mysql-kettle-superset电商可视化数据分析
1、项目概述
需求
对电商业务中的用户、商品、订单的数据进行分析,观察运营的情况
架构
业务数据库:Mysql:存储最原始的数据
ETL:Kettle
数据仓库:Mysql:存储需要进行分析处理的数据
分析处理:SQL/Kettle
可视化:Superset
2、准备工作
系统
linux系统
软件
VMware虚拟机——安装linux操作系统
1 Windows版下载地址:
2 https://www.vmware.com/
finalshell——远程操作系统
Windows版下载地址:
http://www.hostbuf.com/downloads/finalshell_install.exe
Mac版,Linux版安装及教程:
http://www.hostbuf.com/t/1059.html
mysql——数据库(安装版和压缩包版)
1 Windows版下载地址:
2 https://www.mysql.com//downloads/
datagrip——数据库管理工具
链接:https://pan.baidu.com/s/1K1pPIX9uZiAKOAiFgHMlnw
提取码:lhr4
Navicat——数据库管理工具
链接:https://pan.baidu.com/s/1eaW3CMhen_7X5sjVgs7enw
提取码:fqov
kettle——如有安装问题请自行度娘
1、Kettle的下载与安装(本文使用kettle版本为pdi-ce-7.1.0.0-12)点击下载地址官方网站
可视化工具
superset——有问题请度娘
linux环境安装依赖
yum upgrade python-setuptools
yum install -y gcc gcc-c++ libffi-devel python-devel python-pip python-wheel openssl-devel libsasl2-devel openldap-devel
安装superset
supersetcd /root/anaconda3/
pip install email_validator -i https://pypi.douban.com/simple
pip install superset==0.30.0 -i https://pypi.douban.com/simple
3、数据环境
1、导入业务数据
将这段sql代码下载运行,生成数据库,表格
链接:https://pan.baidu.com/s/1uVYISah6hYkBqiyhIk407w
提取码:sfdm
2、构建数据仓库
通过kettle将业务数据抽取到数据分析的数据库中
链接:https://pan.baidu.com/s/1shH0zexh3WraQnMt17n-SA
提取码:ao7n
生成表格——kettle操作略
mysql> use itcast_shop_bi; Database changed
mysql> show tables;
+--------------------------+
| Tables_in_itcast_shop_bi |
+--------------------------+
| ods_itcast_good_cats |商品分类表
| ods_itcast_goods |商品表
| ods_itcast_order_goods |订单及详情表
| ods_itcast_orders |订单表
| ods_itcast_users |用户表
| ods_itcast_area |行政区域表
+--------------------------+
3、自动化构建抽取实现
1、地区表以及商品分类表的自动抽取
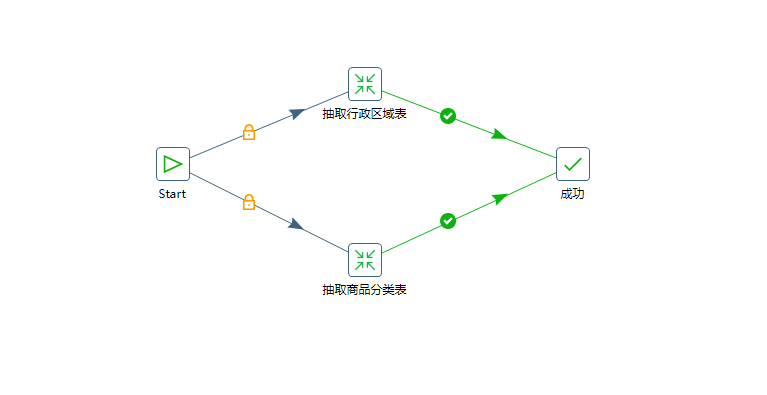
2、商品表、订单表、订单详情表、用户表

3、设置定时自动运行

4、数据分析
需求1
需求:统计 2019-09-05 订单支付的总金额、订单的总笔数
演变:统计每天的订单支付的总金额和订单的总笔数
指标:总金额、订单总笔数
维度:天
-- 创建结果表
use itcast_shop_bi;
create table app_order_total(
id int primary key auto_increment,
dt date,
total_money double,
total_cnt int
);
-- 将分析的结果保存到结果表
insert into app_order_total
select
null,
substring(createTime,1,10) as dt,-- 2019-09-05这一天的日期
round(sum(realTotalMoney),2) as total_money, -- 分组后这一天的所有订单总金额
