浅谈SQL优化入门:2、等值连接和EXPLAIN(MySQL)
1、等值连接:显性连接和隐性连接
//WHERE方式
SELECT
vend_name,
prod_name,
prod_price,
quantity
FROM
vendors,
products,
orderitems
WHERE
vendors.vend_id = products.vend_id
AND
orderitems.prod_id = products.prod_id;//WHERE方式
SELECT
vend_name,
prod_name,
prod_price,
quantity
FROM
vendors,
products,
orderitems
WHERE
vendors.vend_id = products.vend_id
AND
orderitems.prod_id = products.prod_id;
//INNER JOIN方式
SELECT
vend_name,
prod_name,
prod_price,
quantity
FROM
(vendors INNER JOIN products ON vendors.vend_id = prodcuts.vend_id)
INNER JOIN orderitems ON orderitems.prod_id = products.prod_id;//INNER JOIN方式
SELECT
vend_name,
prod_name,
prod_price,
quantity
FROM
(vendors INNER JOIN products ON vendors.vend_id = prodcuts.vend_id)
INNER JOIN orderitems ON orderitems.prod_id = products.prod_id;
- 隐性连接,在FROM过程中对所有表进行笛卡儿积,最终通过WHERE条件过滤
- 显性连接,在每一次表连接时通过ON过滤,筛选后的结果集再和下一个表做笛卡儿积,以此循环
- 隐性连接,做所有表的笛卡儿积,共1000*1000*1000=1亿 行数据,再通过WHERE过滤,也就是说,三张表连接最终扫描的数据量高达1亿
- 显性连接,先做头两张表的笛卡儿积1000*1000=100万 行数据,通过ON条件筛选后的结果集(可能不到1000行)再和第三张表1000行数据做笛卡儿积
2、EXPLAIN
2.1 驱动表

- 指定了连接条件时,满足查询条件的记录行数少的表为驱动表
- 未指定连接条件时,行数少的表为驱动表
2.2 EXPLAIN
EXPLAIN
SELECT *
FROM
(SELECT * from t_rank AS r JOIN csic_delegation_dict AS dele ON r.commonCode_Delegation = dele.DELEGATION_CODE) tmp1
JOIN csic_event AS eve ON tmp1.commonCode_Event = eve.EVENTEXPLAIN
SELECT *
FROM
(SELECT * from t_rank AS r JOIN csic_delegation_dict AS dele ON r.commonCode_Delegation = dele.DELEGATION_CODE) tmp1
JOIN csic_event AS eve ON tmp1.commonCode_Event = eve.EVENT
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-----------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-----------+
| 1 | PRIMARY | eve | ALL | NULL | NULL | NULL | NULL | 441 | |
| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 504 |Using where|
| 2 | DERIVED | dele | ALL | NULL | NULL | NULL | NULL | 41 | |
| 2 | DERIVED | r | ALL | NULL | NULL | NULL | NULL | 539 |Using where|
