STL测试3)优先级队列实现二叉堆
用法:
big_heap.empty();判断堆是否为空
big_heap.pop();弹出栈顶元素最大值
big_heap.push(x);将x添加到最大堆
big_heap.top();返回栈顶元素;
big_heap.size();返回堆中元素个数
简单的应用
#include<stdio.h>
#include<queue>
#include<vector>
#include<functional> using namespace std; int main()
{ priority_queue <int> big_heap;//默认构造是最大堆
priority_queue<int, vector<int>, greater<int> > small_heap;//最小堆
priority_queue<int, vector<int>, less<int> > big_heap2;//最大堆
if(big_heap.empty())
{
printf("big_heap is empty\n");
}
int test[]={,,,,,,}; for(int i=;i< ;i++)
{ big_heap.push(test[i]);
small_heap.push(test[i]);
printf("input %d,big_heap top is %d ,small_heap top is%d\n",test[i],big_heap.top(),small_heap.top());
}
big_heap.push();
small_heap.push();
printf("now big_heap top is %d\nnow small_heap top is %d\n",big_heap.top(),small_heap.top()); for(int i=;i<;i++)
{ big_heap.pop();
small_heap.pop();
} printf("now heap has %d num,the max is %d,the min is%d\n",big_heap.size(),big_heap.top(),small_heap.top());
return ;
}
下面来一个简单的应用
在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
示例 1:
输入: [3,2,1,5,6,4] 和 k = 2
输出: 5
示例 2:
输入: [3,2,3,1,2,4,5,5,6] 和 k = 4
输出: 4
说明:
你可以假设 k 总是有效的,且 1 ≤ k ≤ 数组的长度。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/kth-largest-element-in-an-array
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
思路:
维护一个K大小的最小堆,如果堆中栈顶的元素<k,直接入堆;此外情况如果堆顶的元素小于新元素的时候,弹出堆顶,将新元素入堆。
这样保证堆外的元素都是比堆顶小的,不然会把该元素和堆顶的元素置换,这样保证最后堆里存的是k个最大的元素,且堆顶是这k个元素里最小的。那么堆顶倒数第k小的就是第k大的了。
代码写在下面。
下面是一个利用最大堆和最小堆求中位数的问题。
中位数是有序列表中间的数。如果列表长度是偶数,中位数则是中间两个数的平均值。
例如,
[2,3,4] 的中位数是 3
[2,3] 的中位数是 (2 + 3) / 2 = 2.5
设计一个支持以下两种操作的数据结构:
void addNum(int num) - 从数据流中添加一个整数到数据结构中。
double findMedian() - 返回目前所有元素的中位数。
示例:
addNum(1)
addNum(2)
findMedian() -> 1.5
addNum(3)
findMedian() -> 2
进阶:
如果数据流中所有整数都在 0 到 100 范围内,你将如何优化你的算法?
如果数据流中 99% 的整数都在 0 到 100 范围内,你将如何优化你的算法?
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/find-median-from-data-stream
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
