数据挖掘入门系列教程(四)之基于scikit-lean实现决策树
数据挖掘入门系列教程(四)之基于scikit-lean决策树处理Iris
在上一篇博客,我们介绍了决策树的一些知识。如果对决策树还不是很了解的话,建议先阅读上一篇博客,在来学习这一篇。
本次实验基于scikit-learn中的Iris数据。说了好久的Iris,从OneR到决策树,那么Iris到底长啥样呢?

加载数据集
首先我们还是需要先加载数据集,数据集来自scikit自带的iris数据集,数据集的内容可以参考以前的博客,这里就不在赘述。
首先让我们从scikit-learn中加载数据集。
from sklearn.datasets import load_iris
dataset = load_iris()
data = dataset.data
target = dataset.target然后我们再使用pandas将数据进行格式化以下,添加Iris的属性到数据集中。
import numpy as np
import pandas as pd
data = pd.DataFrame(data,columns=["sepal_length","sepal_width","petal_length","petal_width"])
data["class"] = targetdata的数据如下所示:
class代表类别。其他的就是Iris的属性了。
数据特征
这里我们主要是用画图来看一看Iris数据集的特征。本来以为画图就matpotlib就行了,但是没想到有seaborn这个好使用的库,来自B站up主的提示。使用的库如下:
- matplotlib
- seaborn
首先我们画散点图:
import matplotlib.pyplot as plt
import seaborn as sb
# data.dropna()去除里面的none元素
sb.pairplot(data.dropna(),hue="class")图像如下所示:
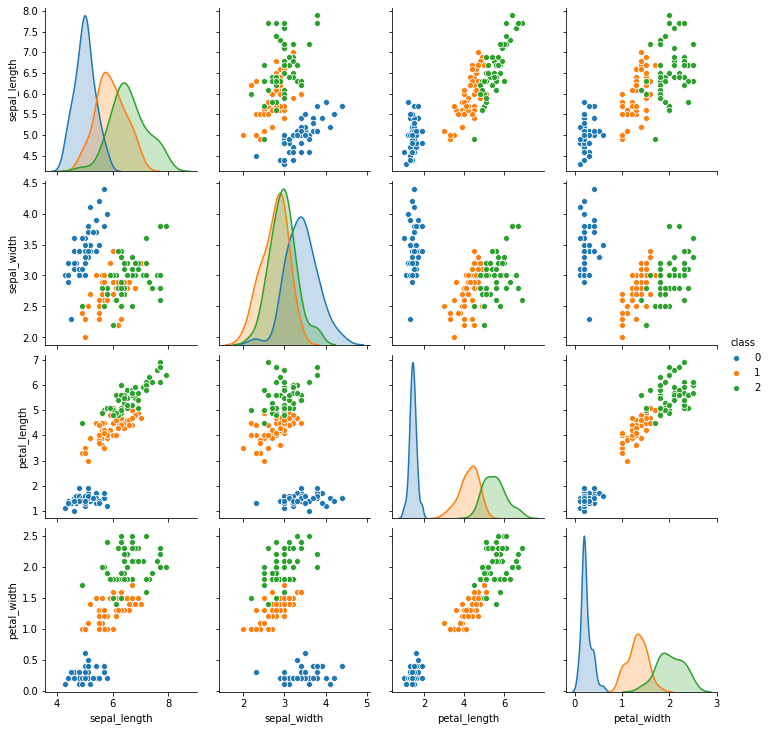
上面的这幅图展示了在四个属性中的类别的分别情况。
同时我们还可以画小提琴图:
plt.figure(figsize=(20, 20))
for column_index, column in enumerate(data.columns):
if column == 'class':
continue
plt.subplot(2, 2, column_index + 1)
sb.violinplot(x='class', y=column, data=data)画出的图如下:

通过上面的这幅图我们可以直观的比较出哪一个变量更具有代表性。比如说petal_width 对类别0更加的友好。
接下来就是进行训练了。
训练
首先的首先,我们还是需要从数据集中抽出训练集和测试集。这个内容在前面讲过了,就不多讲了。
from sklearn.model_selection import train_test_split
input_data = data[["sepal_length","sepal_width","petal_length","petal_width"]]
input_class = data["class"]
train_data,test_data,train_class,test_class = train_test_split(input_data,input_class,random_state = 14)then,让我们来开始进行训练吧,在scikit-learn中实现了决策树,和前面的K近邻算法一样我们直接引用就行,调用fit(训练)和predict(预测)函数。使用如下所示:
from sklearn.tree import DecisionTreeClassifier
decision_tree = DecisionTreeClassifier(random_state=14)
decision_tree.fit(train_data,train_class)
predict_class = decision_tree.predict(test_data)
predict_score = np.mean(predict_class == test_class)
print("预测的准确度为{}".format(predict_score))DecisionTreeClassifier其他的参数在后面说,这里主要说一下random_state参数。为什么决策树还需要random_state这个参数,以下知乎上面的两位博主的说法。


至于哪个说法是正确的,我暂时也不知道,如果有知道的,可以在评论区留言哦!
