使用selenium webdriver+beautifulsoup+跳转frame,实现模拟点击网页下一页按钮,抓取网页数据
记录一次快速实现的python爬虫,想要抓取中财网数据引擎的新三板板块下面所有股票的公司档案,网址为http://data.cfi.cn/data_ndkA0A1934A1935A1986A1995.html。
比较简单的网站不同的页码的链接也不同,可以通过观察链接的变化找出规律,然后生成全部页码对应的链接再分别抓取,但是这个网站在换页的时候链接是没有变化的,因此打算去观察一下点击第二页时的请求
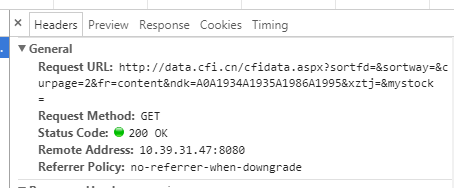
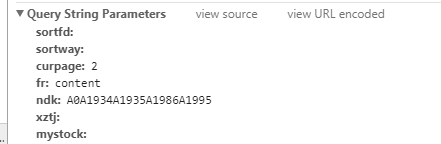
发现使用的是get的请求方法,并且请求里有curpage这个参数,貌似控制着不同页数,于是改动了请求链接中的这个参数值为其他数值发现并没有变化,于是决定换一种方法,就是我们标题中提到的使用selenium+beautifulsoup实现模拟点击网页中的下一页按钮来实现翻页,并分别抓取网页里的内容。
首先我们先做一下准备工作,安装一下需要的包,打开命令行,直接pip install selenium和pip install beautifulsoup4
然后就是下载安装chromedriver的驱动,网址如下https://sites.google.com/a/chromium.org/chromedriver/downloads,记得配置下环境变量或者直接安装在工作目录下。(还可以使用IE、phantomJS等)
这里我们先抓取每一个股票对应的主页链接,代码如下(使用python2):
1 # -*- coding: utf-8 -*-
2 from selenium import webdriver
3 from bs4 import BeautifulSoup
4 import sys
5 reload(sys)
6 sys.setdefaultencoding('utf-8')
7
8 def crawl(url):
9 driver = webdriver.Chrome()
10 driver.get(url)
11 page = 0
12 lst=[]
13 with open('./url.txt','a') as f:
14 while page < 234:
15 soup = BeautifulSoup(driver.page_source, "html.parser")
16 print(soup)
17 urls_tag = soup.find_all('a',target='_blank')
18 print(urls_tag)
19 for i in urls_tag:
20 if i['href'] not in lst:
21 f.write(i['href']+'\n')
22 lst.append(i['href'])
23 driver.find_element_by_xpath("//a[contains(text(),'下一页')]").click()
24 time.sleep(2)
25 return 'Finished'
26 def main():
27 url = 'http://data.cfi.cn/cfidata.aspx?sortfd=&sortway=&curpage=2&fr=content&ndk=A0A1934A1935A1986A1995&xztj=&mystock='
28 crawl(url)
29 if __name__ == '__main__':
30 main()
运行代码发现总是报错:

这里报错的意思是找不到想要找的按钮。
于是我们去查看一下网页源代码:
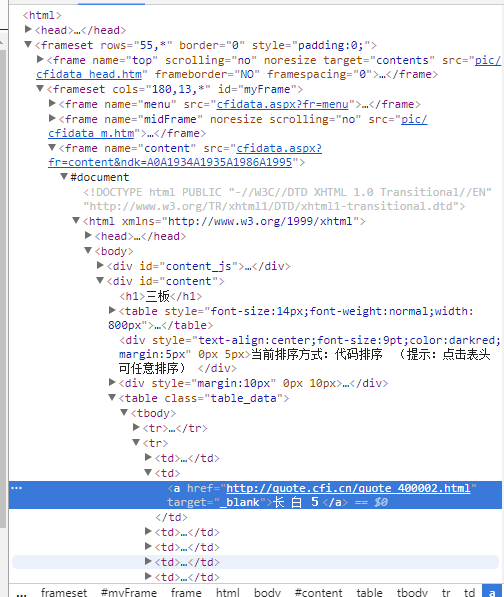
发现网页分为不同的frame,所以我们猜想应该需要跳转frame,我们需要抓取的链接处于的frame的name为“content”,所以我们添加一行代码:driver.switch_to.frame('content')
def crawl(url):
driver = webdriver.Chrome()
driver.get(url)
driver.switch_to.frame('content')
page = 0
lst=[]
with open('./url.txt','a') as f:
while page < 234:
soup = BeautifulSoup(driver.page_source, "html.parser")
print(soup)
urls_tag = soup.find_all('a',target='_blank')
print(urls_tag)
for i in urls_tag:
if i['href'] not in lst:
f.write(i['href']+'\n')
lst.append(i['href'])
driver.find_element_by_xpath("//a[contains(text(),'下一页')]").click()
time.sleep(2)
return 'Finished'
至此,运行成:
参考博文链接: http://unclechen.github.io/2016/12/11/python%E5%88%A9%E7%94%A8beautifulsoup+selenium%E8%87%AA%E5%8A%A8%E7%BF%BB%E9%A1%B5%E6%8A%93%E5%8F%96%E7%BD%91%E9%A1%B5%E5%86%85%E5%AE%B9/
http://www.cnblogs.com/liyuhang/p/6661835.html
使用selenium webdriver+beautifulsoup+跳转frame,实现模拟点击网页下一页按钮,抓取网页数据的更多相关文章
- 使用Selenium+firefox抓取网页指定firefox_profile后的问题
from: https://blog.csdn.net/chufazhe/article/details/51145834 摘要:在使用selenium和firefox抓取网页指定firefox_pr ...