count(orderId) as total_cnt -- 分组后这一天的订单总个数
from
ods_itcast_orders
where
substring(createTime,1,10) = '2019-09-05'
group by
substring(createTime,1,10);
-- 表结构及内容
mysql> desc app_order_user;
+----------------+------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------------+------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| dt | date | YES | | NULL | |
| total_user_cnt | int | YES | | NULL | |
+----------------+------+------+-----+---------+----------------+
3 rows in set (0.00 sec) mysql> select * from app_order_user;
+----+------------+----------------+
| id | dt | total_user_cnt |
+----+------------+----------------+
| 1 | 2019-09-05 | 11 |
| 2 | 2019-09-05 | 11 |
+----+------------+----------------+
2 rows in set (0.01 sec)
需求2
需求:统计2019-09-05当天所有下单的用户总数
演变:统计订单表中2019-09-05这一天的所有订单的用户id的个数
-- 创建结果表
use itcast_shop_bi;
create table app_order_user(
id int primary key auto_increment,
dt date,
total_user_cnt int
);
-- 插入结果数据
insert into app_order_user
select
null,
substring(createTime,1,10) as dt,-- 2019-09-05这一天的日期
count(distinct userId) as total_user_cnt
from
ods_itcast_orders
where
substring(createTime,1,10) = '2019-09-05'
group by
substring(createTime,1,10);
需求3
需求;每天不同支付方式订单总额/订单笔数分析
指标:订单总额、订单总笔数
维度:时间维度【天】、支付方式维度
-- 创建结果表
create table app_order_paytype(
id int primary key auto_increment,
dt date,
pay_type varchar(20),
total_money double,
total_cnt int
);
-- 插入结果数据
insert into app_order_paytype
select
null,
substring(createTime,1,10) as dt,-- 获取每一天的日期
case payType when 1 then '支付宝' when 2 then '微信' when 3 then '现金' else '其他' end as pay_type,
round(sum(realTotalMoney),2) as total_money, -- 分组后这一天的所有订单总金额
count(orderId) as total_cnt -- 分组后这一天的订单总个数
from
ods_itcast_orders
group by
substring(createTime,1,10),payType;
需求4
需求;统计2019年9月下订单最多的用户TOP5,也就是前5名
方式一:上面考虑的是简单的情况,只获取订单个数最多的前5个人
select
date_format(dt,'%Y-%m') as dt,
userId,
userName,
count(orderId) as total_cnt
from
ods_itcast_orders
where
date_format(dt,'%Y-%m') = '2019-09'
group by
date_format(dt,'%Y-%m'),userId,userName
order by
total_cnt desc
limit 5;
