机器学习:从编程的角度理解BP神经网络
1.简介(只是简单介绍下理论内容帮助理解下面的代码,如果自己写代码实现此理论不够)
1) BP神经网络是一种多层网络算法,其核心是反向传播误差,即: 使用梯度下降法(或其他算法),通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。
BP神经网络模型拓扑结构包括输入层(input)、隐藏层(hidden layer)和输出层(output layer),每层包含多个神经元。
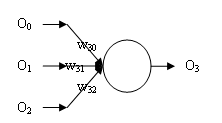
2)BP神经网络示例图

上图就是一个简单的三层BP神经网络。网络共有6个单元,O0用于表示阈值,O1、O2为输入层,O3、O4为第一隐层,也是唯一隐层,O5为输出层单元。网络接收两个输入 ,发送一个输出
,发送一个输出 。每个单元接收一组输入,发送一个输出。
。每个单元接收一组输入,发送一个输出。 为权值,例如W40 表示O0与O4之间的权重。
为权值,例如W40 表示O0与O4之间的权重。
3)神经单元(计算单元)
如上图所示,每个圆表示一个神经单元。其接收一组数据,经过计算输出一个数据。
4)传播过程
a)正向传递
例如:从O1-->O4-->05,这是正向传递过程中的一个路径(O4除了接收O1,还接收O0、O2的输入)。这里重点说下权重,W41表示O1和O4之间的权重,假如O1=1,O4=4,W41=0.5,那么O5=1*4*0.5=2(2不是最终输出,最终输出还需要加上O0、O2 的计算结果).
b)反向传递(过程比较复杂,这个表述不是特别精确,只是为了方便理解)
例如:从O1<--O4<--05,在这个过程中,O5是计算出的值,参与计算的O4的值不是其本身的值,而是在正向传递过程中计算出的值(即输出值)。而权重也是这个过程中调整的。
2.MLPClassifier函数
此函数是sklearn.neural_network中的函数,它是利用反向传播误差进行计算的多层感知器算法。
a) 主要参数
hidden_layer_sizes:隐藏层,例如:(5,2) 表示有2个隐藏层,第一隐藏层有5个神经单元,第二个隐藏层有2个神经单元;(5,2,4)表示有三个隐藏层。
activation:激活函数,在反向传递中需要用到。有以下四个可选项:
'identity':无激活操作,有助于实现线性瓶颈, 返回 f(x) = x
'logistic':逻辑函数, 返回 f(x) = 1 / (1 + exp(-x)).
'tanh': 双曲线函数, 返回 f(x) = tanh(x).
'relu': 矫正线性函数, 返回 f(x) = max(0, x),(默认)
solver:反向传播过程中采用的算法,有以下三个选项:
'lbfgs': 准牛顿算法.适用于较小数据集
'sgd': 随机梯度下降算法.
'adam':优化的随机梯度下降算法(默认)。适用于较大数据集
alpha:L2惩罚系数
learning_rate:学习速率,有以下几个选项:(只有当slver='sgd'时有用)
constant:参数learning_rate_init指定的恒定学习速率.(默认选项)
invscaling’:使用“scale_t”的反向缩放指数逐渐降低每个时间步长t 的学习率。effective_learning_rate = learning_rate_init / pow(t,power_t)(power_t是另外一个参数)
adaptive: 自适应,只要损失不断下降就是用learning_rate_init。否则会自动调整(由另外一个参数tol决定)。
learning_rate_init:初始学习速率
b)属性
coefs_:权重列表
n_layers_:神经网络的总层数
3.示例一
本示例使用的数据:机器学习:从编程的角度去理解逻辑回归 。在下面的参数情况下正确率95%。
import numpy as np
import os
import pandas as pd
from sklearn.neural_network import MLPClassifier def loadDataSet():
##运行脚本所在目录
base_dir=os.getcwd()
##记得添加header=None,否则会把第一行当作头
data=pd.read_table(base_dir+r"\lr.txt",header=None)
##dataLen行dataWid列 :返回值是dataLen=100 dataWid=3
dataLen,dataWid = data.shape
##训练数据集
xList = []
##标签数据集
lables = []
##读取数据
for i in range(dataLen):
row = data.values[i]
xList.append(row[0:dataWid-1])
lables.append(row[-1])
return xList,lables def GetResult():
