从入门到精通(分布式文件系统架构)-FastDFS,FastDFS-Nginx整合,合并存储,存储缩略图,图片压缩,Java客户端
导读
篇幅较长,干货满满,需花费较长时间,转载请注明出处!
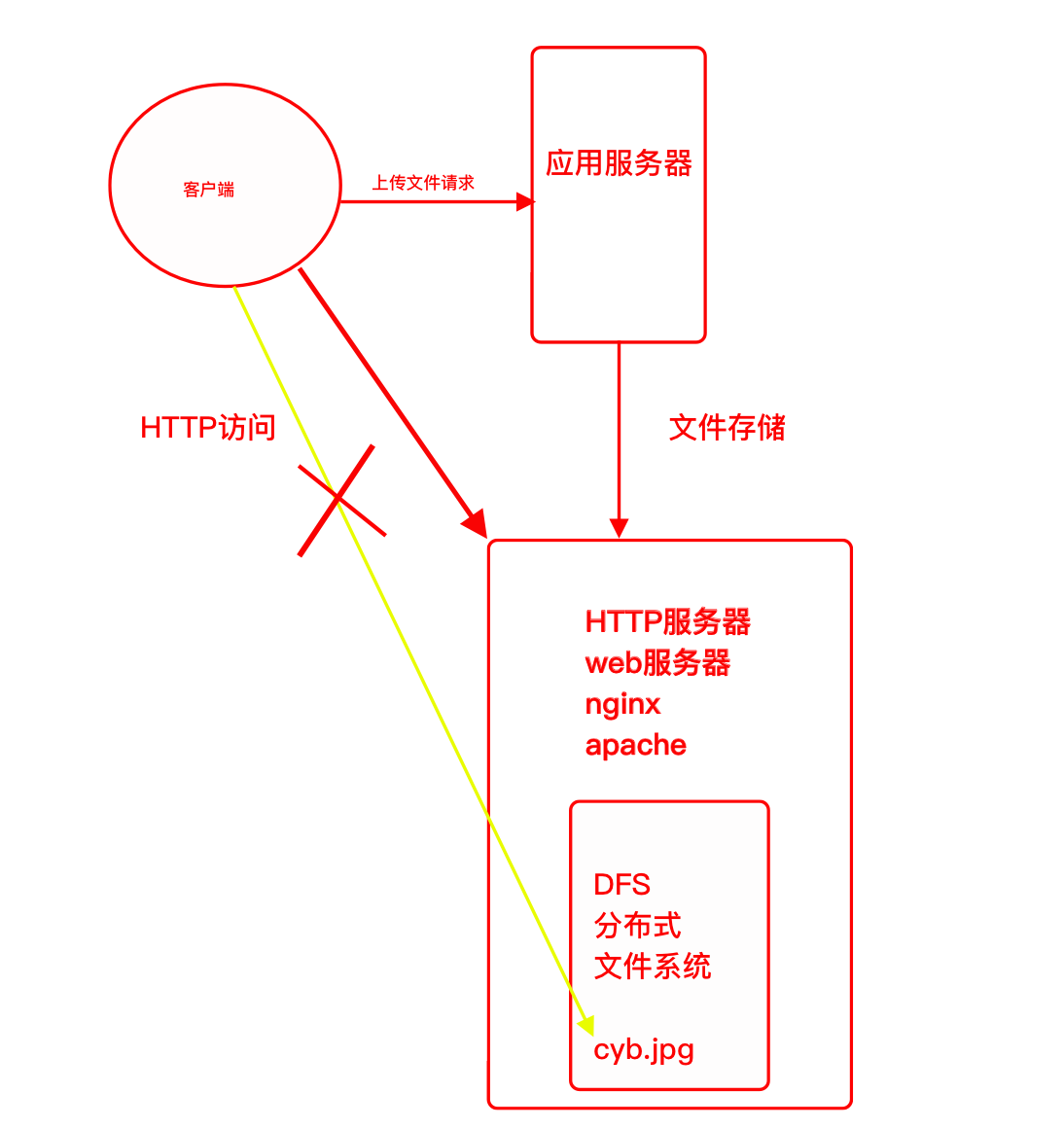
互联网环境中的文件如何存储?
- 不能存本地应用服务器
- NFS(采用mount挂载)
- HDFS(适合大文件)
- FastDFS(强力推荐)
- 云存储(有免费和收费的,不推荐,使用前可以看该公司实力怎么样,别文件都存上去了,过2年公司破产了,损失惨重呀,呜呜呜~~~)
互联网环境中的文件如何进行HTTP访问?
Web服务器:Nginx(本案例使用Nginx,还不会用Nginx的小伙伴,请看我另一篇博客:点我直达)、Apache等等。
FastDFS介绍
FastDFS是什么?
- FastDFS是一个C编写的开源的高性能分布式文件系统(Distributed File System,简称DFS)
- 它由淘宝开发平台部资深架构师余庆开发,论坛:http://bbs.chinaunix.net/forum-240-1.html
- 它对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题
- 特别适合以文件为载体的在线服务,如相册网站、视频网站、电商等等。特别适合以中小文件(建议范围:4KB<file_size<500mb)为载体的在线服务
- FastDFS为互联网量身定制,充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重高可用、高性能等指标,使用FastDFS很容易搭建一套高性能的文件服务器集群提供文件上传、下载等服务
- github:https://github.com/happyfish100/fastdfs
技术文档
链接: https://pan.baidu.com/s/1BpPwJBg2mR8CvqOiKj2rDQ 密码: ocj5
流程图
实际比这复杂的多
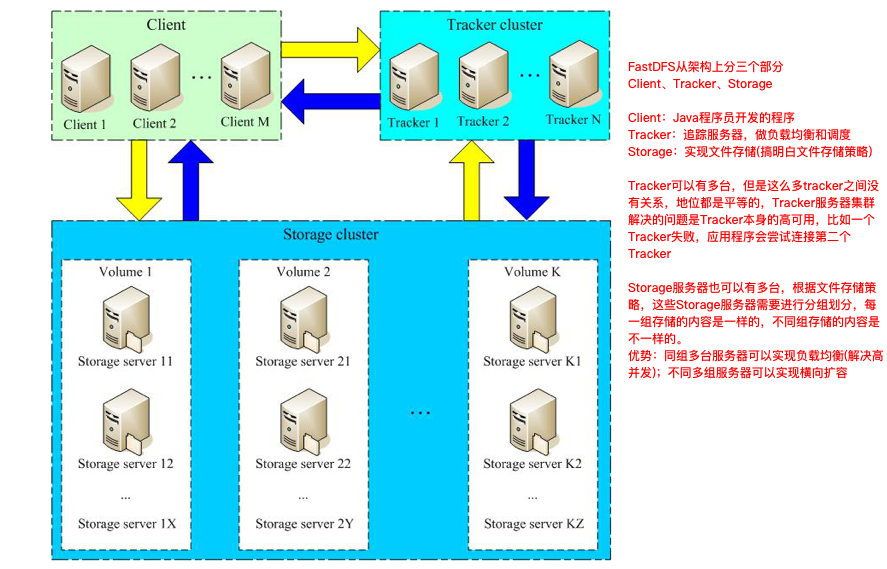
FastDFS架构原理分析(重点)
架构分析
FastDFS系统有三个角色:跟踪服务器(Tracker Server)、存储服务器(Storage Server)和客户端(Client)。
Tracker Server:跟踪服务器
- 主要做调度工作,并对Storage Server起到负载均衡的作用
- 负责管理所有的Storage Server和group,每个storage在启动后连接Tracker,告知自己所属group等信息,并保存周期性心跳。
- Tracker Server可以有多台,Tracker Server之间是相互平等关系同时提供服务,Tracker Server不存在单点故障。客户端请求Tracker Server采用轮询方式,如果请求的Tracker无法提供服务则换另一个Tracker。
Storage Server:存储服务器
- 主要提供容量和备份服务
- 以group为单位,不同group之间互相独立,每个group内可以有多台storage server,数据互为备份。
- 采用分组存储方式的好处是灵活,可控性强,比如上传文件时,可以由客户端直接指定上传到的组也可以由Tracker进行调度选择。
- 一个分组的存储服务器的访问压力较大时,可以在该组增加存储服务器来扩充服务能力(纵向扩容)。当系统容量不足时,可以增加组来扩充存储容量(横向扩容)。
Client:客户端
- 上传下载数据的服务器,也就是我们自己的项目所部署在的服务器
存储策略
为了支持大容量,存储节点(服务器)采用分卷(或分组)的组织方式。存储系统由一个或多个卷组成,卷与卷之间的文件是相互独立的,所有卷的文件容量累加就是整个存储系统中的文件容量。一个卷可以由一台或多台存储服务器组成,一个卷下的存储服务器中的文件都是相同的,卷中的多台存储服务器起到了冗余备份和负载均衡的作用。
在卷中增加服务器时,同步已有的文件由系统自动完成,同步完成后,系统自动将新增服务器切换到线上提供服务。当存储空间不足或即将耗尽时,可以动态加载卷,只需要增加一台或多台服务器,并将它们配置为一个新的卷,这样就扩大了存储系统的容量。
Storage状态收集
Storage Server会通过配置连接集群中所有的Tracker Server,定时向他们报告自己的状态,包括磁盘剩余空间、文件上传下载次数等统计信息。
Storage Server有7个状态,如下
- FDFS_STORAGE_STATUS_INIT ->初始化,尚未得到同步已有数据的源服务器
- FDFS_STORAGE_STATUS_WAIT_SYNC ->等待同步,已得到同步已有数据的源服务器
- FDFS_STORAGE_STATUS_SYNCING ->同步中
- FDFS_STORAGE_STATUS_DELETED ->已删除,该服务器从本组中摘除
