scrapy跟pyspider的杂谈
最近有一个私人项目要搞,可能最近的博客都会变成爬虫跟数据分析类的了。既然是爬虫,第一反应想到的就是鼎鼎大名的scrapy了,其次想到的pyspider,最后想到的就是自己写。
scrapy是封装了twisted的一个爬虫框架,项目结构比较清晰
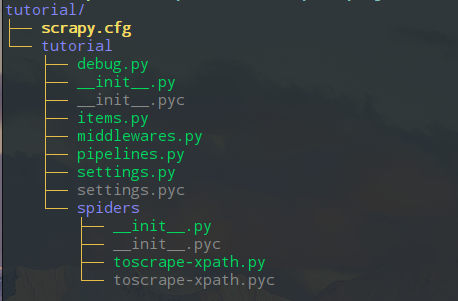
其中Item Pipeline决定了数据传输跟保存的结构,而爬虫的核心部分在spider目录下,而爬虫也只需要关系核心的解析规则编写。可以看出,scrapy框架搭了一个架子,在这框架中其实需要实现的核心功能还是要很多的,但是不需要关心中间件层面的东西了。另外scrapy很方便扩展,因此,是一个很不错的轮子了。
另外一个就是pyspider,这个框架封装了tornado,以及集成了一系列工具,比如lxml, css-selector-help,pyquery,phantomjs等,而且开放的api也相当精简,相当于说,pyspider就是针对新手量身定做的一个框架,类似于scrapy中中间件的东西,这边已经帮你集成好了,所有需要关心的就是你的爬虫规则,甚至爬虫规则都支持单步调试编写,门槛几乎为0了。
经过思考,如果要研究一个框架的技术,我决定还是研究pyspider会比较好,原因如下。
1.同样的异步框架,tornado可能比twisted抽象程度更低,且更现代一点;
2.pyquery,phantomjs等都是目前比较流行的前端解析工具,因此研究一下它的接入方式以及api封装对我来说更有实际价值;
3.不用操心scrapy的动态网站的处理,目前scrapy在我研究中发现,主要有几种方式解决:
(1)scrapy-splash:https://github.com/scrapy-plugins/scrapy-splash,另外有一个实战的例子也贴出来:http://blog.csdn.net/qq_23849183/article/details/51287935
(2)scrapy+spynner:实战例子也贴一下:http://kevinflynn.iteye.com/blog/2230990
但是 spynner是基于PyQT 和 WebKit构建的,而splash也是基于twisted跟QT。有QT,那肯定效率不行啊,还不如用selenium了,在这一点上,phantomjs是基于webkit的js api,因此它的好处就是快。综合考虑下,还是研究pyspider吧。
也许后续会贴出一系列pyspider源码分析的文章。
scrapy跟pyspider的杂谈的更多相关文章
- Pyspider框架
1, 2,在ubuntu安装pyspider如果出现pycul的问题 首先执行命令:sudo apt-get install libssl-dev libcurl4-openssl-dev pytho ...
- Python3爬虫(十六) pyspider框架
Infi-chu: http://www.cnblogs.com/Infi-chu/ 一.pyspider介绍1.基本功能 提供WebUI可视化功能,方便编写和调试爬虫 提供爬取进度监控.爬取结果查看 ...
- python爬虫之Scrapy学习
在爬虫的路上,学习scrapy是一个必不可少的环节.也许有好多朋友此时此刻也正在接触并学习scrapy,那么很好,我们一起学习.开始接触scrapy的朋友可能会有些疑惑,毕竟是一个框架,上来不知从何学 ...
- Scrapy框架的架构原理解析
爬虫框架--Scrapy 如果你对爬虫的基础知识有了一定了解的话,那么是时候该了解一下爬虫框架了.那么为什么要使用爬虫框架? 学习框架的根本是学习一种编程思想,而不应该仅仅局限于是如何使用它.从了解到 ...