方式二:我们希望得到订单个数最多的排名的前5名,如果个数相同排名相同
select
*
from (
select *,
dense_rank() over (partition by dt order by total_cnt desc) as rn
from (
select date_format(dt, '%Y-%m') as dt,
userId,
userName,
count(orderId) as total_cnt
from ods_itcast_orders
where date_format(dt, '%Y-%m') = '2019-09'
group by date_format(dt, '%Y-%m'), userId, userName
) tmp1
) tmp2 where rn < 6;
需求5
需求:统计不同分类的订单总金额以及订单总笔数【类似于统计不同支付类型的订单总金额和总笔数】
-- 创建结果表
use itcast_shop_bi;
drop table if exists app_order_goods_cat;
create table app_order_goods_cat(
id int primary key auto_increment,
dt date,
cat_name varchar(20),
total_money double,
total_num int
);
-- step2:先构建三级分类与一级分类之间的关系
-- 使用join实现
drop table if exists tmp_goods_cats;
create temporary table tmp_goods_cats as
select
t3.catId as t3Id,-- 三级分类id
t3.catName as t3Name, -- 三级分类名称
t2.catId as t2Id,
t2.catName as t2Name,
t1.catId as t1Id,
t1.catName as t1Name
from
ods_itcast_good_cats t3 join ods_itcast_good_cats t2 on t3.parentId = t2.catId
join ods_itcast_good_cats t1 on t2.parentId = t1.catId; CREATE UNIQUE INDEX idx_goods_cat3 ON tmp_goods_cats(t3Id);
CREATE UNIQUE INDEX idx_itheima_goods ON ods_itcast_goods(goodsId);
CREATE INDEX idx_itheima__order_goods ON ods_itcast_order_goods(goodsId);
-- 插入结果数据
insert into app_order_goods_cat
select
null,
substring(c.createtime,1,10) as dt,
a.t1Name,
sum(c.payPrice) as total_money,
count(distinct orderId) as total_num
from
tmp_goods_cats a left join ods_itcast_goods b on a.t3Id = b.goodsCatId
left join ods_itcast_order_goods c on b.goodsId = c.goodsId
where
substring(c.createtime,1,10) = '2019-09-05'
group by
substring(c.createtime,1,10),a.t1Name;
5、构建自动化Kettle作业实现自动化分析
创建一个作业
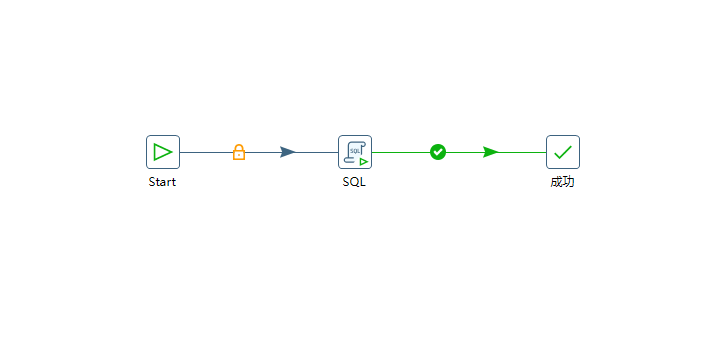
配置SQL脚本
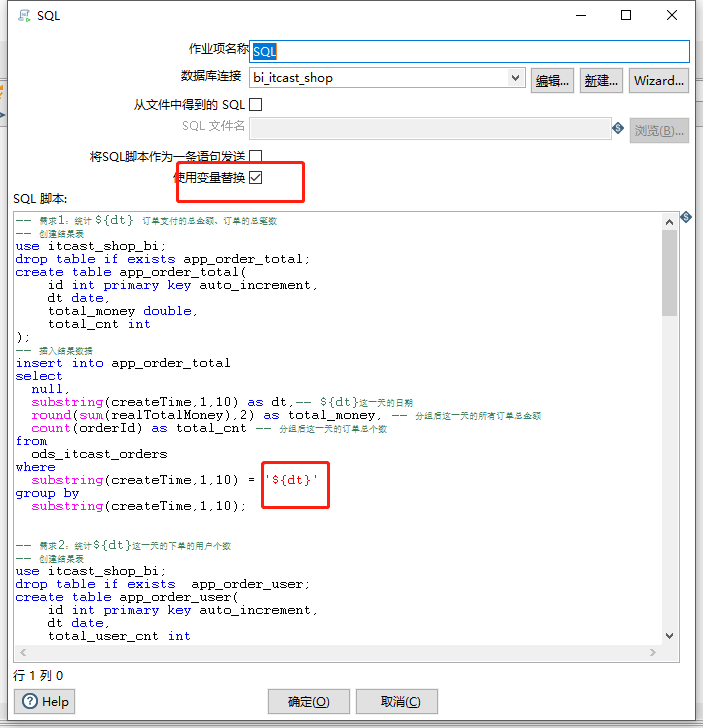
定义作业的变量

6、可视化构建
订单销售总额
订单总笔数
订单总用户数
不同支付方式的总订单金额比例
不同支付方式的订单个数
不同商品分类的订单总金额
不同商品分类的订单总个数
词云图
7、构建看板

mysql-kettle-superset电商可视化数据分析的更多相关文章
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
- [原创]如何利用BI搭建电商数据分析平台
某电商是某大型服装集团下的重要销售平台.2015 年,该集团品牌价值达数百亿元,产品质量.市场占有率.出口创汇.销售收入连年居全国绒纺行业第一,在中国有终端店3000多家,零售额80 亿.其羊绒制品年 ...
