多任务学习(MTL)在转化率预估上的应用
今天主要和大家聊聊多任务学习在转化率预估上的应用。
多任务学习(Multi-task learning,MTL)是机器学习中的一个重要领域,其目标是利用多个学习任务中所包含的有用信息来帮助每个任务学习得到更为准确的学习器,通过使用包含在相关任务的监督信号中的领域知识来改善泛化性能。深度学习流行之后,MTL在深度网络也有很多尝试和方法。
(0).背景介绍
名词定义:
CTR: 指曝光广告中,被点击的广告比例
CVR: 指被点击的广告中,最终形成转化的广告比例
CTCVR: 指曝光广告中,被点击且最终形成转化的广告比例
正如上一篇《oCPC中转化率模型与校准》中所讲,如果完全是按照CPC出价计费,那只需要建模CTR模型,而在oCPC场景下,需要对CTCVR进行建模,我们目前的业务恰好属于后者。前期分析表明,直接对CTCVR建模,会导致召回用户的CTR竞争力较低,影响最终曝光。所以建模需要同时考虑CTR和CTCVR两个指标。基于以上背景,我们在业务中引入多任务学习的建模方式。
(1).多任务学习介绍
多任务学习是指: 给定m个学习任务,其中所有或一部分任务是相关但并不完全一样的,多任务学习的目标是通过使用这m个任务中包含的知识来帮助提升各个任务的性能。联合学习(joint learning)、自主学习(learning to learn)和带有辅助任务的学习(learning with auxiliary task)等都可以指 MTL。一般来说,优化多个损失函数就等同于进行多任务学习(与单任务学习相反)。即使只优化一个损失函数(如在典型情况下),也有可能借助辅助任务来改善原任务模型。在深度学习中,多任务学习通常通过隐藏层的Hard或Soft参数共享两种方式来完成。