- FDFS_STORAGE_STATUS_OFFLINE ->离线
- FDFS_STORAGE_STATUS_ONLINE ->在线,尚不能提供服务
- FDFS_STORAGE_STATUS_ACTIVE ->在线,可以提供服务
文件上传流程分析
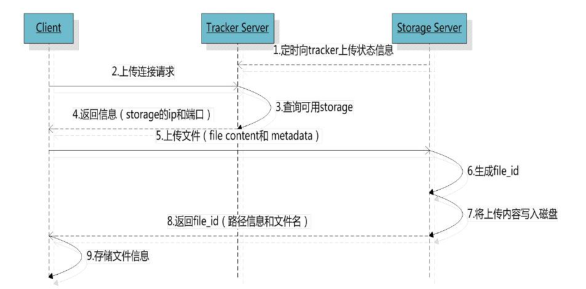
流程说明
1、Tracker Server收集Storage Server的状态信息
1.1、Storage Server定时向已知的tracker server(可以是多个)发送磁盘剩余空间、文件同步状态、文件上传下载次数等统计信息
1.2、Storage Server会连接整个集群中所有的Tracker Server,向它们报告自己的状态
2、选择Tracker server
2.1、当集群中不止一个Tracker Server时,由于Tracker之间是完全对等的关系,客户端在upload文件时可以任意选择一个Tracker
3、选择存储的group
当Tracker接收到upload file的请求时,会为该文件分配一个可存储该文件的group,支持如下规则
3.1、Round robin,所有的group间轮询(默认)
3.2、Specified group,指定某一个确定的group
3.3、Load balance,剩余存储空间多的,group优先
4、选择Storage Server
当选定group后,Tracker会在group内选择一个Storage Server给客户端,支持如下选择Storage的规则
4.1、Round robin,在group内的所有Storage间轮询(默认)
4.2、First server ordered by ip,按ip排序
4.3、First server ordered by priority,按优先级排序(优先级在Storage上配置)
5、选择Storage path
当分配好Storage server后,客户端将向Storage发送写文件请求,Storage将会为文件分配一个数据存储目录,支持如下规则(在Storage配置文件中可以通过store_path*参数来设置,该参数可以设置多个,通过*来区别)
5.1、Round robin,多个存储目录间轮询
5.2、剩余存储空间最多的优先
6、生成fileid
选定存储目录之后,Storage会为文件生一个fileid,由源Storage server ip、文件创建时间、文件大小、文件crc32和一个随机数拼接而成,然后将这个二进制串进行base64编码,转换为可打印的字符串。
7、选择两级目录
当选定存储目录之后,Storage会为文件分配一个fileid,每个存储目录下有两级256*256的子目录,Storage会按文件fileid进行两次hash,路由到其中一个子目录,然后将文件以fileid为文件名存储到该子目录下。
8、生成文件名
当文件存储到某个子目录后,既认为该文件存储成功,接下来会为该文件生成一个文件名,文件名由group、存储目录、两级子目录、fileid、文件后缀名(由客户端指定,主要用于区分文件类型)拼接而成。
文件同步分析
写文件时,客户端将文件写至group内一个Storage Server既认为写文件成功,Storage Server写完文件后,会由后台线程将文件同步至group内其他的Storage Server。
同步规则总结如下
- 只在本组内的Storage Server之间进行同步
- 源头数据才需要同步,备份数据不需要再次同步,否则就构成闭环了
- 上述第二条规则有个例外,就是新增一台Storage Server时,由已有的一台Storage Server将已有的所有数据(包括源头数据和备份数据)同步给该新增服务器
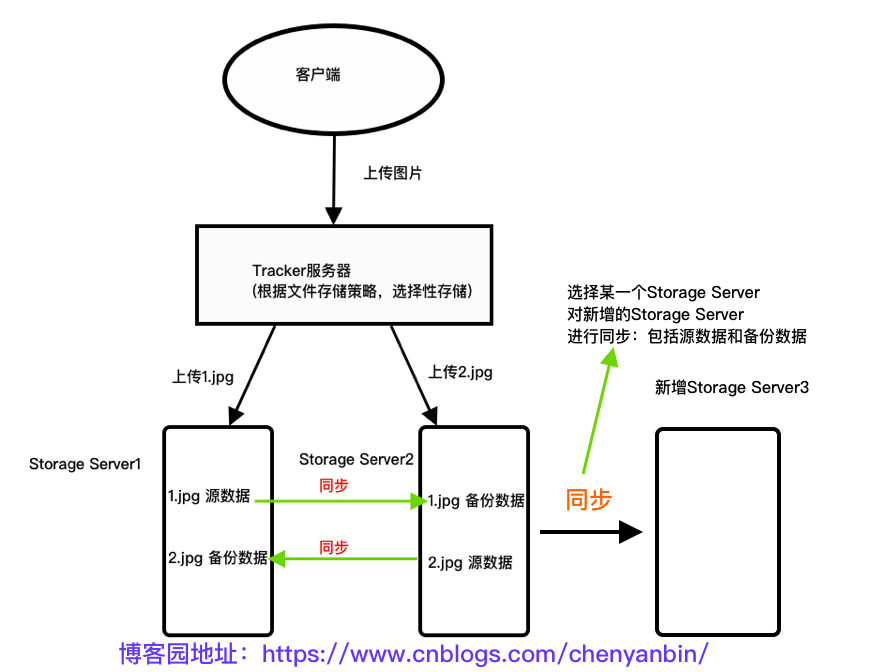
每个Storage写文件后,同时会写一份binlog,binlog里不包含文件数据,只包含文件名等元信息,这份binlog用于后台同步,Storage会记录向group内其他Storage同步的进度,以便重启后能接上次的进度继续同步;进度以时间戳的方式进行记录,所以最好能保证集群内所有Server的时钟保持同步。
文件下载流程分析
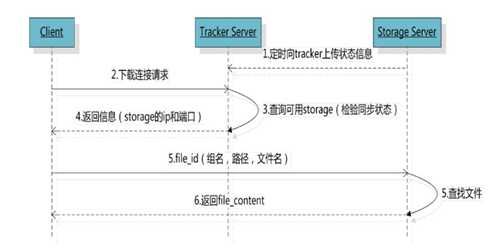
客户端upload file成功后,会拿到一个Storage生成的文件名,接下来客户端根据这个文件名即可访问到该文件。
流程说明
1、Tracker Server收集Storage Server的状态信息
1.1、Storage Server定时向已知的Tracker Server(可以是多个)发送磁盘剩余空间、文件同步状态、文件上传下载次数等统计信息。
1.2、Storage Server会连接整个集群中所有的Tracker Server,向他们报告自己的状态。
2、选择Tracker Server
2.1、跟upload file一样,在download file时客户端可以选择任意Tracker Server
