提升GAN的技术 Tips for Improving GAN
Wasserstein GAN (WGAN)
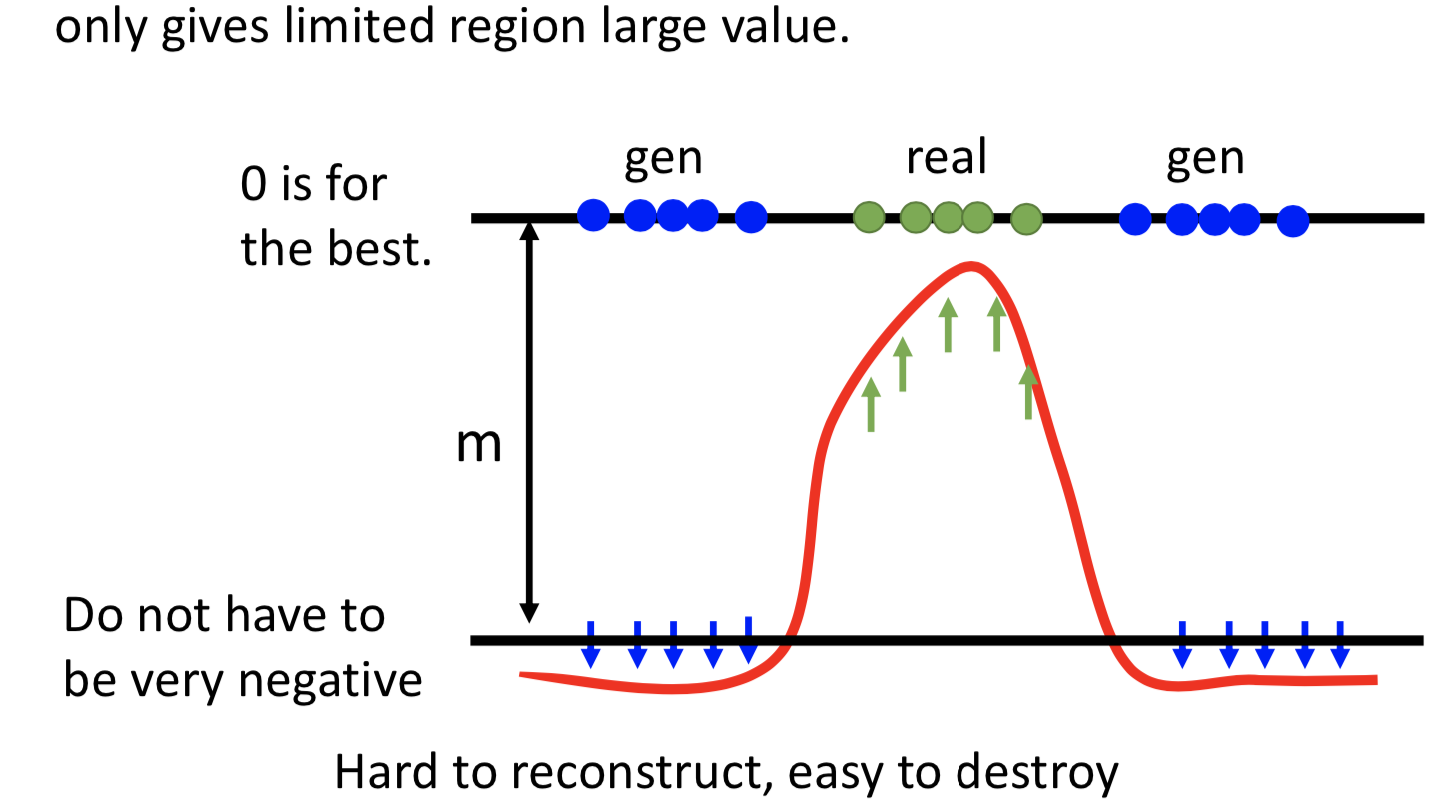
在一些情况下,用 JS散度来衡量两个分布的远近并不适合:
1. 数据是高维空间中的低维流形(manifold),两个分布在高维空间中的 overlap 少到可以忽略。

2. 由于 sampling 的局限性,即使两个分布之间真的存在一定的 