a. Hard参数共享
共享Hard参数是神经网络 MTL最常用的方法,在实际应用中,通常通过在所有任务之间共享隐藏层,同时保留几个特定任务的输出层来实现。硬共享机制降低了过拟合的风险。事实上,有文献证明了这些共享参数过拟合风险的阶数是N,其中N为任务的数量,比任务相关参数的过拟合风险要小。直观来讲,这一点是非常有意义的。越多任务同时学习,我们的模型就能捕捉到越多任务的同一个表示,从而使得在我们原始任务上的过拟合风险越小。如下图所示:
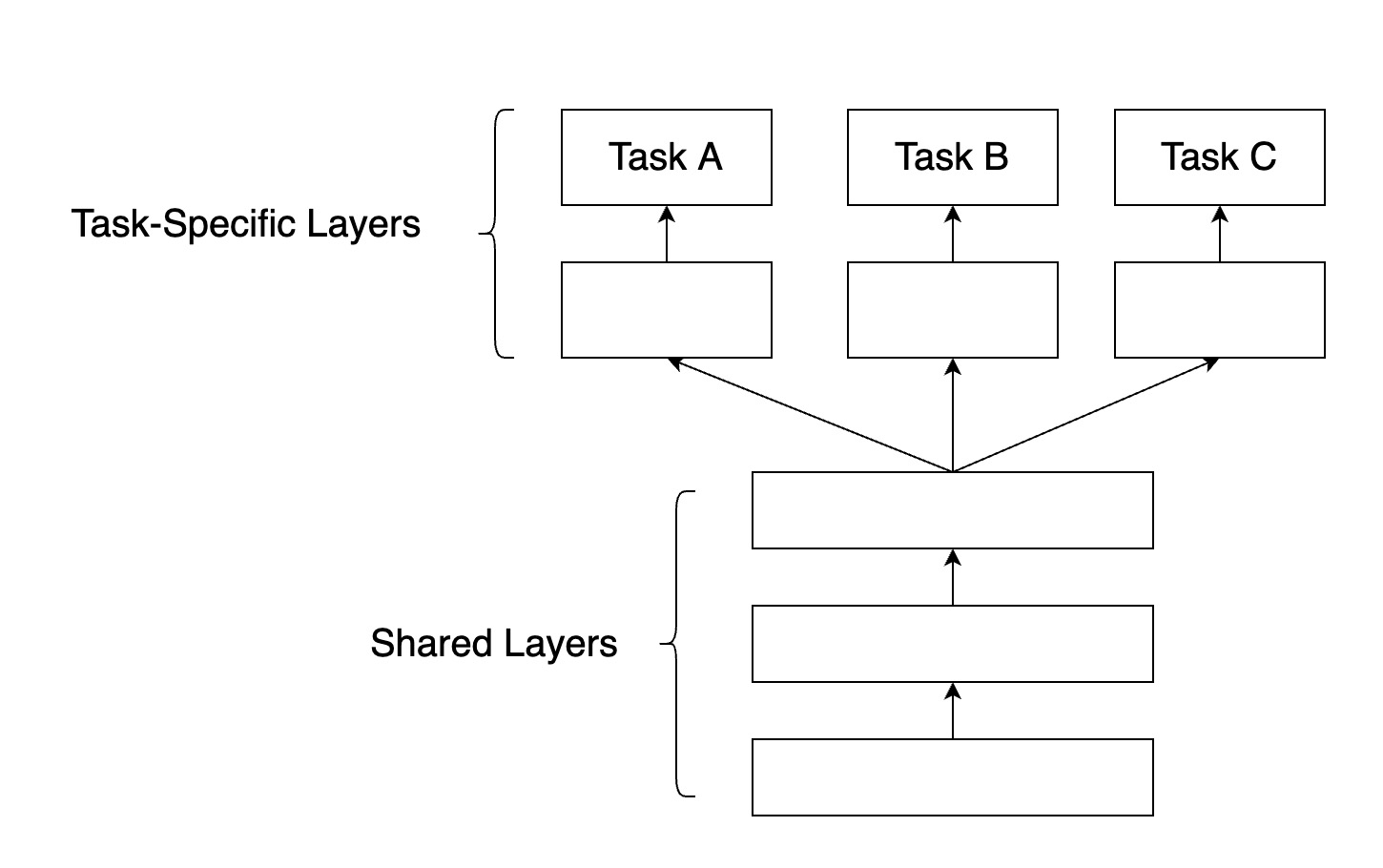
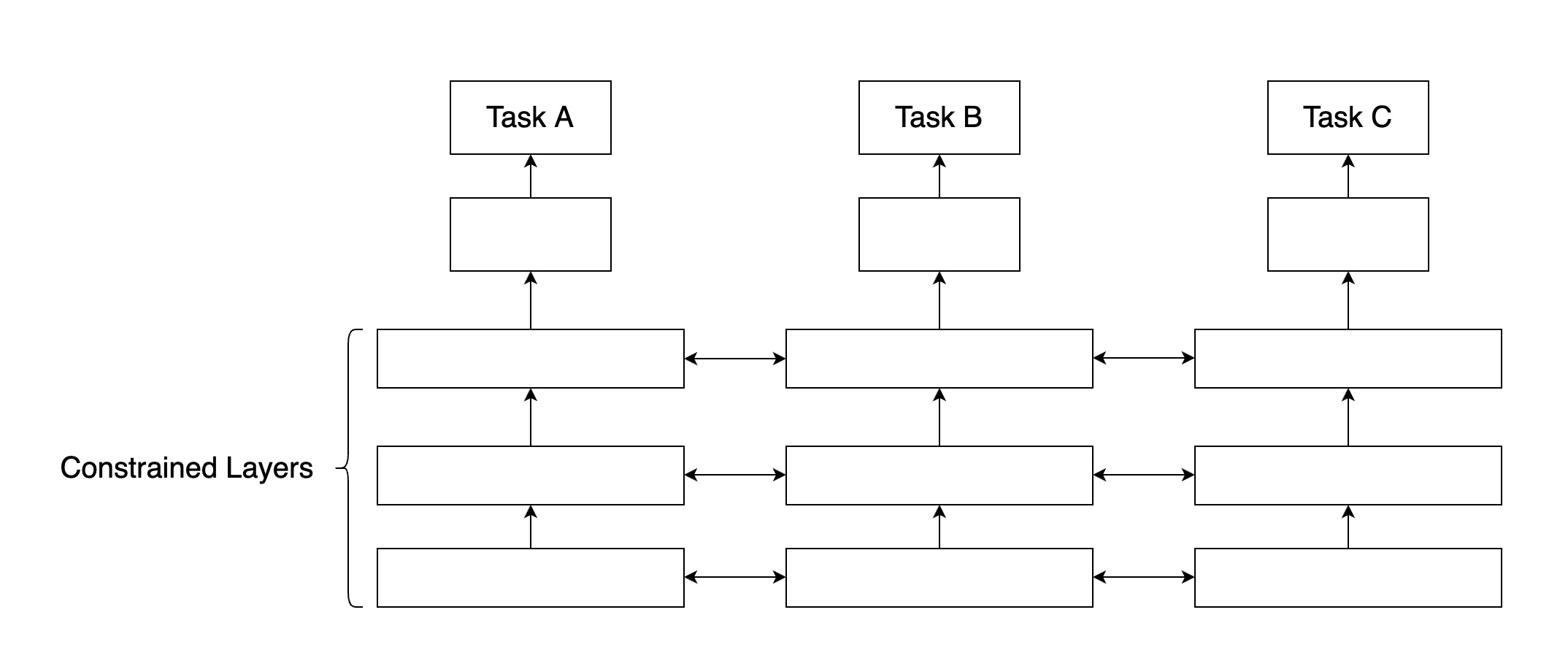
b. Soft参数共享
在共享Soft参数时,每个任务都有自己的参数和模型。模型参数之间的距离是正则化的,以便鼓励参数相似化,业内常用L2距离进行正则化,或者使用迹范数(trace norm)。

(2). ESMM模型
ESMM:完整空间多任务模型(Entire Space Multi-Task Model),是阿里2018年提出的模型思想,是一个hard参数共享的MTL模型。主要为了解决传统CVR建模过程中样本选择偏差(sample selection bias, SSB)和数据稀疏(data sparsity,DS)问题。
样本选择偏差:用户在广告上的行为属于顺序行为模式impression -> click -> conversion,传统CVR建模训练时是在click的用户集合中选择正负样本,模型最终是对整个impression的用户空间进行CVR预估,由于click用户集合和impression用户集合存在差异(如下图),引起样本选择偏差。
