2021-2-17:Java HashMap 的中 key 的哈希值是如何计算的,为何这么计算?
首先,我们知道 HashMap 的底层实现是开放地址法 + 链地址法的方式来实现。
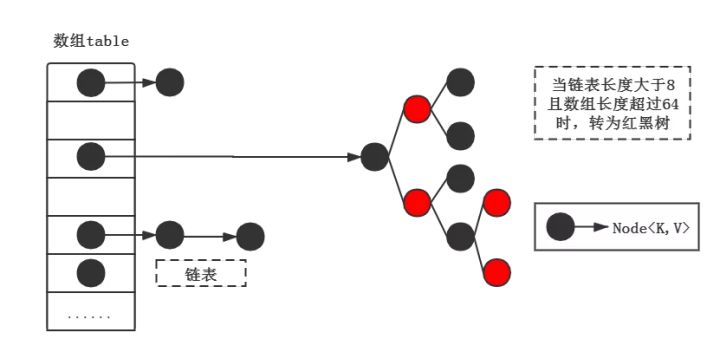
即数组 + 链表的实现方式,通过计算哈希值,找到数组对应的位置,如果已存在元素,就加到这个位置的链表上。在 Java 8 之后,链表过长还会转化为红黑树。
这个数组并不是一开始就很大,而是随着 HashMap 里面的值变多,达到 LoadFactor 的界限之后,就会扩容。刚开始的数组很小,默认只有 16。
这个数组大小一定是 2 的 n 次方,因为找到数组对应的位置需要通过取余计算,取余计算是一个很耗费性能的计算,而对 2 的 n 次方取余就是对 2 的 n 次方减一取与运算。所以保持数组大小为 2 的 n 次方,这样就可以保证计算位置高效。
那么这个哈希值究竟是怎么计算的呢?假设就是用 Key 的哈希值直接计算。假设有如下两个 key,哈希值分别是:
key1:
0000 0000 0010 1111 1001 0000 0110 1101
key2:
0000 0000 0010 0000 1001 0000 0110 1101
如果直接使用数组默认大小,取余之后 key1 与 key2 就会到数组同一个下标。其实 key1 和 key2 的高位是不一样的。
由于数组是从小到达扩容的,为了优化高位被忽略这个问题,HashMap 源码中对于计算哈希值做了优化,采用高位16位组成的数字与源哈希值取异或而生成的哈希值作为用来计算 HashMap 的数组位置的哈希值:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
为什么要用异或?首先,对于一个数字,转换成二进制之后,其中为的 1 的位置代表这个数字的特性.对于异或运算,如果a、b两个值不相同,则异或结果为1。如果a、b两个值相同,异或结果为0。0与0异或是0,0与1异或是1,这样相当于让高位的特性在低位得以体现,所以采用这种算法,减少碰撞。
微信搜索“我的编程喵”关注公众号,每日一刷,轻松提升技术,斩获各种offer:

2021-2-17:Java HashMap 的中 key 的哈希值是如何计算的,为何这么计算?的更多相关文章
- 【转】HashMap集合中key只能为引用数据类型,不能为基本类型
在HashMap中,为什么不能使用基本数据类型作为key? 其实和HashMap底层的存储原理有关,HashMap存储数据的特点是:无序.无索引.不能存储重复元素. 存储元素采用的是hash表存储数据 ...
- Java - HashMap分别按Key和Value进行排序
我们都知道,Java中的Map结构是key->value键值对存储的,而且根据Map的特性,同一个Map中 不存在两个Key相同的元素,而value不存在这个限制.换句话说,在同一个Map中Ke ...
- Java中String的哈希值计算
下面都是从String类的源码中粘贴出来的 private int hash; // Default to 0 public int hashCode() { int h = hash; if (h ...
- 关于Java读取mysql中date类型字段默认值'0000-00-00'的问题
今天在做项目过程中,查询一个表中数据时总碰到这个问题: java.sql.SQLException:Value '0000-00-00' can not be represented as ...