overlap,但如果采样的数据不够多的话,可能实际上并不能体现出来。
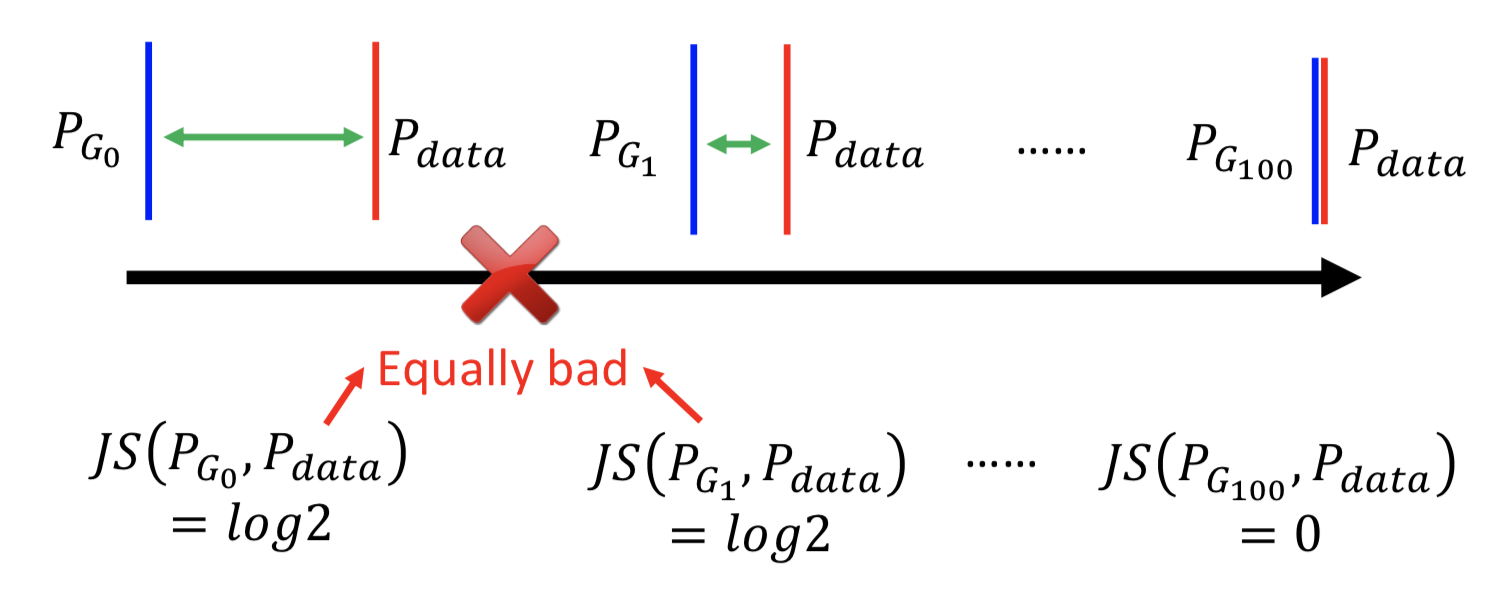
在这种情况,GAN 训练过程中用JS散度来衡量分布之间的距离,即使已经很接近但是没有重合,还是会计算为常数 2log2,那在训练 D 的过程中 loss 就没有改变,梯度也就一直不变,整个 GAN 的 minmax 训练就变得困难。
Earth Mover’s Distance