dataMat,labelMat=loadDataSet()
clf = MLPClassifier(solver='lbfgs', alpha=1e-5,
hidden_layer_sizes=(5,2), random_state=1)
clf.fit(dataMat, labelMat)
#print("层数----------------------")
#print(clf.n_layers_)
#print("权重----------------------")
#for cf in clf.coefs_:
# print(cf)
#print("预测值----------------------")
y_pred=clf.predict(dataMat)
m = len(y_pred)
##分错4个
t = 0
f = 0
for i in range(m):
if y_pred[i] ==labelMat[i]:
t += 1
else :
f += 1
print("正确:"+str(t))
print("错误:"+str(f)) if __name__=='__main__':
GetResult()
4.示例二(数据来源)
这次使用的数据还是红酒。因为红酒的口感得分是整数,所以也可以当作是分类。但是针对此实验数据,在多次调整参数的过程中(主要是调整隐藏层)正确率最高只有61%。这正是BP神经网络的一个缺陷:隐含层的选取缺乏理论的指导。
代码:
import numpy as np
import os
import pandas as pd
from sklearn.neural_network import MLPClassifier ##运行脚本所在目录
base_dir=os.getcwd()
##记得添加header=None,否则会把第一行当作头
data=pd.read_table(base_dir+r"\wine.txt",header=None,sep=';')
##dataLen行dataWid列 :返回值是dataLen=1599 dataWid=12
dataLen,dataWid = data.shape ##训练数据集
xList = []
##标签数据集
lables = []
##读取数据
for i in range(dataLen):
row = data.values[i]
xList.append(row[0:dataWid-1])
lables.append(row[-1])
##设置训练函数
clf = MLPClassifier(solver='lbfgs', alpha=1e-5,
hidden_layer_sizes=(14,14,30), random_state=1)
##开始训练数据
clf.fit(xList, lables)
##读取预测值
y_pred=clf.predict(xList)
m = len(y_pred) t = 0
f = 0
##预测结果分析
for i in range(m):
if int(y_pred[i]) == lables[i]:
t += 1
else :
f += 1
print("正确:"+str(t))
print("错误:"+str(f))
5.BP神经网络的缺点
1)容易形成局部极小值而得不到全局最优值。BP神经网络中极小值比较多,所以很容易陷入局部极小值,这就要求对初始权值和阀值有要求,要使得初始权值和阀值随机性足够好,可以多次随机来实现。
2)训练次数多使得学习效率低,收敛速度慢。
3)隐含层的选取缺乏理论的指导。
4)训练时学习新样本有遗忘旧样本的趋势。(可以把最优的权重记录下来)
机器学习:从编程的角度理解BP神经网络的更多相关文章
- 从编程的角度理解gradle脚本﹘﹘Android Studio脚本构建和编程[魅族Degao]
本篇文章由嵌入式企鹅圈原创团队.魅族资深project师degao撰写. 随着Android 开发环境从Eclipse转向Android Studio,我们每一个人都開始或多或少要接触gradle脚本 ...
- 机器学习(4):BP神经网络原理及其python实现
BP神经网络是深度学习的重要基础,它是深度学习的重要前行算法之一,因此理解BP神经网络原理以及实现技巧非常有必要.接下来,我们对原理和实现展开讨论. 1.原理 有空再慢慢补上,请先参考老外一篇不错的 ...
- 菜鸟之路——机器学习之BP神经网络个人理解及Python实现
关键词: 输入层(Input layer).隐藏层(Hidden layer).输出层(Output layer) 理论上如果有足够多的隐藏层和足够大的训练集,神经网络可以模拟出任何方程.隐藏层多的时 ...
- 机器学习:python使用BP神经网络示例
1.简介(只是简单介绍下理论内容帮助理解下面的代码,如果自己写代码实现此理论不够) 1) BP神经网络是一种多层网络算法,其核心是反向传播误差,即: 使用梯度下降法(或其他算法),通过反向传播来不断调 ...