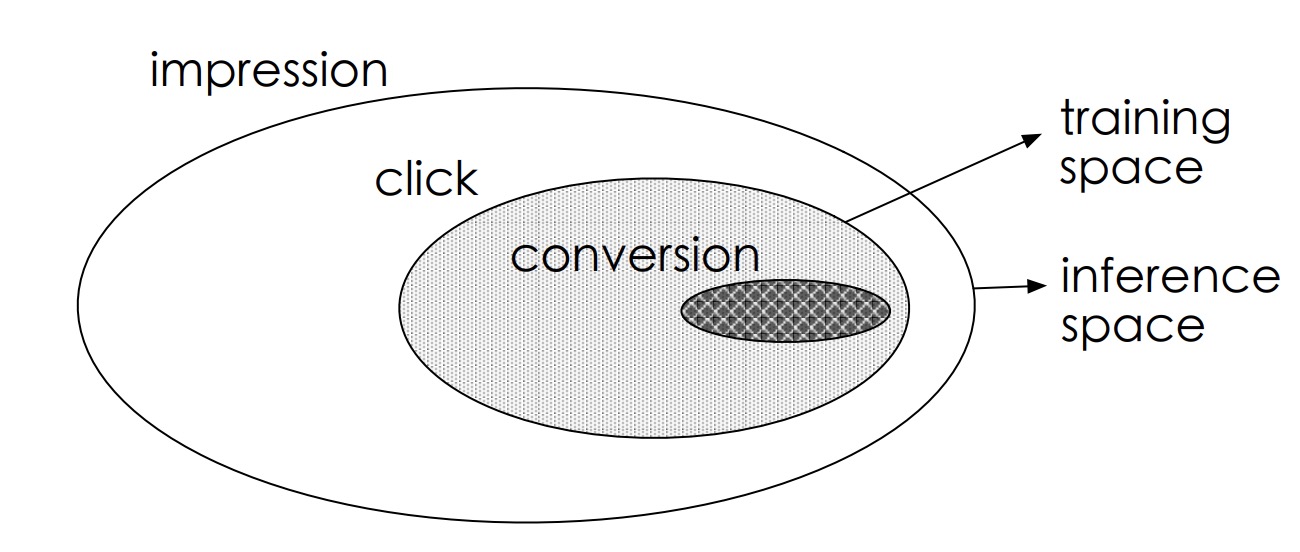
数据稀疏:推荐系统中有click行为的用户占比是很低的,相比曝光用户少1~3个数量级,在实际业务中,有click行为的用户占比不到4%,就会导致CVR模型训练数据稀疏,高度稀疏的训练数据使得模型的学习变的相当困难。由于用户行为遵循impression -> click -> conversion的顺序行为模式,预估结果遵循以下关系:

ESMM算法引入两个辅助任务学习任务,分别拟合pCTR和pCTCVR,都是从整个样本空间选择样本,来同时消除上面提到的两个问题。其架构图如下:

从架构图可以看到,ESMM模型由两个子网络组成,左边的子网络用来拟合pCVR,右边的子网络用来拟合pCTR,最终两个网络结果相乘得到pCTCVR。pCVR只是作为模型训练的中间结果,最终根据模型输出的pCTCVR和pCTR结果计算最终的pCVR,计算公式如下:
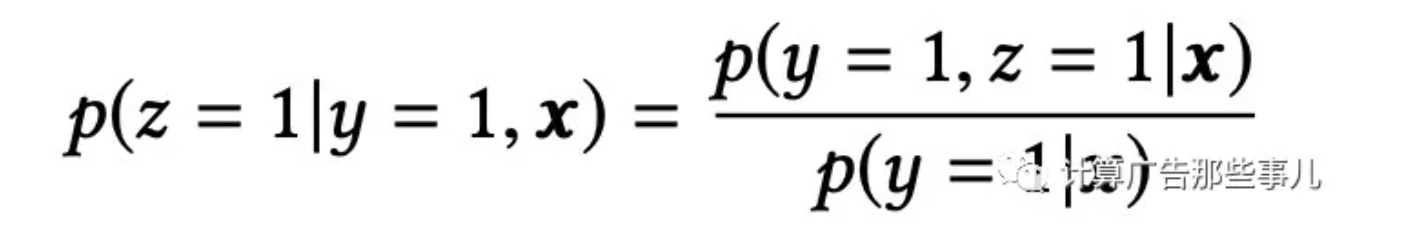
模型很好的解决了样本偏差问题,训练过程使用的所有样本,均是从整个曝光的样本空间进行选择,其中有点击的为CTR正样本,否则为负样本;有点击且转化的为CTCVR的正样本,否则为负样本。同时模型两个子网络共享embedding层,由于CTR任务的训练样本量要大大超过CTCVR任务的训练样本量,ESMM模型中特征表示共享的机制能够使得CVR子任务也能够从只有展现没有点击的样本中学习,从而能够极大地缓解训练数据稀疏性问题。