不用JS散度,用 The Earth Mover's Distance http://homepages.inf.ed.ac.uk/rbf/CVonline/LOCAL_COPIES/RUBNER/emd.htm
所有的 moving plan 中平均距离最小的
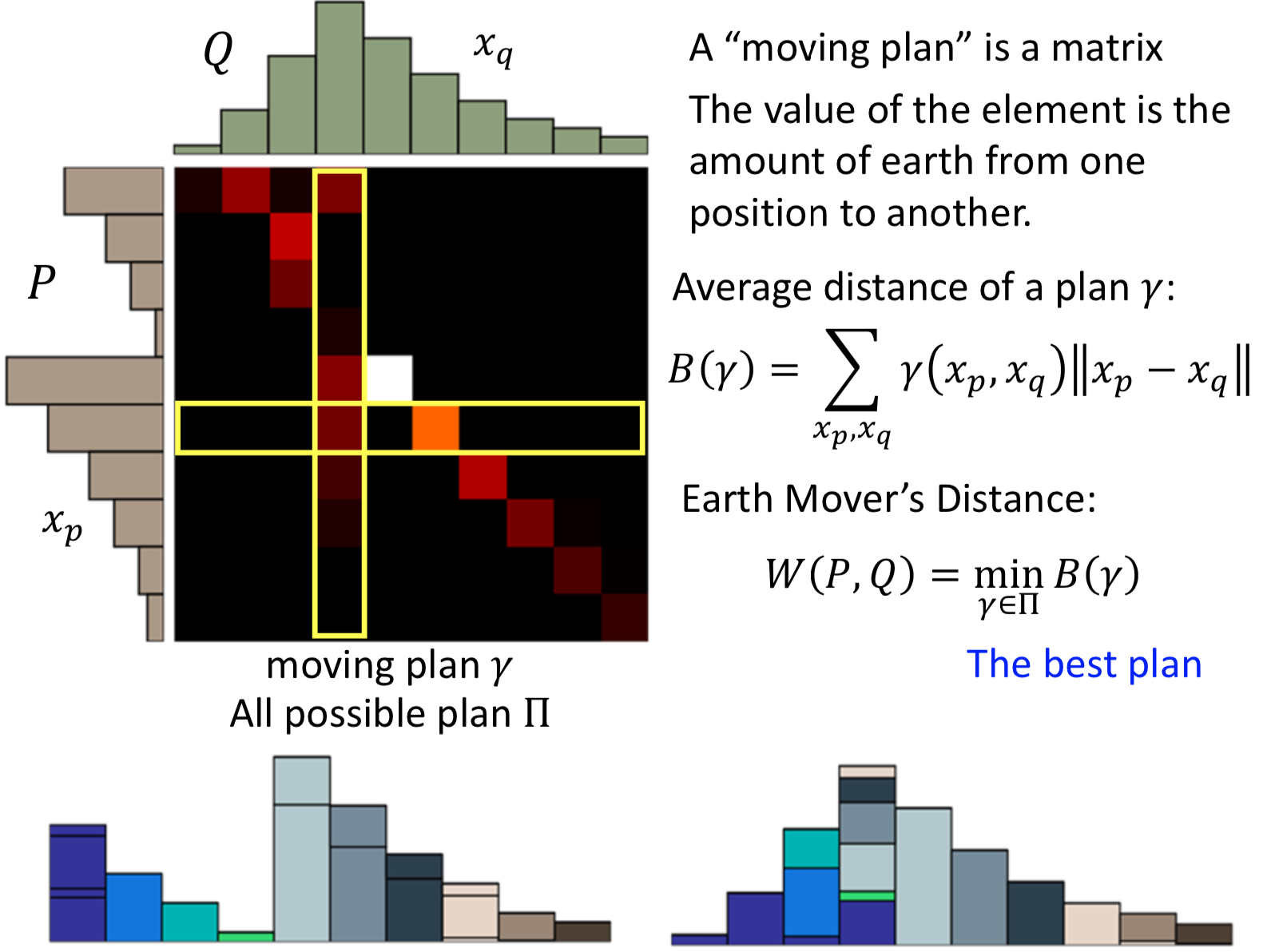
好处就是,即使两个分布没有overlap,还是能够体现出距离远近。怎么应用到 GAN 的目标函数中呢?