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-----------++----+-------------+------------+--------+-------------------+---------+---------+------+------+-----------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-----------+
| 1 | PRIMARY | eve | ALL | NULL | NULL | NULL | NULL | 441 | |
| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 504 |Using where|
| 2 | DERIVED | dele | ALL | NULL | NULL | NULL | NULL | 41 | |
| 2 | DERIVED | r | ALL | NULL | NULL | NULL | NULL | 539 |Using where|
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-----------+
2.2.1 id
- id值较大的,执行优先级较高,且从上到下执行,且id值最大的组中,第一行为驱动表,如上图的table dele
- id值相同时,认为是一组,执行顺序从上到下
2.2.2 select_type
| 该字段的值 | 含义 |
| SIMPLE | 简单的SELECT,不适用UNION或子查询等 |
| PRIMARY | 查询中包含任何复杂的子部分,最外层的SELECT标记为PRIMARY |
| UNION | UNION中的第二个或后面的SELECT语句 |
| DEPENDENT UNION | UNION中的第二个或后面的SELECT语句,取决于外面的查询 |
| UNION RESULT | UNION的结果 |
| SUBQUERY | 子查询中的第一个SELECT |
| DEPENDENT SUBQUERY | 子查询中的第一个SELECT,取决于外面的查询 |
| DERIVED | 派生表的SELECT,FROM子句的子查询 |
| UNCACHEABLE SUBQUERY | 一个子查询的结果不能被缓存,必须重新评估外链接的第一行 |
2.2.3 table
- 当数据集市UNION的结果时,其值可能是<UNION M,N>,这里的M或N是id字段的值
- 当数据集来自派生表的SELECT,则显示的是derived*,这里的*是id字段的值,如:
mysql> EXPLAIN SELECT * FROM (SELECT * FROM ( SELECT * FROM t1 WHERE id=2602) a) b;
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
| 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | |
| 2 | DERIVED | <derived3> | system | NULL | NULL | NULL | NULL | 1 | |
| 3 | DERIVED | t1 | const | PRIMARY,idx_t1_id | PRIMARY | 4 | | 1 | |
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+mysql> EXPLAIN SELECT * FROM (SELECT * FROM ( SELECT * FROM t1 WHERE id=2602) a) b;
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
| 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | |
| 2 | DERIVED | <derived3> | system | NULL | NULL | NULL | NULL | 1 | |
| 3 | DERIVED | t1 | const | PRIMARY,idx_t1_id | PRIMARY | 4 | | 1 | |
