java爬取图片示例
爬虫是什么
这里引用一下 wiki 中关于 网络爬虫的定义,相信大家看过后会有一个清晰的认识
网络爬虫(英语:web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引。
网络搜索引擎等站点通过爬虫软件更新自身的网站内容或其对其他网站的索引。网络爬虫可以将自己所访问的页面保存下来,以便搜索引擎事后生成索引供用户搜索。
爬虫访问网站的过程会消耗目标系统资源。不少网络系统并不默许爬虫工作。因此在访问大量页面时,爬虫需要考虑到规划、负载,还需要讲“礼貌”。 不愿意被爬虫访问、被爬虫主人知晓的公开站点可以使用robots.txt文件之类的方法避免访问。这个文件可以要求机器人只对网站的一部分进行索引,或完全不作处理。
互联网上的页面极多,即使是最大的爬虫系统也无法做出完整的索引。因此在公元2000年之前的万维网出现初期,搜索引擎经常找不到多少相关结果。现在的搜索引擎在这方面已经进步很多,能够即刻给出高质量结果。
爬虫还可以验证超链接和HTML代码,用于网络抓取(参见数据驱动编程)。

爬虫的核心
- 分析目标网站的数据格式
- 编写对应的代码爬取
分析目标网站的数据格式 这一步中我们需要仔细分析目标网站的html格式,寻找它们的内在联系,(如果是异步加载的数据处理起来比较麻烦一点,此处我们不做讲解),找出规律
编写对应的代码爬取 第二步我们需要伪造好我们的目标网站需要的请求头部分,同时根据第一步的规律解析出你想要的数据,然后保存即可

示例
package photo;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
/**
* @author: latinos-bub
* @date: 2019/11/10 17:18
* @description: 爬取 https://image.so.com/ 网站的图片
* @className: CrawlSophoto
*/
public class CrawlSophoto {
/**
* @Author latinos-bub
* @Description //TODO 获取页面中所有的 <img src/> 中的 src 链接 https://p5.ssl.qhimgs1.com/bdr/326__/t0104acadc3f46e94a5.jpg
* @Date 2019/11/10 17:20
* @Param [url]
* @return java.util.List<java.lang.String>
**/
public static List<String> getImgSrc(String url) throws Exception{
// 实例化 返回数据
List<String> imgSrcList = new ArrayList<String>();
// 使用 Jsoup 获取 document 文档对象
Document document = Jsoup.connect(url).get();
// 获取所有的 img 标签元素
Elements elements = document.getElementsByTag("img");
String srcUrl;
// 遍历所有的 elements 元素,获取 <img src/> 中的 src 属性值 (不推荐使用,涉及的图片太多了,建议使用下面的 for 循环控制大小)
// for (Element e : elements){
// srcUrl = e.attr("src");
//
// // 添加入 imgSrcList 集合中
// imgSrcList.add(srcUrl);
// }
for (int i = 0; i < 7; i++){ // 因为 https://image.so.com/ 图片默认是7个,采用的 异步加载,我们这里不处理这种的,只取默认的7个
srcUrl = elements.get(i).attr("src");
// 添加入 imgSrcList 集合中
imgSrcList.add(srcUrl);
}
// 返回符合你要求的所有的 <img src/> 中的 src 链接
return imgSrcList;
}
public static void saveImage(List<String> imgSrcList){
// 先设置 你的图片保存位置
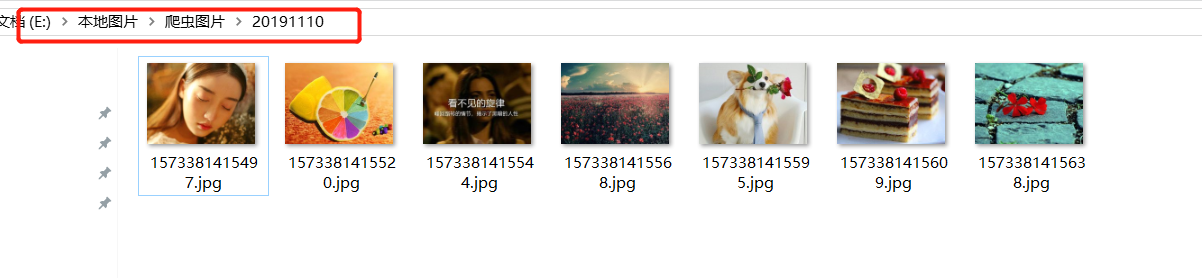
String path = "E:\\本地图片\\爬虫图片\\20191110\\";
// 实例化一个 File 对象 (文件/文件夹)
File file = new File(path);
// 如果上述目录不存在,则自动创建
if (!file.exists()){
file.mkdir();
}
// 声明 HttpURLConnection 请求对象
HttpURLConnection httpURLConnection = null;
// 声明 InputStream 输入字节流
InputStream inputStream = null;
