文本情感分析(二):基于word2vec、glove和fasttext词向量的文本表示
上一篇博客用词袋模型,包括词频矩阵、Tf-Idf矩阵、LSA和n-gram构造文本特征,做了Kaggle上的电影评论情感分类题。
这篇博客还是关于文本特征工程的,用词嵌入的方法来构造文本特征,也就是用word2vec、glove和fasttext词向量进行文本表示,训练随机森林分类器。
一、训练word2vec和fasttext词向量
Kaggle情感分析题给出了三个数据集,一个是带标签的训练集,共25000条评论,一个是测试集,无标签的,用来做预测并提交结果,这两个数据集是上一篇文章里我们用过的。
此外还有一个无标签的数据集,有50000条评论,不用太可惜了。我们可以想到,用无标签的数据可以训练word2vec词向量,进行词嵌入。与词袋模型相比,word2vec词向量能解决文本表示维度过高的问题,并且把单词之间的位置信息考虑进去了。或许,用word2vec词向量进行文本表示,能取得更好的预测结果。
另外,我们也可以训练fasttext词向量。fasttext这个模型就是为了文本分类而造出来的,词向量是其副产品,它的结构和word2vec的CBOW模型的结构类似,但是输入是整篇文本而不是上下文信息,而且用字符级别的n-gram来得到单词的词向量表示,捕捉有相同后缀的词的语义关联。
gensim中集成了训练word2vec词向量和fasttext词向量的包,用法非常类似。不过貌似gensim中的fasttext包只能用来训练词向量,不能用来做fasttext文本分类。
首先导入所需要的库。
import os,re
import numpy as np
import pandas as pd from bs4 import BeautifulSoup
from gensim import models
接着读取有标签的训练数据和无标签的数据,把影评合并到一个列表中。
"""读取数据,包括有标签的和无标签的数据""" # 定义读取数据的函数
def load_dataset(name, nrows=None):
datasets = {
'unlabeled_train': 'unlabeledTrainData.tsv',
'labeled_train': 'labeledTrainData.tsv',
'test': 'testData.tsv'
}
if name not in datasets:
raise ValueError(name)
data_file = os.path.join('..', 'data', datasets[name])
df = pd.read_csv(data_file, sep='\t', escapechar='\\', nrows=nrows)
print('Number of reviews: {}'.format(len(df)))
return df # 读取有标签和无标签的数据
df_labeled = load_dataset('labeled_train')
df_unlabeled = load_dataset('unlabeled_train') sentences = [] for s in df_labeled['review']:
sentences.append(s) for s in df_unlabeled['review']:
sentences.append(s) print("一共加载了",len(sentences),"条评论。")
Number of reviews: 25000
Number of reviews: 50000
一共加载了 75000 条评论。
接着进行数据预处理,处理成gensim所需要的格式。这里非常关键,我还摸索了一阵,才知道什么输入格式是正确的。
其实输入格式是这样的,假设有两篇文本,那么处理成 [ ['with', 'all', 'this', 'stuff', 'going',...], ['movie', 'but', 'mj', 'and', 'most',...]]的格式,每篇文本是一个列表,列表元素为单个单词。这个很容易做到,因为英文不需要进行分词,用text.split()按照空格进行切分就行。
由于word2vec依赖于上下文,而上下文有可能就是停词,所以这里选择不去停用词。
"""数据预处理,去html标签、去非字母的字符"""
eng_stopwords = {}.fromkeys([ line.rstrip() for line in open('../stopwords.txt')])
# 可以选择是否去停用词,由于word2vec依赖于上下文,而上下文有可能就是停词。
# 因此对于word2vec,我们可以不用去停词。
def clean_text(text, remove_stopwords=False):
text = BeautifulSoup(text,'html.parser').get_text()
text = re.sub(r'[^a-zA-Z]', ' ', text)
words = text.lower().split()
if remove_stopwords:
words = [w for w in words if w not in eng_stopwords]
return words
sentences = [clean_text(s) for s in sentences]
# 这里可以说是最关键的,gensim需要的格式就是把每条评论弄成['with', 'all', 'this', 'stuff', 'going',...]的格式。
# 再次强调,这里最关键,格式不对则没法学习。
现在就可以输入进去训练词向量了。训练好之后,有两种保持模型的方式,一种是把训练的模型本身保存下来,是一个二进制格式的文件,打开以后看不到单词和词向量,但是以后可以继续用更多的数据进行训练,第二种是把单词和对应的词向量以txt的格式保存,不能再追加训练,但是打开后可以看到单词和词向量。下面的代码以这两种方式分别保存了模型。
"""打印日志信息""" import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO) """"设定词向量训练的参数,开始训练词向量""" num_features = 300 # 词向量取300维
min_word_count = 40 # 词频小于40个单词就去掉
num_workers = 4 # 并行运行的线程数
context = 10 # 上下文滑动窗口的大小
model_ = 0 # 使用CBOW模型进行训练 model_name = '{}features_{}minwords_{}context.model'.format(num_features, min_word_count, context) print('Training model...')
