通过mapreduce把mysql的数据读取到hdfs
前面讲过了怎么通过mapreduce把mysql的一张表的数据放到另外一张表中,这次讲的是把mysql的数据读取到hdfs里面去
具体怎么搭建环境我这里就不多说了。参考
通过mapreduce把mysql的一张表的数据导到另外一张表中
也在eclipse里面创建一个mapreduce工程

具体的实现代码
package com.gong.mrmysql; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Iterator; import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.lib.IdentityReducer;
import org.apache.hadoop.mapred.lib.db.DBConfiguration;
import org.apache.hadoop.mapred.lib.db.DBInputFormat;
import org.apache.hadoop.mapred.lib.db.DBOutputFormat;
import org.apache.hadoop.mapred.lib.db.DBWritable; /**
* Function: 测试 mr 与 mysql 的数据交互,此测试用例将一个表中的数据复制到另一张表中
* 实际当中,可能只需要从 mysql 读,或者写到 mysql 中。
* date: 2013-7-29 上午2:34:04 <br/>
* @author june
*/
public class Mysql2Mr {
// DROP TABLE IF EXISTS `hadoop`.`studentinfo`;
// CREATE TABLE studentinfo (
// id INTEGER NOT NULL PRIMARY KEY,
// name VARCHAR(32) NOT NULL); public static class StudentinfoRecord implements Writable, DBWritable {
int id;
String name; //构造方法
public StudentinfoRecord() { } //Writable接口是对数据流进行操作的,所以输入是DataInput类对象
public void readFields(DataInput in) throws IOException {
this.id = in.readInt(); //输入流中的读取下一个整数,并返回
this.name = Text.readString(in);
} public String toString() {
return new String(this.id + " " + this.name);
} //DBWritable负责对数据库进行操作,所以输出格式是PreparedStatement
//PreparedStatement接口继承并扩展了Statement接口,用来执行动态的SQL语句,即包含参数的SQL语句
@Override
public void write(PreparedStatement stmt) throws SQLException {
stmt.setInt(, this.id);
stmt.setString(, this.name);
} //DBWritable负责对数据库进行操作,输入格式是ResultSet
// ResultSet接口类似于一张数据表,用来暂时存放从数据库查询操作所获得的结果集
@Override
public void readFields(ResultSet result) throws SQLException {
this.id = result.getInt();
this.name = result.getString();
} //Writable接口是对数据流进行操作的,所以输出是DataOutput类对象
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(this.id);
Text.writeString(out, this.name);
}
} // 记住此处是静态内部类,要不然你自己实现无参构造器,或者等着抛异常:
// Caused by: java.lang.NoSuchMethodException: DBInputMapper.<init>()
// http://stackoverflow.com/questions/7154125/custom-mapreduce-input-format-cant-find-constructor
// 网上脑残式的转帖,没见到一个写对的。。。
public static class DBInputMapper extends MapReduceBase implements
Mapper<LongWritable, StudentinfoRecord, LongWritable, Text> {
public void map(LongWritable key, StudentinfoRecord value,
OutputCollector<LongWritable, Text> collector, Reporter reporter) throws IOException {
