个类中,允许存在一个以上的同名函数,主要他们的参数个数和参数类型不同即可 重载特点: 与返回值无关,只和参数类型和参数个数有关系(重载只和参数列表有关系) ...
- 黄聪:移动应用抓包调试利器Charles
一.Charles是什么? Charles是在 Mac或Windows下常用的http协议网络包截取工具,是一款屌的不行的抓包工具,在平常的测试与调式过程中,掌握此工具就基本可以不用其他抓包工具了 ...
- adb调试android设备 说的比较清楚的一篇文章
ADB支持两种连接Android系统的方式,USB方式及网络方式.一般手机及平板默认会设置为USB方式.android系统底层运行着一个服务(adbd),用于相应和管理大家在电脑端的adb命令连接,这 ...
- 进程守护为什么选择pm2
官网::: https://pm2.io/doc/en/runtime/quick-start/ 前言 源码:https://github.com/Unitech/pm2 这里的pm2并不是大气污染 ...
- svn项目清除svn链接信息
如果copy的项目原来有svn连接信息,测试新技术新方案时可能会有隐患,不小心上传svn很造成很多麻烦. 这时先删除svn连接是比较好的选择. 删除svn的方法是删除项目根目录下的.svn文件夹.这个 ...