- 为什么阿里巴巴Java开发手册中强制要求接口返回值不允许使用枚举?
在阅读<阿里巴巴Java开发手册>时,发现有一条关于二方库依赖中接口返回值不允许使用枚举类型的规约,具体内容如下: 在谈论为什么之前先来科普下什么是二方库,二方库也称作二方包,一般指公司内 ...
- Java异常处理场景中不同位置的返回值详细解析
Java 异常处理中的返回值在不同位置不同场景下是有一些差别的,这里需要格外注意 具体分以下两种场景: 1 finally语句块没有return语句,即当代码执行到try或者catch语句块中的ret ...
- JAVA获取oracle中sequences的最后一个值
项目中,用到一个序列作单号,框架用的是ssh,在dao层去拿的时候,运行时报错为dual is not mapped,[select *.nextval nextvalue from dual] 后来 ...
- [翻译]Java HashMap工作原理
大部分Java开发者都在使用Map,特别是HashMap.HashMap是一种简单但强大的方式去存储和获取数据.但有多少开发者知道HashMap内部如何工作呢?几天前,我阅读了java.util.Ha ...
- 【转】Java HashMap工作原理(好文章)
大部分Java开发者都在使用Map,特别是HashMap.HashMap是一种简单但强大的方式去存储和获取数据.但有多少开发者知道HashMap内部如何工作呢?几天前,我阅读了java.util.Ha ...
随机推荐
- scrapy-redis非多网址采集的使用
问题描述 默认RedisSpider在启动时,首先会读取redis中的spidername:start_urls,如果有值则根据url构建request对象. 现在的要求是,根据特定关键词采集. 例如 ...
- Mac下IDEA激活Jrebel
第一步:在idea中下载jrebel,过程省略 第二步:配置反向代理工具 Windows 版:http://blog.lanyus.com/archives/317.html MAC 版: 安装hom ...
- 接口新建学习---cookie策略
一.为什么要添加cookie? 模拟浏览器,因为http是无状态协议,像览器一样的存储和发送Cookie,如果发送一个http请求他的响应中包含Cookie,那么Cookie Manager就会自动地 ...
- 配置MySQL主从复制报错Last_IO_Error: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server ids; these ids must be different for replication to work
配置MySQL主从复制报错 ``` Last_IO_Error: Fatal error: The slave I/O thread stops because master and slave ha ...
- 微博CacheService架构浅析 对底层协议进行适配
https://mp.weixin.qq.com/s/wPR0j2bmHBF6z0ZjTlz_4A 麦俊生 InfoQ 2014-04-21 微博作为国内最大的社交媒体网站之一,每天承载着亿万用户的服 ...
- Android使用代码开关Location服务
Android系统中,只有系统设置里面有入口开关位置服务.其他的应用应该怎么去开关这个服务呢? 首先,应用需要有系统权限(签名),在这基础上,我们就可以通过一些手段来实现这个功能. 这里要注意一点,不 ...
- java架构《并发编程框架篇 __Disruptor》
Disruptor入门 获得Disruptor 可以通过Maven或者下载jar来安装Disruptor.只要把对应的jar放在Java classpath就可以了. 基本的事件生产和消费 我们从 ...
- Filter过滤器除去部分URL链接
在web.xml中配置的Filter如下: <filter> <filter-name>HazardousParametersFilter</filter-name> ...
- 子网划分、变长子网掩码和TCP/IP排错__散知识点
1.IP零子网(ip subnet-zero):这个命令可以允许你在自己的网络设计中使用第一个和最后一个子网.例如,C类掩码192通常只可以提供子网64和128,但在使用了ip subnet-zero ...
- docker(4)解决pull镜像速度缓慢
前言 上一篇讲到pull 镜像,但是pull镜像的时候下拉的速度实在感人,有什么解决办法吗?我们只需将docker镜像源修改为国内的 将docker镜像源修改为国内的: 在 /etc/docker/d ...