最后得到的预测结果如下所示:
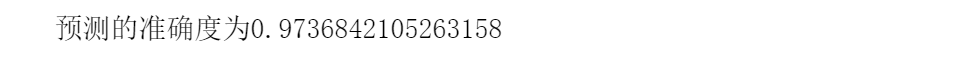
这里值得注意的是DecisionTreeClassifier()函数,里面可以添加很多参数。官方文档在这里: https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html 。
这里还是稍微的说一下参数。
# criterion gini(默认)/tropy:这里对应的就是之前的熵增益和Gini系数
# splitter best(默认)/random 每个结点选择的拆分策略
# max_depth 树的最大深度。
# min_samples_split int类型或者float(默认2) 如果某节点的样本数少于min_samples_split,则不会进行拆分了。浮点值表示分数,代表所占比例
# min_samples_leaf 默认=1 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。
# min_weight_fraction_leaf float(默认0.0) 这个值限制了叶子节点所有样本权重,如果小于这个值,则会和兄弟节点一起被剪枝。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。
# max_features int, float or {“auto”, “sqrt”, “log2”}(默认0.0)
# max_leaf_nodes 通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。如果加了限制,算法会建立在最大叶子节点数内最优的决策树。
# class_weight dict/balanced 指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重。“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。
# min_impurity_split 这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值则该节点不再生成子节点。即为叶子节点 。更多的可以去看官网细节。
然后我们可以将这个树的结构可视化,将文件保存在“tree.dot”中:
from sklearn.tree import export_graphviz
with open("tree.dot",'w') as f:
export_graphviz(decision_tree, feature_names =['sepal_length', 'sepal_width', 'petal_length', 'petal_width'], out_file = f)这个是决策树的图:
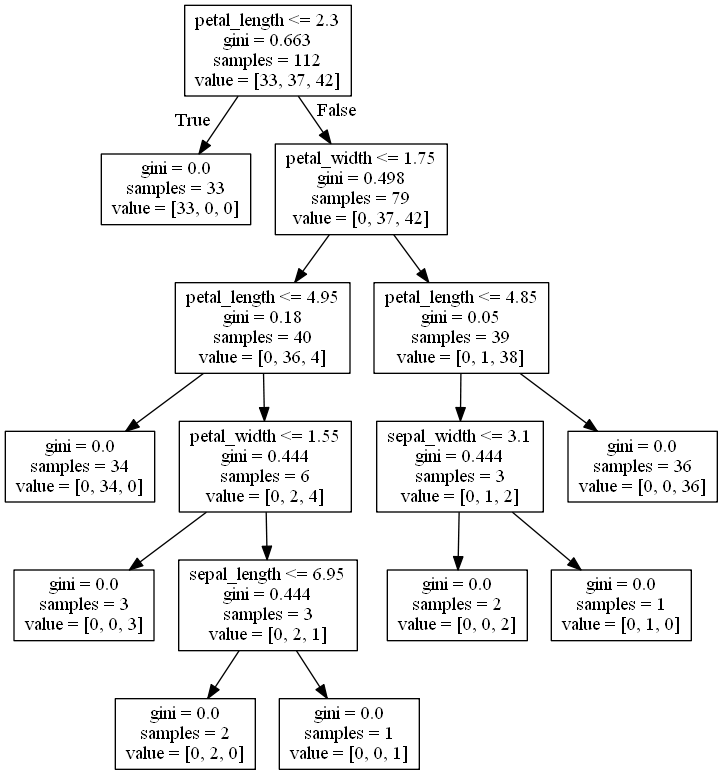
同样,我们还可以使用交叉验证,具体的使用可以参考别人的博客,或者看我的这一篇博客:
from sklearn.model_selection import cross_val_score
decision_tree = DecisionTreeClassifier()
scores = cross_val_score(decision_tree,input_data,input_class,scoring='accuracy')
print("交叉验证结果: {0:.2f}%".format(np.mean(scores) * 100))通过交叉验证得到的准确度如下:

比上面的结果略低,不过这个是正常的。
随机森林
前面的博客介绍了随机树,这里不多做介绍,直接看使用吧。我们通过导入RandomForestClassifier模块,并指令森林中树的个数为30,具体的参数看官网
from sklearn.ensemble import RandomForestClassifier
rft = RandomForestClassifier(n_estimators=20,random_state=14)
rft.fit(train_data,train_class)
predict_class = rft.predict(test_data)
predict_score = np.mean(predict_class == test_class)
print("随机森林预测的准确度为{}".format(predict_score))最后的结果如下图
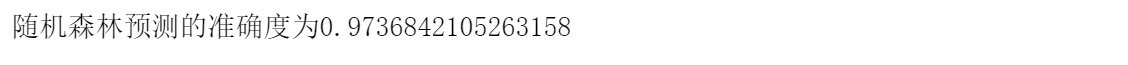
然后进行交叉验证:
scores = cross_val_score(rft,input_data,input_class,scoring='accuracy')