model = models.Word2Vec(sentences, workers=num_workers, \
size=num_features, min_count = min_word_count, \
window = context, sg=model_) # 保存模型
# 第一种方法保存的文件不能利用文本编辑器查看,但是保存了训练的全部信息,可以在读取后追加训练
# 后一种方法保存为word2vec文本格式,但是保存时丢失了词汇树等部分信息,不能追加训练 model.save(os.path.join('..', 'models', model_name)) model.wv.save_word2vec_format(os.path.join('..','models','word2vec_txt.txt'),binary = False)
加载保存好的模型,并取出词向量。
# 加载模型,根据保持时的格式不同,有两种加载方式
model = models.Word2Vec.load(os.path.join('..', 'models', model_name))
model_txt = models.KeyedVectors.load_word2vec_format(os.path.join('..','models','word2vec_txt.txt'),binary = False)
# 可以同时取出一个句子中单词的词向量
model.wv[['man','woman','guy']]
检验一下模型训练的效果,查看和 man 这个单词最相关的词,可以看到,结果还不错。
model.wv.most_similar("man")
[('woman', 0.6039960384368896),
('lady', 0.5690498948097229),
('lad', 0.5434065461158752),
('guy', 0.4913134276866913),
('person', 0.4771265387535095),
('monk', 0.47647857666015625),
('widow', 0.47423964738845825),
('millionaire', 0.4719209671020508),
('soldier', 0.4717007279396057),
('men', 0.46545034646987915)]
接着训练fasttext词向量,输入数据的格式要求和word2vec一样,所以我们直接用上面的数据开始训练。
要吐槽一下,尽管据说fasttext做文本分类贼快,可是训练词向量的过程非常慢,感觉比word2vec慢多了,内存也时不时显示99%,吓死人。
model_name_2 = 'fasttext.model'
print('Training model...')
model_2 = models.FastText(sentences, size=num_features, window=context, min_count=min_word_count,\
sg = model_, min_n = 2 , max_n = 3)
# 保存模型
# 第一种方法保存的文件不能利用文本编辑器查看,但是保存了训练的全部信息,可以在读取后追加训练
# 后一种方法保存为word2vec文本格式,但是保存时丢失了词汇树等部分信息,不能追加训练
model_2.save(os.path.join('..', 'models', model_name_2))
model_2.wv.save_word2vec_format(os.path.join('..','models','fasttext.txt'),binary = False)
查看和man这个单词最相关的词,还是非常慢。从结果来看,和word2vec大有不同,找出来的词后缀都是man。
model_2.wv.most_similar("man")
[('woman', 0.6353151798248291),
('boman', 0.6015676856040955),
('wolfman', 0.5951900482177734),
('wyman', 0.5888750553131104),
('snowman', 0.5807067155838013),
('madman', 0.5781949162483215),
('gunman', 0.5617127418518066),
('henchman', 0.5536723136901855),
('guffman', 0.5454517006874084),
('kidman', 0.5268094539642334)]
二、用word2vec、glove和fasttext词向量进行文本表示
好,下面分别用word2vec、glove和fasttext词向量做电影评论的文本表示,再次训练随机森林分类器,看哪种词向量的效果更好。
重开了一个jupyter notebook。首先导入所需要的库。
import os
import re
import numpy as np