- [Python爬虫] 之八:Selenium +phantomjs抓取微博数据
基本思路:在登录状态下,打开首页,利用高级搜索框输入需要查询的条件,点击搜索链接进行搜索.如果数据有多页,每页数据是20条件,读取页数 然后循环页数,对每页数据进行抓取数据. 在实践过程中发现一个问题 ...
- [Python爬虫] 之四:Selenium 抓取微博数据
抓取代码: # coding=utf-8import osimport refrom selenium import webdriverimport selenium.webdriver.suppor ...
- selenium配合phantomjs实现爬虫功能,并把抓取的数据写入excel
# -*- coding: UTF-8 -*- ''' Created on 2016年5月13日 @author: csxie ''' import datetime from Base impor ...
- 利用selenium抓取网页的ajax请求
部门需要一个自动化脚本,完成web端界面功能的冒烟,并且需要抓取加载页面时的ajax请求,从接口层面判断请求是否成功.查阅了很多资料都没有人有过相关问题的处理经验,在处理过程中也踩了很多坑,所以如果你 ...
- php使用curl抓取网页自动跳转问题处理
问题分析: 请求抓取http://go.com数据: function curlGet($url) { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, ...
- python+selenium+webdriver+BeautifulSoup实现自动登录
from selenium import webdriverimport timefrom bs4 import BeautifulSoupfrom urllib import requestimpo ...
- 一、使用 BeautifulSoup抓取网页信息信息
一.解析网页信息 from bs4 import BeautifulSoup with open('C:/Users/michael/Desktop/Plan-for-combating-master ...
- Selenium webdriver 截图 太长截不全的问题
Selenium webdriver 截图 太长截不全的问题 1.环境 selenium webdriver.net 2.46.0.0 + firefox 37.0.1 + win 8.1 2.问题 ...
随机推荐
- python 输出颜色的与样式的方法
上次遇到这个问题就想写下来,其实当时我也不怎么会,老师说这个东西不需要理解,只需要死记硬背,写的多了就记住了,所以今天搜集了几篇文章,加上自己的理解,写下了这篇python 输出颜色的样式与方法的文章 ...
- Shiro第三篇【授权、自定义reaml授权】
Shiro授权 上一篇我们已经讲解了Shiro的认证相关的知识了,现在我们来弄Shiro的授权 Shiro授权的流程和认证的流程其实是差不多的: Shiro支持的授权方式 Shiro支持的授权方式有三 ...
- Django中的信号及其用法
Django中提供了"信号调度",用于在框架执行操作时解耦. 一些动作发生的时候,系统会根据信号定义的函数执行相应的操作 Django中内置的signal Model_signal ...
- 只用一招让你Maven依赖下载速度快如闪电
一.背景 众所周知,Maven对于依赖的管理让我们程序员感觉爽的不要不要的,但是由于这货是国外出的,所以在我们从中央仓库下载依赖的时候,速度如蜗牛一般,让人不能忍,并且这也是大多数程序员都会遇到的问题 ...
- Kafka水位(high watermark)与leader epoch的讨论
~~~这是一篇有点长的文章,希望不会令你昏昏欲睡~~~ 本文主要讨论0.11版本之前Kafka的副本备份机制的设计问题以及0.11是如何解决的.简单来说,0.11之前副本备份机制主要依赖水位(或水印) ...
- 由一次自建库迁移到阿里云RDS引发的性能问题。
刚入职一互联网公司,项目正好处于计划上线的时间,由于公司前不久已经购买了rds服务,领导决定尝试一番! 当然,新事物.云事物还是要谨慎的.安排我先把测试环境数据库迁移上去,这里吐槽一下,往rds迁移一 ...
- [python学习笔记] String格式化
格式化 S % (args...) 方式 特点 str里的占位符同java里的占位符. 优势 这种方式可以限定格式化的时候接受的数据类型. 常见占位符 %d 接收数字,格式化为 十进制 %x 接收数字 ...
- Safe Area Layout Guide
原文:Safe Area Layout Guide Apple在iOS 7中引入了topLayoutGuide和bottomLayoutGuide作为UIViewController属性.它们允许您创 ...
- swift 开发学习问题
1 UITableViewController 问题: [UITableView dequeueReusableCellWithIdentifier:forIndexPath:], unable to ...
- 2008-2009 ACM-ICPC, NEERC, Southern Subregional ContestF
Problem F. Text Editor Input file: stdin Output file: stdout Time limit: 1 second Memory limit: 64 m ...