+----+-------------+------------+--------+-------------------+---------+---------+------+------+-------+
2.2.4 type
| 该字段的值 | 含义 |
| ALL | 遍历全表 |
| index | 与ALL的区别在于只遍历索引树 |
| range | 表示只操作单表,且符合查询条件的记录不止1条 |
| ref | 表明本步执行计划操作的数据集中关联字段是索引字段,但不止1条记录符合上步执行计划操作的数据集的关联条件 |
| eq_ref | 表明本步执行计划操作的数据集中关联字段是索引字段,且只有1条记录符合上步执行计划操作的数据集的关联条件 |
| const | 表明上述"table"字段代表的数据集中,最多只有1行记录命中本步执行计划的查询条件 |
| system | system只是const值的一个特例,它表示本步执行计划要操作的数据集中只有1行记录 |
2.2.5 possible_keys
2.2.6 key
2.2.7 key_len
2.2.8 ref
2.2.9 rows
2.2.10 Extra
| 该字段的值 |
含义 |
| Using index | 表示使用索引,如果只有 Using index,说明他没有查询到数据表,只用索引表就完成了这个查询,这个叫覆盖索引。如果同时出现Using where,代表使用索引来查找读取记录, 也是可以用到索引的,但是需要查询到数据表。 |
| Using where | 表示条件查询,如果不读取表的所有数据,或不是仅仅通过索引就可以获取所有需要的数据,则会出现 Using where。如果type列是ALL或index,而没有出现该信息,则你有可能在执行错误的查询:返回所有数据。 |
| Using filesort | 不是“使用文件索引”的含义!filesort是MySQL所实现的一种排序策略,通常在使用到排序语句ORDER BY的时候,会出现该信息。 |
| Using temporary | 表示为了得到结果,使用了临时表,这通常是出现在多表联合查询,结果排序的场合。 |
3、STRAIGHT_JOIN
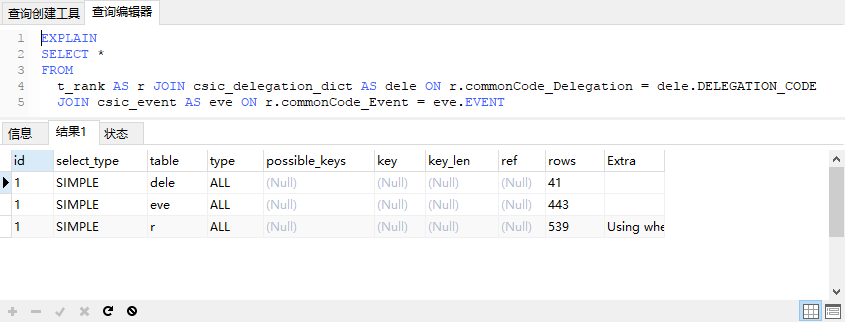
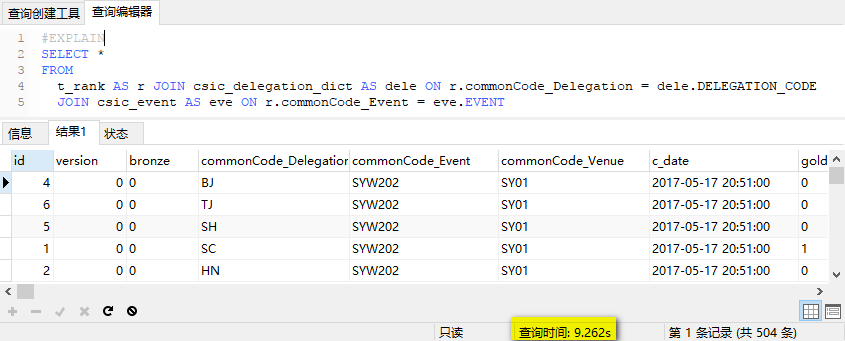

SQL查询时间为0.2s:
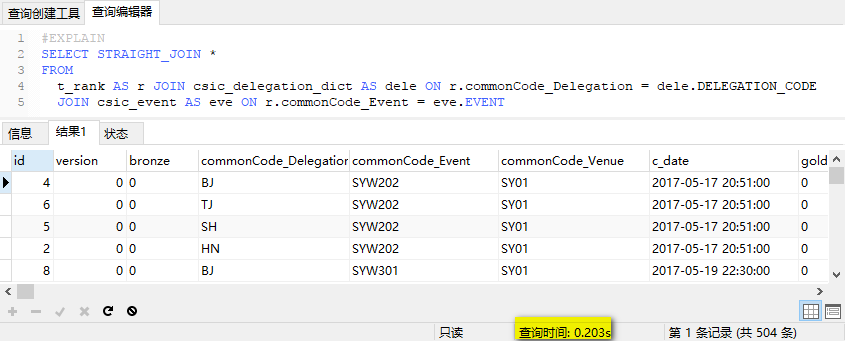
但是仍然需要引起注意的是,这种方式因为执行顺序被固化了,那么随着时间的推移,数据库中的数据分布随着业务开展而发生变化,很可能导致原本运行顺畅的SQL逐渐变得糟糕。
RESET QUERY CACHE;RESET QUERY CACHE;
4、参考链接
附件列表
浅谈SQL优化入门:2、等值连接和EXPLAIN(MySQL)的更多相关文章
- 浅谈SQL优化入门:3、利用索引
0.写在前面的话 关于索引的内容本来是想写的,大概收集了下资料,发现并没有想象中的简单,又不想总结了,纠结了一下,决定就大概写点浅显的,好吧,就是懒,先挖个浅坑,以后再挖深一点.最基本的使用很简单,直 ...
- 浅谈SQL优化入门:1、SQL查询语句的执行顺序
1.SQL查询语句的执行顺序 (7) SELECT (8) DISTINCT <select_list> (1) FROM <left_table> (3) <join_ ...
- 浅谈sql优化
问题的发现: 菜鸟D在工作的时候发现项目的sql语句很怪,例如 : select a.L_ZTBH, a.D_RQ, a.VC_BKDM, (select t.vc_name from tb ...
- c#Winform程序调用app.config文件配置数据库连接字符串 SQL Server文章目录 浅谈SQL Server中统计对于查询的影响 有关索引的DMV SQL Server中的执行引擎入门 【译】表变量和临时表的比较 对于表列数据类型选择的一点思考 SQL Server复制入门(一)----复制简介 操作系统中的进程与线程
c#Winform程序调用app.config文件配置数据库连接字符串 你新建winform项目的时候,会有一个app.config的配置文件,写在里面的<connectionStrings n ...
