吴裕雄--天生自然python机器学习:KNN-近邻算法在手写识别系统上的应用
需要识别的数字已经使用图形处理软件,处理成具有相同的色
彩和大小® : 宽髙是32像 素 *32像素的黑白图像。尽管采用文本格式存储图像不能有效地利用内
存空间,但是为了方便理解,我们还是将图像转换为文本格式。


准备数据:将图像转换为测试向量
每个数字大约有200个样本;目录中包含了大约900个测试
数据。我们使用目录比testDigits的数据训练分类器,使用目录把testDigits的数据测试分类器
的效果。两组数据没有覆盖,你可以检查一下这些文件夹的文件是否符合要求。

我们将把一个32*32的二进制图像矩阵转换为1 * 1024的向量

def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
returnVect = img2vector("F:\\machinelearninginaction\\Ch02\\trainingDigits\\3_48.txt")
print(returnVect)
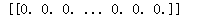
测 试 算 法 : 使 用 尽 近 邻 算 法 识 别 手 写 数 字
import numpy as np def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('F:\\machinelearninginaction\\Ch02\\trainingDigits') #load the training set
m = len(trainingFileList)
trainingMat = np.zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('F:\\machinelearninginaction\\Ch02\\trainingDigits\\%s' % fileNameStr)
testFileList = listdir('F:\\machinelearninginaction\\Ch02\\testDigits') #iterate through the test set
mTest = len(testFileList)
errorCount = 0.0
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('F:\\machinelearninginaction\\Ch02\\testDigits\\%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr))
if (classifierResult != classNumStr):
errorCount += 1.0
print("\nthe total number of errors is: %d" % errorCount)
print("\nthe total error rate is: %f" % (errorCount/float(mTest))) handwritingClassTest()
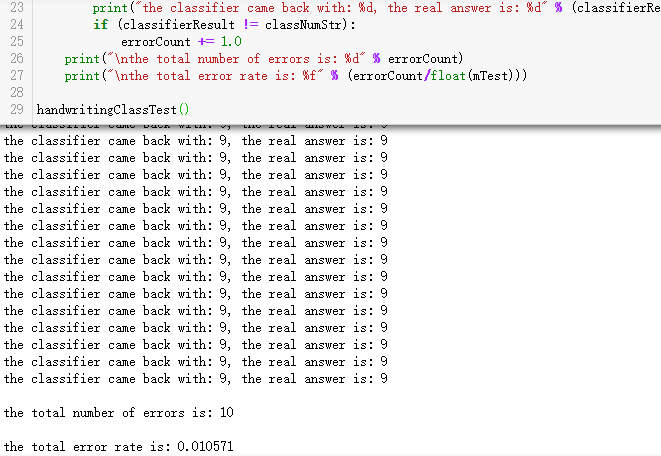
错误率大约是1.6左右,可以说是很不错的准确率了。
小结:
K-近邻算法是基于实例的学习,使用算法时我们必须有接近实际数据的训练样本数
据。A-近邻算法必须保存全部数据集,如果训练数据集的很大,必须使用大量的存储空间。此外,
由于必须对数据集中的每个数据计算距离值,实际使用时可能非常耗时。
K近邻算法的另一个缺陷是它无法给出任何数据的基础结构信息,因此我们也无法知晓平均
实例样本和典型实例样本具有什么特征。
吴裕雄--天生自然python机器学习:KNN-近邻算法在手写识别系统上的应用的更多相关文章
- 吴裕雄--天生自然python机器学习实战:K-NN算法约会网站好友喜好预测以及手写数字预测分类实验
实验设备与软件环境 硬件环境:内存ddr3 4G及以上的x86架构主机一部 系统环境:windows 软件环境:Anaconda2(64位),python3.5,jupyter 内核版本:window ...
- 吴裕雄--天生自然python机器学习:K-近邻算法介绍
k-近邻算法概述 简单地说,谷近邻算法采用测量不同特征值之间的距离方法进行分类. 优 点 :精度高.对异常值不敏感.无数据输入假定. 缺点:计算复杂度高.空间复杂度高. 适用数据范围:数值型和标称型. ...
- 吴裕雄--天生自然python机器学习:朴素贝叶斯算法
分类器有时会产生错误结果,这时可以要求分类器给出一个最优的类别猜测结果,同 时给出这个猜测的概率估计值. 概率论是许多机器学习算法的基础 在计算 特征值取某个值的概率时涉及了一些概率知识,在那里我们先 ...
