scrapy跟pyspider的杂谈
最近有一个私人项目要搞,可能最近的博客都会变成爬虫跟数据分析类的了。既然是爬虫,第一反应想到的就是鼎鼎大名的scrapy了,其次想到的pyspider,最后想到的就是自己写。
scrapy是封装了twisted的一个爬虫框架,项目结构比较清晰
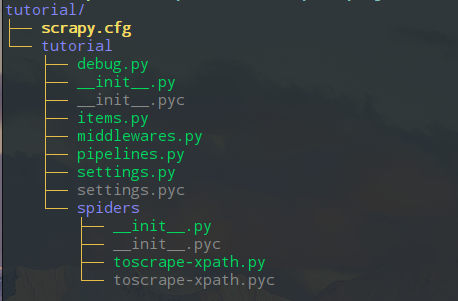
其中Item Pipeline决定了数据传输跟保存的结构,而爬虫的核心部分在spider目录下,而爬虫也只需要关系核心的解析规则编写。可以看出,scrapy框架搭了一个架子,在这框架中其实需要实现的核心功能还是要很多的,但是不需要关心中间件层面的东西了。另外scrapy很方便扩展,因此,是一个很不错的轮子了。
另外一个就是pyspider,这个框架封装了tornado,以及集成了一系列工具,比如lxml, css-selector-help,pyquery,phantomjs等,而且开放的api也相当精简,相当于说,pyspider就是针对新手量身定做的一个框架,类似于scrapy中中间件的东西,这边已经帮你集成好了,所有需要关心的就是你的爬虫规则,甚至爬虫规则都支持单步调试编写,门槛几乎为0了。
经过思考,如果要研究一个框架的技术,我决定还是研究pyspider会比较好,原因如下。
1.同样的异步框架,tornado可能比twisted抽象程度更低,且更现代一点;
2.pyquery,phantomjs等都是目前比较流行的前端解析工具,因此研究一下它的接入方式以及api封装对我来说更有实际价值;
3.不用操心scrapy的动态网站的处理,目前scrapy在我研究中发现,主要有几种方式解决:
(1)scrapy-splash:https://github.com/scrapy-plugins/scrapy-splash,另外有一个实战的例子也贴出来:http://blog.csdn.net/qq_23849183/article/details/51287935
(2)scrapy+spynner:实战例子也贴一下:http://kevinflynn.iteye.com/blog/2230990
但是 spynner是基于PyQT 和 WebKit构建的,而splash也是基于twisted跟QT。有QT,那肯定效率不行啊,还不如用selenium了,在这一点上,phantomjs是基于webkit的js api,因此它的好处就是快。综合考虑下,还是研究pyspider吧。
也许后续会贴出一系列pyspider源码分析的文章。
scrapy跟pyspider的杂谈的更多相关文章
- Pyspider框架
1, 2,在ubuntu安装pyspider如果出现pycul的问题 首先执行命令:sudo apt-get install libssl-dev libcurl4-openssl-dev pytho ...
- Python3爬虫(十六) pyspider框架
Infi-chu: http://www.cnblogs.com/Infi-chu/ 一.pyspider介绍1.基本功能 提供WebUI可视化功能,方便编写和调试爬虫 提供爬取进度监控.爬取结果查看 ...
- python爬虫之Scrapy学习
在爬虫的路上,学习scrapy是一个必不可少的环节.也许有好多朋友此时此刻也正在接触并学习scrapy,那么很好,我们一起学习.开始接触scrapy的朋友可能会有些疑惑,毕竟是一个框架,上来不知从何学 ...
- Scrapy框架的架构原理解析
爬虫框架--Scrapy 如果你对爬虫的基础知识有了一定了解的话,那么是时候该了解一下爬虫框架了.那么为什么要使用爬虫框架? 学习框架的根本是学习一种编程思想,而不应该仅仅局限于是如何使用它.从了解到 ...
- Python爬虫之PySpider框架
概述 pyspider 是一个支持任务监控.项目管理.多种数据库,具有 WebUI 的爬虫框架,它采用 Python 语言编写,分布式架构.详细特性如下: 拥有 Web 脚本编辑界面,任务监控器,项目 ...