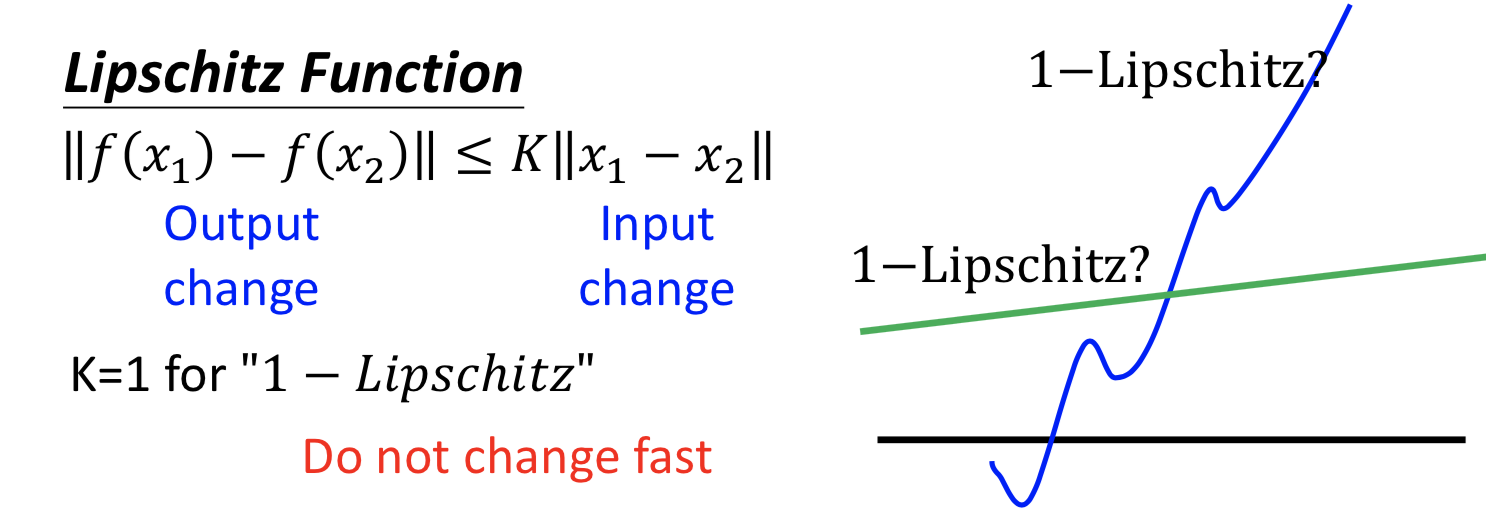
把 D 的最后一层的 sigmoid 函数拿掉,让 D 变成一个 real-value function ,但必须是 1-Lipschitz 连续的。(就是要让这个函数平滑,避免无法收敛的情况)

Lipschitz 函数的定义,K=1 的时候就是 1-Lipschitz 函数,y的变化总是比x的变化要小,就会比较平滑。
实施 1-Lipschitz 约束的方法:
1. weight clipping:Force the parameters w between c and -c. After parameter update, if w > c, w = c; if w < -c, w = -c. 但是这个做法比较粗糙,会导致 weights 大部分都直接被截在+c和-c,相当于减弱了NN的拟合能力。
