【论文研读】Sabir, Ekraam, et al. "Recurrent convolutional strategies for face manipulation detection in videos." Interfaces (GUI) 3.1 (2019).
#摘要
错误信息通过合成逼真的图像和视频进行传播这一严重问题,需要鲁棒的篡改检测方法来应对。尽管在检测静止图像上的面部篡改方面已付出了巨大的努力,但人们对于通过利用视频流中存在的时序信息,对视频中被篡改面部的识别方面的研究较少。循环卷积模型是一类深度学习模型,已证明能够有效地利用跨域图像流中的时序信息。因此,我们通过广泛的实验,提出了将这些模型中的变化与特定领域的面部预处理技术相结合的最佳策略(根据后文应该是面部对齐和CNN (DenseNet) + bidirectional RNN),从而在公开的基于视频的面部篡改benchmark上达到了目前最先进的性能。具体来说,我们尝试检测Deepfake,Face2Face和FaceSwap生成的视频流中的篡改人脸。对最近提出的 FaceForensics++数据集进行评估,将以前的最先进技术的精确度提高 4.55%。
1. Introduction
错误信息可以以不同的方式表现:直接篡改信息(如copy-move和splicing)或在误导的环境中呈现未篡改的内容(如image repurposing)。
通过深度学习生成的人脸的伪像是如此微妙,以至于评估脸部真假的唯一线索是(i) 头发的微妙不一致 - 头发太直,断线或干脆不自然,(ii) 不自然不对称的脸,(iii) 奇怪的牙齿,更重要的是,大多数时候,(iv) 其他更明显的不一致不在脸上而在背景上。
假视频数量的激增可能归因于两个原因:1. 将某人的身份或表情换成别人的,现在更容易了;2. 一段视频比一张图片更可信。
鉴于上述观察结果,并考虑到人脸篡改生成工具不会在合成过程中增强时间连贯性,而是逐帧执行操作,因此我们提出利用时间上的伪像来指示视频流中的异常人脸。
本文使用循环卷积模型以利用时间差异来改进当前方法。为了消除与视频中面部刚性运动相关的其他混淆因素,本文还使用了面部对齐方法。
2. Related Work
Video processing with deep models.
这方面有三种主要方法:
• 第一种研究从两个流网络 [37] 发展,其中 RGB 视频帧及其光流版本在网络中的两个独立分支中处理,然后是融合机制。
• 第二个是由循环卷积层支持的单个流网络:使用提取高级语义特征的单独卷积神经网络 (CNN) 收集每个帧中内容的感知知识,同时在这些特征上训练一个循环模型,以执行对时间维度的决策。
• 第三种发展使用 3D 卷积 [40, 19] 作为网络中的local building block,以学习丰富的时空特征。
本文认为基于双流架构的方法在动作识别方面是有效的,但与捕获生成器在视频中可能产生的细微闪烁的伪像不相关;并且另一方面,3D卷积虽然可能更适合于此目的,但它们会大大增加可学习的滤波器的数量。因此本文使用第二种方法。
Face manipulation benchmarks.
FaceForensics以及FaceForensics++。
Face Manipulation Detection.