- 浅谈SQL Server内部运行机制
对于已经很熟悉T-SQL的读者,或者对于较专业的DBA来说,逻辑的增删改查,或者较复杂的SQL语句,都是非常简单的,不存在任何挑战,不值得一提,那么,SQL的哪些方面是他们的挑战 或者软肋呢? 那就是 ...
- 浅谈SQL Server数据内部表现形式
在上篇文章 浅谈SQL Server内部运行机制 中,与大家分享了SQL Server内部运行机制,通过上次的分享,相信大家已经能解决如下几个问题: 1.SQL Server 体系结构由哪几部分组成? ...
- 浅谈SQL Server---2
浅谈SQL Server内部运行机制 https://www.cnblogs.com/wangjiming/p/10098061.html 对于已经很熟悉T-SQL的读者,或者对于较专业的DBA来说, ...
- 浅谈SQL Server---1
浅谈SQL Server优化要点 https://www.cnblogs.com/wangjiming/p/10123887.html 1.SQL Server 体系结构由哪几部分组成? 2.SQL ...
- 浅谈SQL注入风险 - 一个Login拿下Server
前两天,带着学生们学习了简单的ASP.NET MVC,通过ADO.NET方式连接数据库,实现增删改查. 可能有一部分学生提前预习过,在我写登录SQL的时候,他们鄙视我说:“老师你这SQL有注入,随便都 ...
随机推荐
- vue插件编写与实战
关于 微信公众号:前端呼啦圈(Love-FED) 我的博客:劳卜的博客 知乎专栏:前端呼啦圈 前言 热爱vue开发的同学肯定知道awesome-vue 这个github地址,里面包含了数以千计的vue ...
- Mac配置eclipse+pydev+Python遇到的问题
最近在研究Python,作为一名新手在配置环境的时候遇到各种问题:高手可略过~ 1.eclipse官网上下载最新的OS版本,并成功安装eclipse 2.安装JDK,eclipse这些都是要安装JDK ...
- 提高NetBeans的代码提示速度.md
NetBeans配置 如何提高NetBeans的代码提示速度,打开下面的文件然后配置 **C:\Users\ylg\AppData\Roaming\NetBeans\8.2\config\Editor ...
- Android事件传递机制详解及最新源码分析——View篇
摘要: 版权声明:本文出自汪磊的博客,转载请务必注明出处. 对于安卓事件传递机制相信绝大部分开发者都听说过或者了解过,也是面试中最常问的问题之一.但是真正能从源码角度理解具体事件传递流程的相信并不多, ...
- 微信小程序--ajax服务器交互及页面渲染
网上找的帖子大多是直接在onload中请求数据.而我想实现的是点击按钮,然后请求服务器,接着返回数据,前端页面渲染.所以搞了挺久的,在此记录一下. 请求是按照微信官方给出的,wx.request 在这 ...
- 基于 HtmlHelper 的自定义扩展Container
基于 HtmlHelper 的自定义扩展Container Intro 基于 asp.net mvc 的权限控制系统的一部分,适用于对UI层数据呈现的控制,基于 HtmlHelper 的扩展组件 Co ...
- HDU 6185 Covering 矩阵快速幂
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6185 题意:用 1 * 2 的小长方形完全覆盖 4 * n的矩形有多少方案. 解法:小范围是一个经典题 ...
- RPC框架实现思路浅析
第一部分,设计分析 远程调用要解决的主要问题: 1,序列化 : 如何将对象转化为二进制数据进行传输,如何将二进制数据转化对象 2,数据的传输(协议,第三方框架) 3,服务的注册/发现,单点故障,分布式 ...
- 安装python虚拟环境
虚拟环境: 之前安装python包的命令: sudo pip3 install 包名包的安装路径:/usr/local/lib/python3.5/dist-packages安装同一个包的不同版本,后 ...
- 小程序脚本语言WXS详解
WXS脚本语言是 Weixin Script脚本的简称,是JS.JSON.WXML.WXSS之后又一大小程序内部文件类型.截至到目前小程序已经提供了5种文件类型. 解构小程序的几种方式,其中一种方式就 ...