(3). ESMM模型的优化
在ESMM模型的基础上,我们做了以下两点优化:
a. 优化网络embedding层,使其可以处理用户不定长行为特征
用户历史行为属于不定长行为,比如曾经点击过的ID列表,一般我们对这种行为引入网络中的时候,会将不定长进行截断成统一长度(比如:平均长度)的定长行为,方便网络使用。很多用户行为没有达到平均长度,则会在后面统一补0,这会导致用户embedding结果里面包含很多并未去过的节点0的信息。这里我们提出一种聚合-分发的特征处理方式,使得网络的特征embedding层可以处理不定长的特征。
由于单个特征节点的embedding结果是和用户无关的,比如:用户A点击k,用户B也点击了k,最终embedding得到的k结果是唯一的,对A和B两个用户访问的k都是一样的。基于该前提,我们采用聚合-分发的处理思想。将min-batch的所有用户的不定长行为聚合拼接成一维的长矩阵,并记录下各个用户行为的索引,在embedding完成之后,根据索引将各个用户的实际行为进行还原,并降维成固定长度,输入到dense层使用。
b. 由于训练正负样本差异比较大,模型引入Focal Loss,使训练过程更加关注数量较少的正样本
原始ESMM模型中,直接使用pCTCVR和pCTR两个模型的交叉熵之和作为总的loss函数,loss计算公式如下:
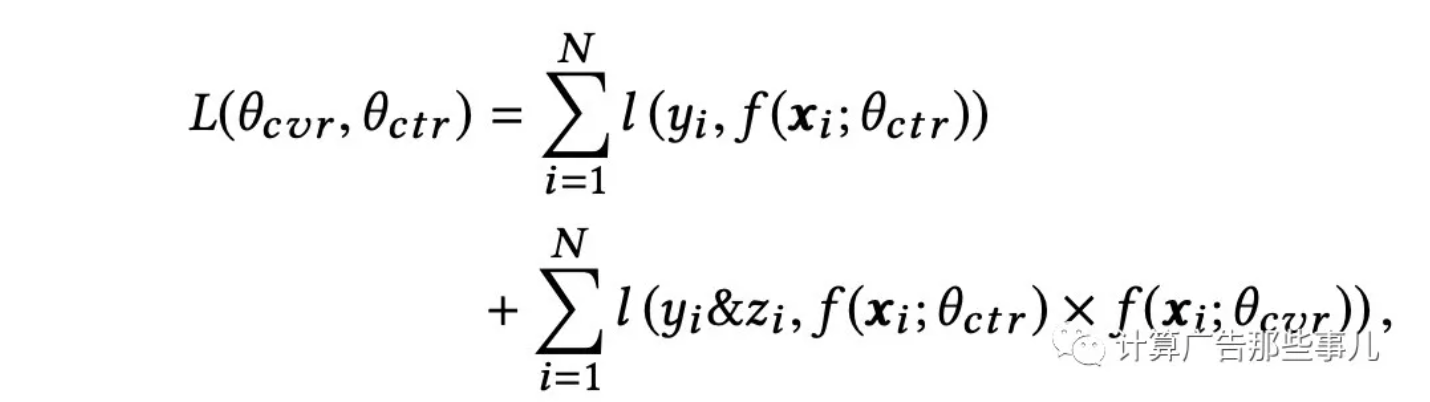