print("Accuracy: {0:.2f}%".format(np.mean(scores) * 100))结果如下:

emm,好像和上面的结果一样,因为这个数据集很小,可能会有这种情况。
调参工程师
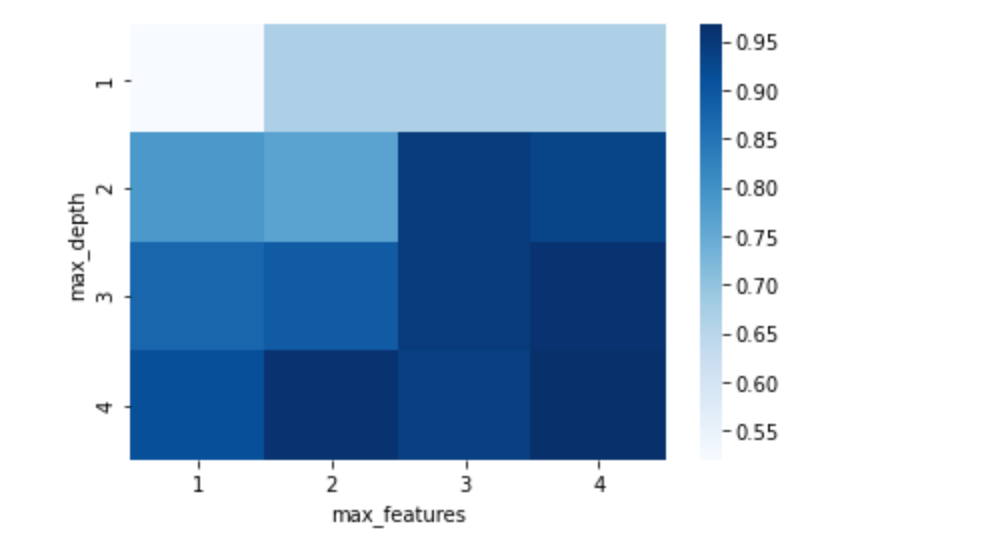
首先,我们可以对决策树的max_feature和max_depth进行调参,改变其值,最终的结果如下:
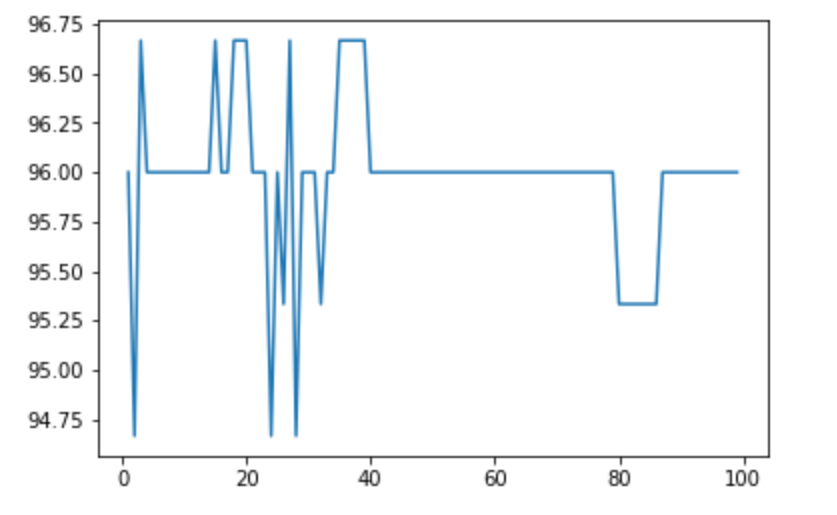
在随机森林中,我们可以对树的个数进行调参,结果如下图:
结尾
这次并没有使用《 Python数据挖掘入门与实践 》书上的例子,实在是它打篮球的数据找不到,emm。相比较与oneR算法的70%左右的正确率,决策树95%正确率已经算足够优秀了。
尽管代码写起来很简单,也很容易实现得到结果,但是我们真正应该了解的是里面的内涵:决策树是什么?里面是怎样工作的?以及所蕴含的含义……
项目地址:GitHub
数据挖掘入门系列教程(四)之基于scikit-lean实现决策树的更多相关文章
- 数据挖掘入门系列教程(九)之基于sklearn的SVM使用
目录 介绍 基于SVM对MINIST数据集进行分类 使用SVM SVM分析垃圾邮件 加载数据集 分词 构建词云 构建数据集 进行训练 交叉验证 炼丹术 总结 参考 介绍 在上一篇博客:数据挖掘入门系列 ...
- 数据挖掘入门系列教程(八)之使用神经网络(基于pybrain)识别数字手写集MNIST
目录 数据挖掘入门系列教程(八)之使用神经网络(基于pybrain)识别数字手写集MNIST 下载数据集 加载数据集 构建神经网络 反向传播(BP)算法 进行预测 F1验证 总结 参考 数据挖掘入门系 ...
- 数据挖掘入门系列教程(二)之分类问题OneR算法
数据挖掘入门系列教程(二)之分类问题OneR算法 数据挖掘入门系列博客:https://www.cnblogs.com/xiaohuiduan/category/1661541.html 项目地址:G ...
- 数据挖掘入门系列教程(十点五)之DNN介绍及公式推导
深度神经网络(DNN,Deep Neural Networks)简介 首先让我们先回想起在之前博客(数据挖掘入门系列教程(七点五)之神经网络介绍)中介绍的神经网络:为了解决M-P模型中无法处理XOR等 ...