System.out.println("开始下载图片...");
// 循环遍历 imgSrcList
for (String src : imgSrcList){
try {
// 实例化 一个特定 http 类型的新的 URL 对象
URL url = new URL(src);
// 实例化 HttpURLConnection 对象
httpURLConnection = (HttpURLConnection) url.openConnection();
// 设置 HttpURLConnection 请求头部分,通过 chrome 的 F12 查看
httpURLConnection.setRequestProperty("Cookie", "opqopq=0c01989c7413e5a5d21e68f310c397b5.1573377223; _S=03b161a0b5b7eaaadd261490c514a29d; __guid=16527278.863313966117013800.1573377222710.2178; count=1; tracker=; test_cookie_enable=null");
httpURLConnection.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36");
// 从 HttpURLConnection 请求对象中 实例化(获取) 输入字节流
inputStream = httpURLConnection.getInputStream();
// 声明 输出流对象, 并实例化为 一个 文件输出流对象; 这里很好理解,实例化文件输出流对象,肯定需要一个文件对象作参数
OutputStream outputStream = new FileOutputStream(new File(path + new Date().getTime() + ".jpg"));
// 实例化一个 byte[] 对象,用于 io 缓冲区的大小设置
byte[] bytes = new byte[2048];
// 接收 每次读取到的 字节数
int len = 0;
// 采用 while 循环,只要满足条件,一直循环执行
while ((len = inputStream.read(bytes)) != -1) { // 从 输入字节流 中读取内容
// 将 读取到的 字节 写入文件即可
outputStream.write(bytes, 0, len);
}
}catch (Exception e){
System.out.println( "src为: " + src + " 的图片下载出错..." + e.getMessage());
continue;
}
}
System.out.println("下载图片完成...");
}
public static void main(String[] args){
// 输入 https://image.so.com/ 进行测试
String url = "https://image.so.com/";
try {
// 先获取 src 路径
List<String> imgSrcList = getImgSrc(url);
// 下载
saveImage(imgSrcList);
}catch (Exception e){
System.out.println("测试出错..." + e.getMessage());
}
}
}
结果展示


-- 金朝:元好问
乙丑岁赴试并州,道逢捕雁者云:“今旦获一雁,杀之矣。其脱网者悲鸣不能去,竟自投于地而 死。”予因买得之,葬之汾水之上,垒石为识,号曰“雁丘”。 同行者多为赋诗,予亦有《雁丘词》。旧所作无宫商,今改定之。
问世间,情为何物,直教生死相许?
天南地北双飞客,老翅几回寒暑。
欢乐趣,离别苦,就中更有痴儿女。
君应有语:渺万里层云,千山暮雪,只影向谁去?
横汾路,寂寞当年箫鼓,荒烟依旧平楚。
招魂楚些何嗟及,山鬼暗啼风雨。
天也妒,未信与,莺儿燕子俱黄土。
千秋万古,为留待骚人,狂歌痛饮,来访雁丘处。
java爬取图片示例的更多相关文章
- Java jsoup爬取图片
jsoup爬取百度瀑布流图片 是的,Java也可以做网络爬虫,不仅可以爬静态网页的图片,也可以爬动态网页的图片,比如采用Ajax技术进行异步加载的百度瀑布流. 以前有写过用Java进行百度图片的抓取, ...
- [python爬虫] 爬取图片无法打开或已损坏的简单探讨
本文主要针对python使用urlretrieve或urlopen下载百度.搜狗.googto(谷歌镜像)等图片时,出现"无法打开图片或已损坏"的问题,作者对它进行简单的探讨.同时 ...
- 爬取图片过程遇到的ValueError: Missing scheme in request url: h 报错与解决方法
一 .scrapy整体框架 1.1 scrapy框架图 1.2 scrapy框架各结构解析 item:保存抓取的内容 spider:定义抓取内容的规则,也是我们主要编辑的文件 pipelines:管道 ...