3、选择可用的Storage Server
3.1、client发送download请求给某个Tracker,必须带上文件名信息,Tracker从文件名中解析出文件的group、路径信息、文件大小、创建时间、源Storage Server ip等信息,然后为该请求选择一个Storage用来服务读请求。
3.2、由于group内的文件同步是在后台异步进行的,所以有可能出现在读的时候,文件还没有同步到某些Storage Server上,为了尽量避免访问到这样的Storage,Tracker按照如下规则选择group内可读的Storage
3.2.1、该文件上传到的源头Storage - 源头Storage只要存活着,肯定包含这个文件,源头的地址被编码在文件名中。
3.2.2、文件创建时间戳 == Storage被同步到时间戳 且(当前时间 - 文件创建时间戳) > 文件同步最大时间 - 文件创建后,认为经过最大同步时间后,肯定已经同步到其他Storage了。
3.2.3、文件创建时间戳 < Storage被同步到的时间戳。 - 同步时间戳之前的文件确定已经同步
3.2.4、(当前时间 - 文件创建时间戳) > 同步延迟阈值。 经过同步延迟阈值时间,认为文件肯定已经同步了
FastDFS安装
需求
- Tracker Server:
- Storage Server:
注:Tracker和Storage安装,安装过程都一样,配置文件有差异
安装gcc环境
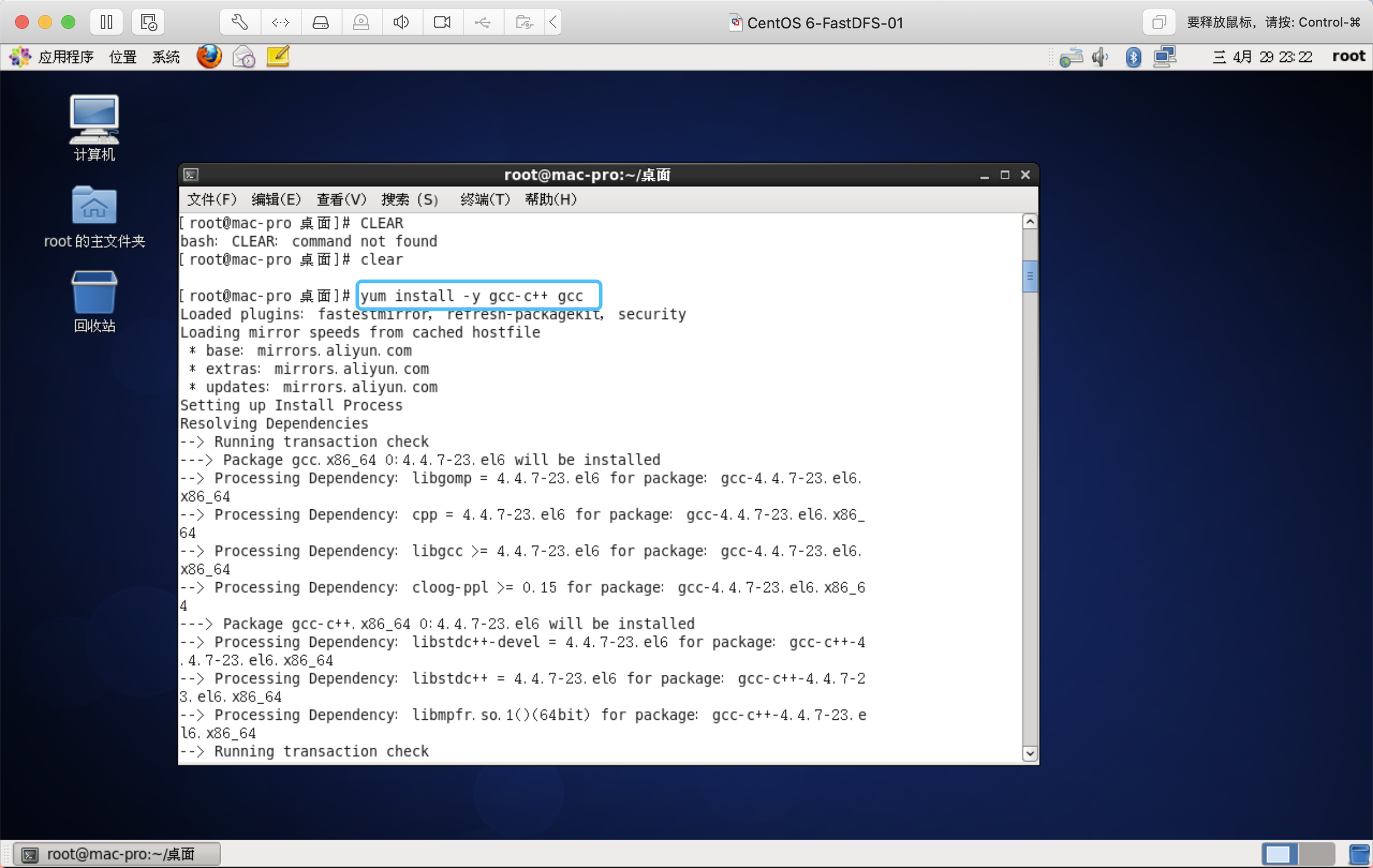
yum install -y gcc-c++ gcc
安装libevent(高版本可忽略,保险起见安装)
FastDFS依赖libevent库
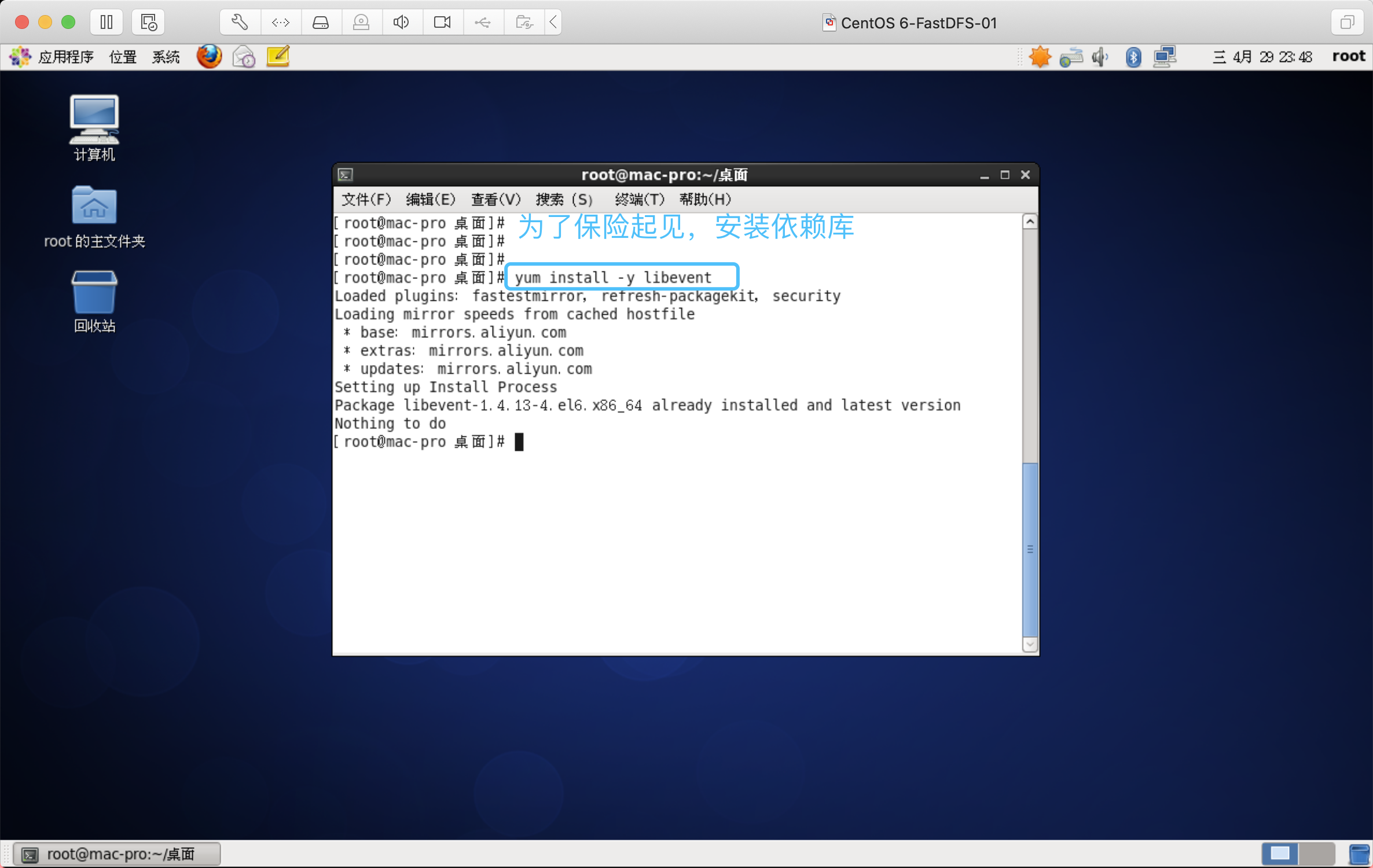
yum install -y libevent
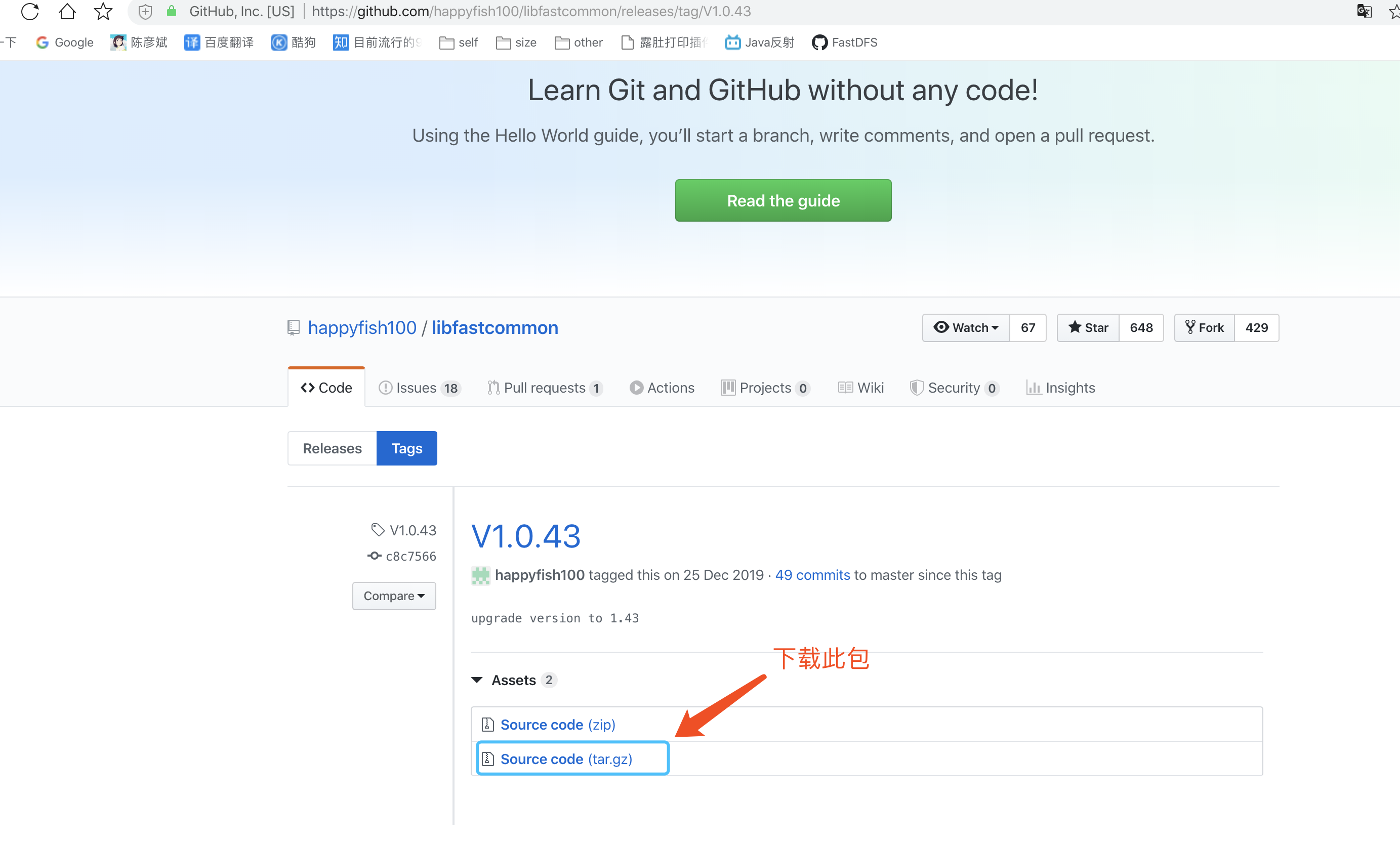
安装libfastcommon
下载地址:
https://github.com/happyfish100/libfastcommon/releases
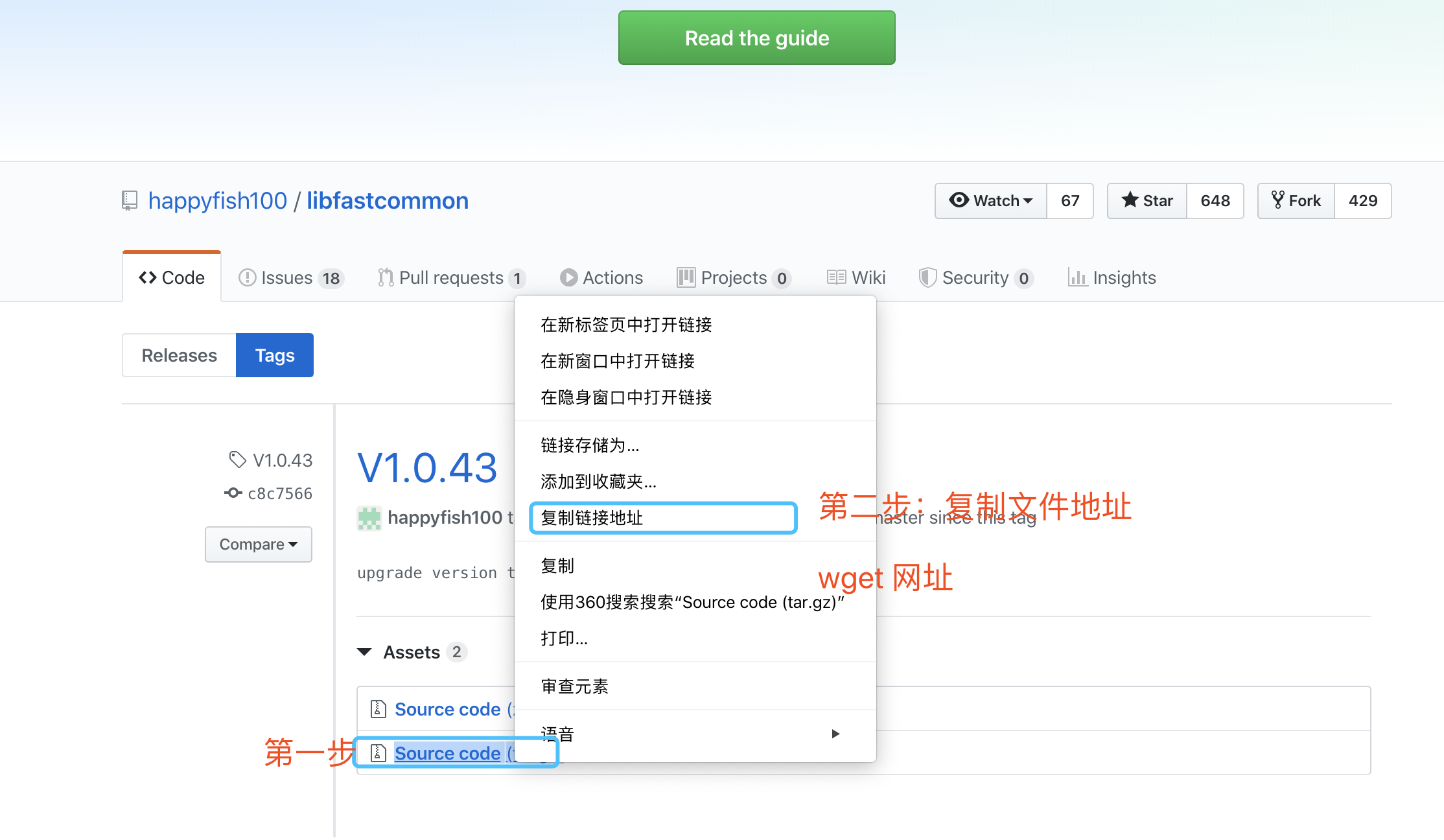
补充
也可以用wget方式联网下载,这里我是提前下载到本地客户端,将包拖进linux中 若wget命令不能使用,请执行:yum install -y wget wget方式:
wget https://github.com/happyfish100/libfastcommon/archive/V1.0.43.tar.gz
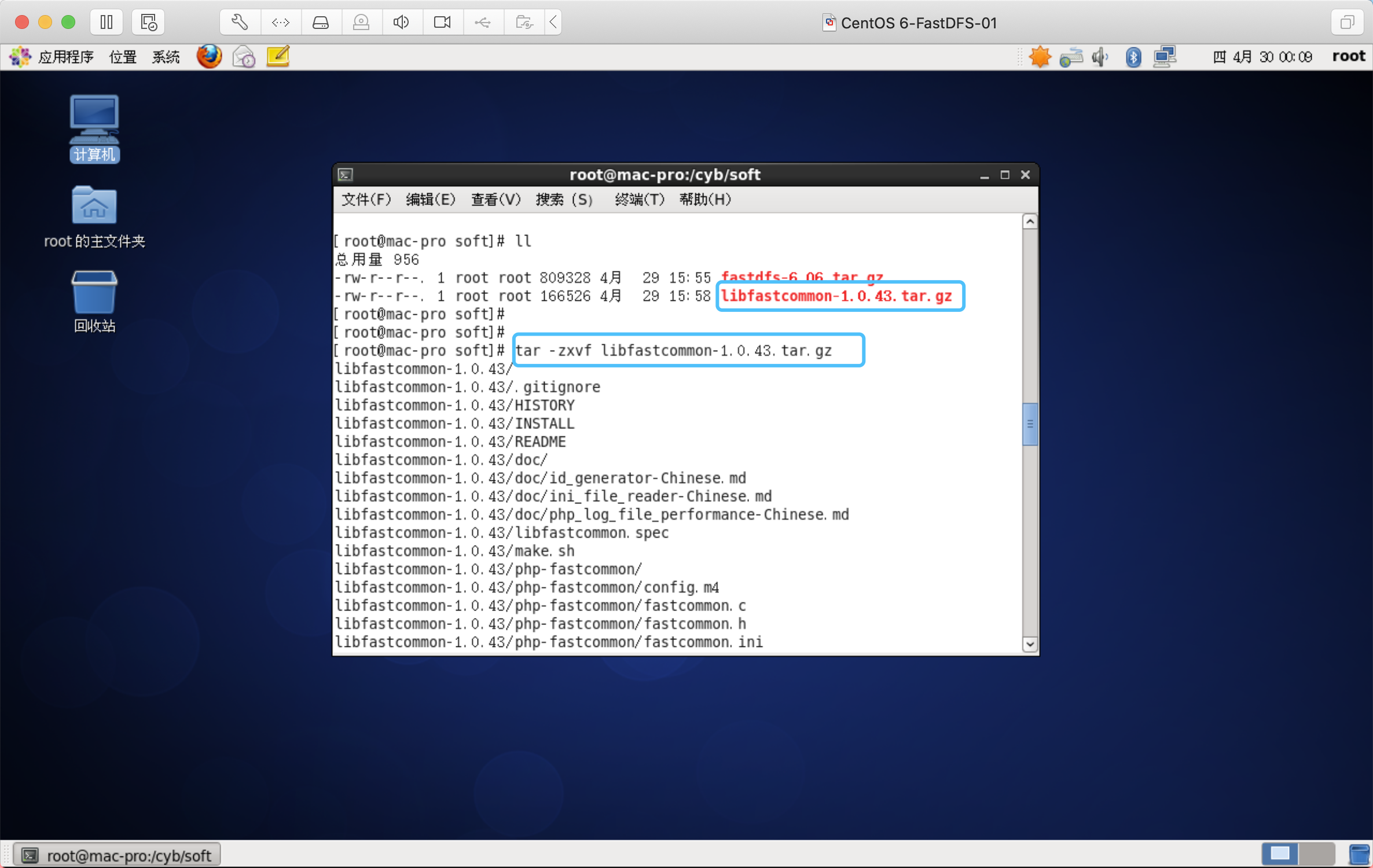
创建文件夹,用于存放安装包

将下载后的包放到该目录下
解压缩
编译并安装

拷贝libfastcommon.so文件至/usr/lib目录(高版本可忽略此步)
cp /usr/lib64/libfastcommon.so /usr/lib/
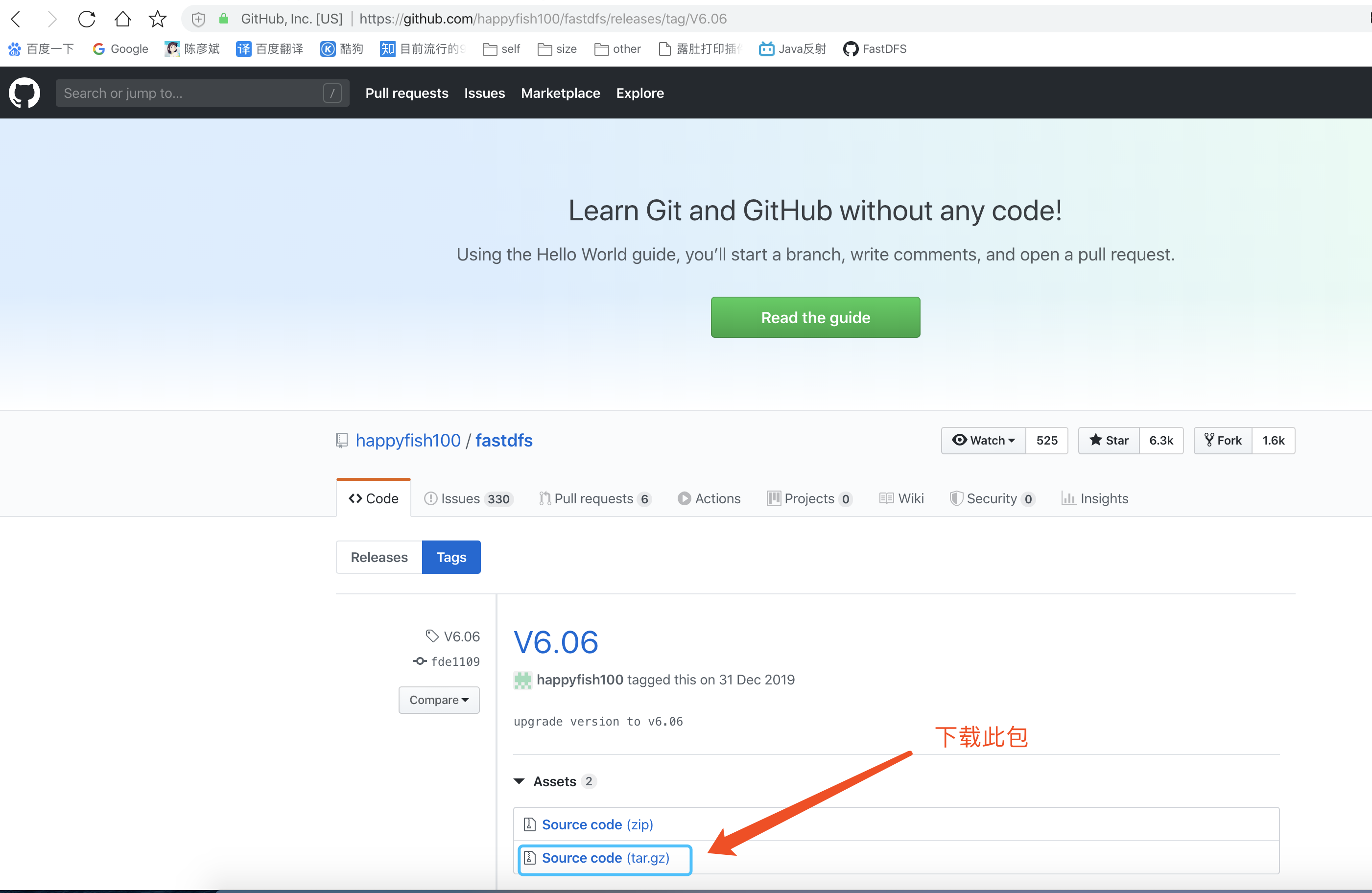
安装FastDFS
下载地址
https://github.com/happyfish100/fastdfs/releases
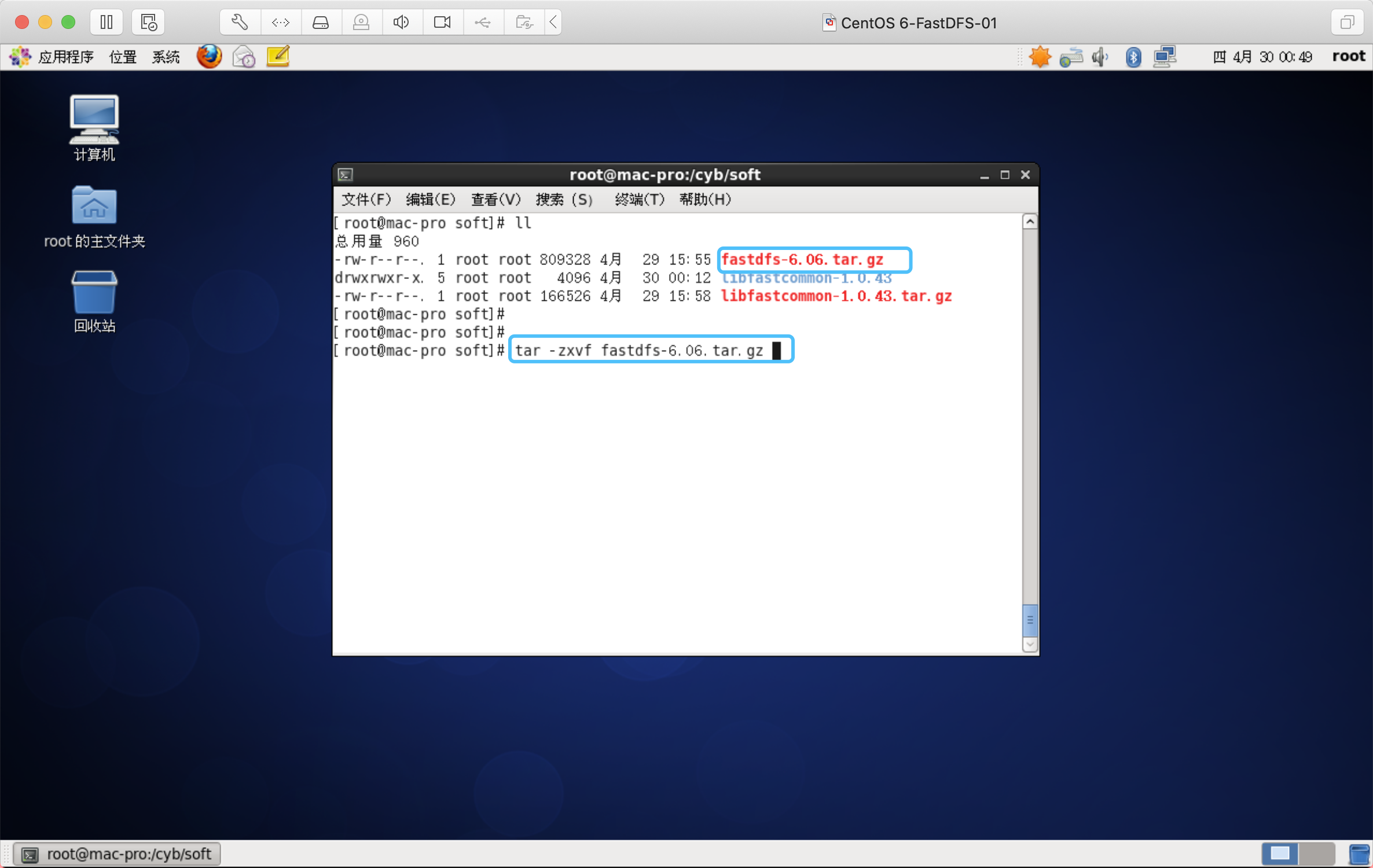
解压缩
编译与安装
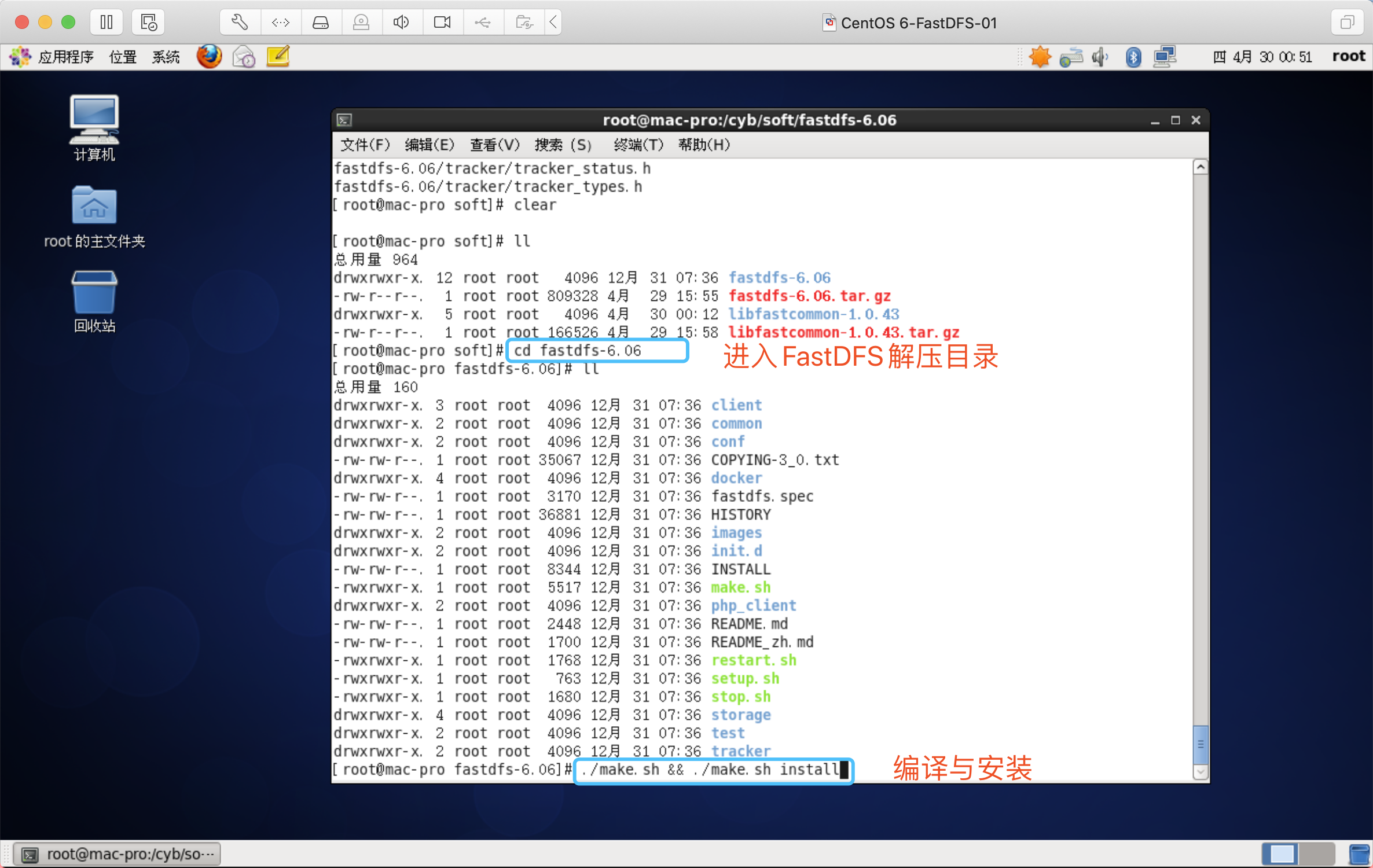
拷贝FastDFS目录下的文件到/etc/fdfs目录下
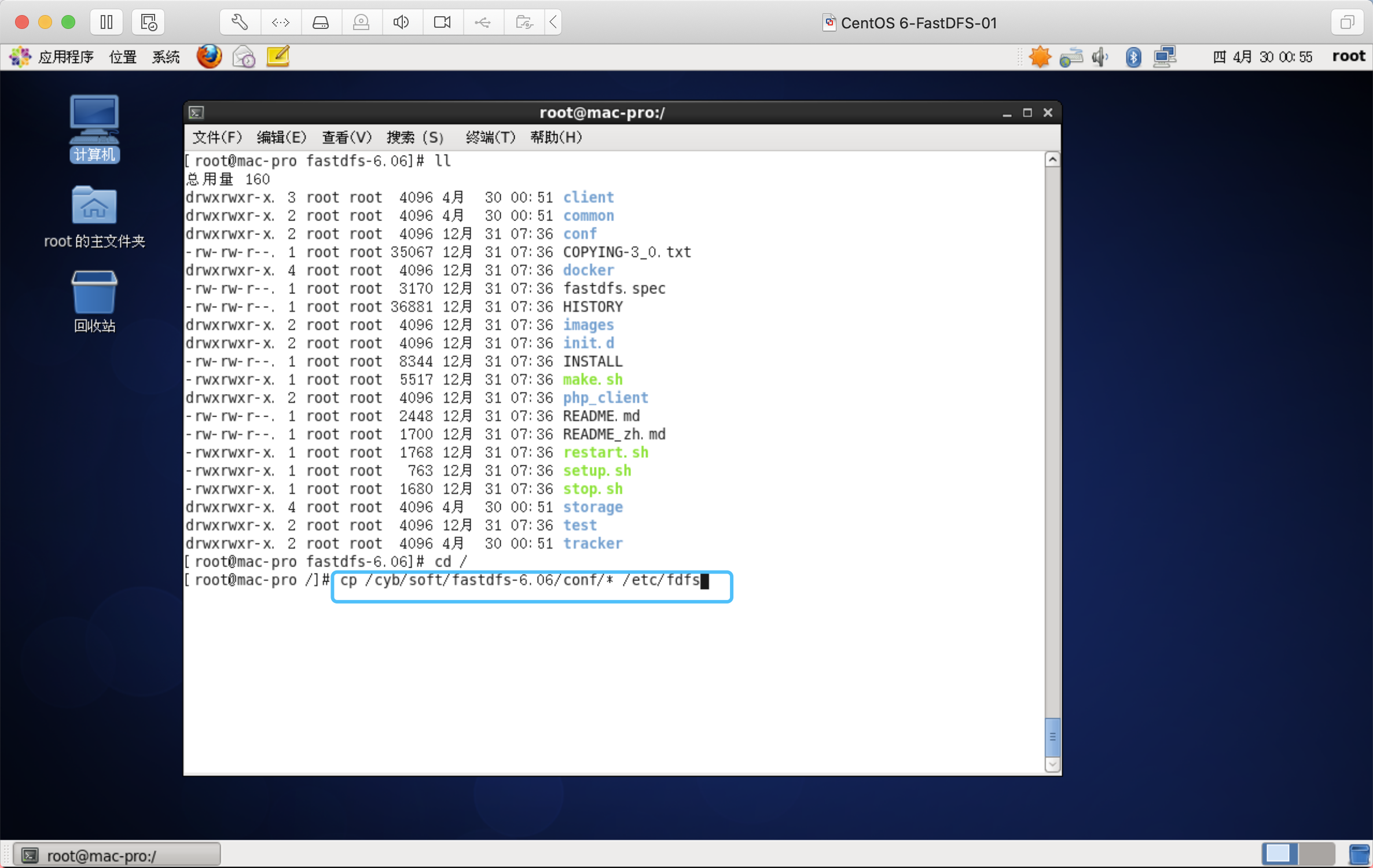
cp /cyb/soft/fastdfs-6.06/conf/* /etc/fdfs
=========================分割线======================================================
-----------------Tracker和Storage共同安装步骤结束!!!----------------------------
------------------Tracker和Storage只是配置不同!!!!-----------------------------
=========================分割线======================================================
Tracker Server 配置(虚拟机名:CentOS 6-FastDFS-01)
修改/etc/fdfs/tracker.conf
vim /etc/fdfs/tracker.conf
修改内容
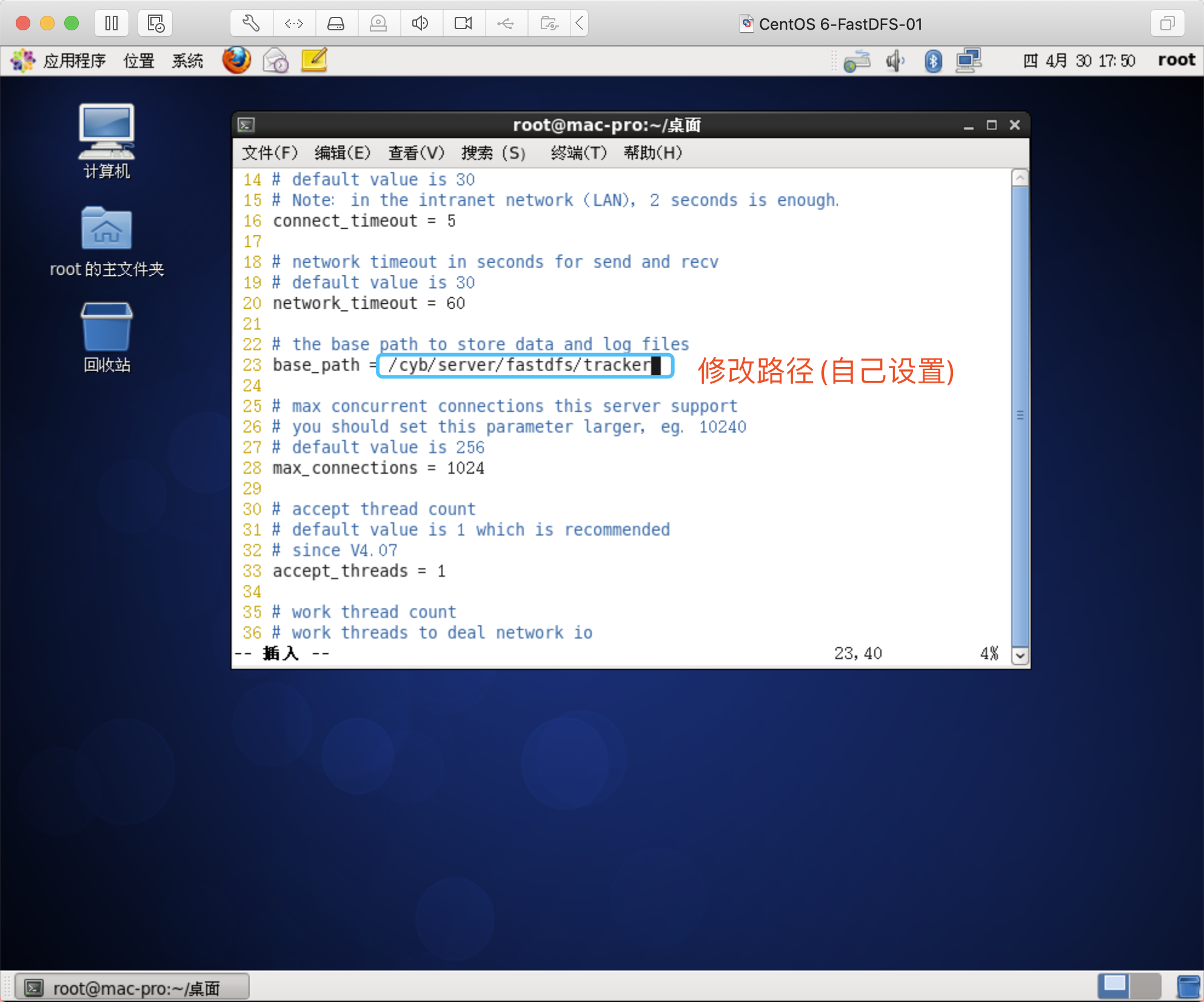
创建目录(若目录已存在,可忽略)
mkdir /cyb/server/fastdfs/tracker -p
Storage Server配置(虚拟机名:CentOS 6-FastDFS-02)