- 放养的小爬虫--豆瓣电影入门级爬虫(mongodb使用教程~)
放养的小爬虫--豆瓣电影入门级爬虫(mongodb使用教程~) 笔者声明:只用于学习交流,不用于其他途径.源代码已上传github.githu地址:https://github.com/Erma-Wa ...
- 芝麻软件: Python爬虫进阶之爬虫框架概述
综述 爬虫入门之后,我们有两条路可以走. 一个是继续深入学习,以及关于设计模式的一些知识,强化Python相关知识,自己动手造轮子,继续为自己的爬虫增加分布式,多线程等功能扩展.另一条路便是学习一些优 ...
- python爬虫 | 一条高效的学习路径
数据是创造和决策的原材料,高质量的数据都价值不菲.而利用爬虫,我们可以获取大量的价值数据,经分析可以发挥巨大的价值,比如: 豆瓣.知乎:爬取优质答案,筛选出各话题下热门内容,探索用户的舆论导向. 淘宝 ...
- 专业的“python爬虫工程师”需要学习哪些知识?
学到哪种程度 暂且把目标定位初级爬虫工程师,简单列一下吧: (必要部分) 熟悉多线程编程.网络编程.HTTP协议相关 开发过完整爬虫项目(最好有全站爬虫经验,这个下面会说到) 反爬相关,cookie. ...
随机推荐
- sql中的for xml path() 实现字符串拼接
通常我们需要在sql中拼接字符串 ,可以用for xml path() 来进行拼接,如下实例. 同时未去掉最后一个逗号可以用LEFT函数来实现. ) AS UserName FRO ...
- mvc 筛选器
之前公司中,运用ActionFilterAttribute特性实现用户登录信息的验证,没事看了看,留下点东西备忘. 好的,瞅这玩意一眼就大概能猜到这货是干嘛的了吧,没错,action过滤器.其实就是A ...
- EF的DbSet属性的Where查询,注意事项
#1 Func<T,bool>与 Expression<Func<T,bool>>的区别 Func<T,bool>本身就是一个委托(delegate), ...
- javascript动画毛爷爷满天飘
var minSize=50;var maxSize=100;var newOn=200;var flakeColor="#fff";var flak=$("<di ...
- apache配置多个站点
序:这次项目主要是为了给微信客户端添加一个地址,在微信公众号里面添加一个可以访问的app下载页面,说起来很简单,但总不能为了这么小的一个网站新建一个web服务器吧! 现在开始配置,首先必须确认已经在L ...
- Android RoboGuice 使用指南
1.概述 在开发应用时一个基本原则是模块化,并且近最大可能性地降低模块之间的耦合性.在Java平台上Spring Framework 以及.Net 平台 CAB ,SCSF 和Prism (WPF,S ...
- IOS安装CocoaPods详情过程
一.简介 什么是CocoaPods CocoaPods是OS X和iOS下的一个第三类库管理工具,通过CocoaPods工具我们可以为项目添加被称为“Pods”的依赖库(这些类库必须是CocoaPod ...
- 零售业山重水复,全景行柳暗花明——VR全景智慧城市
对今天的中国来说,寻找经济转型的突破口,寻找经济权力的新霸主,零售业应该当仁不让. 零售业正在经历一场脱胎换骨的改造.一方面零售额达到前所未有的水平,另一方面,传统零售商也面临诸多挑战,其中之一,便是 ...
- React入门---属性(state)-7
state------>虚拟dom------>dom 这个过程是自动的,不需要触发其他事件来调用它. state中文理解:页面状态的的一个值,可以存储很多东西. 学习state的使用: ...
- 2.从AbstractQueuedSynchronizer(AQS)说起(1)——独占模式的锁获取与释放
首先我们从java.util.concurrent.locks包中的AbstraceQueuedSynchronizer说起,在下文中称为AQS. AQS是一个用于构建锁和同步器的框架.例如在并发包中 ...