- [译]Java Thread Sleep示例
Java Thread Sleep示例 java.lang.Thread sleep(long millis)方法被用来暂停当前线程的执行,暂停时间由方法参数指定,单位为毫秒.注意参数不能为负数,否则 ...
- [译]Java Thread join示例与详解
Java Thread join示例与详解 Java Thread join方法用来暂停当前线程直到join操作上的线程结束.java中有三个重载的join方法: public final void ...
- MinerHtmlThread.java 爬取页面线程
MinerHtmlThread.java 爬取页面线程 package com.iteye.injavawetrust.miner; import org.apache.commons.logging ...
- MinerConfig.java 爬取配置类
MinerConfig.java 爬取配置类 package com.iteye.injavawetrust.miner; import java.util.List; /** * 爬取配置类 * @ ...
- Java爬取网络博客文章
前言 近期本人在某云上购买了个人域名,本想着以后购买与服务器搭建自己的个人网站,由于需要筹备的太多,暂时先搁置了,想着先借用GitHub Pages搭建一个静态的站,搭建的过程其实也曲折,主要是域名地 ...
- Java爬取校内论坛新帖
Java爬取校内论坛新帖 为了保持消息灵通,博主没事会上上校内论坛看看新帖,作为爬虫爱好者,博主萌生了写个爬虫自动下载的想法. 嗯,这次就选Java. 第三方库准备 Jsoup Jsoup是一款比较好 ...
随机推荐
- luogu P3645 [APIO2015]雅加达的摩天楼 分块 根号分治
LINK:雅加达的摩天楼 容易想到设\(f_{i,j}\)表示第i个\(doge\)在第j层楼的最小步数. 转移显然是bfs.值得一提的是把初始某层的\(doge\)加入队列 然后转移边权全为1不需要 ...
- CF R638 div2 F Phoenix and Memory 贪心 线段树 构造 Hall定理
LINK:Phoenix and Memory 这场比赛标题好评 都是以凤凰这个单词开头的 有凤来仪吧. 其实和Hall定理关系不大. 不过这个定理有的时候会由于 先简述一下. 对于一张二分图 左边集 ...
- 账本APP开发
服务端开发 好好学习,天天向上 本文已收录至我的Github仓库DayDayUP:github.com/RobodLee/DayDayUP,欢迎Star,更多文章请前往:目录导航 前言 我平时喜欢用账 ...
- stl_heap
学习一下stl_heap 下面的算法是根据stl源码重新整合一下,是为了方便理解 因为使用的迭代器,为了在给定的迭代器之间使用heap的一些方法, 内部通常用disHole来确定某个节点 dishol ...
- js数组中如何去除重复值?
在日常开发中,我们可能会遇到将一个数组中里面的重复值去除,那么,我就将我自己所学习到的几种方法分享出来 去除数组重复值方法: 1,利用indexOf()方法去除 思路:创建一个新数组,然后循环要去重的 ...
- java.lang.NoSuchMethodError:javax.validation.BootstrapConfiguration.getClockProviderClassName
Spring Boot 2随附了hibernate-validator 6(org.hibernate.validator:hibernate-validator:6.0.16.Final依赖于val ...
- Python笔试——毕业旅行问题
毕业旅行问题 小明目前在做一份毕业旅行的规划.打算从北京出发,分别去若干个城市,然后再回到北京,每个城市之间均乘坐高铁,且每个城市只去一次.由于经费有限,希望能够通过合理的路线安排尽可能的省一些路上的 ...
- 5、Java 修饰符
引言:Java的修饰符根据修饰的对象不同,分为类修饰符.方法修饰符.变量修饰符,其中每种修饰符又分为访问控制修饰符和非访问控制修饰符. 1.访问控制修饰符的总结 四个关键字:public.protec ...
- Docker 搭建 Keycloak
Docker 搭建 Keycloak 命令 需要创建好数据库,启动容器指定数据库信息 # KEYCLOAK_USER 用户名 # KEYCLOAK_PASSWORD 密码 # DB_ADDR 数据库地 ...
- 代码生成器插件与Creator预制体文件解析
前言 之前写过一篇自动生成脚本的工具,但是我给它起名叫半自动代码生成器.之所以称之为半自动,因为我觉得全自动代码生成器应该做到两点:代码生成+自动绑定.之前的工具只做了代码生成,并没有做自动绑定,所以 ...