- 数据挖掘入门系列教程(三)之scikit-learn框架基本使用(以K近邻算法为例)
数据挖掘入门系列教程(三)之scikit-learn框架基本使用(以K近邻算法为例) 简介 scikit-learn 估计器 加载数据集 进行fit训练 设置参数 预处理 流水线 结尾 数据挖掘入门系 ...
- 数据挖掘入门系列教程(四点五)之Apriori算法
目录 数据挖掘入门系列教程(四点五)之Apriori算法 频繁(项集)数据的评判标准 Apriori 算法流程 结尾 数据挖掘入门系列教程(四点五)之Apriori算法 Apriori(先验)算法关联 ...
- 数据挖掘入门系列教程(五)之Apriori算法Python实现
数据挖掘入门系列教程(五)之Apriori算法Python实现 加载数据集 获得训练集 频繁项的生成 生成规则 获得support 获得confidence 获得Lift 进行验证 总结 参考 数据挖 ...
- 数据挖掘入门系列教程(十一)之keras入门使用以及构建DNN网络识别MNIST
简介 在上一篇博客:数据挖掘入门系列教程(十点五)之DNN介绍及公式推导中,详细的介绍了DNN,并对其进行了公式推导.本来这篇博客是准备直接介绍CNN的,但是想了一下,觉得还是使用keras构建一个D ...
- 数据挖掘入门系列教程(十二)之使用keras构建CNN网络识别CIFAR10
简介 在上一篇博客:数据挖掘入门系列教程(十一点五)之CNN网络介绍中,介绍了CNN的工作原理和工作流程,在这一篇博客,将具体的使用代码来说明如何使用keras构建一个CNN网络来对CIFAR-10数 ...
随机推荐
- 74)PHP,Session的一些属性
(1) (2)有效期在 会话周期结束(就是将浏览器关闭前) (3)有效路径: 整站都有效 (4)有效域:当前域 (5)是否安全传输:否 (6)以上的session数据的特征都是由一个问题导致的,就 ...
- 浙江省第十六届大学生ACM程序设计竞赛部分题解
E .Sequence in the Pocket sol:将数组copy一份,然后sort一下,找寻后面最多多少个元素在原数组中保持有序,用总个数减去已经有序的就是我们需要移动的次数. 思维题 #i ...
- Angular开发者指南(四)控制器
了解控制器controller 在AngularJS中,Controller由JavaScript构造函数定义,用于扩充AngularJS Scope. 当控制器通过ng-controller指令连接 ...
- Javascript 表达式中连续的 && 和 || 之赋值区别
为了区分赋值表达式中出现的连续的 ‘&&’和 ‘||’的不同的赋值含义,做了一个小测试,代码如下: function write(msg){ for(var i = 0; i ...
- centos7 上安装jira调试系统
安装mysql数据库 在windows上面下载 http://dev.mysql.com/downloads/mysql/ 在liunx系统上可直接wget, wget https://dev.mys ...
- js类型比较
比较数据类型做比较的三种方法typeofinstanceofObject.prototype.toString.call() javascript七大类型 javascript的数据类型分为两类:原始 ...
- 转:ZABBIX监控H3C设备的CPU和内存使用率
由于最近监控的H3C路由器经常出现死机现象,SNMP获取不到数据,后面检查发现是CPU使用率过高,直接导致无法处理SNMP请求,所以需求来了,怎样通过SNMP监控H3C路由器的CPU和内存使用率? ...
- virtualenv 个人指南
virtualenv是解决一个机器上多个应用需要的Python版本不一致的问题,virtualenv就是用来为一个应用创建一套"隔离"的Python运行环境,解决了解决了不同应用间 ...
- js里的null 与undefined
null 表示一个值被定义了,定义为'空值': undefined 表示没有定义. 转换为数字时 Number(undefined) === NaN Number(null) === 0 在es6使用 ...
- Redis 安装及入门
Redis简介 Redis是一个开源的使用ANSI C语言编写.支持网络.可基于内存亦可持久化的日志型.Key-Value数据库,并提供多种语言的API. Docker方式安装Redis # 拉取 r ...