- 吴裕雄--天生自然python机器学习:决策树算法
我们经常使用决策树处理分类问题’近来的调查表明决策树也是最经常使用的数据挖掘算法. 它之所以如此流行,一个很重要的原因就是使用者基本上不用了解机器学习算法,也不用深究它 是如何工作的. K-近邻算法可 ...
- 吴裕雄--天生自然python机器学习:支持向量机SVM
基于最大间隔分隔数据 import matplotlib import matplotlib.pyplot as plt from numpy import * xcord0 = [] ycord0 ...
- 吴裕雄--天生自然python机器学习:使用K-近邻算法改进约会网站的配对效果
在约会网站使用K-近邻算法 准备数据:从文本文件中解析数据 海伦收集约会数据巳经有了一段时间,她把这些数据存放在文本文件(1如1^及抓 比加 中,每 个样本数据占据一行,总共有1000行.海伦的样本主 ...
- 吴裕雄--天生自然python机器学习:机器学习简介
除却一些无关紧要的情况,人们很难直接从原始数据本身获得所需信息.例如 ,对于垃圾邮 件的检测,侦测一个单词是否存在并没有太大的作用,然而当某几个特定单词同时出现时,再辅 以考察邮件长度及其他因素,人们 ...
- 吴裕雄--天生自然python机器学习:基于支持向量机SVM的手写数字识别
from numpy import * def img2vector(filename): returnVect = zeros((1,1024)) fr = open(filename) for i ...
- 吴裕雄--天生自然python机器学习:使用Logistic回归从疝气病症预测病马的死亡率
,除了部分指标主观和难以测量外,该数据还存在一个问题,数据集中有 30%的值是缺失的.下面将首先介绍如何处理数据集中的数据缺失问题,然 后 再 利 用 Logistic回 归 和随机梯度上升算法来预测 ...
随机推荐
- webview HttpClient 怎么保持会话session统一
cookies session均为key---value的形式展示, 1. session是存储在服务端,并有一块区域控件存储用户信息,主要是为了判断该用户是否登录,在客户端采用httpC ...
- UVM实战[二]
本期将讲解UVM环境构成和启动方式.主要参考资料为 http://bbs.eetop.cn/thread-320165-1-1.html http://rockeric.com/ 环境构成 进行仿真验 ...
- Thread.sleep 与Thread.currentThread.sleep 相同
package com.citi.tm.api.trade.mongo; public class ThreadTest { public static void main(String[] args ...
- SQL基础教程(第2版)第4章 数据更新:4-4 事务
●事务是需要在同一个处理单元中执行的一系列更新处理的集合. ● 事务处理的终止指令包括COMMIT(提交处理)和ROLLBACK(取消处理)两种. ● DBMS的事务具有原子性(Atomicity). ...
- vue项目 首页开发 part3
da当拖动图标时候,只有上部分可以,下部分无响应 swiper 为根页面引用,其中的css为独立,点击swiper标签可以看见其包裹区域只有部分 那么需要修改 就需要穿透样式 外部 >> ...
- Mybatis实现if trim(四)
1. 准备 请先完成Mybatis实现增删改查(二)和Mybatis实现条件查询(三)的基本内容 2. 关于多条件查询的疑问 在Mybatis实现条件查询(三)中我们实现了多条件(商品编码.商品名称. ...
- 量化交易alpha、beta、shape等基本概念梳理
1.期货型基金(CTA)的 Alpha 和 Beta 是指什么? https://zhuanlan.zhihu.com/p/20700337 1980S ...
- mysql字符集配置&mysql中文乱码
问题描述 这两天重置了下自己的电脑系统,一个ubuntu,另外一个当然就是windows. 不过在运行程序的时候发现,出现了很多的"????",也就是乱码字符.毫无疑问,这定然是m ...
- 美团:WSDM Cup 2019自然语言推理任务获奖解题思路
WSDM(Web Search and Data Mining,读音为Wisdom)是业界公认的高质量学术会议,注重前沿技术在工业界的落地应用,与SIGIR一起被称为信息检索领域的Top2. 刚刚在墨 ...
- Ubuntu的奇技淫巧
sudo apt-get install cmatrix 输入密码,安装后,按F11把terminal全屏,输入cmatrix -b sudo apt-get install sl 安装后执行sl,屏 ...