XceptionNet [8]、MesoNet [4]、GoogLeNet等等。
3. Method
篡改检测的整体方法是分成两步:从视频帧裁剪和对齐人脸,然后对预处理面部区域进行篡改检测。
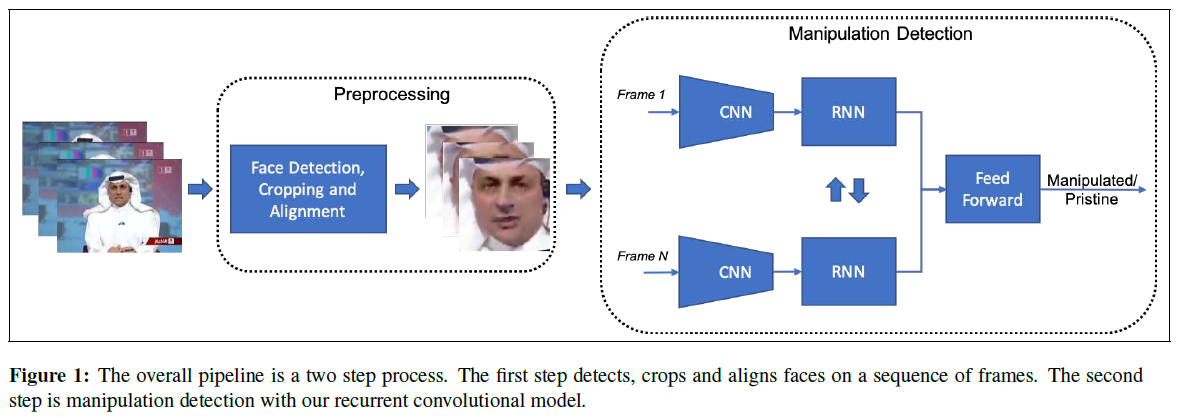
3.1. Face preprocessing
两种用于对齐人脸的技术:(i)使用面部landmark进行显式对齐,其中参考坐标系和面部裁剪的紧度由先验知识决定,并且所有面部都与该参考坐标系对齐,以便补偿面部的任何刚性运动,(ii)使用基于可学习的仿射变换的空间转换网络(STN:Spatial Transformer Network )进行隐式对齐。
Landmark-based alignment.
使用简单的相似度转换(四个自由度)对齐人脸图像,以补偿各向同性比例,平面内旋转和2D平移。转换后,分辨率为224×224。
Spatial Transformer Network.
其包括三个部分:定位网络,网格生成器和采样器。定位网络预测仿射变换参数,并且网格生成器和采样器将输入特征图使用仿射参数包装以生成输出特征图。
3.2. Videobased Face Manipulation Detection
使用循环卷积网络利用视频帧之间的时序伪像进行篡改检测。
Backbone encoding network.
本文使用ResNet [14]和DenseNet [15]作为模型的CNN组件有如下两个原因:
(i)FaceForensics ++ [34]是一个包含1,000个视频的低分辨率数据集,为避免过拟合,作者不得不使用经过预训练的具有固定特征提取层的XceptionNet [8]。
为了实现端到端的可训练性,本文选择了ResNet [14]。
(ii)篡改伪像表现为不需要高级面部语义特征的低级特征(例如不连续的下巴,眼睛模糊等)。
DenseNet也是一种合适的CNN架构,因为它提取了不同层次结构的特征。并使用cross-entropy loss。
RNN training strategies.实验将循环模型放置在backbone网络的不同部分:它将backbone网络连接在一起,充当特征学习器,将特征传递给RNN,随着时间的推移汇总。本文实验了两种策略:第一个是在backbone网络的最终特征之上仅使用单个循环网络。第二个是尝试在backbone网络层次结构的不同级别上学习多个循环网络。从CNN中提取多个特征级别的特征以进行篡改检测,这些特征在单个循环网络中处理,期望这个新的多循环卷积模型能够利用微观,中观和宏观特征进行篡改检测。
4. Experiments
通过实验发现(1)DenseNet优于ResNet,(2)面部对齐可提高性能,(3)图像序列要比单帧输入更好。
5. Conclusion
We found a landmark based face alignment with bidirectional-recurrent-denset to perform the best for face manipulation detection in videos.
【论文研读】Sabir, Ekraam, et al. "Recurrent convolutional strategies for face manipulation detection in videos." Interfaces (GUI) 3.1 (2019).的更多相关文章
- 论文笔记之:Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking
Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking arXiv Paper ...
- AD预测论文研读系列2
EARLY PREDICTION OF ALZHEIMER'S DISEASE DEMENTIA BASED ON BASELINE HIPPOCAMPAL MRI AND 1-YEAR FOLLOW ...