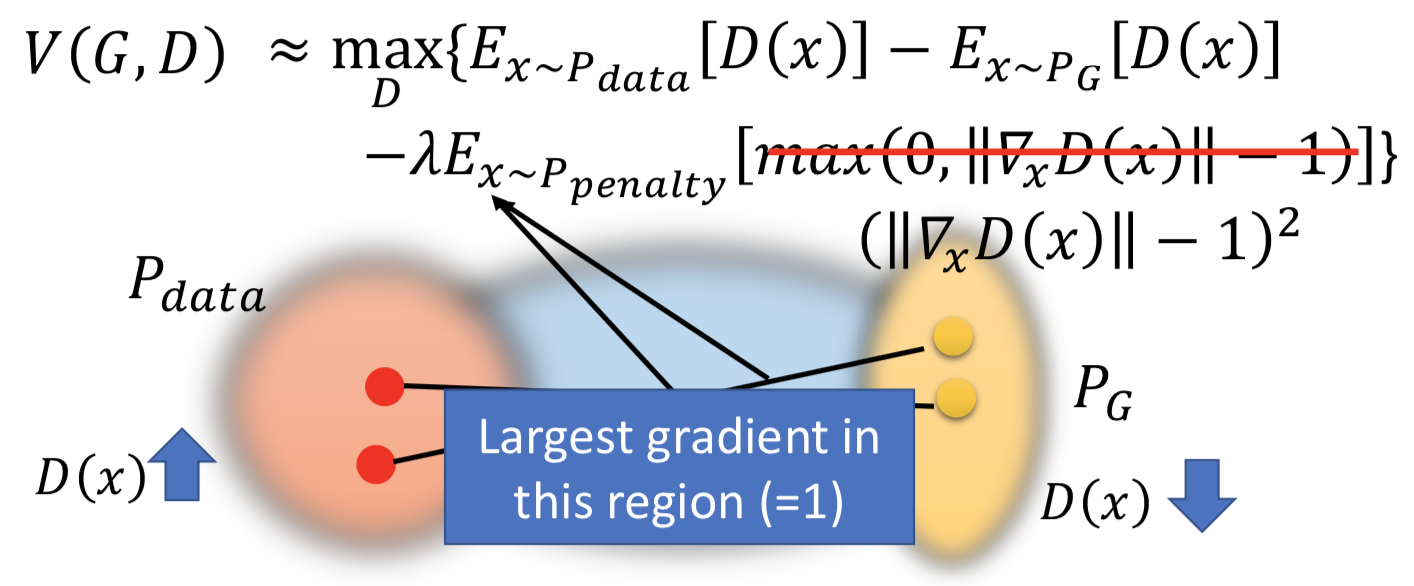
2. gradient penalty(WGAN-GP):A differentiable function is 1-Lipschitz if and only if it has gradients with norm less than or equal to 1 everywhere. 这个做法就是从 1-Lipschitz 函数定义出发了,但没办法真的做到对 x 积分,所以通过在P_data 和 P_G 之间随机插值采样来实现 from P_penalty 对里面的 max 函数求期望,近似积分项。
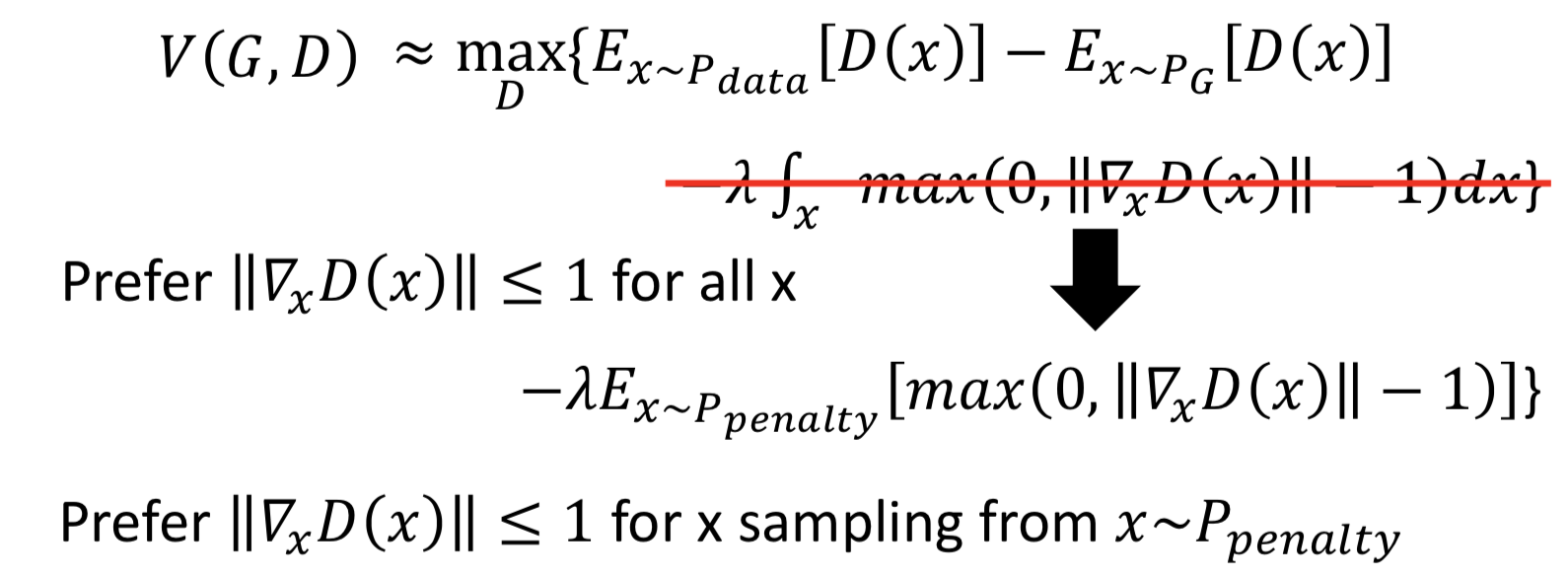
为什么是在 P_data 和 P_G 之间插值呢?