import pandas as pd from bs4 import BeautifulSoup from nltk.corpus import stopwords from gensim import models from sklearn.ensemble import RandomForestClassifier from sklearn import metrics
读取训练集数据。
"""读取训练集数据""" def load_dataset(name, nrows=None):
datasets = {
'unlabeled_train': 'unlabeledTrainData.tsv',
'labeled_train': 'labeledTrainData.tsv',
'test': 'testData.tsv'
}
if name not in datasets:
raise ValueError(name)
data_file = os.path.join('..', 'data', datasets[name])
df = pd.read_csv(data_file, sep='\t', escapechar='\\', nrows=nrows)
print('Number of reviews: {}'.format(len(df)))
return df df = load_dataset('labeled_train')
读取训练好的word2vec词向量,和预训练的glove词向量(需要先下载glove词向量),备用。怕内存受不了,先不加载fasttext词向量。
"""读取训练好的word2vec模型""" model_name_w2v = '300features_40minwords_10context.model'
word2vec_embedding = models.Word2Vec.load(os.path.join('..', 'models', model_name_w2v)) """读取glove词向量""" glove_embedding = {}
f = open('../glove.6B/glove.6B.300d.txt', encoding='utf-8')
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
glove_embedding[word] = coefs
f.close()
将训练集中的每条电影评论用向量表示,首先要得到每条评论中每个单词的词向量,然后把所有单词的词向量做平均,当作是句子或文本的向量表示。
于是得到电影评论的word2vec表示和golve表示。
"""数据预处理,得到单词的词向量,并得到句子的向量"""
#编码方式有一点粗暴,简单说来就是把这句话中的词的词向量做平均
eng_stopwords = set(stopwords.words('english'))
# 清洗文本数据
def clean_text(text, remove_stopwords=False):
text = BeautifulSoup(text, 'html.parser').get_text()
text = re.sub(r'[^a-zA-Z]', ' ', text)
words = text.lower().split()
if remove_stopwords:
words = [w for w in words if w not in eng_stopwords]
return words
# 取word2vec词向量,或者glove词向量
def to_review_vector(review,model='word2vec'):
words = clean_text(review, remove_stopwords=True)
if model == 'word2vec':
array = np.asarray([word2vec_embedding[w] for w in words if w in word2vec_embedding],dtype='float32')
elif model == 'glove':
array = np.asarray([glove_embedding[w] for w in words if w in glove_embedding],dtype='float32')
elif model == 'fasttext':
array = np.asarray([fasttext_embedding[w] for w in words if w in fasttext_embedding],dtype='float32')
else:
raise ValueError('请输入:word2vec、glove或fasttext')
return array.mean(axis=0)
"""word2vec表示的样本"""
train_data_word2vec = [to_review_vector(text,'word2vec') for text in df['review']]
"""用glove表示的样本"""
train_data_glove = [to_review_vector(text,'glove') for text in df['review']]