- 如何利用BI搭建电商数据分析平台
某电商是某大型服装集团下的重要销售平台.2015 年,该集团品牌价值达数百亿元,产品质量.市场占有率.出口创汇.销售收入连年居全国绒纺行业第一,在中国有终端店3000多家,零售额80 亿.其羊绒制品年 ...
- Amazon电商数据分析——数据获取
最近一段时间主要重心在Amazon电商数据分析上,这是一个偏数据分析和可视化的项目.具体来说就是先获取Amazon的商品数据,数据清洗和持久化存储后作为我们自己的数据源.分析模块和可视化模块基于数据进 ...
- 电商打折套路分析 —— Python数据分析练习
电商打折套路分析 ——2016天猫双十一美妆数据分析 数据简介 此次分析的数据来自于城市数据团对2016年双11天猫数据的采集和整理,原始数据为.xlsx格式 包括update_time/id/tit ...
- EF+MySQL乐观锁控制电商并发下单扣减库存,在高并发下的问题
下订单减库存的方式 现在,连农村的大姐都会用手机上淘宝购物了,相信电商对大家已经非常熟悉了,如果熟悉电商开发的同学,就知道在买家下单购买商品的时候,是需要扣减库存的,当然有2种扣减库存的方式, 一种是 ...
- 电商网站垮IDC数据备份,MySql主从同步,图片及其它数据文件的同步
原文网址:http://www.bzfshop.net/article/180.html 对一个电子商务网站而言,最宝贵的资源就是数据.服务器是很廉价的东西,即使烧了好几个也问题不大,但是用户数据如果 ...
- 电商中的库存管理实现-mysql与redis
库存是电商系统的核心环节,如何做到不少卖,不超卖是库存关心的核心业务问题.业务量大时带来的问题是如何更快速的处理库存计算. 此处以最简模式来讨论库存设计. 以下内容只做分析,不能直接套用,欢迎 ...
- 常见电商项目的数据库表设计(MySQL版)
转自:https://cloud.tencent.com/developer/article/1164332 简介: 目的: 电商常用功能模块的数据库设计 常见问题的数据库解决方案 环境: MySQL ...
随机推荐
- 尝试用python开发一款图片压缩工具1:尝试 pillow库
开发目的 我经常使用图片.公众号文章发文也好,还是生活中要使用素材.图片是一种比文字更加直观的载体.但是图片更加占用带宽,很多软件都对图片有大小限制.图片太大也会影响加载速度.我试过几款图片压缩工具, ...
- 使用RNN对文本进行分类实践电影评论
本教程在IMDB大型影评数据集 上训练一个循环神经网络进行情感分类. from __future__ import absolute_import, division, print_function, ...
- qa问答机器人pysparnn问题的召回
""" 构造召回的模型 """ from sklearn.feature_extraction.text import TfidfVecto ...
- Python3 注释和运算符
Python3 注释 确保对模块, 函数, 方法和行内注释使用正确的风格 Python中的注释有单行注释和多行注释: Python中单行注释以 # 开头,例如:: # 这是一个注释 print(&qu ...
- linux awk 命令实用手册
0,简介 Linux awk 是一个实用的文本处理工具,它不仅是一款工具软件,也是一门编程语言.awk 的名称来源于其三位作者的姓氏缩写,其作者分别是Alfred Aho,Peter Weinberg ...
- HDU 2513 Cake slicing
#include<bits/stdc++.h> using namespace std; int n,m,k; int cherry[405],dp[405][405]; int solv ...
- java 之 javaBean
什么是JavaBean? JavaBean是特殊的Java类,使用J ava语言书写,并且遵守JavaBean API规范. JavaBean与其它Java类相比而言独一无二的特征: 提供一个默认的无 ...
- python 列表加法"+"和"extend"的区别
相同点 : "+"和"extend"都能将两个列表成员拼接到到一起 不同点 : + : 生成的是一个新列表(id改变) extend : 是将一个列表的成员 ...
- db2 锁表
2019独角兽企业重金招聘Python工程师标准>>> 查询锁表情况 db2 => get snapshot for locks on databasename 可以看到什么表 ...
- Oliver Twist
对于济贫院那些绅士们而言,贫民好吃懒做.贪得无厌.他们消耗的食物即是对教区最大的威胁. 绅士们的利益得不到满足时,孤儿们只能被驱之而后快,甚至被"加价出售". 然而,眼泪这种东西根 ...