- AD预测论文研读系列1
A Deep Learning Model to Predict a Diagnosis of Alzheimer Disease by Using 18F-FDG PET of the Brain ...
- GoogLeNetv4 论文研读笔记
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning 原文链接 摘要 向传统体系结构中引入 ...
- GoogLeNetv3 论文研读笔记
Rethinking the Inception Architecture for Computer Vision 原文链接 摘要 卷积网络是目前最新的计算机视觉解决方案的核心,对于大多数任务而言,虽 ...
- GoogLeNetv2 论文研读笔记
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift 原文链接 摘要 ...
- GoogLeNetv1 论文研读笔记
Going deeper with convolutions 原文链接 摘要 研究提出了一个名为"Inception"的深度卷积神经网结构,其目标是将分类.识别ILSVRC14数据 ...
- Paper Reading - Long-term Recurrent Convolutional Networks for Visual Recognition and Description ( CVPR 2015 )
Link of the Paper: https://arxiv.org/abs/1411.4389 Main Points: A novel Recurrent Convolutional Arch ...
- [论文理解]Region-Based Convolutional Networks for Accurate Object Detection and Segmentation
Region-Based Convolutional Networks for Accurate Object Detection and Segmentation 概括 这是一篇2016年的目标检测 ...
随机推荐
- std::thread线程库详解(2)
目录 目录 简介 最基本的锁 std::mutex 使用 方法和属性 递归锁 std::recursive_mutex 共享锁 std::shared_mutex (C++17) 带超时的锁 总结 简 ...
- Vue.nextTick()的使用
什么是Vue.nextTick()?? 定义:在下次 DOM 更新循环结束之后执行延迟回调.在修改数据之后立即使用这个方法,获取更新后的 DOM. 所以就衍生出了这个获取更新后的DOM的Vue方法.所 ...
- version can neither be null, empty nor blank
在用mybatis-generator逆向生成mapper和DAO的时候,出现了这个错误. mybatis-generator:generate 原因是在pom.xml中我的mysql依赖没有写版本号 ...
- CVE-2019-15107_webmin漏洞复现
一.漏洞描述 Webmin的是一个用于管理类Unix的系统的管理配置工具,具有网络页面.在其找回密码页面中,存在一处无需权限的命令注入漏洞,通过这个漏洞攻击者即可以执行任意系统命令.它已知在端口100 ...
- 一. SpringCloud简介与微服务架构
1. 微服务架构 1.1 微服务架构理解 微服务架构(Microservice Architecture)是一种架构概念,旨在通过将功能分解到各个离散的服务中以实现对解决方案的解耦.你可以将其看作是在 ...
- mybatis中传集合时 报异常 invalid comparison: java.util.Arrays$ArrayList and java.lang.String
犯了一个低级的错误,在传集合类型的参数时,把他当成字符串处理了,导致报类型转换的错误 把 and nsrsbh!=' ' 删掉就行了
- React 入门-redux 和 react-redux
React 将页面元素拆分成组件,通过组装展示数据.组件又有无状态和有状态之分,所谓状态,可以简单的认为是组件要展示的数据.React 有个特性或者说是限制单向数据流,组件的状态数据只能在组件内部修改 ...
- Python执行程序实可视化_heartrate
最近发现了一个Python程序执行的简单实时可视化神器,名字叫 heartrate,安装完运行可以看到下面这样的炫酷过程. 虽然很炫酷,但有点看不懂. 来解释下,左边的动态数字代表每行被触发的次数.变 ...
- 1.kafka基础架构
kafka基础架构 ## 什么是kafka? Kafka是一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域. 1.什么是消息队列? 2.使用消息队列的好处 1)解耦 允许你独立的 ...
- Spring框架入门浅析
一.Spring Bean的配置 在需要被Spring框架创建对象的实体类的类声明前面加注解:```@component```.这样在Spring扫描的时候,看到该注解就会在容器中创建该实体类的对象. ...