思路就是设计一个最大堆和最小堆分别存储一般数据,并维持两个堆中最大堆的堆顶比最小堆小。这样如果两个堆大小相同,那么中位数就是两个堆顶的平均值,如果是堆大小不同,那么中位数就是size大的那个堆的堆顶。
看到一个别人画的示意图,非常形象,这里搬过来方便以后理解。
addNum 函数设计
addNum() 函数在添加元素的过程中保持两个堆的动态平衡:
Condition 1.保证两堆元素个数相差不超过 1 |
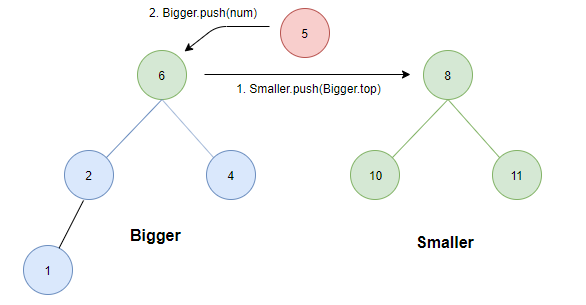
case 1:
- 如果两堆中的元素个数相同。这个时候无论插入哪一个堆,条件 1 都不会被破坏,因此考虑条件 2 ,将待插入元素与两堆的堆顶比较:若待插入元素为 5,显然这个时候若插入smaller会破坏条件 2,因此因插入bigger中。而若待插入为 9 则显然应插入 smaller 中。
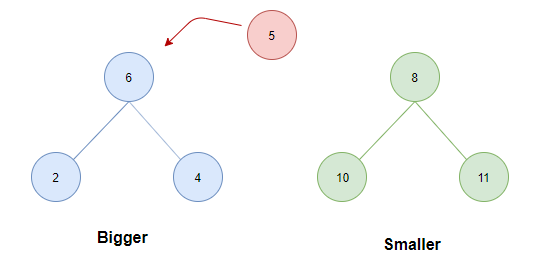
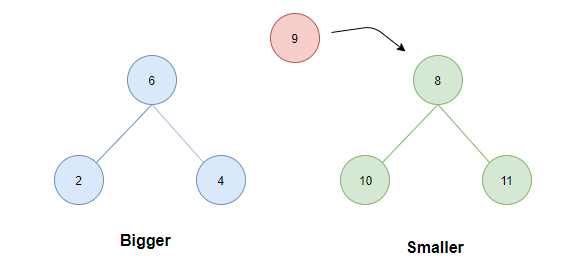
case 2:
- 如果大顶堆元素个数小于小顶堆的元素个数。此时,将待插入元素与两堆堆顶比较:
- 若小于等于Bigger.top则直接插入Bigger中;
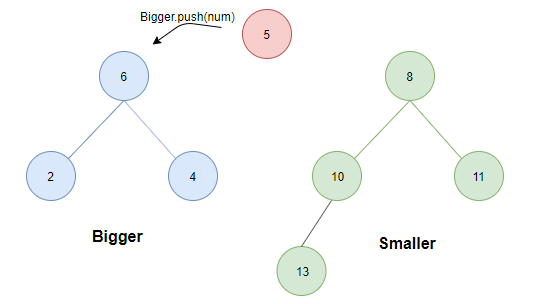
- 若大于smaller.top则为了保证条件1,需将smaller中的最小值(根)转存至Bigger中。
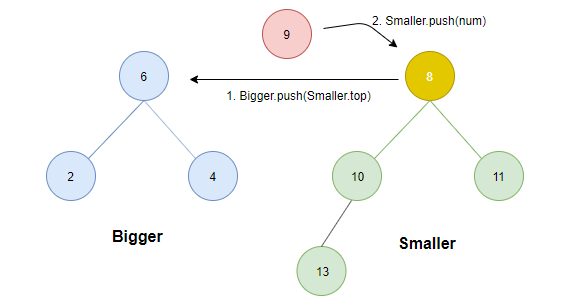
case 3:
- 如果大顶堆的元素个数大于小顶堆的元素个数。此时,将待插入元素与两堆堆顶比较:
- 若其大于等于Smaller.top则直接插入Smaller中;
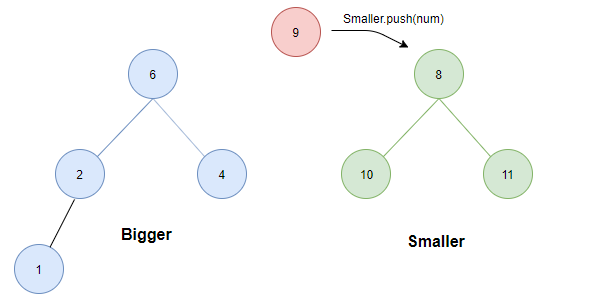
- 若小于Bigger.top则为了保证条件1,需将Bigger中的最大元素值(根)转存至Smaller中。
最后是实现以后的代码:
class MedianFinder {
public:
priority_queue <int> big_queue;
priority_queue<int, vector <int>, greater <int> > small_queue;
/** initialize your data structure here. */
MedianFinder() {
}
void addNum(int num) {
if(big_queue.empty())
{
big_queue.push(num);
return;
}
if(big_queue.size() == small_queue.size())
{
if(num < big_queue.top())
{
big_queue.push(num);
}
else
{
small_queue.push(num);
}
}
else if(big_queue.size() > small_queue.size())
{
if(num > big_queue.top())
{
small_queue.push(num);
}
else
{
small_queue.push(big_queue.top());
big_queue.pop();
big_queue.push(num);
}
}
else if(big_queue.size() < small_queue.size())
{
if(num < small_queue.top())
{
big_queue.push(num);
}
else
{
big_queue.push(small_queue.top());
small_queue.pop();
small_queue.push(num);
}
}
}
double findMedian() {
if(big_queue.size() == small_queue.size())
return ((big_queue.top()+small_queue.top())/2.0);
else if(big_queue.size() > small_queue.size())
return big_queue.top();
else
return small_queue.top();
}
};
STL测试3)优先级队列实现二叉堆的更多相关文章
- 【数据结构与算法Python版学习笔记】树——利用二叉堆实现优先级队列
概念 队列有一个重要的变体,叫作优先级队列. 和队列一样,优先级队列从头部移除元素,不过元素的逻辑顺序是由优先级决定的. 优先级最高的元素在最前,优先级最低的元素在最后. 实现优先级队列的经典方法是使 ...