由于正负样本比例严重失衡,样本中会存在大量的easy samples,且都是属于负样本,这些easy negative examples会对loss起主要贡献作用,会主导梯度的更新方向,导致模型无法学到较好的区分能力。
我们在模型中引入Focal Loss,Focal Loss是对交叉熵的优化,引入平衡权重alpha,一般与样本权重成负相关,该类样本占比越少,在loss函数中的权重就越大,用来平衡正负样本比例不均的问题。引入难易因子gamma,是给loss函数中困难的、错分的样本权重更大,模型更偏向于学习困难错分的样本。Focal Loss函数定义如下:
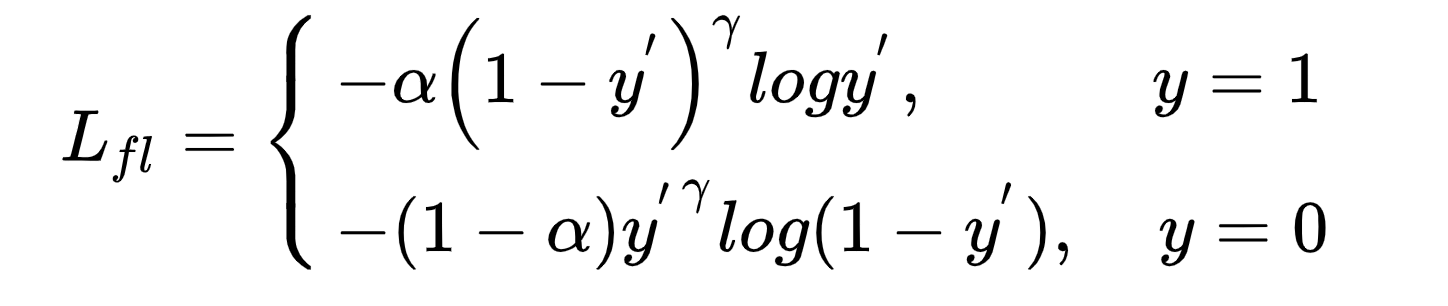
模型实际使用中,根据每个batch里面正负样本分布来计算α,优化focal loss之后,模型CTCVR-AUC基本持平,和优化前保持一致;CTCVR的分数在CTR上的AUC表现绝对值提升1.5%。focal loss在模型训练主任务的过程中学习到了更多CTR相关的能力,提升了模型在CTR表现。
结合ESMM结构和loss函数可以看出,原模型两个子网络dense层数据分别是pCTR和PCVR,所以在loss函数使用CTR*CVR来评估CTCVR的loss。由于我们模型是直接采用pCTCVR作为主任务,在评估的时候直接使用CTCVR的输出评估。最终的loss函数如下:
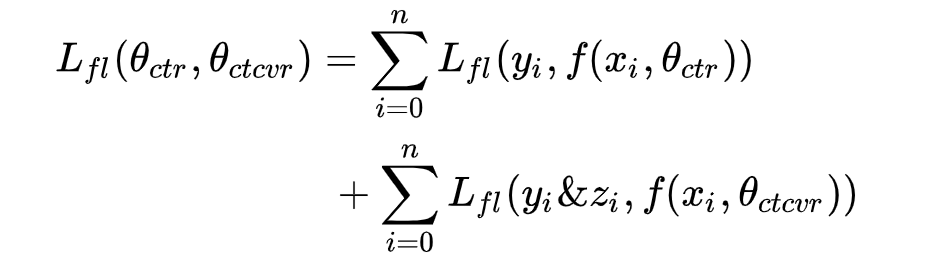
(4). 小结
本文主要介绍了多任务学习的基本概念以及我们在实际业务上对ESMM模型做的一些改进,后会有期,拜了个拜!
欢迎大家关注计算广告那些事儿哈,除了原创文章之外,也会不定期和大家分享业内大牛的文章哈!

多任务学习(MTL)在转化率预估上的应用的更多相关文章
- keras函数式编程(多任务学习,共享网络层)
https://keras.io/zh/ https://keras.io/zh/getting-started/functional-api-guide/ https://github.com/ke ...
- 多任务学习Multi-task-learning MTL
https://blog.csdn.net/chanbo8205/article/details/84170813 多任务学习(Multitask learning)是迁移学习算法的一种,迁移学习可理 ...
- 推荐中的多任务学习-ESMM
本文将介绍阿里发表在 SIGIR'18 的论文ESMM<Entire Space Multi-Task Model: An Effective Approach for Estimating Po ...
- 【论文笔记】多任务学习(Multi-Task Learning)
1. 前言 多任务学习(Multi-task learning)是和单任务学习(single-task learning)相对的一种机器学习方法.在机器学习领域,标准的算法理论是一次学习一个任务,也就 ...
- 深度神经网络多任务学习(Multi-Task Learning in Deep Neural Networks)
https://cloud.tencent.com/developer/article/1118159 http://ruder.io/multi-task/ https://arxiv.org/ab ...