collector.collect(new LongWritable(value.id), new Text(value.toString()));
}
} public static class MyReducer extends MapReduceBase implements
Reducer<LongWritable, Text, StudentinfoRecord, Text> {
@Override
public void reduce(LongWritable key, Iterator<Text> values,
OutputCollector<StudentinfoRecord, Text> output, Reporter reporter) throws IOException {
String[] splits = values.next().toString().split(" ");
StudentinfoRecord r = new StudentinfoRecord();
r.id = Integer.parseInt(splits[]);
r.name = splits[];
output.collect(r, new Text(r.name));
}
} public static void main(String[] args) throws IOException {
JobConf conf = new JobConf(Mysql2Mr.class);
DistributedCache.addFileToClassPath(new Path("hdfs://192.168.241.13:9000/mysqlconnector/mysql-connector-java-5.1.38-bin.jar"), conf); conf.setMapOutputKeyClass(LongWritable.class);
conf.setMapOutputValueClass(Text.class);
conf.setOutputKeyClass(LongWritable.class);
conf.setOutputValueClass(Text.class); // conf.setOutputFormat(DBOutputFormat.class);
conf.setInputFormat(DBInputFormat.class); // mysql to hdfs
conf.set("fs.defaultFS", "hdfs://192.168.241.13:9000");//在配置文件conf中指定所用的文件系统---HDFS
conf.setReducerClass(IdentityReducer.class);
Path outPath = new Path("hdfs://192.168.241.13:9000/student/out1");
FileSystem.get(conf).delete(outPath, true);
FileOutputFormat.setOutputPath(conf, outPath); DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver", "jdbc:mysql://192.168.241.13:3306/mrtest",
"root", "");
String[] fields = { "id", "name" };
// 从 t 表读数据
DBInputFormat.setInput(conf, StudentinfoRecord.class, "t", null, "id", fields); // mapreduce 将数据输出到 t2 表
//DBOutputFormat.setOutput(conf, "t2", "id", "name"); // FileOutputFormat.setOutputPath(conf, new Path("hdfs://192.168.241.13:9000/student/out1")); conf.setMapperClass(org.apache.hadoop.mapred.lib.IdentityMapper.class);
conf.setMapperClass(DBInputMapper.class);
// conf.setReducerClass(MyReducer.class); JobClient.runJob(conf);
}
}
特别要主要的是在主函数里面添加这么一句话

如果不添加这句话的话就不能识别你的hdfs路径了,除了这个方法之外还,不想添加这句话的话还可以把集群的core-site.xml文件直接拷贝一份放到工程的src目录下
这样也是可以的
运行程序
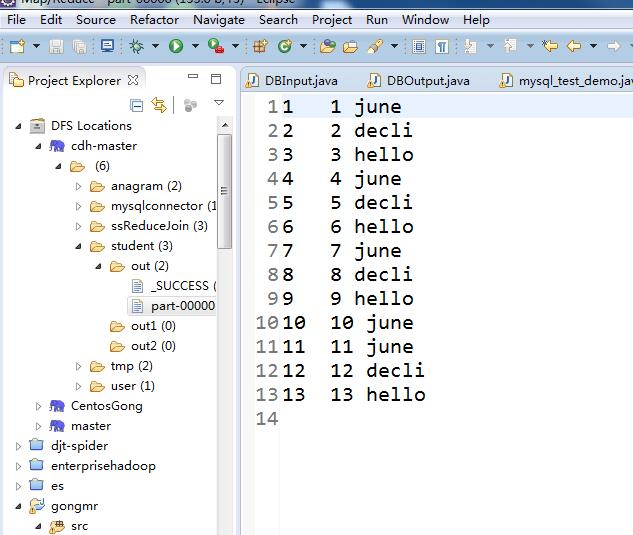
可以看到hdfs的文件上面已经有mysql数据库表的内容了
通过mapreduce把mysql的数据读取到hdfs的更多相关文章
- Mysql遍历大表(Mysql大量数据读取内存溢出的解决方法)
mysql jdbc默认把select的所有结果全部取回,放到内存中,如果是要遍历很大的表,则可能把内存撑爆. 一种办法是:用limit,offset,但这样你会发现取数据的越来越慢,原因是设置了of ...
- MySQL的数据读取过程
本文来自:http://blog.chinaunix.net/uid-20785090-id-4759476.html 对于build-in的innodb的架构,每次当发布IO请求时,究竟是mysql ...