- NO.2:自学tensorflow之路------BP神经网络编程
引言 在上一篇博客中,介绍了各种Python的第三方库的安装,本周将要使用Tensorflow完成第一个神经网络,BP神经网络的编写.由于之前已经介绍过了BP神经网络的内部结构,本文将直接介绍Tens ...
- 机器学习(一):梯度下降、神经网络、BP神经网络
这几天围绕论文A Neural Probability Language Model 看了一些周边资料,如神经网络.梯度下降算法,然后顺便又延伸温习了一下线性代数.概率论以及求导.总的来说,学到不少知 ...
- 【机器学习】BP神经网络实现手写数字识别
最近用python写了一个实现手写数字识别的BP神经网络,BP的推导到处都是,但是一动手才知道,会理论推导跟实现它是两回事.关于BP神经网络的实现网上有一些代码,可惜或多或少都有各种问题,在下手写了一 ...
- 机器学习入门学习笔记:(一)BP神经网络原理推导及程序实现
机器学习中,神经网络算法可以说是当下使用的最广泛的算法.神经网络的结构模仿自生物神经网络,生物神经网络中的每个神经元与其他神经元相连,当它“兴奋”时,想下一级相连的神经元发送化学物质,改变这些神经元的 ...
- 简单易学的机器学习算法——神经网络之BP神经网络
一.BP神经网络的概念 BP神经网络是一种多层的前馈神经网络,其基本的特点是:信号是前向传播的,而误差是反向传播的.详细来说.对于例如以下的仅仅含一个隐层的神经网络模型: watermark/ ...
随机推荐
- z-index失效的原因
在做的过程中,发现了一个很简单却又很多人应该碰到的问题,设置Z-INDEX属性无效.在CSS中,只能通过代码改变层级,这个属性就是z-index,要让z-index起作用有个小小前提,就是元素的pos ...
- line-height属性总结
line-height属性的继承性: 子元素不设置line-height时, 在父元上设置带单位的值和百分比时会先计算父元素的line-height大小然后继承过来,在父元素上设置无单位的数值时,子 ...
- wamp2.4.4 如何配置虚拟主机及反向代理(解决跨域问题)
一.找到安装目录下的httpd.conf文件 1. 删除Include conf/extra/httpd-vhosts.conf前面的#号(开启虚拟主机的配置) 2. 删除LoadModule pro ...
- PRINCE2考试一共多少道题
一.Foundation 基础级: 考试时长 1 个小时: 75 道单选题,其中 5 道随机测试题,无论对错都不计入考分:满分 70 分,获得 35 分才能通过考试,正确率 50%: 全程闭卷考试 二 ...
- Apache Mina入门实例
一.mina是啥 ApacheMINA是一个网络应用程序框架,用来帮助用户简单地开发高性能和高可扩展性的网络应用程序.它提供了一个通过Java NIO在不同的传输例如TCP/IP和UDP/IP上抽象的 ...
- es 6点滴记录
关于babel和webpack的使用: Babel 所做的只是帮你把'ES6 模块化语法'转化为'CommonJS 模块化语法',其中的require exports 等是 CommonJS 在具体实 ...
- 浩哥解析MyBatis源码(四)——DataSource数据源模块
原创作品,可以转载,但是请标注出处地址:http://www.cnblogs.com/V1haoge/p/6634880.html 1.回顾 上一文中解读了MyBatis中的事务模块,其实事务操作无非 ...
- 老李分享:大数据框架Hadoop和Spark的异同 2
Spark数据处理速度秒杀MapReduce Spark因为其处理数据的方式不一样,会比MapReduce快上很多.MapReduce是分步对数据进行处理的: ”从集群中读取数据,进行一次处理,将结果 ...
- 接口测试培训:HTTP协议基础
接口测试培训:HTTP协议基础 引言 HTTP是一个属于应用层的面向对象的协议,由于其简捷.快速的方式,适用于分布式超媒体信息系统.它于1990年提出,经过几年的使用与发展,得到不断地完善和扩展. ...
- WPF自定义控件(2)——图表设计[1]
0.小叙闲言 除了仪表盘控件比较常用外,还有图表也经常使用,同样网上也有非常强大的图表控件,有收费的(DEVexpress),也有免费的.但我们平时在使用时,只想简单地绘一个图,控件库里面的许多功能我 ...