- Python爬虫之PySpider框架
概述 pyspider 是一个支持任务监控.项目管理.多种数据库,具有 WebUI 的爬虫框架,它采用 Python 语言编写,分布式架构.详细特性如下: 拥有 Web 脚本编辑界面,任务监控器,项目 ...
- 放养的小爬虫--豆瓣电影入门级爬虫(mongodb使用教程~)
放养的小爬虫--豆瓣电影入门级爬虫(mongodb使用教程~) 笔者声明:只用于学习交流,不用于其他途径.源代码已上传github.githu地址:https://github.com/Erma-Wa ...
- 芝麻软件: Python爬虫进阶之爬虫框架概述
综述 爬虫入门之后,我们有两条路可以走. 一个是继续深入学习,以及关于设计模式的一些知识,强化Python相关知识,自己动手造轮子,继续为自己的爬虫增加分布式,多线程等功能扩展.另一条路便是学习一些优 ...
- python爬虫 | 一条高效的学习路径
数据是创造和决策的原材料,高质量的数据都价值不菲.而利用爬虫,我们可以获取大量的价值数据,经分析可以发挥巨大的价值,比如: 豆瓣.知乎:爬取优质答案,筛选出各话题下热门内容,探索用户的舆论导向. 淘宝 ...
- 专业的“python爬虫工程师”需要学习哪些知识?
学到哪种程度 暂且把目标定位初级爬虫工程师,简单列一下吧: (必要部分) 熟悉多线程编程.网络编程.HTTP协议相关 开发过完整爬虫项目(最好有全站爬虫经验,这个下面会说到) 反爬相关,cookie. ...
随机推荐
- for xml path 如何将字段转换为xml的属性
for xml path 如何将字段作为xml的属性: 可在查询时 别名用 as '@..' 如'@value' 如下实例: SELECT A.GiftSetGUID AS '@value',A.Gi ...
- SSE 系列内置函数中的 shuffle 函数
SSE 系列内置函数中的 shuffle 函数 邮箱: quarrying@qq.com 博客: http://www.cnblogs.com/quarryman/ 发布时间: 2017年04月18日 ...
- mysql数据库开启日志
旧版 #开启慢查询 slow_query_log # (超过2秒的SQL语法记录起来,设短一点来记录除错也是一种方法.) long_query_time = 2 log-slow-queries=D: ...
- Mac 下载安装MySQL
step 1. 从官网上下载MySQL Community Server step 2. 安装MySQL step 3. 配置mysql和mysqladmin的alias $ vim ~/.bashr ...
- 通过chrome inspect 来调试手机hybird APP
hybird APP 虽然显示效果和编译前的前端页面大致相同,但是其中操作可能会调用一些浏览器中没有的接口,从而产生一些意料之外的问题,因此了解和掌握如何调试就变得尤为重要. 本文简要介绍了如何利用c ...
- JS + HTml 时钟代码实现
JS+ Html 画布实现的时钟效果图: 闲来无聊做了一个网页的时钟,效果模拟传统时钟的运行方式, 运用了html 的画布实现指针,背景图片引用了网络图片. 具体原理: 首先将时钟分为四个不同区域,对 ...
- 移动端H5开发 (滑动事件)
最近一直在做手机App H5的开发,在开发过程中,经常会遇到很多滑动事件,写个demo,分享自己的一些写法.(如写的不好,轻喷!) 直接贴代码 html css代码 <!DOCTYPE html ...
- 金山助手流氓软件-被进程sjk_daemon.exe坑死
修改完Android工程代码,进入调试阶段时DDMS中报错:The connection to adb is down, and a severe error has occured. 由于之前也碰到 ...
- 【算法系列学习】[kuangbin带你飞]专题十二 基础DP1 C - Monkey and Banana
https://vjudge.net/contest/68966#problem/C [参考]http://blog.csdn.net/qinmusiyan/article/details/79862 ...
- phpcms笔记
一.建立虚拟站点 1.先更改www目录下的站点名称,再找到apache, 打开"Apache2\conf\extra"下的"httpd-vhosts.conf" ...