因为论文中表示,这样做效果好。而且这个区域的点能够反映 how P_G moves to P_data,其他的 region 反正 P_G 也走不到,干脆就不管它。
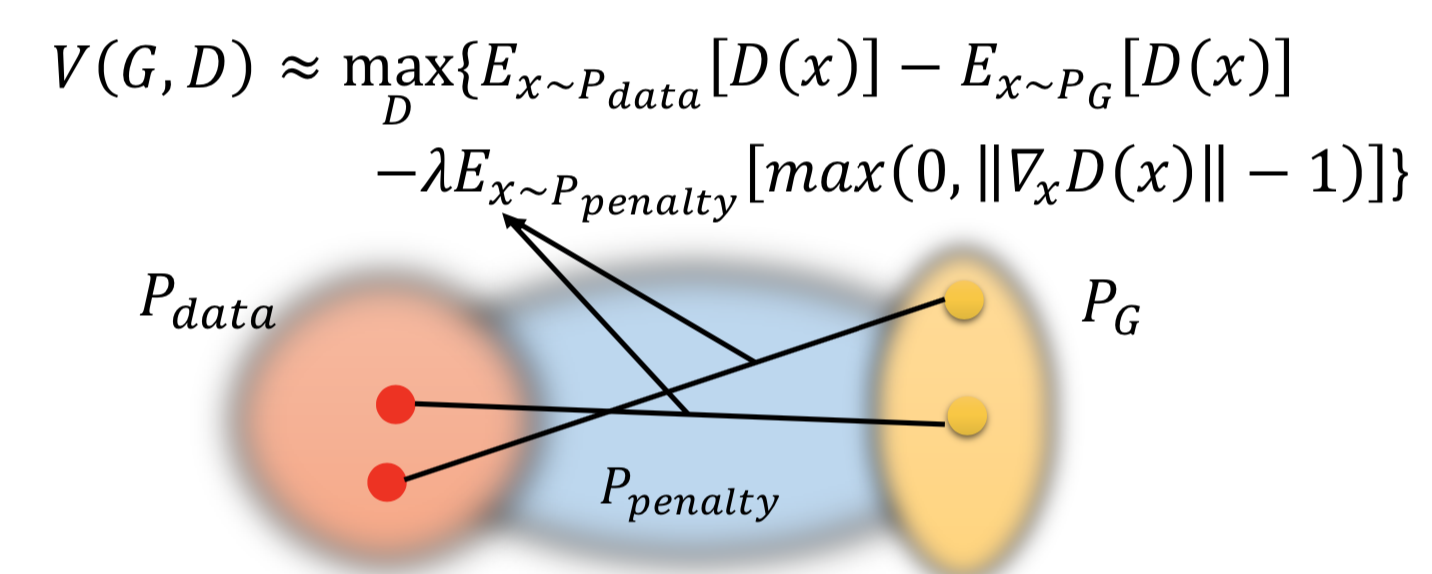
实际做的时候,gradient 的 norm 大于或小于 1 都会惩罚,原因也是做实验效果好:
3. Spectrum Norm
总结一下,WGAN:

Energy-based GAN (EBGAN)
用一个 ae 来当作 discriminator,generator不改变。不用二分类器来做判别,而是依据自编码器的 negative reconstruction error 。这样做的好处是 ae 可以事先单独拿出来只用real data 就能 pre-train 。
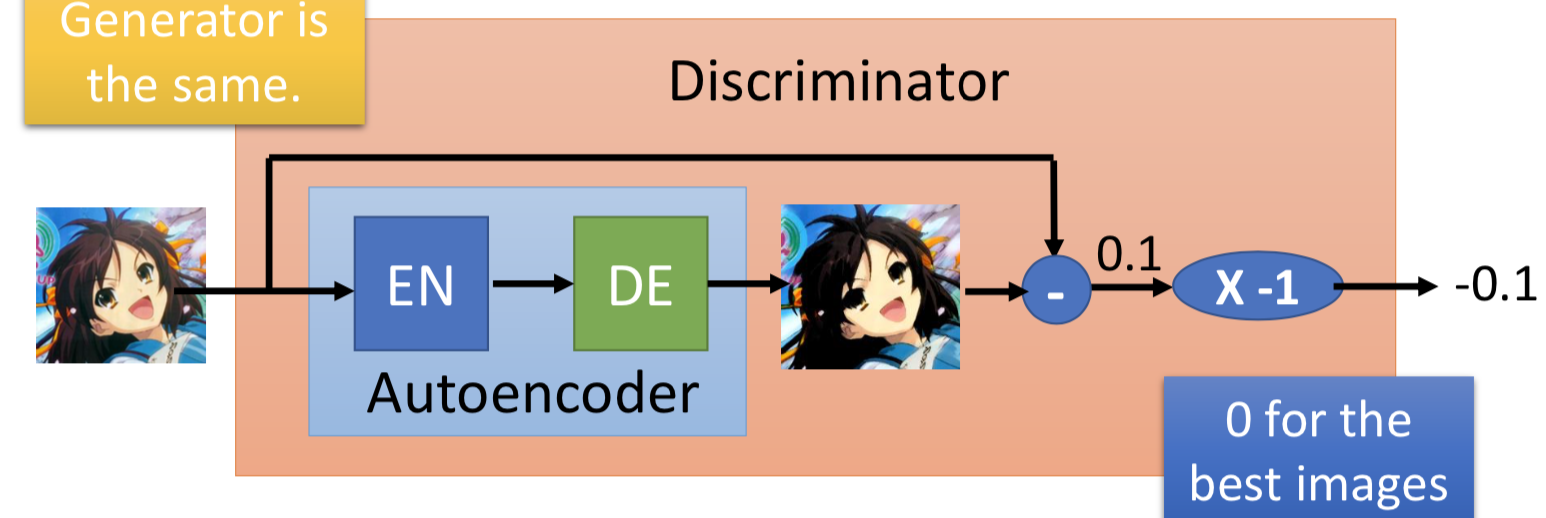
另外一个要特别注意的是,并不是要让 generated data 的 reconstruction error 越大越好,所以要设置一个margin,generated data 的 reconstruction error 小于这个阈值就好
提升GAN的技术 Tips for Improving GAN的更多相关文章
- TIPS FOR IMPROVING PERFORMANCE OF KAFKA PRODUCER
When we are talking about performance of Kafka Producer, we are really talking about two different t ...
- tflearn kears GAN官方demo代码——本质上GAN是先训练判别模型让你能够识别噪声,然后生成模型基于噪声生成数据,目标是让判别模型出错。GAN的过程就是训练这个生成模型参数!!!
GAN:通过 将 样本 特征 化 以后, 告诉 模型 哪些 样本 是 黑 哪些 是 白, 模型 通过 训练 后, 理解 了 黑白 样本 的 区别, 再输入 测试 样本 时, 模型 就可以 根据 以往 ...
- GAN生成的评价指标 Evaluation of GAN
传统方法中,如何衡量一个generator ?-- 用 generator 产生数据的 likelihood,越大越好. 但是 GAN 中的 generator 是隐式建模,所以只能从 P_G 中采样 ...