修改/etc/fdfs/storage.conf
vim /etc/fdfs/storage.conf
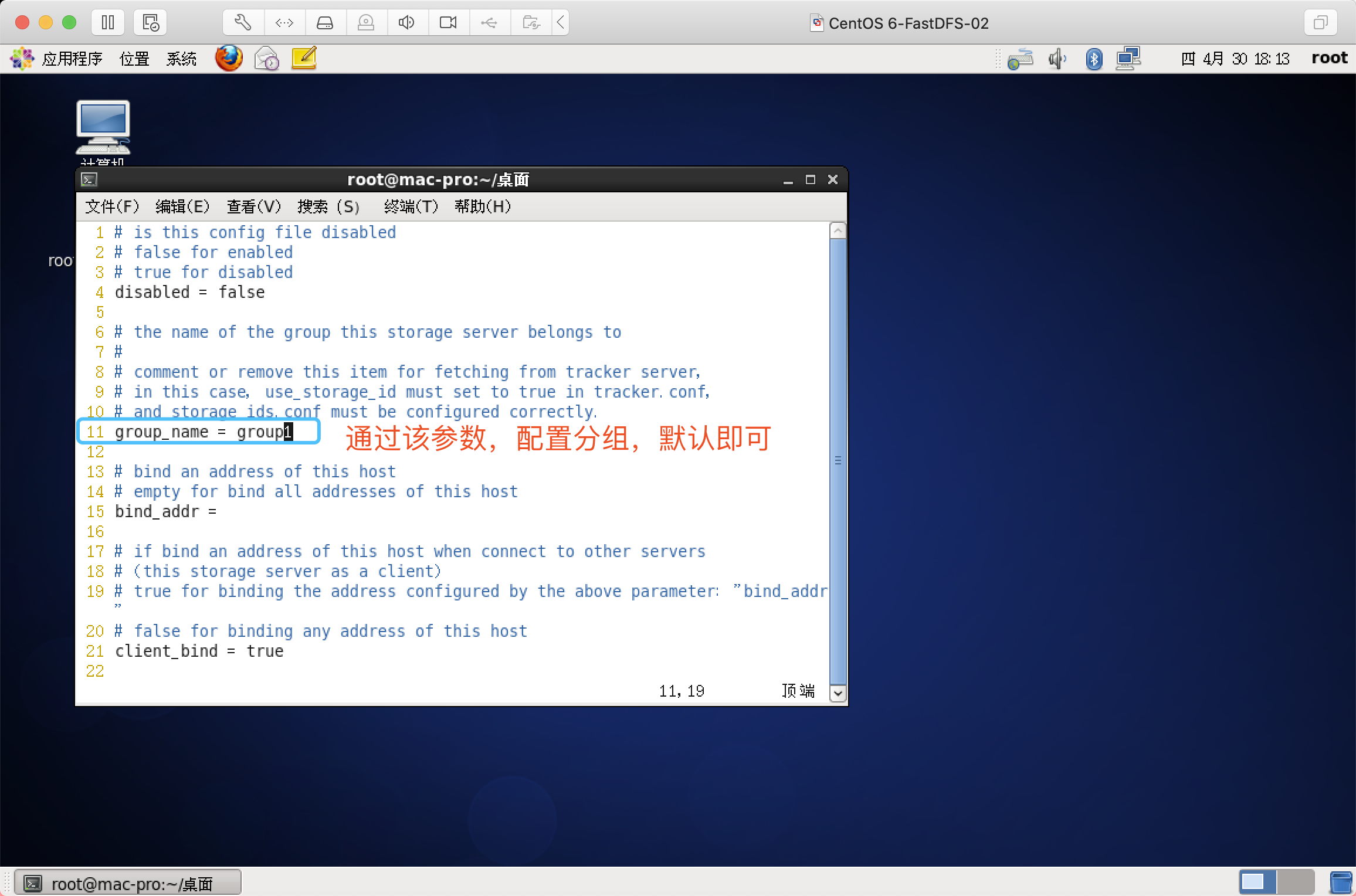
修改内容模板
# 指定storage的组名
group_name=group1
base_path=/cyb/server/fastdfs/storage # 如果有多个挂载磁盘则定义多个store_path
store_path0=/cyb/server/fastdfs/storage
# store_path1=.......
# store_path2=.......
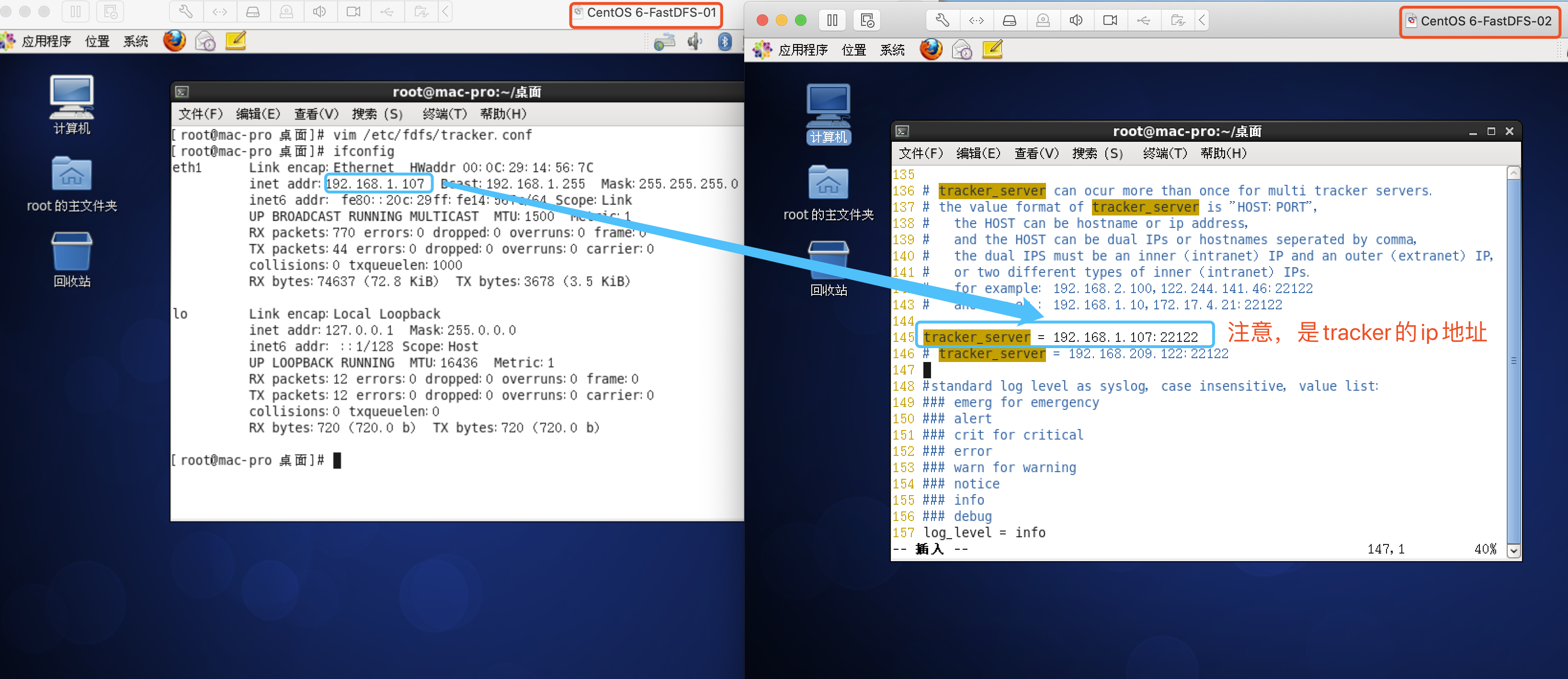
# store_path3=....... # 配置tracker服务器ip和端口
tracker_server=192.168.1.1:22122
# 若果有多个则配置多个tracker
# tracker_server=xxx.xxx.xxx.xxx:xxxx
# tracker_server=xxx.xxx.xxx.xxx:xxxx
# tracker_server=xxx.xxx.xxx.xxx:xxxx
修改:group_name
修改:base_path

修改:store_path*
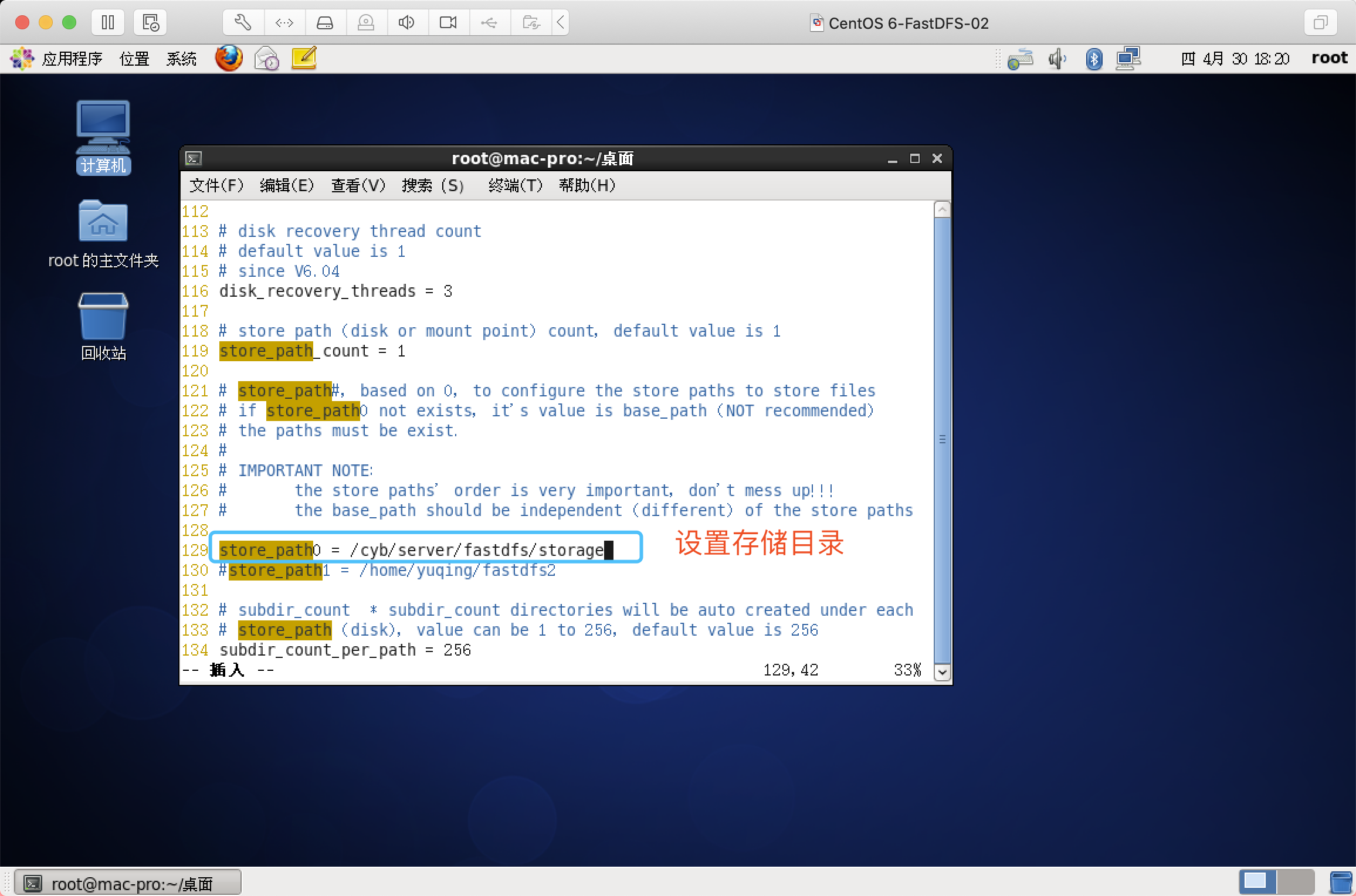
补充:为什么要设置多个store_path*呢?linux如果磁盘不够用的话,用户可以加硬盘,然后设置多个store_path*
修改:tracker_server
创建目录(若目录已存在,可忽略)
mkdir /cyb/server/fastdfs/storage -p
重复Storage Server配置步骤(虚拟机名:CentOS 6-FastDFS-03)
用途
该步骤用于演示负载均衡,冗余备份
启动
Tracker启动命令
/usr/bin/fdfs_trackerd /etc/fdfs/tracker.conf
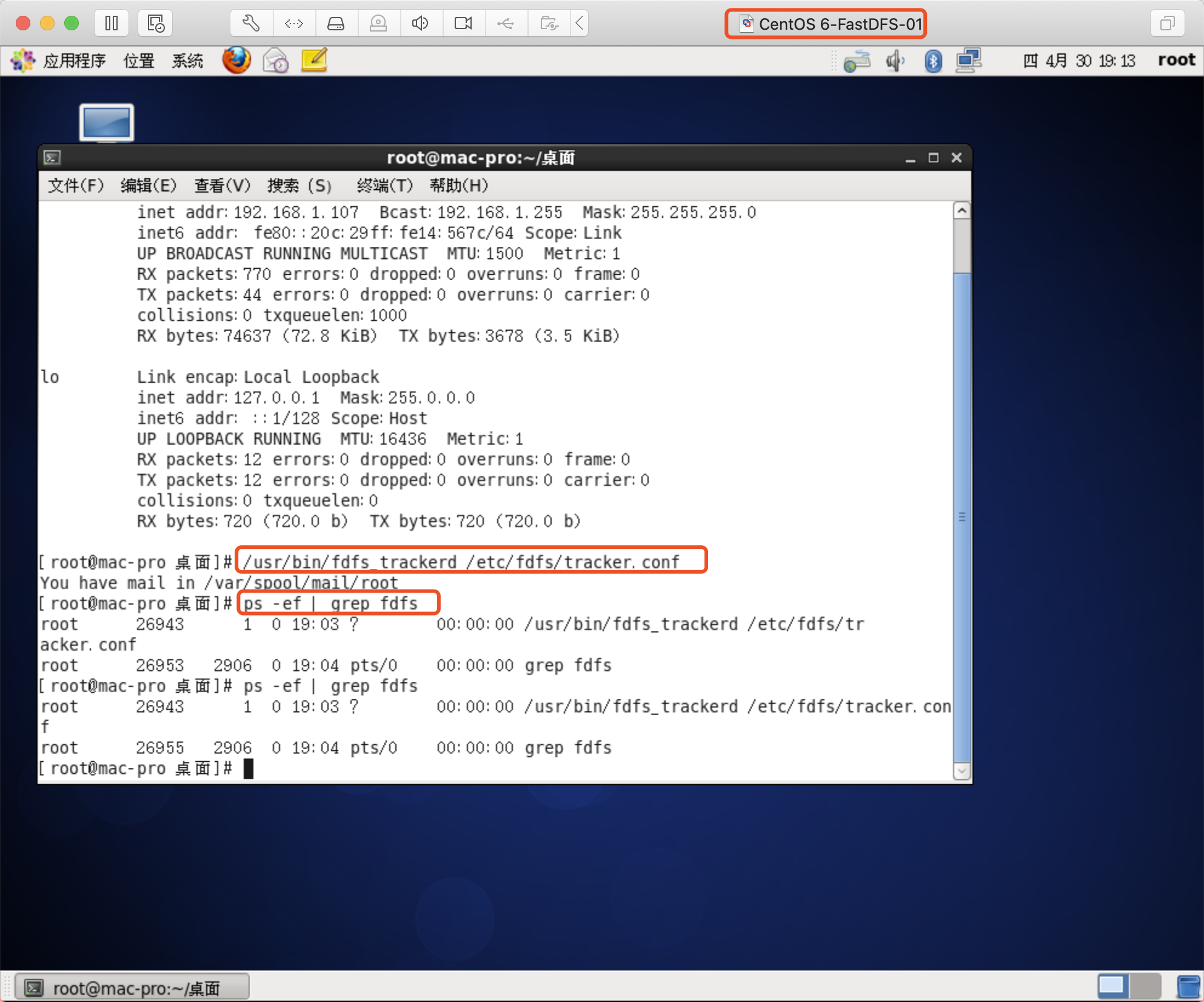
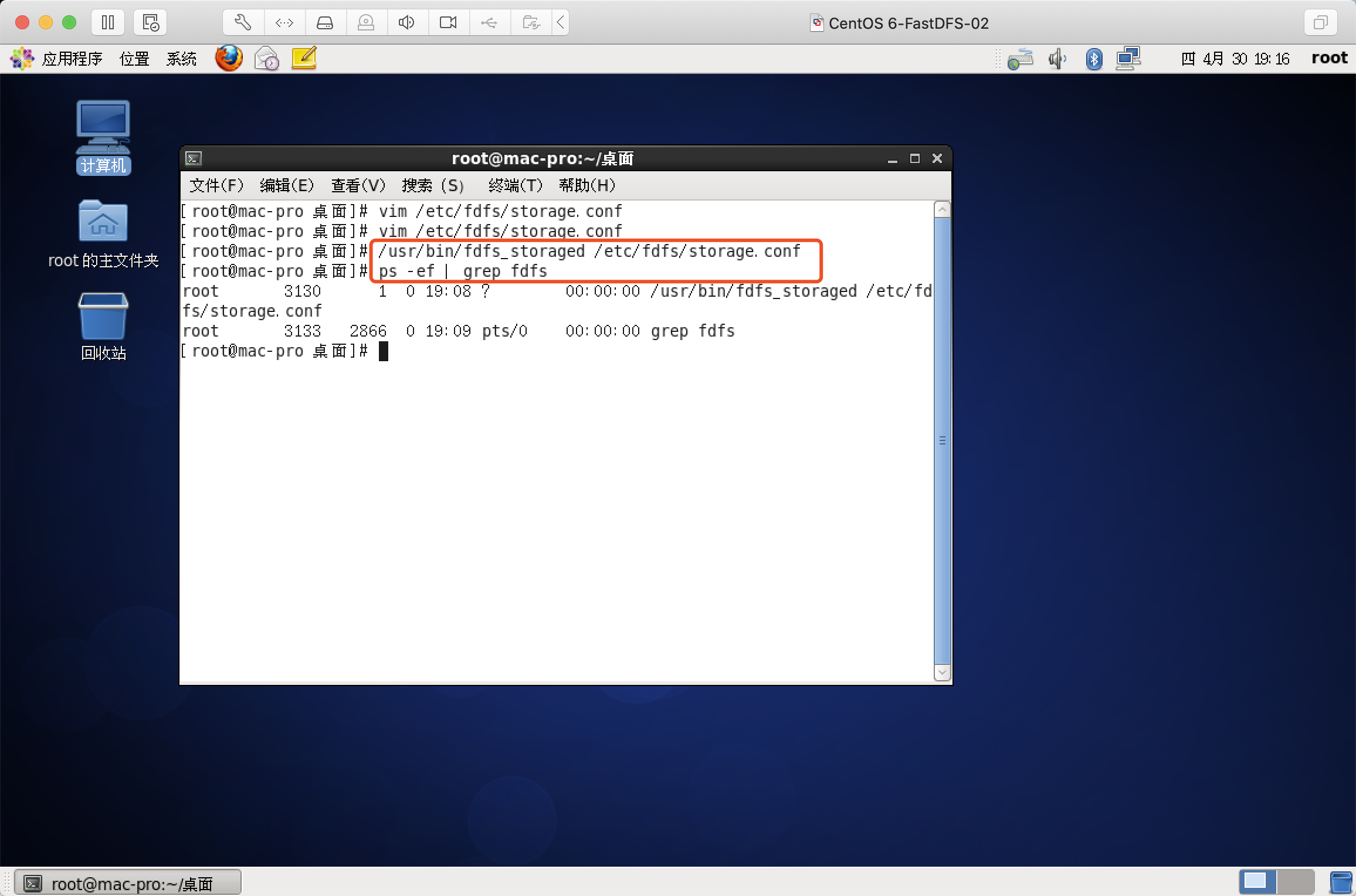
Storage启动命令
/usr/bin/fdfs_storaged /etc/fdfs/storage.conf
Tracker开启自启动
编辑文件:
vim /etc/rc.d/rc.local 将以下内容添加到该文件中:
/usr/bin/fdfs_trackerd /etc/fdfs/tracker.conf
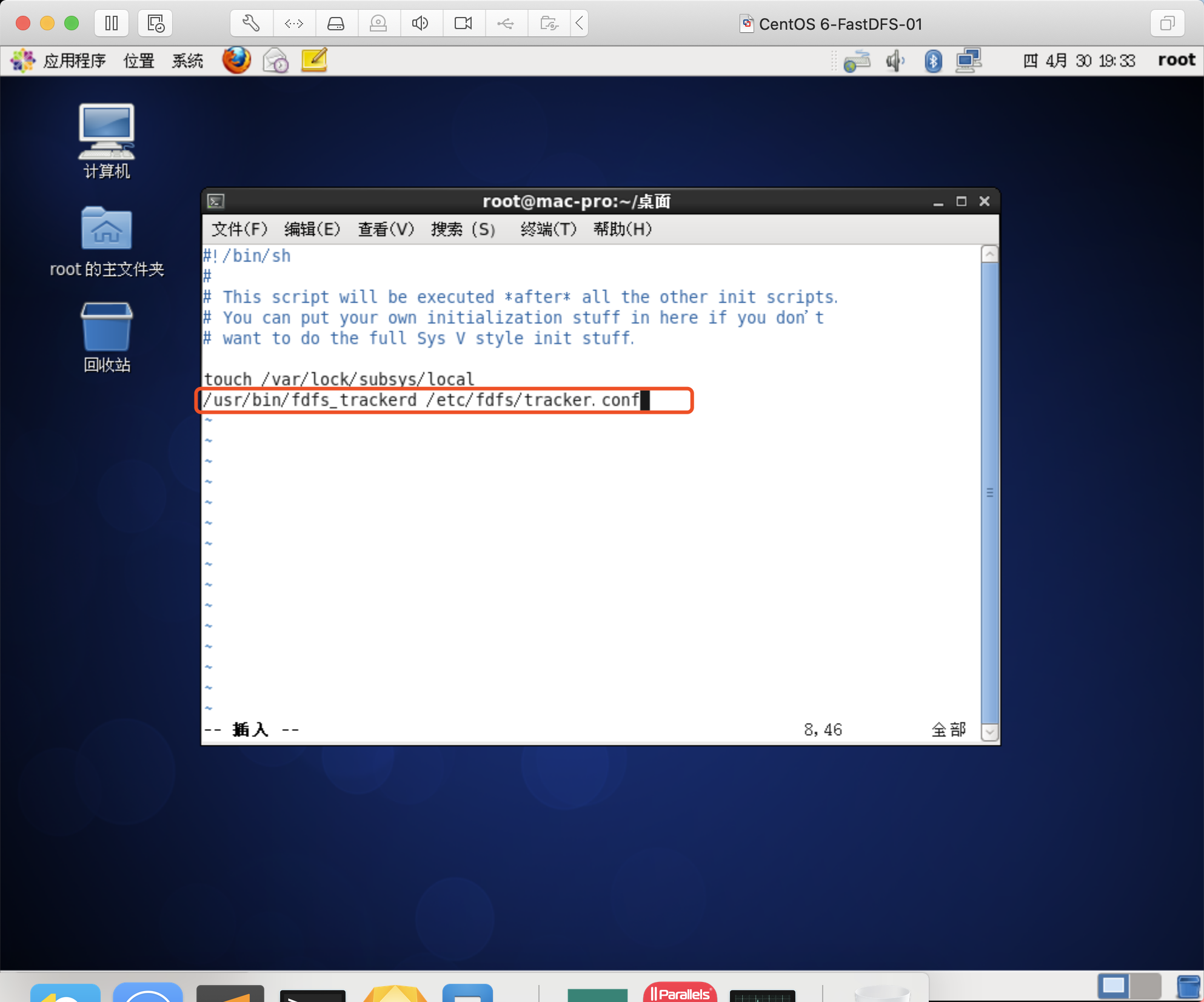
Storage开启自启动
编辑文件:
vim /etc/rc.d/rc.local 将以下内容添加到该文件中:
/usr/bin/fdfs_storaged /etc/fdfs/storage.conf
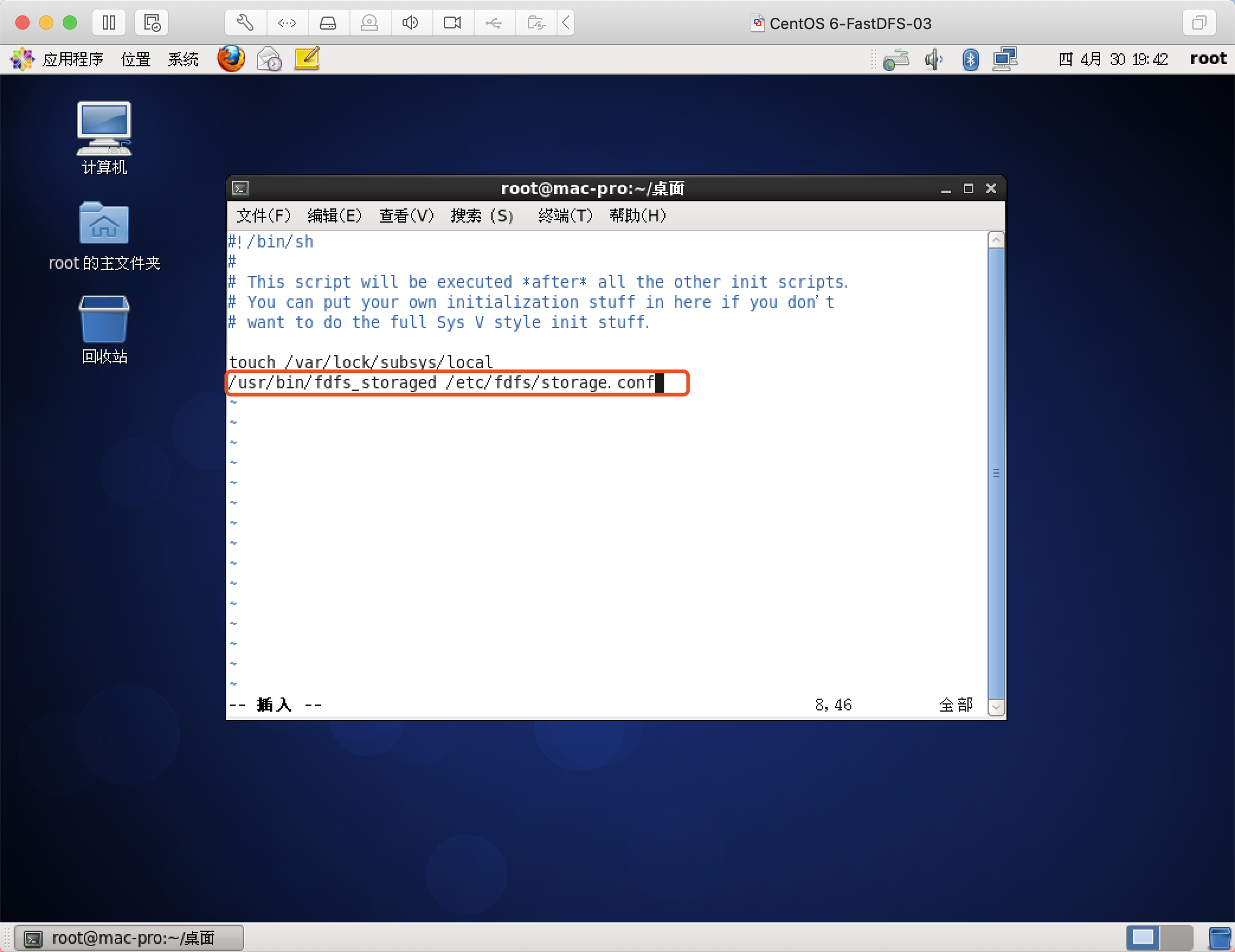
重启
sudo /usr/bin/fdfs_trackerd /etc/fdfs/tracker.conf restart
sudo /usr/bin/fdfs_storaged /etc/fdfs/storage.conf restart
补充(重要)
查看Storage日志
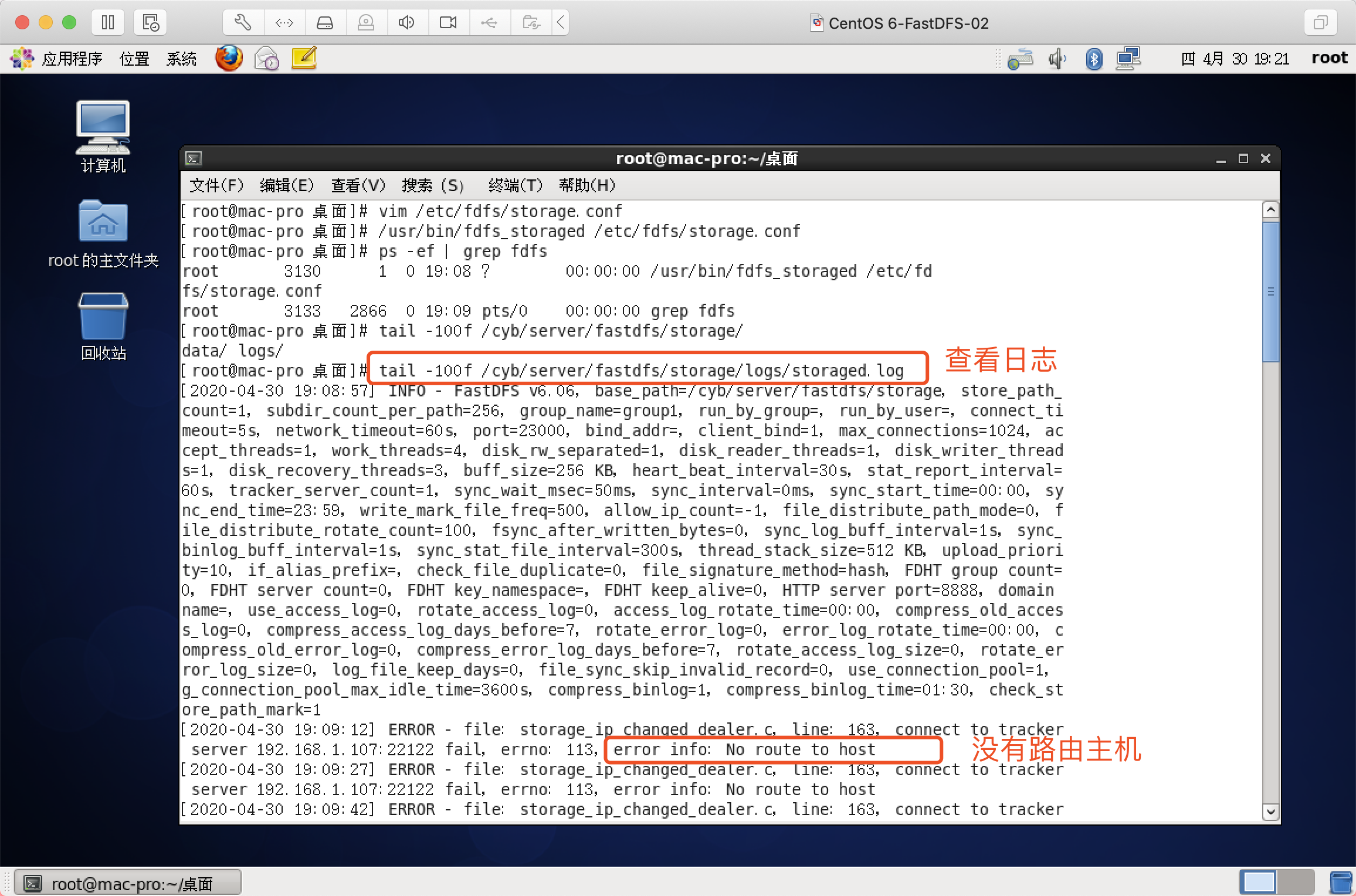
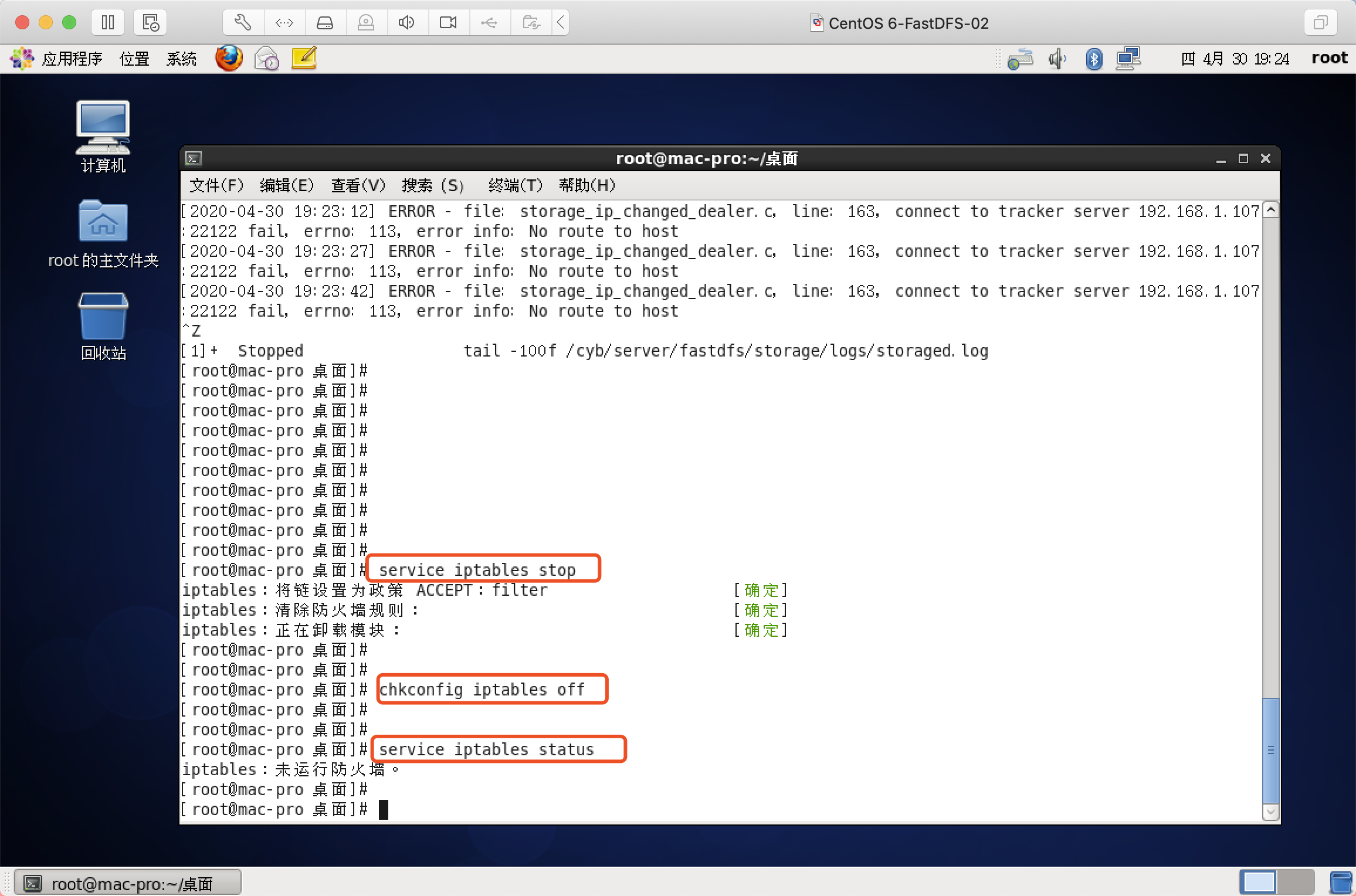
关闭防火墙!!!
1、关闭命令: service iptables stop
2、永久关闭防火墙:chkconfig iptables off
3、两个命令同时运行内,运行完成容后查看防火墙关闭状态
service iptables status
上传图片测试
FastDFS安装成功后可通过【fdfs_test】命令测试上传、下载等操作(三台中的任意一台测试即可)
修改client.conf
vim /etc/fdfs/client.conf
修改内容如下
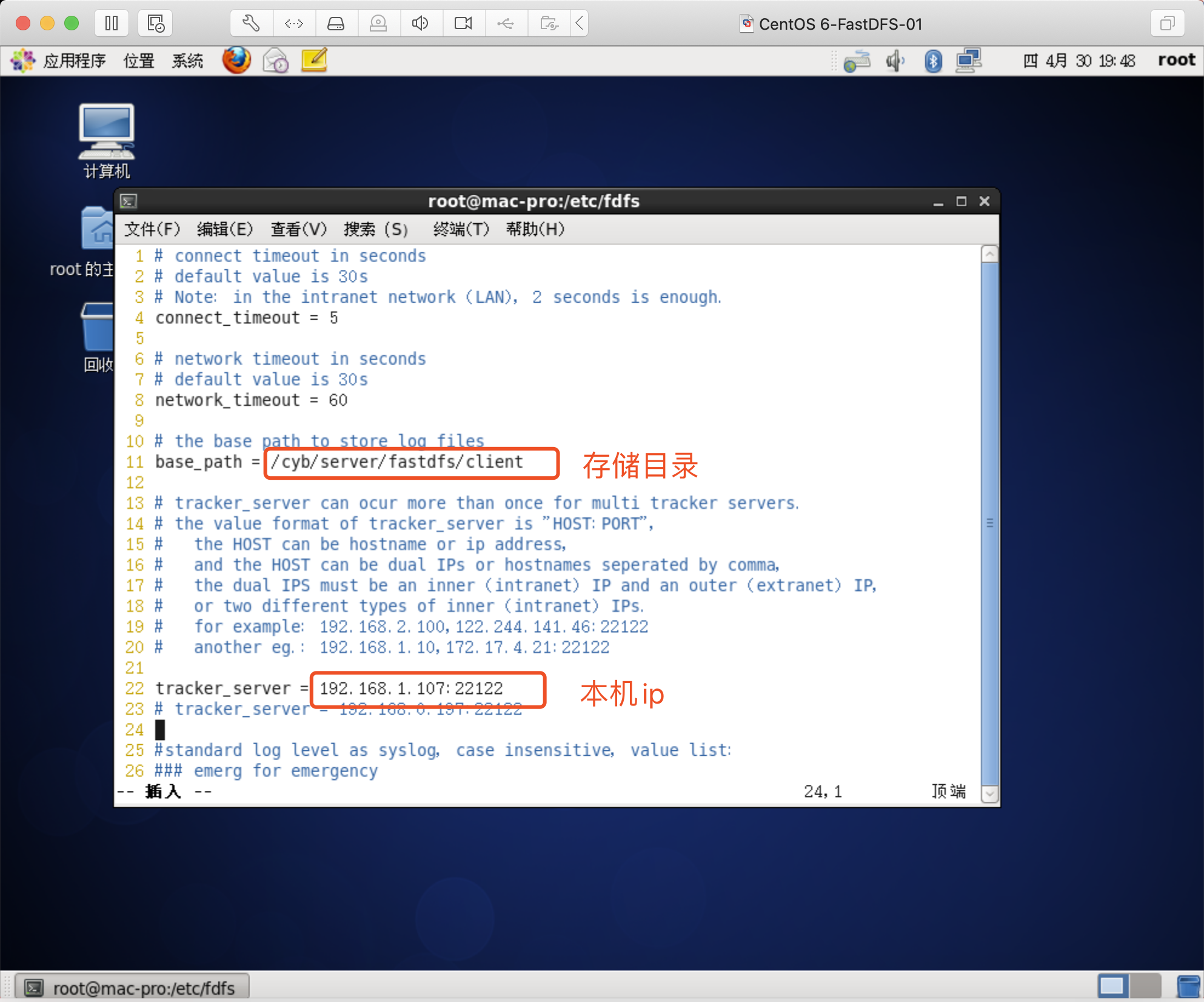
创建目录
mkdir /cyb/server/fastdfs/client -p
上传到FastDFS中
格式:
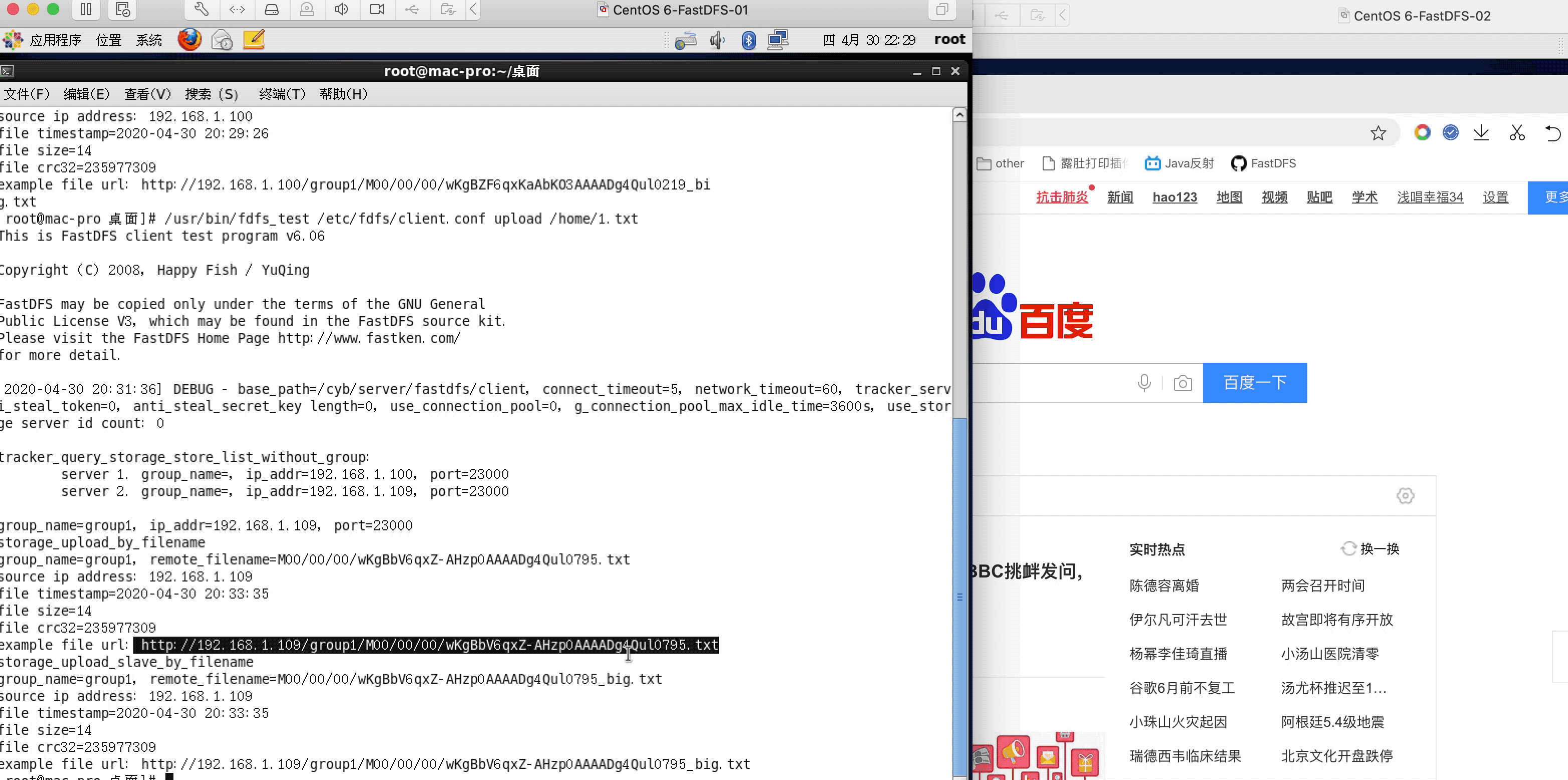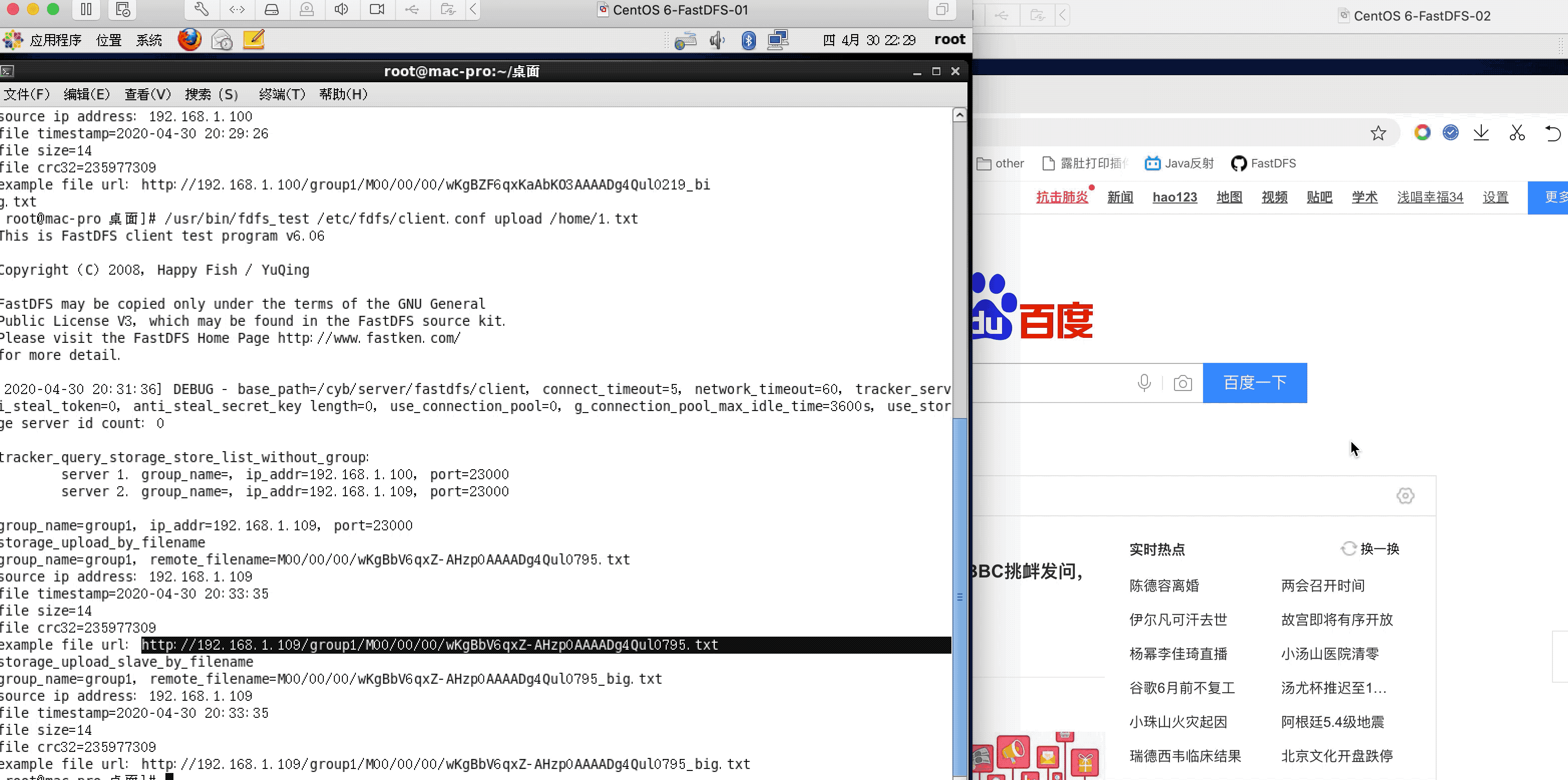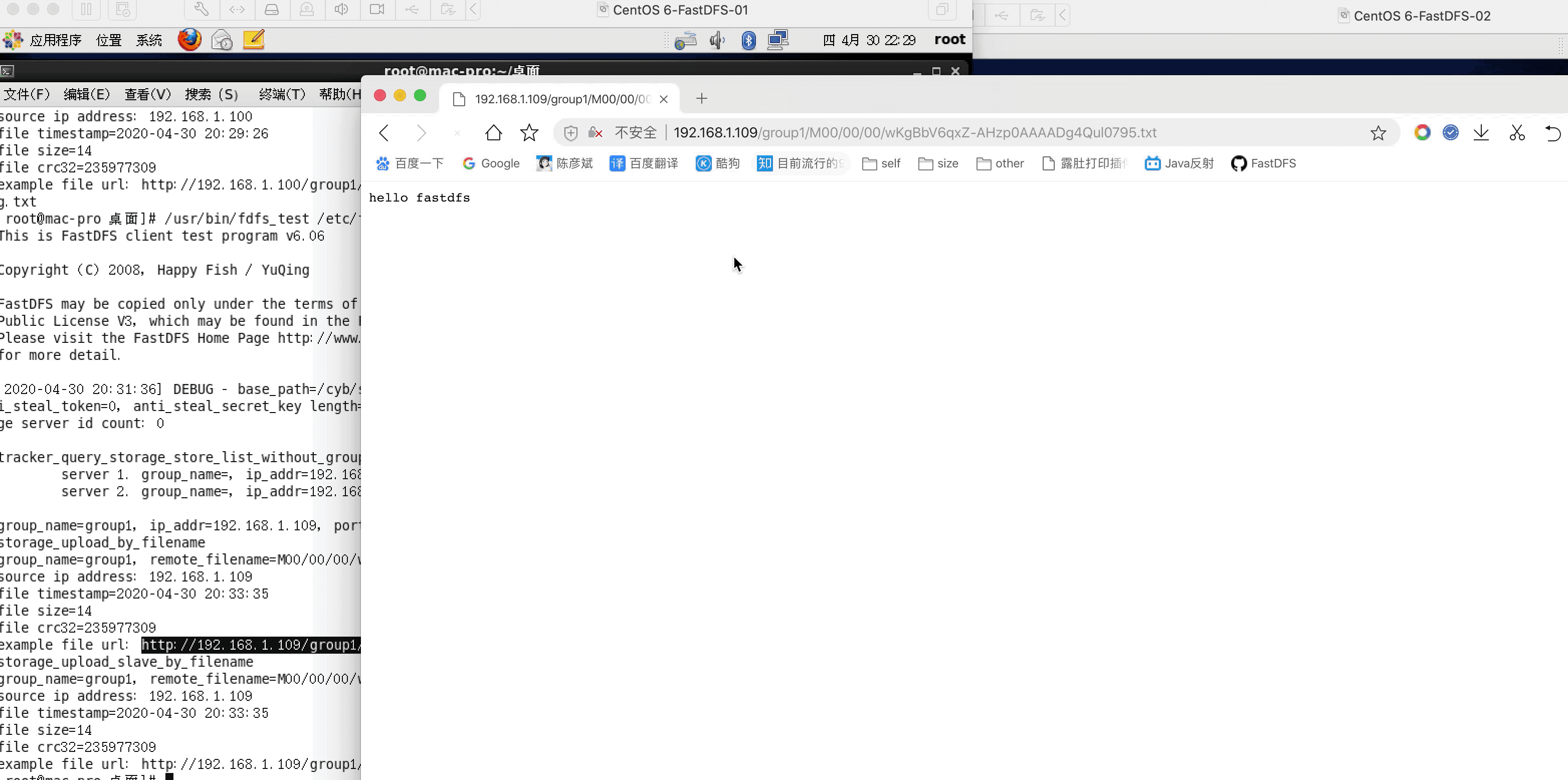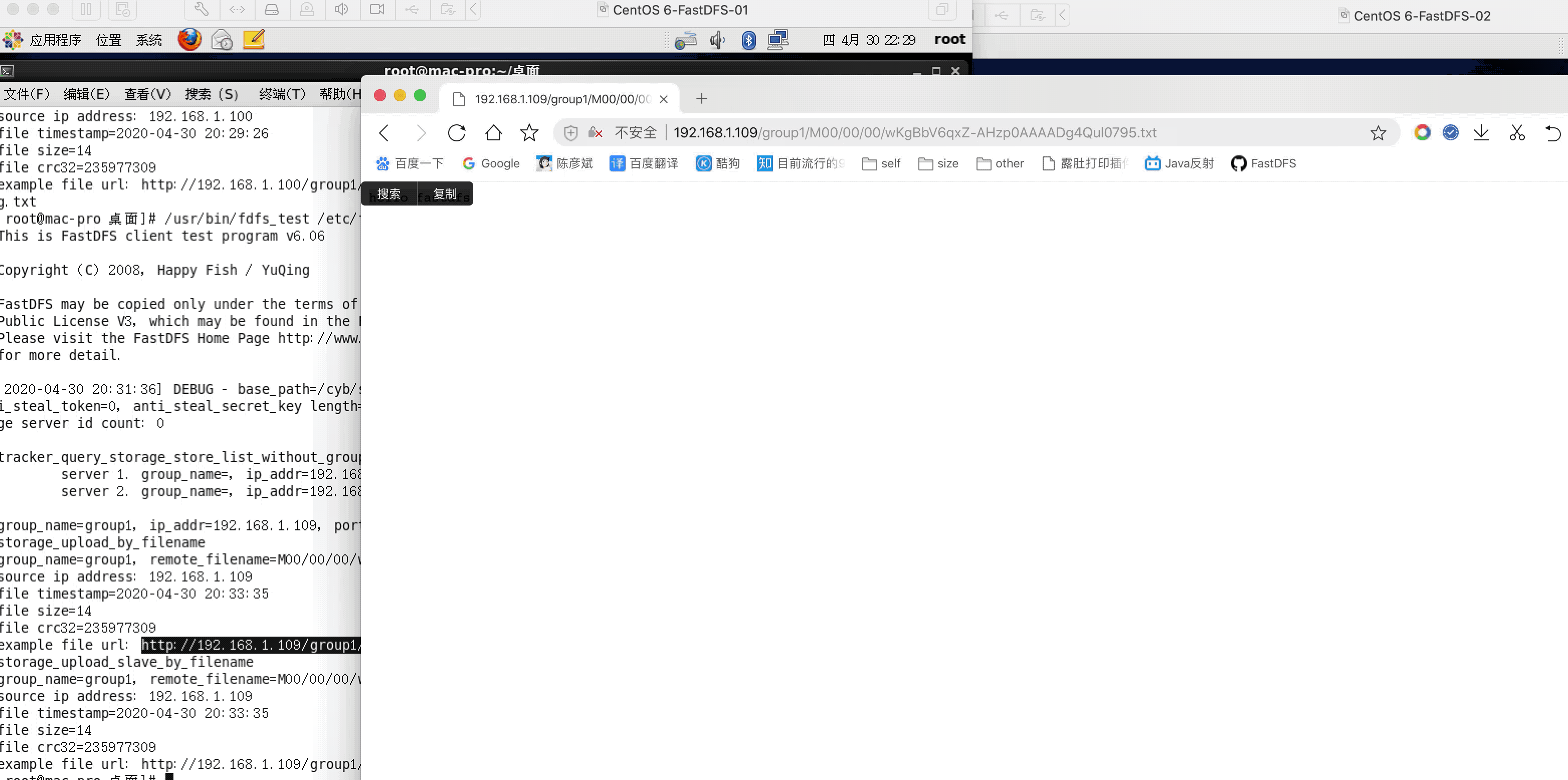
/usr/bin/fdfs_test /etc/fdfs/client.conf upload 文件路径 /usr/bin/fdfs_test /etc/fdfs/client.conf upload /home/1.txt
上传成功
