使用java API操作hdfs--拷贝部分文件到本地
要求:和前一篇的要求正好相反。。
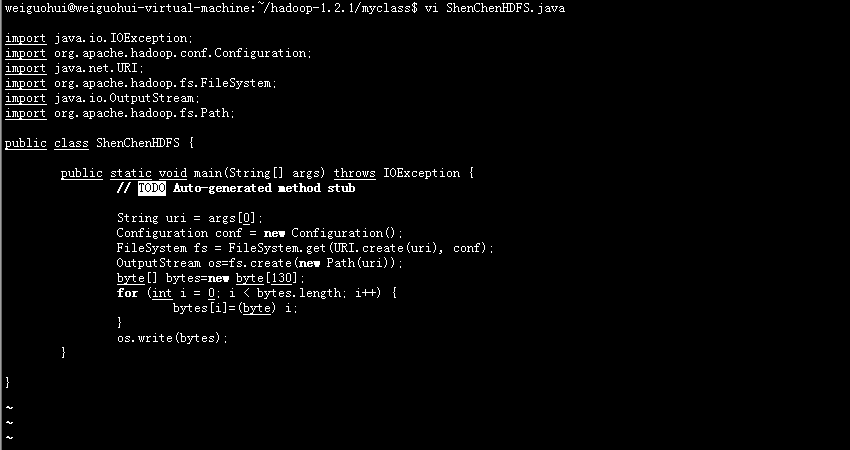
在HDFS中生成一个130KB的文件:
代码如下:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import java.net.URI;
import org.apache.hadoop.fs.FileSystem;
import java.io.OutputStream;
import org.apache.hadoop.fs.Path;
public class ShenChenHDFS {
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
OutputStream os=fs.create(new Path(uri));
byte[] bytes=new byte[130];
for (int i = 0; i < bytes.length; i++) {
bytes[i]=(byte) i;
}
os.write(bytes);
}
}
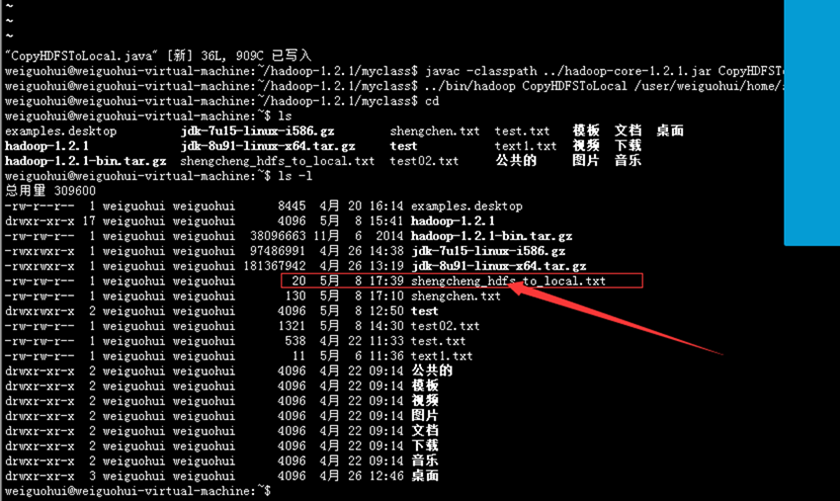
运行的结果:

代码如下:
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.fs.Path;
import java.net.URI;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.conf.Configuration;
public class CopyHDFSToLocal {
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
InputStream in = in = fs.open(new Path(uri));
File file=new File("/home/weiguohui/shengcheng_hdfs_to_local.txt");
FileOutputStream fos=new FileOutputStream(file);
byte[] bytes=new byte[1024];
int offset=100;
int len=20;
int numberRead=0;
while((numberRead=in.read(bytes))!=-1){
fos.write(bytes, 100, 20);
}
IOUtils.closeStream(in);
IOUtils.closeStream(fos);
}
}
使用java API操作hdfs--拷贝部分文件到本地的更多相关文章
- 使用Java API操作HDFS文件系统
使用Junit封装HFDS import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org ...
- 使用Java Api 操作HDFS
如题 我就是一个标题党 就是使用JavaApi操作HDFS,使用的是MAVEN,操作的环境是Linux 首先要配置好Maven环境,我使用的是已经有的仓库,如果你下载的jar包 速度慢,可以改变Ma ...
