【网络爬虫入门02】HTTP客户端库Requests的基本原理与基础应用
【网络爬虫入门02】HTTP客户端库Requests的基本原理与基础应用
广东职业技术学院 欧浩源
1、引言
实现网络爬虫的第一步就是要建立网络连接并向服务器或网页等网络资源发起请求。urllib是目前最常用的做法,然而Requests会比urlib更加方便,能够让人以更加简单的方式获取网络资源。
2、什么是Requests?
Requests是用Python语言编写,基于urllib,采用Apache2 Licensed开源协议的HTTP库。它比urllib更加方便,可以节约我们大量的工作,完全满足HTTP测试需求。
Requests对象有Get、Post、Put、Delete、Head、Options等HTTP方法,使用起来非常简单。对于WEB系统,一般只支持Get和Post方法。在网络爬虫中,Get方法最常用。在本文中也重点讨论该方法相关的应用,其他方法即更加详细的使用,见用户手册:
http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
3、发起网络请求
使用Requests的Get方法发送网络请求非常简单。
首先,导入Requests模块:
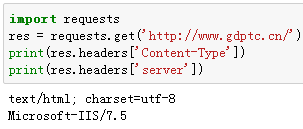
import requests
然后,通过URL向网页发起请求:
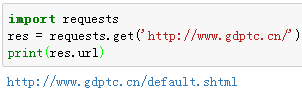
res = requests.get('http://www.gdptc.cn/')
这时,我们有一个名为res的Requests对象,从这个对象中我们可以获取所有我们想要的信息,例如将网页的URL打印出来。
print(res.url)
4、获取响应内容
我们能读取服务器响应的内容。Requests会自动解码来自服务器的内容,大多数unicode字符集都能被无缝地解码。
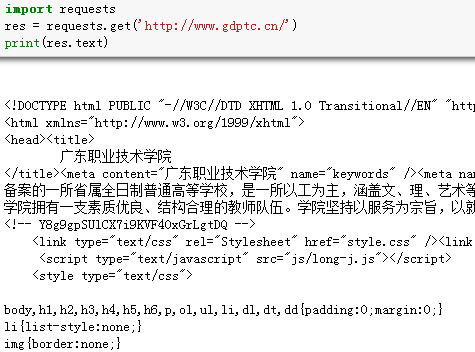
请求发出后,Requests会基于HTTP头部对响应的编码作出有根据的推测。当你访问res.text 之时,Requests会使用其推测的文本编码。你可以找出 Requests使用了什么编码,并且能够使用res.encoding属性来改变它。
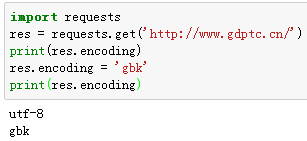
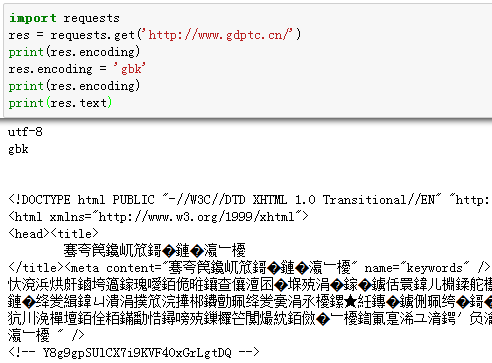
如果你改变了编码,每当你访问 res.text ,Request 都将会使用res.encoding的新值。
5、响应头的内容
服务器响应头以一个Python字典的形式来表示。这个字典比较特殊,它是仅为HTTP头部而生的。
res.headers的结果是:
{
'Content-Length' : '39037'
'X-Powered-By' : 'ASP.NET'
'Date' : 'Sat, 14 Oct 2017 13:58:41 GMT'
'X-AspNet-Version' : '2.0.50727'
'Cache-Control' : 'private'
'Content-Type' : 'text/html; charset=utf-8'
'Server' : 'Microsoft-IIS/7.5'
}
通过这个服务器的响应头,我们可以知道服务器的一些基本数据信息。根据 RFC2616, HTTP头部是大小写不敏感的。因此,我们可以使用任意大写形式来访问这些响应头字段。例如我们想查看服务器的编码和服务器型号:
6、定制请求头
如果你想为请求添加HTTP头部,只要简单地传递一个dict给headers参数就可以了。很多服务器对于非正常的请求往往会拒绝,这时候就需要给网络请求穿上合法的外衣,而伪装请求头部则是最常用的手段。
用户代理User Agent,是HTTP协议中的一部分,属于请求头的组成部分。它是一个特殊字符串头,是一种向访问网站提供你所使用的浏览器类型及版本、操作系统及版本、浏览器内核等信息的标识。通过添加合法浏览器的UA信息,可以将爬虫的请求伪装成浏览器的请求。
例如,IE9浏览器的User Agent为:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;
这些常用的浏览器UA在网上都可以查到。
如果要模拟IE9浏览器访问百度网站,可以这样实现:

Requests不会基于定制 header 的具体情况改变自己的行为。只不过在最后的请求中,所有的header信息都会被传递进去。
7、小结
Requests的用法远不止此,但作为网络爬虫的入门应用,上述知识基本足够。向服务器发送请求的方法也不止一种,怎么熟悉怎么用,怎么方便怎么用,作为入门,多了解,多学习,多练习,多应用才是正道。
【网络爬虫入门02】HTTP客户端库Requests的基本原理与基础应用的更多相关文章
- 【网络爬虫入门01】应用Requests和BeautifulSoup联手打造的第一条网络爬虫
[网络爬虫入门01]应用Requests和BeautifulSoup联手打造的第一条网络爬虫 广东职业技术学院 欧浩源 2017-10-14 1.引言 在数据量爆发式增长的大数据时代,网络与用户的沟 ...