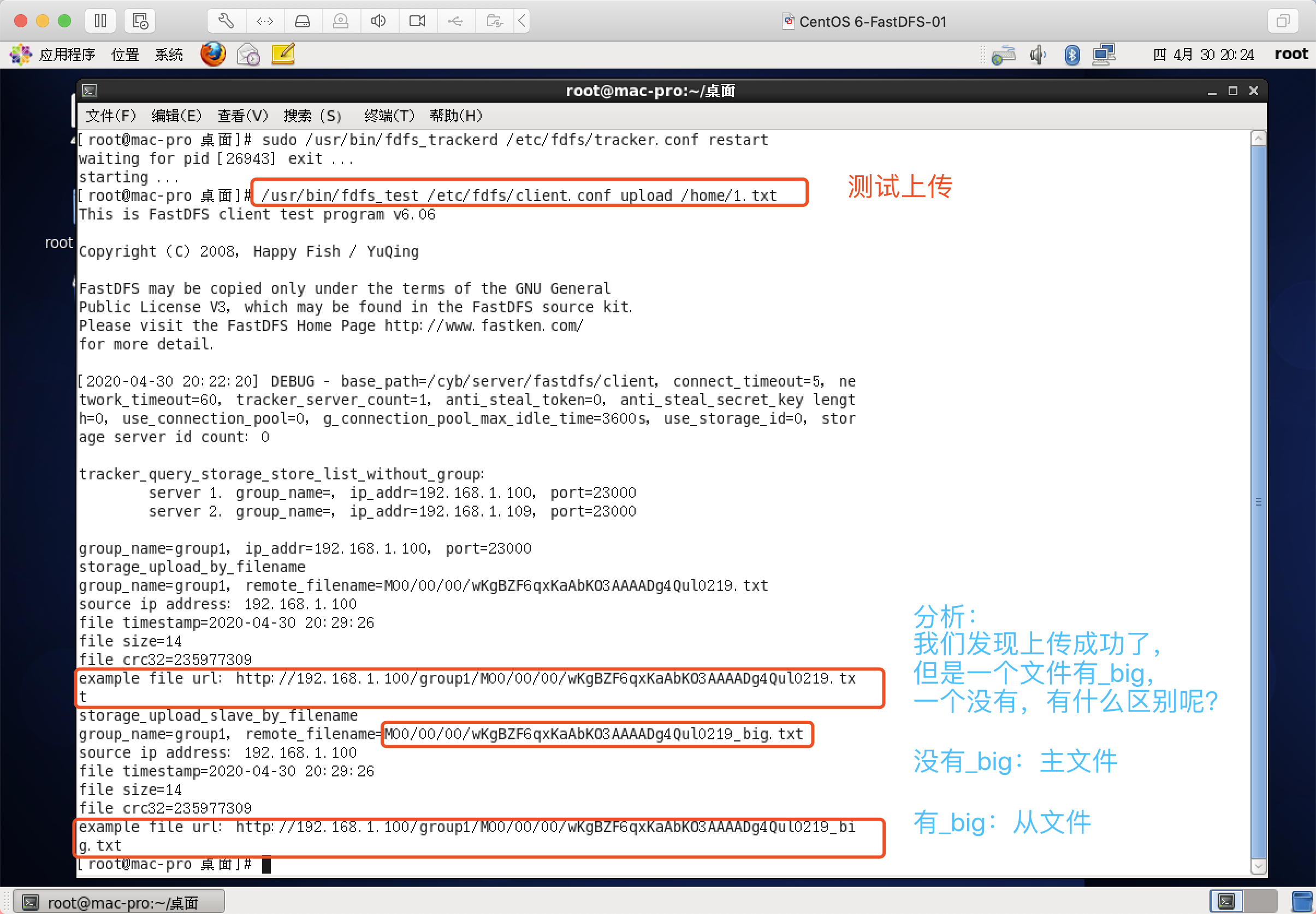
此时这个地址是访问不到的,需要与Nginx整合使用,方可访问该文件!
验证两台机器都上传成功
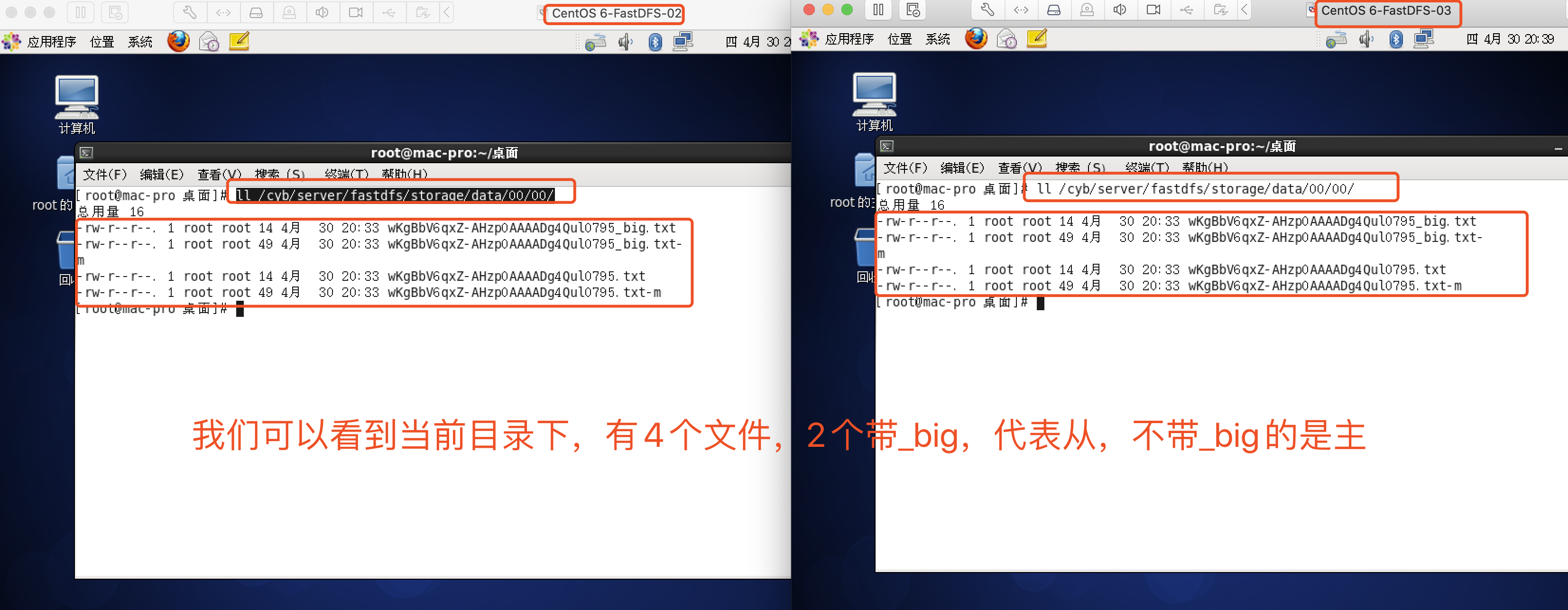
Tracker.conf配置文件
配置参数说明
#此配置文件是否已禁用
#false为启用
#为残疾人士适用
禁用=假 #绑定该主机的地址
#空用于绑定此主机的所有地址
bind_addr = #跟踪器服务器端口
端口= 22122 #连接超时(以秒为单位)
#默认值为30秒
connect_timeout = 10 #网络超时(以秒为单位)
#默认值为30秒
network_timeout = 60 #存储数据和日志文件的基本路径
base_path = / home / yuqing / fastdfs #此服务器支持的最大并发连接数
#您应该将此参数设置得更大一些,例如。102400
max_connections = 1024 #接受线程数
#默认值为1
#自V4.07起
accept_threads = 1 #工作线程数,应<= max_connections
#默认值为4
自V2.00起
work_threads = 4 #最小抛光量
#默认值8KB
min_buff_size = 8KB #最大增益
#默认值128KB
max_buff_size = 128KB #选择上传文件组的方法
#0:循环赛
#1:指定组
#2:负载均衡,选择最大可用空间组来上传文件
store_lookup = 2 #上传文件的组
#当store_lookup设置为1时,必须将store_group设置为组名
store_group = group2 #要上传文件的存储服务器
#0:循环(默认)
#1:第一个服务器按IP地址排序
#2:按优先级排列的第一个服务器顺序(最小)
#注意:如果use_trunk_file设置为true,则必须将store_server设置为1或2
store_server = 0 #存储服务器上载文件的路径(表示磁盘或挂载点)
#0:循环赛
#2:负载均衡,选择最大可用空间路径上传文件
store_path = 0 #要下载文件的存储服务器
#0:循环(默认)
#1:当前文件上传到的源存储服务器
download_server = 0 #为系统或其他应用程序保留的存储空间。
#如果以下任何存储服务器的可用(可用)空间
#一个组<= reserved_storage_space,
#没有文件可以上传到该组。
#字节单位可以是以下之一:
### G或g表示千兆字节(GB)
### M或m表示兆字节(MB)
### K或k表示千字节(KB)
###无字节单位(B)
### XX.XX%作为比例,例如reserved_storage_space = 10%
reserved_storage_space = 20% #standard日志级别为syslog,不区分大小写,值列表:
###紧急应急
###警报
###暴击
###错误
###警告警告
### 注意
###信息
###调试
log_level =信息 #unix组名以运行此程序,
#未设置(空)表示由当前用户组运行
run_by_group = #unix用户名以运行此程序,
#未设置(空)表示由当前用户运行
run_by_user = #allow_hosts可以多次出现,host可以是主机名或IP地址,
#“ *”(仅一个星号)表示匹配所有IP地址
#我们可以使用像192.168.5.64/26这样的CIDR IP
#并使用以下范围:10.0.1。[0-254]和主机[01-08,20-25] .domain.com
# 例如:
#allow_hosts = 10.0.1。[1-15,20]
#allow_hosts = host [01-08,20-25] .domain.com
#allow_hosts = 192.168.5.64 / 26
allow_hosts = * #每隔几秒将日志buff同步到磁盘
#默认值为10秒
sync_log_buff_interval = 10 #检查存储服务器的活动间隔秒数
check_active_interval = 120 #线程堆栈大小,应> = 64KB
#默认值为256KB
thread_stack_size = 256KB #自动调整存储服务器的IP地址
#默认值为true
storage_ip_changed_auto_adjust = true #存储同步文件的最大延迟秒数
#默认值为86400秒(一天)
自V2.00起
storage_sync_file_max_delay = 86400 #存储文件同步的最长时间
#默认值为300秒
自V2.00起
storage_sync_file_max_time = 300 #如果使用中继文件存储几个小文件
#默认值为false
#自V3.00起
use_trunk_file =否 #最小插槽大小,应<= 4KB