- [译]深度神经网络的多任务学习概览(An Overview of Multi-task Learning in Deep Neural Networks)
译自:http://sebastianruder.com/multi-task/ 1. 前言 在机器学习中,我们通常关心优化某一特定指标,不管这个指标是一个标准值,还是企业KPI.为了达到这个目标,我 ...
- 牛亚男:基于多Domain多任务学习框架和Transformer,搭建快精排模型
导读: 本文主要介绍了快手的精排模型实践,包括快手的推荐系统,以及结合快手业务展开的各种模型实战和探索,全文围绕以下几大方面展开: 快手推荐系统 CTR模型--PPNet 多domain多任务学习框架 ...
- [DeeplearningAI笔记]ML strategy_2_3迁移学习/多任务学习
机器学习策略-多任务学习 Learninig from multiple tasks 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.7 迁移学习 Transfer Learninig 神 ...
- caffe实现多任务学习
Github: https://github.com/Haiyang21/Caffe_MultiLabel_Classification Blogs 1. 采用多label的lmdb+Slice L ...
随机推荐
- Elastic Search 原理剖析
Elastic Search 原理剖析 Elasticsearch 是一个开源的分布式 RESTful 搜索和分析引擎,能够解决越来越多不同的应用场景. 搜索引擎 refs https://www.e ...
- 如何使用 js 实现一个 Promise.all 方法 PromiseAll
如何使用 js 实现一个 Promise.all 方法 PromiseAll Promise.all PromiseAll https://developer.mozilla.org/en-US/do ...
- taro 禁用滚动事件
taro 禁用滚动事件 禁止 Modal 蒙层下面的页面的内容跟随滚动 https://github.com/NervJS/taro/issues/3980 https://github.com/Ne ...
- PHP实现一个二维码同时支持支付宝和微信支付
实现思路 生成一个二维码,加入要处理的url连接 在用户扫完码后,在对应的脚本中,判断扫码终端,调用相应的支付 若能够扫码之后能唤起相应app,支付宝要用手机网站支付方式,微信要使用jsapi支付方式 ...
- NGK底层技术如何助力SPC子币VAST高价与安全并行?
NGK近来使用了新的侧链技术推出了新的SPC侧链代币,以及SPC的子币VAST---维萨币. NGK使用去中心化和开源区块链数据分布式协议,不断打造高倍币,力求成为生态建设参与者们所信赖的高倍币孵化器 ...
- 科普NGK公链生态板块旗下的BGV、SPC、NGK、USDN四大币种
众所周知,NGK公链所有数据上链.公开透明,NGK公链生态板块目前主要分为四个板块---BGV.SPC.NGK.USDN四大币种,笔者以时间上倒叙手法来一一科普. 首先,是2021新年刚推出的SPC侧 ...
- 利用 Java 操作 Jenkins API 实现对 Jenkins 的控制详解
本文转载自利用 Java 操作 Jenkins API 实现对 Jenkins 的控制详解 导语 由于最近工作需要利用 Jenkins 远程 API 操作 Jenkins 来完成一些列操作,就抽空研究 ...
- AttributeError: 'function' object has no attribute 'as_view'
我的描述:当我启用jwt_required来进行token验证的时候,我提示错误; 解决方案: 修改前代码: 修改后代码: 多看书.多多了解.多看看世界...
- 开源OA办公平台搭建教程:O2OA表单中的事件
1. 概述 我们设计表单的时候经常会有这样的需求:在表单或者组件加载前/加载后,能够执行一些脚本来改变表单或组件的样式和行为.或者用户在点击组件的时候能够执行脚本.表单的事件就是为这样的场景而设计. ...
- synchronized语法
synchronized( ){ } synchronized 关键字是加锁的意思,用它来修饰方法就表示给该方法加了锁,从而达到线程同步的效果;用它来修饰代码块就表示给该代码块加了锁,从而达到线程同步 ...