- STL中的优先级队列priority_queue
priority_queue(queue类似)完全以底部容器为根据,再加上二叉堆(大根堆或者小根堆)的实现原理,所以其实现非常简单,缺省情况下priority_queue以vector作为底部容器.另 ...
- 洛谷P2827 [NOIP2016 提高组] 蚯蚓 (二叉堆/队列)
容易想到的是用二叉堆来解决,切断一条蚯蚓,其他的都要加上一个值,不妨用一个表示偏移量的delta. 1.取出最大的x,x+=delta: 2.算出切断后的两个新长度,都减去delta和q: 3.del ...
- 纯数据结构Java实现(6/11)(二叉堆&优先队列)
堆其实也是树结构(或者说基于树结构),一般可以用堆实现优先队列. 二叉堆 堆可以用于实现其他高层数据结构,比如优先队列 而要实现一个堆,可以借助二叉树,其实现称为: 二叉堆 (使用二叉树表示的堆). ...
- Binary Heap(二叉堆) - 堆排序
这篇的主题主要是Heapsort(堆排序),下一篇ADT数据结构随笔再谈谈 - 优先队列(堆). 首先,我们先来了解一点与堆相关的东西.堆可以实现优先队列(Priority Queue),看到队列,我 ...
- 数据结构图文解析之:二叉堆详解及C++模板实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- 二叉堆(binary heap)
堆(heap) 亦被称为:优先队列(priority queue),是计算机科学中一类特殊的数据结构的统称.堆通常是一个可以被看做一棵树的数组对象.在队列中,调度程序反复提取队列中第一个作业并运行,因 ...
- D&F学数据结构系列——二叉堆
二叉堆(binary heap) 二叉堆数据结构是一种数组对象,它可以被视为一棵完全二叉树.同二叉查找树一样,堆也有两个性质,即结构性和堆序性.对于数组中任意位置i上的元素,其左儿子在位置2i上,右儿 ...
- 【算法与数据结构】二叉堆和优先队列 Priority Queue
优先队列的特点 普通队列遵守先进先出(FIFO)的规则,而优先队列虽然也叫队列,规则有所不同: 最大优先队列:优先级最高的元素先出队 最小优先队列:优先级最低的元素先出队 优先队列可以用下面几种数据结 ...
随机推荐
- harbor私有仓库安装
准备环境 centos7.4 docker-ce 19.03.8 docker-compose version 1.18.0 harbor 版本: 1.7.5 一.安装dokcer # 安装依赖包 ...
- CSS3动画基础
编写页面 记事本或SublimeText或vscode编写html: <html> <div id="box"></div> <style ...
- [原创][开源] SunnyUI.Net 更新日志
SunnyUI.Net, 基于 C# .Net WinForm 开源控件库.工具类库.扩展类库.多页面开发框架 Blog: https://www.cnblogs.com/yhuse Gitee: h ...
- [转] strtol()详解
点击此处阅读原文 今天,在review 一些代码的时候,看到了strtol()这个函数,由于以前使用它的时候,还没有深刻的了解,这次,我决定探个究竟. 网上关于这个函数的资料大都来源于同份资料,lin ...
- Jupyter的搭建
在家实在无聊,伏案沉思良久,忽然灵机一动,何不写写Python?然而电脑上的软件早已人是物非,Pycharm已然不复存在.但是又不想装软件找激活码,于是,只好建个Jupyter先凑合一下. 1. 安装 ...
- [CF163E]e-Government
题目 点这里看题目. 分析 首先,我们不需要真的从 AC 自动机中把串删掉.由于我们计算贡献和,我们只需要在 AC 自动机上,把已经删除的串的贡献抹掉就可以了. 接着考虑询问.这是一个很基 ...
- Node.js 学习笔记(一)
node.js说白了就是JavaScript. node.js的性能是php的86倍(大概). 在下载完后可以用命令行打开及运行. 什么是 Web 服务器? Web服务器一般指网站服务器,是指驻留 ...
- 最后一面挂在volatile关键字上,面试官:重新学学Java吧!
最后一面挂在volatile关键字上,面试官:重新学学Java吧! 为什么会有volatile关键字? volatile: 易变的; 无定性的; 无常性的; 可能急剧波动的; 不稳定的; 易恶化的; ...
- Java对象转换Json的细节处理
一.fastJson 1.fastJson在转换java对象为json的时候,默认是不序列化null值对应的key的 也就是说当对象里面的属性为空的时候,在转换成json时,不序列化那些为null值的 ...
- 浅谈async 及 await
async 及 await 涉及面试题:async 及 await 的特点,它们的优点和缺点分别是什么?await 原理是什么? 一个函数如果加上 async ,那么该函数就会返回一个 Promise ...