#默认值为256字节
#自V3.00起
slot_min_size = 256 #最大插槽大小,应> slot_min_size
#当上传文件的大小小于等于此值时,将其存储到中继文件
#默认值为16MB
#自V3.00起
slot_max_size = 16MB #中继文件大小,应> = 4MB
#默认值为64MB
#自V3.00起
trunk_file_size = 64MB #如果预先创建中继文件
#默认值为false
#从V3.06开始
trunk_create_file_advance =否 #创建中继文件的时基
#时间格式:HH:MM
#默认值为02:00
#从V3.06开始
trunk_create_file_time_base = 02:00 #创建Trunk文件的时间间隔,单位:秒
#默认值为38400(一天)
#从V3.06开始
trunk_create_file_interval = 86400 #创建中继文件的阈值
#当空闲中继文件大小小于阈值时,将创建
#中继文件
#默认值为0
#从V3.06开始
trunk_create_file_space_threshold = 20G #加载行李箱空闲空间时是否检查行李箱空间占用
#占用的空间将被忽略
#默认值为false
#自V3.09起
#注意:将此参数设置为true会减慢行李箱空间的加载
#启动时。您应在必要时将此参数设置为true。
trunk_init_check_occupying =否 #如果忽略storage_trunk.dat,则从中继binlog重新加载
#默认值为false
#自V3.10起
#如果版本低于V3.10,则一次设置为true进行版本升级
trunk_init_reload_from_binlog =否 #压缩中继binlog文件的最小间隔
#单位:秒
#默认值为0,0表示永不压缩
#在主干初始化和主干销毁时,FastDFS压缩主干binlog
#重新命令将此参数设置为86400(一天)
#自V5.01起
trunk_compress_binlog_min_interval = 0 #如果使用存储ID代替IP地址
#默认值为false
#自V4.00起
use_storage_id =假 #指定存储ID的文件名,可以使用相对或绝对路径
#自V4.00起
storage_ids_filename = storage_ids.conf #文件名中存储服务器的id类型,值是:
## ip:存储服务器的IP地址
## id:存储服务器的服务器ID
#仅当use_storage_id设置为true时,此参数才有效
#默认值为ip
从V4.03开始
id_type_in_filename = id #如果存储从属文件使用符号链接
#默认值为false
#自V4.01起
store_slave_file_use_link = false #如果每天旋转错误日志
#默认值为false
从V4.02开始
rotation_error_log =否 #旋转错误日志的时基,时间格式:小时:分钟
#小时从0到23,分钟从0到59
#默认值为00:00
从V4.02开始
error_log_rotate_time = 00:00 #当日志文件超过此大小时旋转错误日志
#0表示永不按日志文件大小旋转日志文件
#默认值为0
从V4.02开始
rotation_error_log_size = 0 #保留日志文件的天数
#0表示不删除旧的日志文件
#默认值为0
log_file_keep_days = 0 #如果使用连接池
#默认值为false
#自V4.05起
use_connection_pool =否 #空闲时间超过此时间的连接将被关闭
#单位:秒
#默认值为3600
#自V4.05起
connection_pool_max_idle_time = 3600 #该跟踪器服务器上的HTTP端口
http.server_port = 8080 #检查存储HTTP服务器的活动间隔秒数
#<= 0表示永不检查
#默认值为30
http.check_alive_interval = 30 #检查存储HTTP服务器的活动类型,值是:
#tcp:仅使用HTTP端口连接到storge服务器,
#不要求获得回应
#http:存储检查有效网址必须返回http状态200
#默认值为tcp
http.check_alive_type = tcp #检查存储HTTP服务器是否存在uri / url
#注意:存储嵌入HTTP服务器支持uri:/status.html
http.check_alive_uri = / status.html
安装Nginx(Apache)
安装事项
Nginx需要安装在每一台Storage服务器上,Tracker服务器上不需要安装!!!!Nginx不明白的童鞋,可以看我另一篇博客:从入门到精通-Nginx,图文并茂、负载均衡、动静分离、虚拟主机 附案例源码
下载文件
补充
上传文件可以用:
1、yum install -y lrzsz 2、rz