用word2vec表示的样本训练随机森林模型,并用包外估计作为泛化误差的评估指标。
从结果可以看到,包外估计为0.83568,之前用词频矩阵训练的模型包外估计为0.84232,所以比之前用词袋模型训练的效果差一点。
def model_eval(train_data):
print("1、混淆矩阵为:\n")
print(metrics.confusion_matrix(df.sentiment, forest.predict(train_data)))
print("\n2、准确率、召回率和F1值为:\n")
print(metrics.classification_report(df.sentiment,forest.predict(train_data)))
print("\n3、包外估计为:\n")
print(forest.oob_score_)
print("\n4、AUC Score为:\n")
y_predprob = forest.predict_proba(train_data)[:,1]
print(metrics.roc_auc_score(df.sentiment, y_predprob))
"""用word2vec词向量表示训练模型和评估模型"""
forest = RandomForestClassifier(oob_score=True,n_estimators = 200, random_state=42)
forest = forest.fit(train_data_word2vec, df.sentiment)
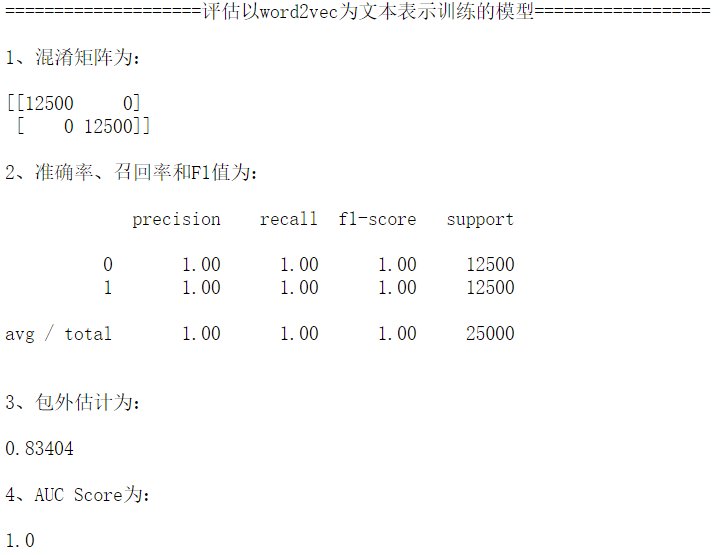
print("\n====================评估以word2vec为文本表示训练的模型==================\n")
model_eval(train_data_word2vec)
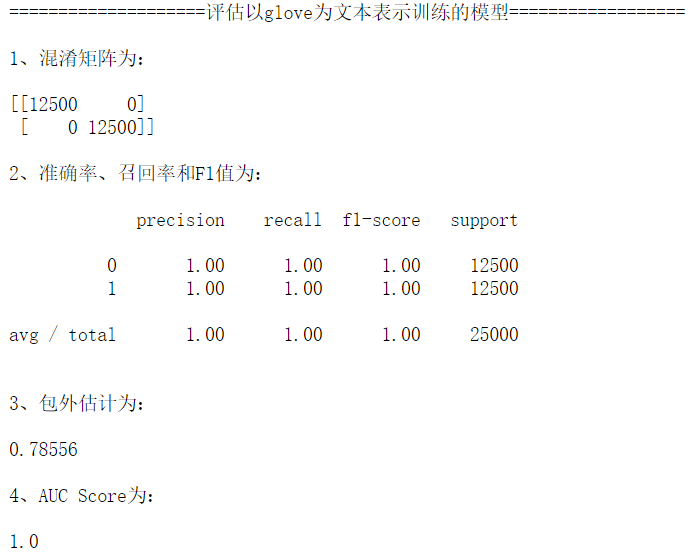
再用glove词向量表示的训练集进行模型训练。很不幸,包外估计为0.78556,泛化性能比较差。
"""用glove词向量表示训练模型和评估模型""" forest = RandomForestClassifier(oob_score=True,n_estimators = 200, random_state=42)
forest = forest.fit(train_data_glove, df.sentiment)
print("\n====================评估以glove为文本表示训练的模型==================\n")
model_eval(train_data_glove)
最后用fasttext词向量表示的样本训练分类器。包外估计为0.81112,比word2vec效果差不少。
del word2vec_embedding
del glove_embedding
del train_data_word2vec
del train_data_glove
del forest """读取训练好的fasttext模型""" model_name_fast = 'fasttext.model'
fasttext_embedding = models.FastText.load(os.path.join('..', 'models', model_name_fast)) """fasttext表示的样本"""
train_data_fasttext = [to_review_vector(text,'fasttext') for text in df['review']] """用fasttext词向量表示训练模型和评估模型""" forest = RandomForestClassifier(oob_score=True,n_estimators = 200, random_state=42)
forest = forest.fit(train_data_fasttext, df.sentiment)
print("\n====================评估以fasttext为文本表示训练的模型==================\n")
model_eval(train_data_fasttext)

三、后记
之前就用gensim训练过中文词向量,一段时间不用,连输入格式都忘记了,这次正好巩固一下。
从上面的结果可以看到,至少在这个任务中,word2vec的表现比glove、fasttext要优秀。
文本情感分析(二):基于word2vec、glove和fasttext词向量的文本表示的更多相关文章
- Keras下的文本情感分析简介。与MLP,RNN,LSTM模型下的文本情感测试
# coding: utf-8 # In[1]: import urllib.request import os import tarfile # In[2]: url="http://ai ...
- 基于 Spark 的文本情感分析
转载自:https://www.ibm.com/developerworks/cn/cognitive/library/cc-1606-spark-seniment-analysis/index.ht ...