- 使用java API操作hdfs--拷贝部分文件到hdfs
要求如下: 自行在本地文件系统生成一个大约一百多字节的文本文件,写一段程序(可以利用Java API或C API),读入这个文件,并将其第101-120字节的内容写入HDFS成为一个新文件. impo ...
- Hadoop Java API操作HDFS文件系统(Mac)
1.下载Hadoop的压缩包 tar.gz https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/ 2.关联jar包 在 ...
- Java API 读取HDFS的单文件
HDFS上的单文件: -bash-3.2$ hadoop fs -ls /user/pms/ouyangyewei/data/input/combineorder/repeat_rec_categor ...
- 使用java api操作HDFS文件
实现的代码如下: import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; import ...
- hadoop学习笔记(五):java api 操作hdfs
HDFS的Java访问接口 1)org.apache.hadoop.fs.FileSystem 是一个通用的文件系统API,提供了不同文件系统的统一访问方式. 2)org.apache.hadoop. ...
- HDFS 05 - HDFS 常用的 Java API 操作
目录 0 - 配置 Hadoop 环境(Windows系统) 1 - 导入 Maven 依赖 2 - 常用类介绍 3 - 常见 API 操作 3.1 获取文件系统(重要) 3.2 创建目录.写入文件 ...
- Hadoop之HDFS(三)HDFS的JAVA API操作
HDFS的JAVA API操作 HDFS 在生产应用中主要是客户端的开发,其核心步骤是从 HDFS 提供的 api中构造一个 HDFS 的访问客户端对象,然后通过该客户端对象操作(增删改查)HDFS ...
随机推荐
- ARC引用计数
NSlog(@"Retain count is %ld", CFGetRetainCount((__bridge CFTypeRef)self)); block保环流---> ...
- 配置linux实现路由功能
说明: 主机1是内网的数据存储服务器,只有一块网卡10.0.0.2: 主机2是web服务器,有两块网卡,一块面向内网10.0.0.3,一块面向外网192.168.220.136: (因为是在虚拟机的环 ...
- maven修改远程和本地仓库地址
简介:我们用maven的时候,maven自带的远程中央仓库经常会很慢,还有默认本地仓库是在c盘C:\Users\你的电脑用户账号\.m2\repository, 对于有强迫症的人,总是看的不爽,下面介 ...
- unity传送门类似效果实现
简述 在传送门中,核心的玩法是在地上或者墙上打开2个可以联通的洞来实现传送的效果.以此扩展加入解谜要素构成游戏的核心. 这里尝试使用unity来实现传送门的核心功能,具体功能分析如下: 1.传送门的模 ...
- java学习常遇问题及解决方案
eclipse中的项目运行时不出现run as→java application选项? 解决方案☞必须有正确的主方法,即public static void main(String[]args){}
- 老李推荐:第14章3节《MonkeyRunner源码剖析》 HierarchyViewer实现原理-HierarchyViewer实例化
老李推荐:第14章3节<MonkeyRunner源码剖析> HierarchyViewer实现原理-HierarchyViewer实例化 poptest是国内唯一一家培养测试开发工程师的培 ...
- 转接口IC GM7150BN/ GM7150BC:CVBS转BT656芯片 低功耗NTSC/PAL 视频解码器
1 概述 GM7150 是一款9 位视频输入预处理芯片,该芯片采用CMOS 工艺,通过I2C 总线与PC 或DSP 相连构成应用系统. 它内部包含1 个模拟处理通道,能实现CVBS.S-V ...
- Android 开发之开发插件使用:Eclipse 插件 SQLiteManger eclipse中查看数据内容--翻译
最近研究了一段时间Android开发后发现,google自带的ADT工具,缺失一些开发常用的东西,希望可以构建一个类似使用JAVA EE开发体系一样开发的工具包集合,包括前台开发,调试,到后台数据库的 ...
- linux环境下 mysql数据库忘记密码 处理办法UPDATE user SET Password = password ( 'new-password' ) WHERE User = 'root' ;
整个修改过程大概3-10分钟(看个人操作),这个时间内mysql出于不需要密码就能登陆的状态,请设法保证系统安全 不罗嗦直接上步骤 1.vi /etc/my.cnf 在[mysqld]下,添加一句:s ...
- SQL入门之条件表达式
where子句和having子句主要是用来筛选符合条件的元组,其后紧跟的即为条件表达式. 0.and, or条件的连接 用法和一般编程语言一样,主要用于条件的拼接.and两边都为真,则结果为真.or两 ...