安装依赖库
1、yum install -y gcc-c++ gcc (C语言依赖库,若安装过,可不安装) pcre-devel:pcre,Perl Compatible Regular Expressions,Perl脚本语言兼容正则表达式,为Nginx提供正则表达式库。
openssl-devel:为Nginx提供SSL(安全套接字层)密码库,包含主要的密码算法,常用的密钥和证书封装管理功能及SSL协议,并提供丰富的应用程序供测试或其他目的使用。
2、yum -y install pcre-devel openssl-devel
解压缩
执行configure配置
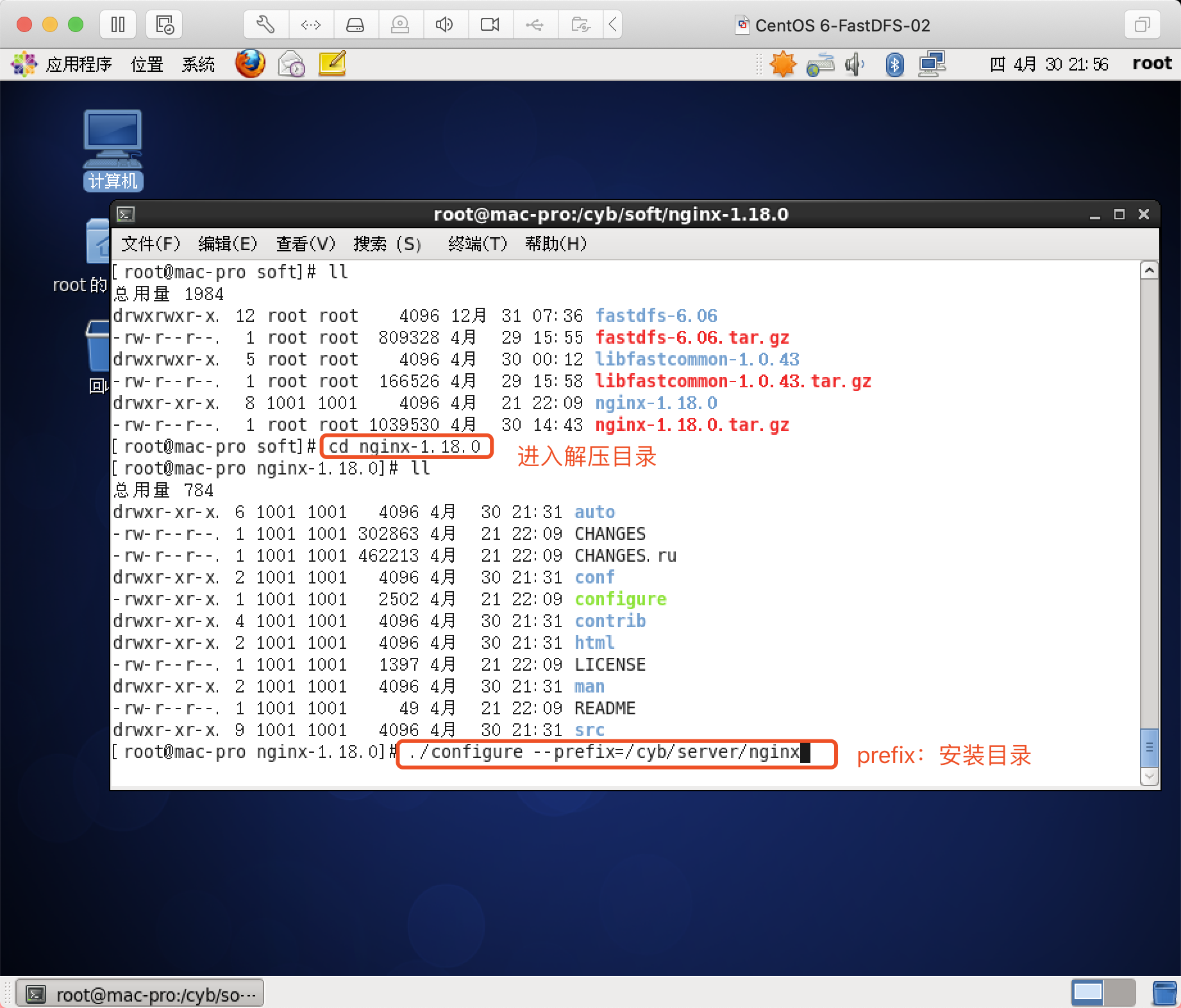
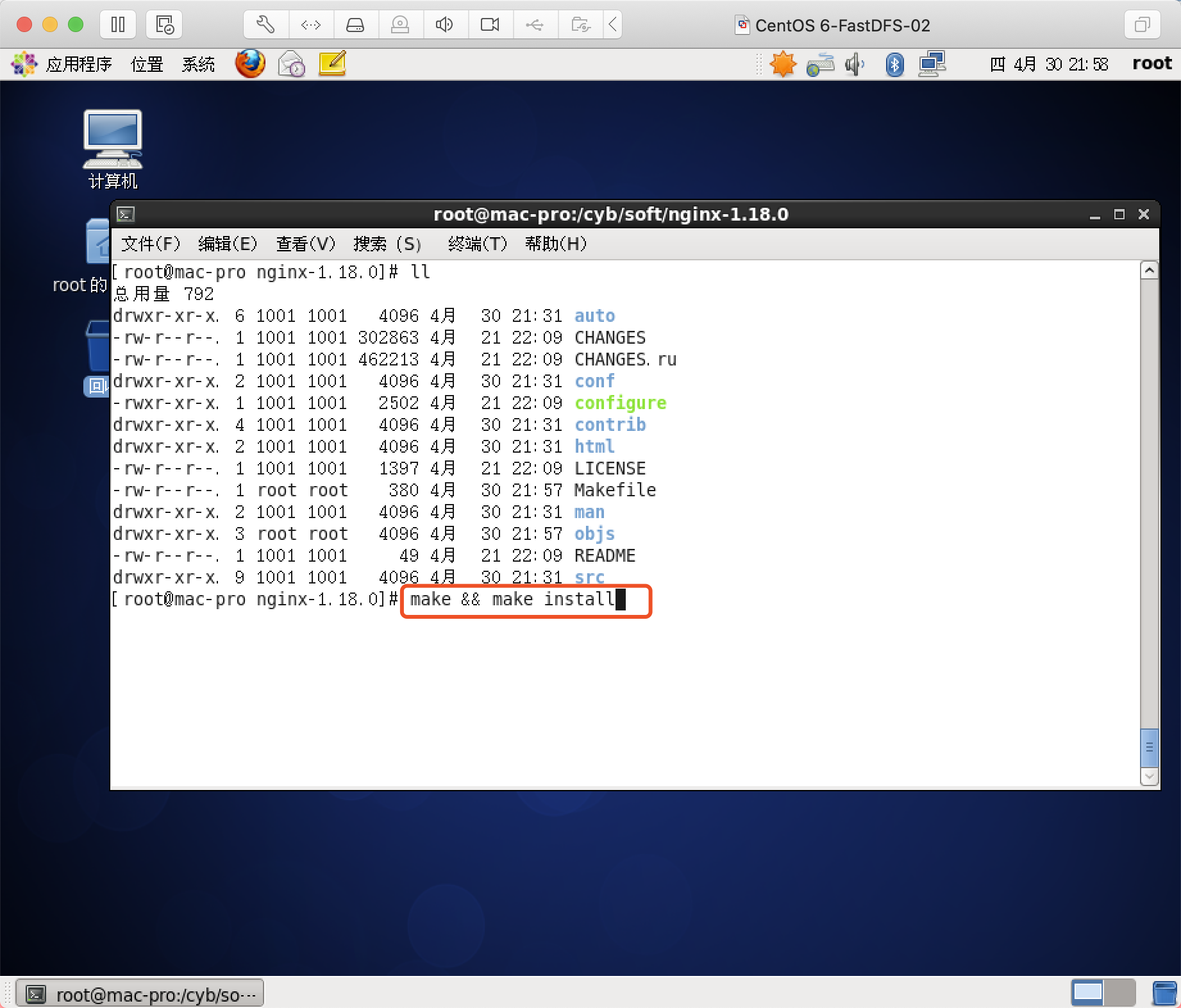
编译与安装
修改nginx.conf
vim /cyb/server/nginx/conf/nginx.conf
注:我的nginx.conf里面内容比较少,是因为我把没用到的东西删掉了!~
建立软链接
ln -n /cyb/server/nginx/sbin/nginx /usr/local/sbin
注:建立完软链接之后,就可以在任意位置执行
启动nginx
注:启动前,可以先执行下:nginx -tq,看会不会报错,没报错,说明nginx.conf配置文件,配置的参数是正确的
nginx
测试
到目前为止,nginx已经可以正常访问FastDFS上传的文件内容了。
FastDFS-Nginx配置扩展模块(重要)
采坑之路
nginx如果在原来的基础模块上,追加新模块,重新编译,原先的不会覆盖,我不知道是版本的原因还是怎么回事,我的解决方案就是把原先的nginx,先删掉,在重新一次性编译与安装。
rm -rf /etc/nginx/ --nginx的安装目录
rm -rf /usr/sbin/nginx 如果建立软连接的话,别忘记一块删了哦
rm -rf /usr/local/sbin/nginx
背景
上面示例,FastDFS上传的文件,已经可以通过nginx正常访问了,为什么还要使用Nginx扩展模块来访问存储文件呢?
- 如果进行文件合并,那么不使用FastDFS的Nginx扩展模块,是无法访问到具体的文件的,因为文件合并之后,多个小文件都是存储在一个trunk文件中的,在存储目录下,是看不到具体的小文件的。
- 如果文件未同步成功,那么不适用FastDFS的Nginx扩展模块,是无法正常访问到指定的文件的,而使用了FastDFS的Nginx扩展模块之后,如果要访问的文件未同步成功,那么会解析出来该文件的源存储服务器ip,然后将访问请求重定向或者代理到源存储服务器中进行访问。
下载文件
注:FastDFS的Nginx扩展模块需要安装到每个Storage Server中
github:https://github.com/happyfish100/fastdfs-nginx-module/releases/tag/V1.22
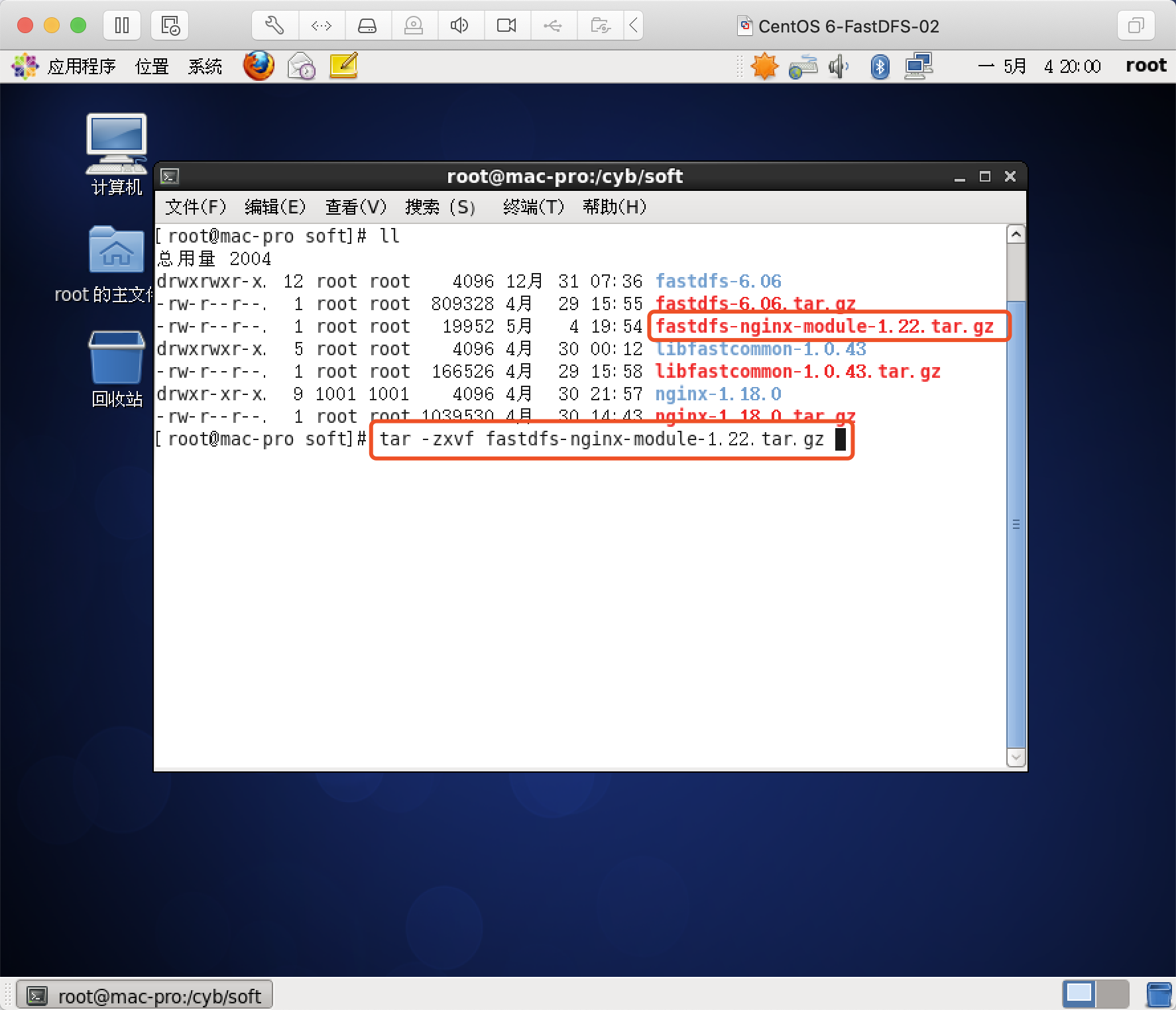
解压缩
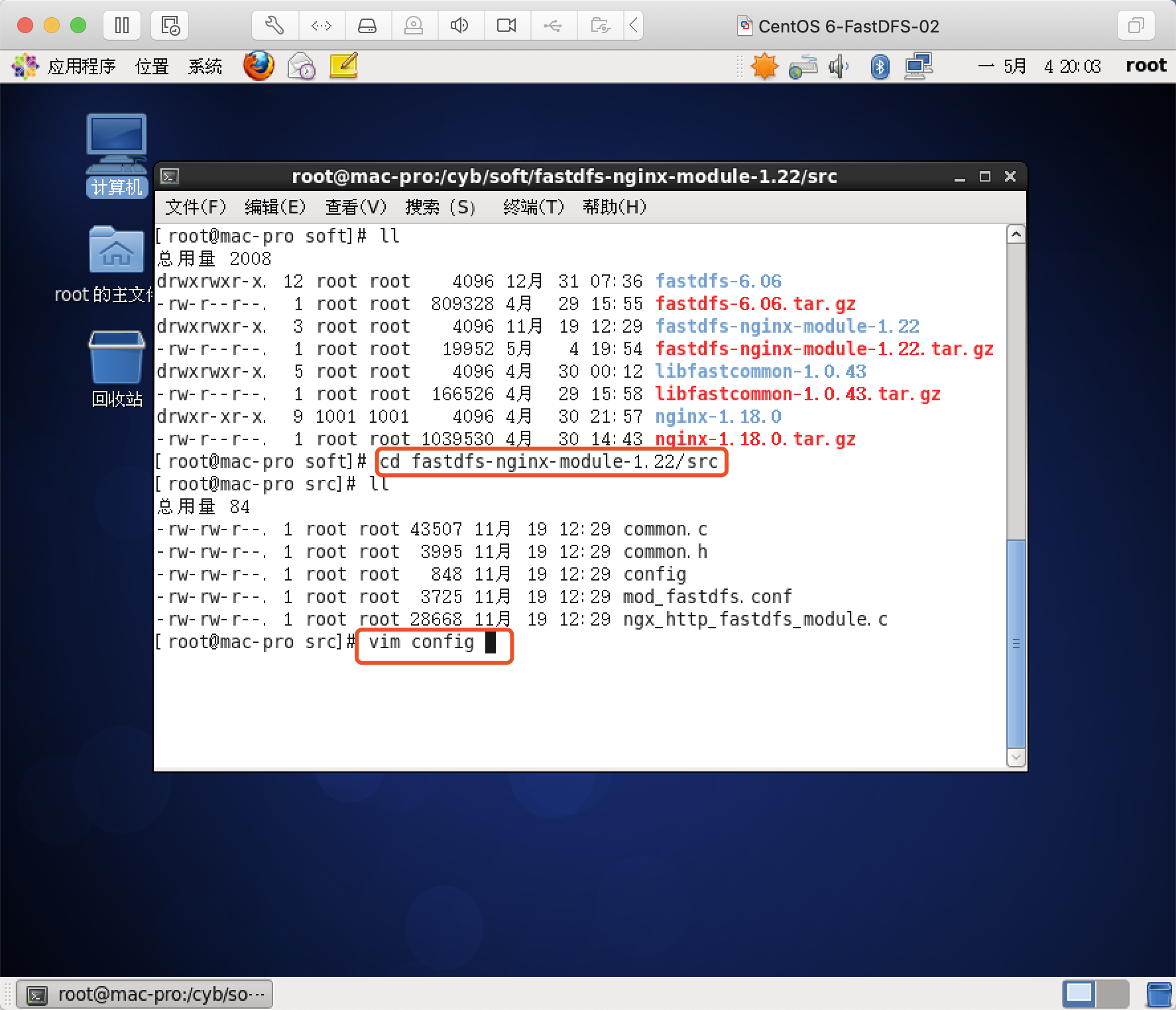
修改config文件(关键一步)
修改第6、15行的内容
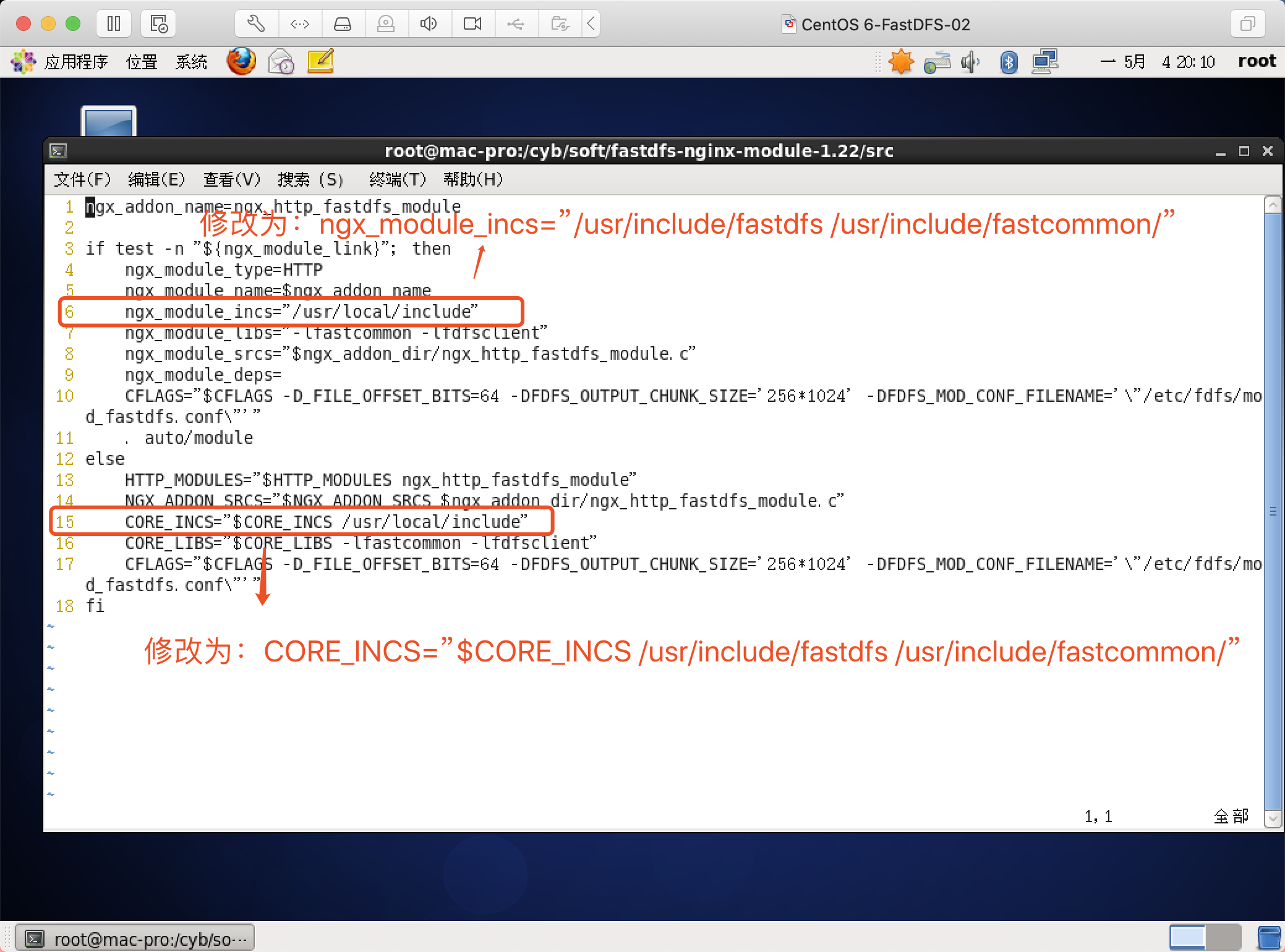
第6行:
ngx_module_incs="/usr/include/fastdfs /usr/include/fastcommon/" 第15行:
CORE_INCS="$CORE_INCS /usr/include/fastdfs /usr/include/fastcommon/"
拷贝mod_fastdfs.conf
将/cyb/soft/fastdfs-nginx-module-1.22/src/mod_fastdfs.conf拷贝至/etc/fdfs/下
cp /cyb/soft/fastdfs-nginx-module-1.22/src/mod_fastdfs.conf /etc/fdfs/
修改mod_fastdfs.conf
vim /etc/fdfs/mod_fastdfs.conf
base_path=/cyb/server/fastdfs/storage # 基础路径,存储日志文件
tracker_server=192.168.31.220:22122 # tracker服务器的ip
url_have_group_name=true # url中是否包含group名称
store_path0=/cyb/server/fastdfs/storage # 指定文件存储路径,访问时使用该路径
拷贝libfdfsclient.so(高版本可忽略)
cp /usr/lib64/libfdfsclient.so /usr/lib/
注:若/usr/lib/下已存在libfdfsclient.so,则此步骤可忽略!!!