- Python爬虫入门(二)之Requests库
Python爬虫入门(二)之Requests库 我是照着小白教程做的,所以该篇是更小白教程hhhhhhhh 一.Requests库的简介 Requests 唯一的一个非转基因的 Python HTTP ...
- 【网络爬虫入门05】分布式文件存储数据库MongoDB的基本操作与爬虫应用
[网络爬虫入门05]分布式文件存储数据库MongoDB的基本操作与爬虫应用 广东职业技术学院 欧浩源 1.引言 网络爬虫往往需要将大量的数据存储到数据库中,常用的有MySQL.MongoDB和Red ...
- 【网络爬虫入门03】爬虫解析利器beautifulSoup模块的基本应用
[网络爬虫入门03]爬虫解析利器beautifulSoup模块的基本应用 1.引言 网络爬虫最终的目的就是过滤选取网络信息,因此最重要的就是解析器了,其性能的优劣直接决定这网络爬虫的速度和效率.B ...
- Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 转 Python爬虫入门四之Urllib库的高级用法
静觅 » Python爬虫入门四之Urllib库的高级用法 1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我 ...
- 【网络爬虫入门04】彻底掌握BeautifulSoup的CSS选择器
[网络爬虫入门04]彻底掌握BeautifulSoup的CSS选择器 广东职业技术学院 欧浩源 2017-10-21 1.引言 目前,除了官方文档之外,市面上及网络详细介绍BeautifulSoup ...
- python网络爬虫入门范例
python网络爬虫入门范例 Windows用户建议安装anaconda,因为有些套件难以安装. 安装使用pip install * 找出所有含有特定标签的HTML元素 找出含有特定CSS属性的元素 ...
- 转 Python爬虫入门三之Urllib库的基本使用
静觅 » Python爬虫入门三之Urllib库的基本使用 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器 ...
随机推荐
- React——组件
一.创建组件 在React中有两种创建组件的方式,分别是函数形式的组件和类形式的组件 //函数形式: function Welcome(props){ return <p>this is ...
- ★不容错过的PPT教程!
IT工程师必须学会的计算机基础应用之一--PPT! 28项大神级PPT制作技术,学会后让你变成PPT高手哦!更多实用教程,请关注@IT工程师 !
- css3新特性---(border,Background部分)
boder属性新特性: border-radius 设置或检索对象使用圆角边框 border-top-left-radius 设置或检索对象左上角圆角边框 border-top-right-rad ...
- 201521123084 《Java程序设计》第3周学习总结
1. 本周学习总结 初学面向对象,会学习到很多碎片化的概念与知识.尝试学会使用思维导图将这些碎片化的概念.知识组织起来.请使用纸笔或者下面的工具画出本周学习到的知识点.截图或者拍照上传. 本周学习总结 ...
- JAVA基础第二组(5道题)
6.[程序6] 题目:输入两个正整数m和n,求其最大公约数和最小公倍数. 1.程序分析:利用辗除法. package com.niit.homework1; import java.ut ...
- 201521123096《Java程序设计》第四周学习总结
1. 本周学习总结 1.1 尝试使用思维导图总结有关继承的知识点. 1.2 使用常规方法总结其他上课内容. 继承能够动态绑定,运行时能够自动的选择调用方法,十分方便. 2. 书面作业 (1)注释的应用 ...
- 201521123064 《Java程序设计》第1周学习总结
1. 本章学习总结 1.了解Java与C/C++的区别,Java语言所写程序较为繁琐,C/C++较为简洁. 2.学会使用cmd进行程序的编译及运行. 3.学会利用JDK辅助Java编程. 4.使用ec ...
- Day-14: 常用的内建模块
collections包含对tuple.list.dict等派生出新功能 namedtuple用来为tuple类型派生出一个新名字的tuple类,并提供用属性引出的功能. >>> f ...
- csv文件读取
from urllib.request import urlopen from io import StringIO import csv data = urlopen("http://py ...
- JSP获取Cookie对象
cookie是小段的文本信息,在网络服务器上生成,并发送给浏览器的.通过使用cookie可以标识用户身份,记录用户和密码,跟踪重复用户等.浏览器将cookie以key/value的形式保存到客户机的某 ...