- LSTM实现中文文本情感分析
1. 背景介绍 文本情感分析是在文本分析领域的典型任务,实用价值很高.本模型是第一个上手实现的深度学习模型,目的是对深度学习做一个初步的了解,并入门深度学习在文本分析领域的应用.在进行模型的上手实现之 ...
- LSTM 文本情感分析/序列分类 Keras
LSTM 文本情感分析/序列分类 Keras 请参考 http://spaces.ac.cn/archives/3414/ neg.xls是这样的 pos.xls是这样的neg=pd.read_e ...
- TensorFlow实现文本情感分析详解
http://c.biancheng.net/view/1938.html 前面我们介绍了如何将卷积网络应用于图像.本节将把相似的想法应用于文本. 文本和图像有什么共同之处?乍一看很少.但是,如果将句 ...
- TensorFlow文本情感分析实现
TensorFlow文本情感分析实现 前面介绍了如何将卷积网络应用于图像.本文将把相似的想法应用于文本. 文本和图像有什么共同之处?乍一看很少.但是,如果将句子或文档表示为矩阵,则该矩阵与其中每个单元 ...
- NLP入门(十)使用LSTM进行文本情感分析
情感分析简介 文本情感分析(Sentiment Analysis)是自然语言处理(NLP)方法中常见的应用,也是一个有趣的基本任务,尤其是以提炼文本情绪内容为目的的分类.它是对带有情感色彩的主观性 ...
- 无所不能的Embedding 2. FastText词向量&文本分类
Fasttext是FaceBook开源的文本分类和词向量训练库.最初看其他教程看的我十分迷惑,咋的一会ngram是字符一会ngram又变成了单词,最后发现其实是两个模型,一个是文本分类模型[Ref2] ...
- 文本情感分析(一):基于词袋模型(VSM、LSA、n-gram)的文本表示
现在自然语言处理用深度学习做的比较多,我还没试过用传统的监督学习方法做分类器,比如SVM.Xgboost.随机森林,来训练模型.因此,用Kaggle上经典的电影评论情感分析题,来学习如何用传统机器学习 ...
随机推荐
- centos 下安装nginx
安装make: yum -y install gcc automake autoconf libtool make 安装g++: yum install gcc gcc-c++ cd /usr/loc ...
- 剑指offer第二版速查表
3.数组中重复数字:每个位置放置数字与下标对应相等 O(n) 4.二维数组中的查找:右下角开始比较 O(m+n) 5.替换空格:python直接替换 6.从尾到头打印链表: 借助栈或直接利用系统调用栈 ...
- AttributeError: 'Word2Vec' object has no attribute 'vocab'
在 Gensim 1.0.0 版本后移除了 vocab,需使用 model.wv.vocab
- windows系统下hosts文件的改写(为了测试nginx内网的证书代理,需要做域名解析)
1. win加R C:\WINDOWS\system32\drivers\etc 2.打开hosts文件 加入一行 IP为客户机要访问的IP地址 域名也是在nginx中定义好的 3.ct ...
- 1009 Product of Polynomials (25分) 多项式乘法
1009 Product of Polynomials (25分) This time, you are supposed to find A×B where A and B are two po ...
- LeetCode 21. Merge Two Sorted Lists(合并两个有序链表)
题意:合并两个有序链表 /** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next ...
- python随机函数.2020.2.26
随机生成函数: import random //首先要引用random模板 print(random.randint(0,9)) //random的语法 random.randint(0,9 ...
- Spring Mvc中Jsp也页面怎么会获取不到Controller中的数据
----------Controller ------- package com.test.mvc; import org.springframework.stereotype.Controller; ...
- Centos7 nginx配置多虚拟主机过程
一.前提准备 1.已经安装好了的Centos7服务器 2.ip 为192.168.1.209 [本次的配置ip] 3.确定防火墙等已经关闭 二.nignx配置文件参数详解 要配置多台虚拟主机,就需 ...
- [Write-up]BSides-Vancouver
关于 下载链接 目标:拿到root用户目录下的flag.txt 全程无图! 信息收集 因为虚拟机网络是设置Host-only,所以是vmnet1这张网卡,IP段为192.168.7.1/24 nmap ...