- 基于GAN的特征抽取 Feature Extraction by GAN
InfoGAN 期望的是 input 的每一个维度都能表示输出数据的某种特征.但实际改变输入的一个特定维度取值,很难发现输出数据随之改变的规律. InfoGAN 就是想解决这个问题.在 GAN 结构以 ...
- 生成式对抗网络(GAN)学习笔记
图像识别和自然语言处理是目前应用极为广泛的AI技术,这些技术不管是速度还是准确度都已经达到了相当的高度,具体应用例如智能手机的人脸解锁.内置的语音助手.这些技术的实现和发展都离不开神经网络,可是传统的 ...
- 生成对抗网络(Generative Adversarial Networks,GAN)初探
1. 从纳什均衡(Nash equilibrium)说起 我们先来看看纳什均衡的经济学定义: 所谓纳什均衡,指的是参与人的这样一种策略组合,在该策略组合上,任何参与人单独改变策略都不会得到好处.换句话 ...
- 学习笔记GAN003:GAN、DCGAN、CGAN、InfoGAN
GAN应用集中在图像生成,NLP.Robt Learning也有拓展.类似于NLP中的Actor-Critic. https://arxiv.org/pdf/1610.01945.pdf . Gen ...
- 深度学习新星:GAN的基本原理、应用和走向
深度学习新星:GAN的基本原理.应用和走向 (本文转自雷锋网,转载已获取授权,未经允许禁止转载)原文链接:http://www.leiphone.com/news/201701/Kq6FvnjgbKK ...
- [GAN] Generative networks
中文版:https://zhuanlan.zhihu.com/p/27440393 原文版:https://www.oreilly.com/learning/generative-adversaria ...
随机推荐
- Clock()函数简单使用(C库函数)
Clock()函数简单使用(转) 存在于标准库<time.h> 描述 C 库函数 clock_t clock(void) 返回程序执行起(一般为程序的开头),处理器时钟所使用的时间.为了获 ...
- Android开发之下载服务器上的一张图片到本地java代码实现HttpURLConnection
package com.david.HttpURLConnectionDemo; import java.io.FileOutputStream; import java.io.IOException ...
- 序列号,IMEI,IMSI,ICCID的含义
什么是序列号? 序列号是一串标识你手机出生证明以及身材特征的信息,甚至还可用来识别是否为官方翻新机.你可以简单的将这一串数字分割为:aabccdddeef 的形式.拿iPhone 4为例 aa = 工 ...
- CA定义以及功能说明
当您访问以HTTPS开头的网站时,即表示正在使用CA.CA是Internet的重要组成部分.如果不存在CA,那么将无法安全在线购物以及使用网银在线业务等.什么是CA?CA具体是做什么的,又是如何确保您 ...
- Oracle RAC与DG
RAC RAC: real application clustersrac RAC: real application clustersrac 单节点数据库:数据文件和示例文件一一对应 实例损坏时数据 ...
- 想要使用GPU进行加速?那你必须事先了解CUDA和cuDNN
这一期我们来介绍如何在Windows上安装CUDA,使得对图像数据处理的速度大大加快,在正式的下载与安装之前,首先一起学习一下预导知识,让大家知道为什么使用GPU可以加速对图像的处理和计算,以及自己的 ...
- 20190930-01 Redis的事务 000 031
- ssh工具 (Java)
执行shell命令.下载文件... package com.sunsheen.blockchain.admin.utils; import java.io.BufferedReader; import ...
- 配置Cassandra开机启动(CentOS 7)
配置环境:centOS 7 1. 编写开机启动脚本[root@cassandra-01 ~]# cd /etc/rc.d/init.d/[root@cassandra-01 init.d]# vi c ...
- Python爬取NBA虎扑球员数据
虎扑是一个认真而有趣的社区,每天有众多JRs在虎扑分享自己对篮球.足球.游戏电竞.运动装备.影视.汽车.数码.情感等一切人和事的见解,热闹.真实.有温度. 受害者地址 https://nba.hupu ...