- MYSQL 的数据读取方式
例子: create table T(X bit(8)); insert into T (X) values(b'11111111'); select X from T; 这个时候会发现这个X 是乱码 ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- 使用Sqoop从MySQL导入数据到Hive和HBase 及近期感悟
使用Sqoop从MySQL导入数据到Hive和HBase 及近期感悟 Sqoop 大数据 Hive HBase ETL 使用Sqoop从MySQL导入数据到Hive和HBase 及近期感悟 基础环境 ...
- 五.hadoop 从mysql中读取数据写到hdfs
目录: 目录见文章1 本文是基于windows下来操作,linux下,mysql-connector-java-5.1.46.jar包的放置有讲究. mr程序 import java.io.DataI ...
- pandas读取MySql/SqlServer数据 (转)
在 Anacondas环境中,conda install pymssql ,一直报包冲突,所以采用先在 https://www.lfd.uci.edu/~gohlke/pythonlibs/#nump ...
- 通过mapreduce把mysql的一张表的数据导到另外一张表中
怎么安装hadoop集群我在这里就不多说了,我这里安装的是三节点的集群 先在主节点安装mysql 启动mysql 登录mysql 创建数据库,创建表格,先把数据加载到表格 t ,表格t2是空的 mys ...
- 如何实现MySQL表数据随机读取?从mysql表中读取随机数据
文章转自 http://blog.efbase.org/2006/10/16/244/如何实现MySQL表数据随机读取?从mysql表中读取随机数据?以前在群里讨论过这个问题,比较的有意思.mysql ...
随机推荐
- PHP实现IP访问限制及提交次数的方法详解
一.原理 提交次数是肯定要往数据库里写次数这个数据的,比如用户登陆,当用户出错时就忘数据库写入出错次数1,并且出错时间,再出错写2,当满比如5次时提示不允许再登陆,请明天再试,然后用DateDiff计 ...
- 反转链表 II
反转从位置 m 到 n 的链表.请使用一趟扫描完成反转. 说明:1 ≤ m ≤ n ≤ 链表长度. 示例: 输入: 1->2->3->4->5->NULL, m = 2, ...
- RedHat6.5创建本地yum源
拷贝Linux操作系统的rhel-server-6.5-x86_64-dvd.iso镜像到装好的Linux中: #执行挂载命令 mount –o loop /media/rhel-server-6.5 ...
- Linux命令之sed
sed命令格式 sed [options] 'command' file(s) 选项 -e :直接在命令行模式上进行sed动作编辑,此为默认选项; -f :将sed的动作写在一个文件内,用–f fil ...
- windows10中git-bash闪退的解决办法
windows10中git-bash闪退的解决办法 出现错误详情 Windows10 64位专业版安装git .18之后出现 Git闪退,报错信息:bash: /dev/null: No such d ...
- 关于SQL Server 无法生成 FRunCM 线程(不完全)
在五一的前一天,准备启动数据库完成我剩下的项目代码时,数据库配置管理器出现了一个让人蛋疼的问题sqlserv配置管理器出现请求失败或服务器未及时响应关于这个问题的处理方法,经过我两个小时的百度,网上对 ...
- NSIS 制作简单安装包
;replace NSIS/Contrib/zip2exe/Modern.nsh;NSI format: Asni;http://nsis.sourceforge.net/ ;UAC级别Request ...
- laravel5.5 excel的安装和使用
在项目开发中 最常用的就是把数据导出成excel的文件报表了 然而新下的项目中啥也没有;没有excel的扩展 会报这个错误 然后你需要通过composer安装这个依赖 学习源头:https://www ...
- 代码从Polyline读取到的坐标和属性对话框显示的不一样?
属性窗口中查询的第一个点坐标: 程序输出的各个点坐标: 差这么多? 原来是坐标系的问题,程序查询到的是世界坐标,属性窗口中是当前ucs坐标 Document doc = Application.Doc ...
- ALGO-145_蓝桥杯_算法训练_4-1打印下述图形
记: 这里用到了printf("%*s%s%*s\n",n-i,"",arr,n-i,"");的写法, 其中%*s中的*代表该字符串s的个数 ...