执行configure配置

重新编译与安装
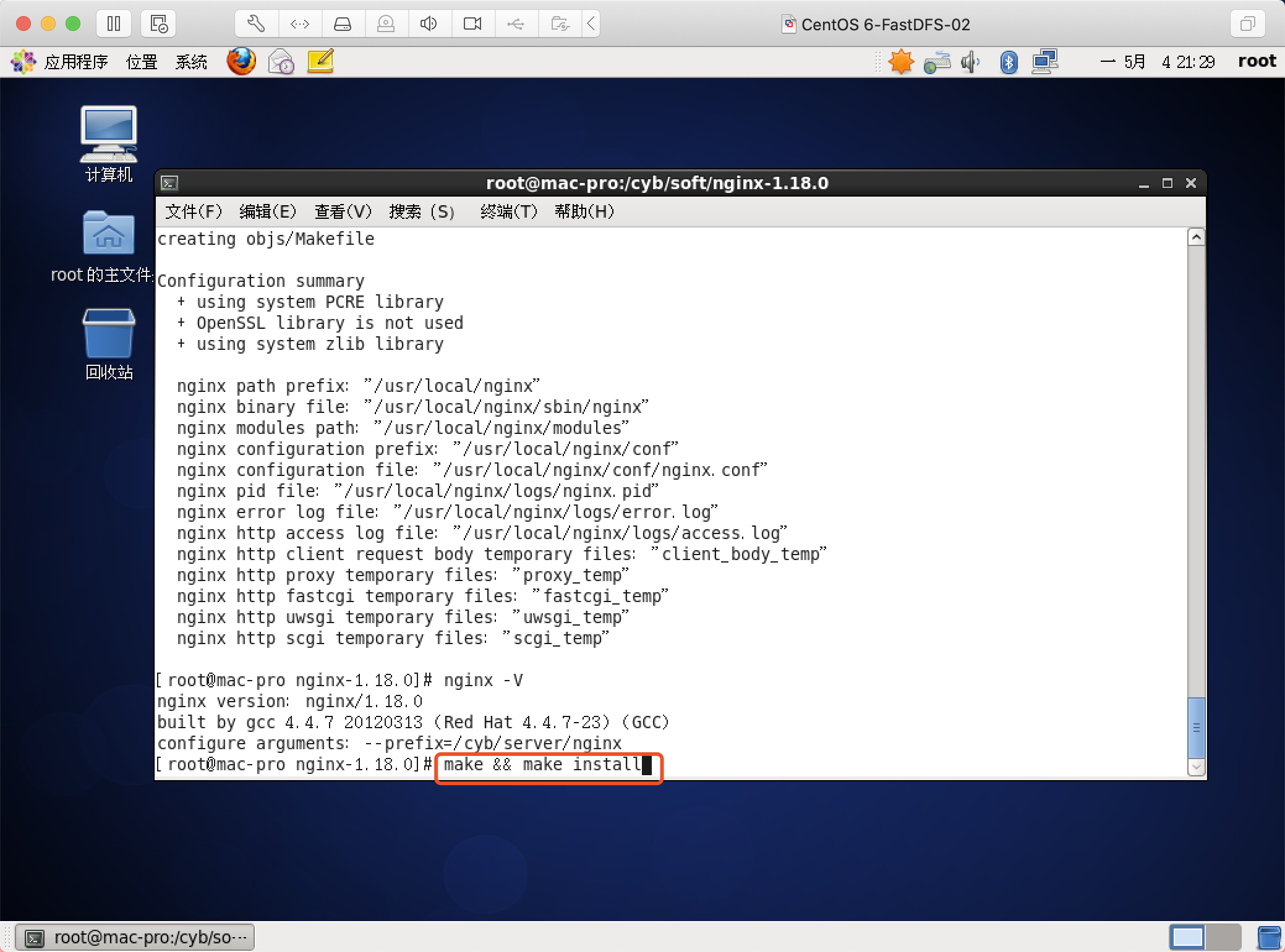
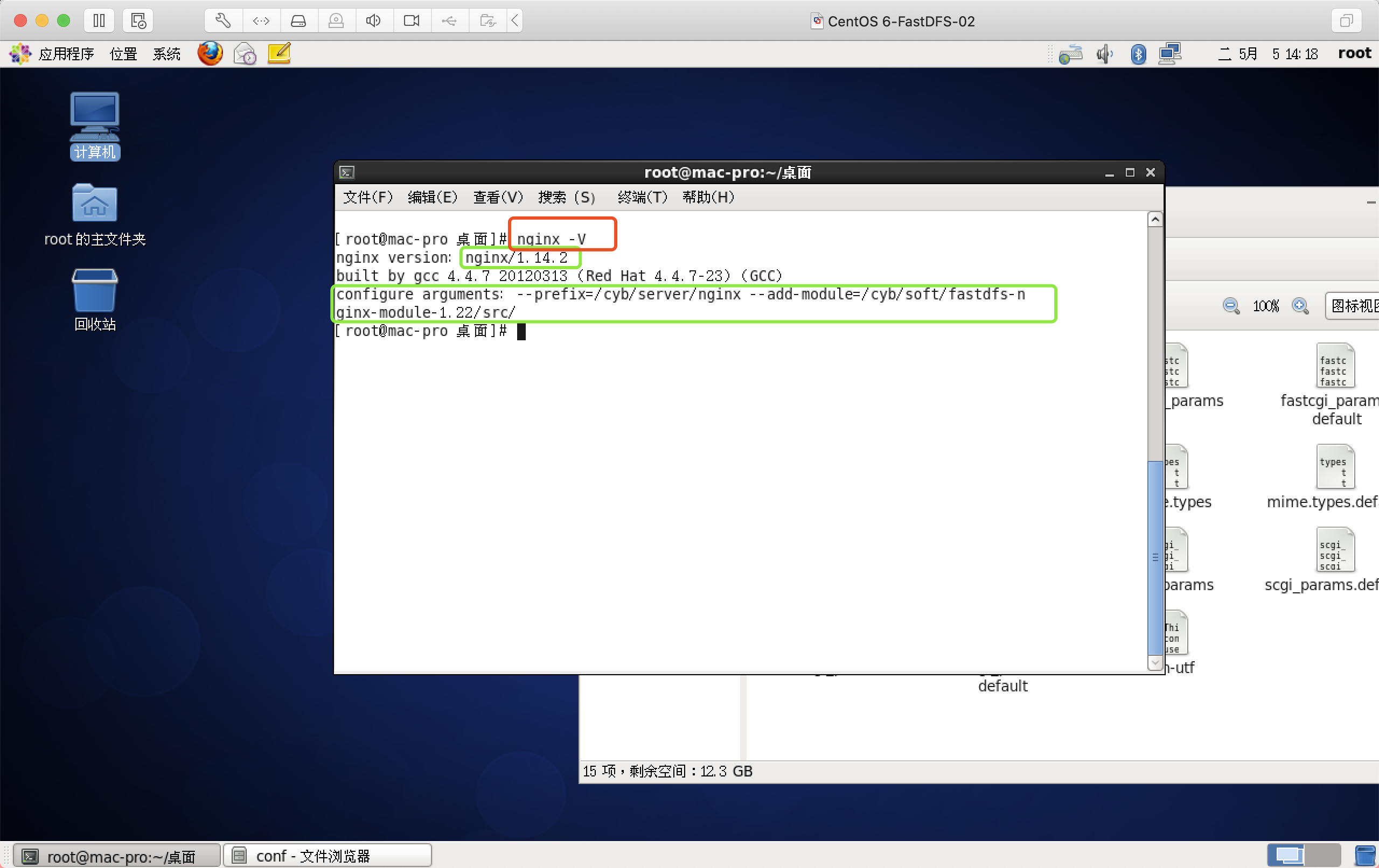
重启并查看扩展包
nginx -V --->V是大写的 显示--add-module,才代表安装模块成功,没成功的,请看我采坑之路介绍
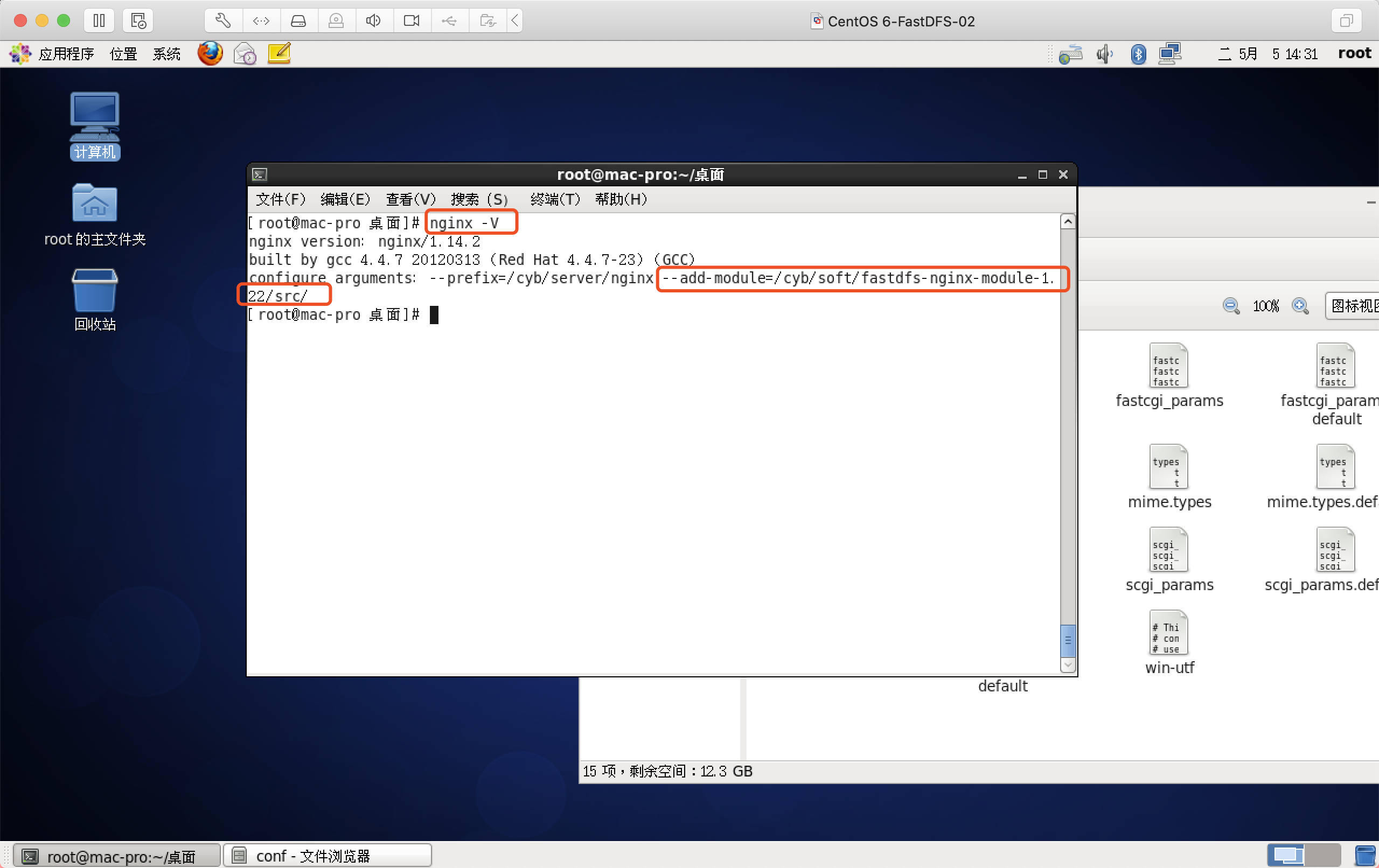
修改nginx.conf配置
搞定
一样可以正常访问
Java客户端
github下载
https://github.com/happyfish100/fastdfs-client-java/releases/tag/V1.26
如何打包,请看:https://www.cnblogs.com/chenyanbin/p/12831553.html
注意修改pom.xml中的<jdk.version>版本
Maven依赖
<!--fastdfs依赖-->
<dependency>
<groupId>org.csource</groupId>
<artifactId>fastdfs-client-java</artifactId>
<version>1.27-SNAPSHOT</version>
</dependency>
java项目结构
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.cyb</groupId>
<artifactId>fastdfs-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!--fastdfs依赖-->
<dependency>
<groupId>org.csource</groupId>
<artifactId>fastdfs-client-java</artifactId>
<version>1.27-SNAPSHOT</version>
</dependency>
</dependencies> </project>
fdfs_client.conf
tracker_server=192.168.31.220:22122
FastDFSClient.java
package com.cyb.fdfs.client; import org.csource.common.NameValuePair;
import org.csource.fastdfs.*;
import java.net.URLDecoder; public class FastDFSClient {
private static TrackerClient trackerClient = null;
private static TrackerServer trackerServer = null;
private static StorageServer storageServer = null;
private static StorageClient1 client = null;
// fdfsClient的配置文件路径
private static String CONF_NAME="/fdfs/fdfs_client.conf"; static {
try{
//配置恩建必须制定全路径
String confName=FastDFSClient.class.getResource(CONF_NAME).getPath();
//配置文件全路径如果有中文,需要进行utf8转码
confName= URLDecoder.decode(confName,"utf8"); ClientGlobal.init(confName);
trackerClient=new TrackerClient();
trackerServer=trackerClient.getConnection();
storageServer=null;
client=new StorageClient1(trackerServer,storageServer);
}
catch (Exception e){
e.printStackTrace();
}
} /**
* 上传文件方法
* @param fileName 文件全路径
* @param extName 文件扩展名,不包含(.)
* @param metas 文件扩展信息
* @return
* @throws Exception
*/
public static String uploadFile(String fileName, String extName, NameValuePair[] metas) throws Exception{
String result = client.upload_file1(fileName, extName, metas);
System.out.println(result);
return result;
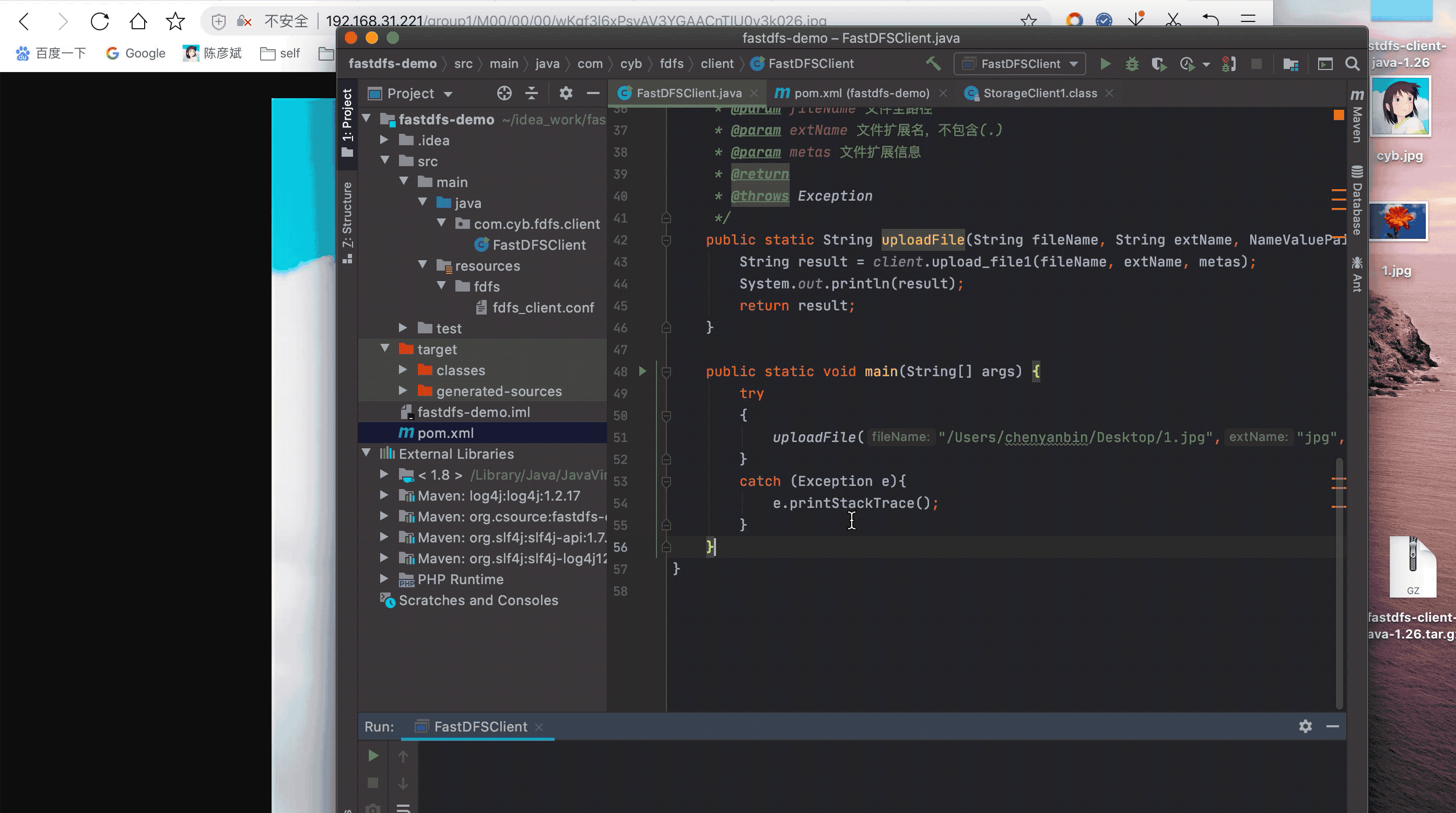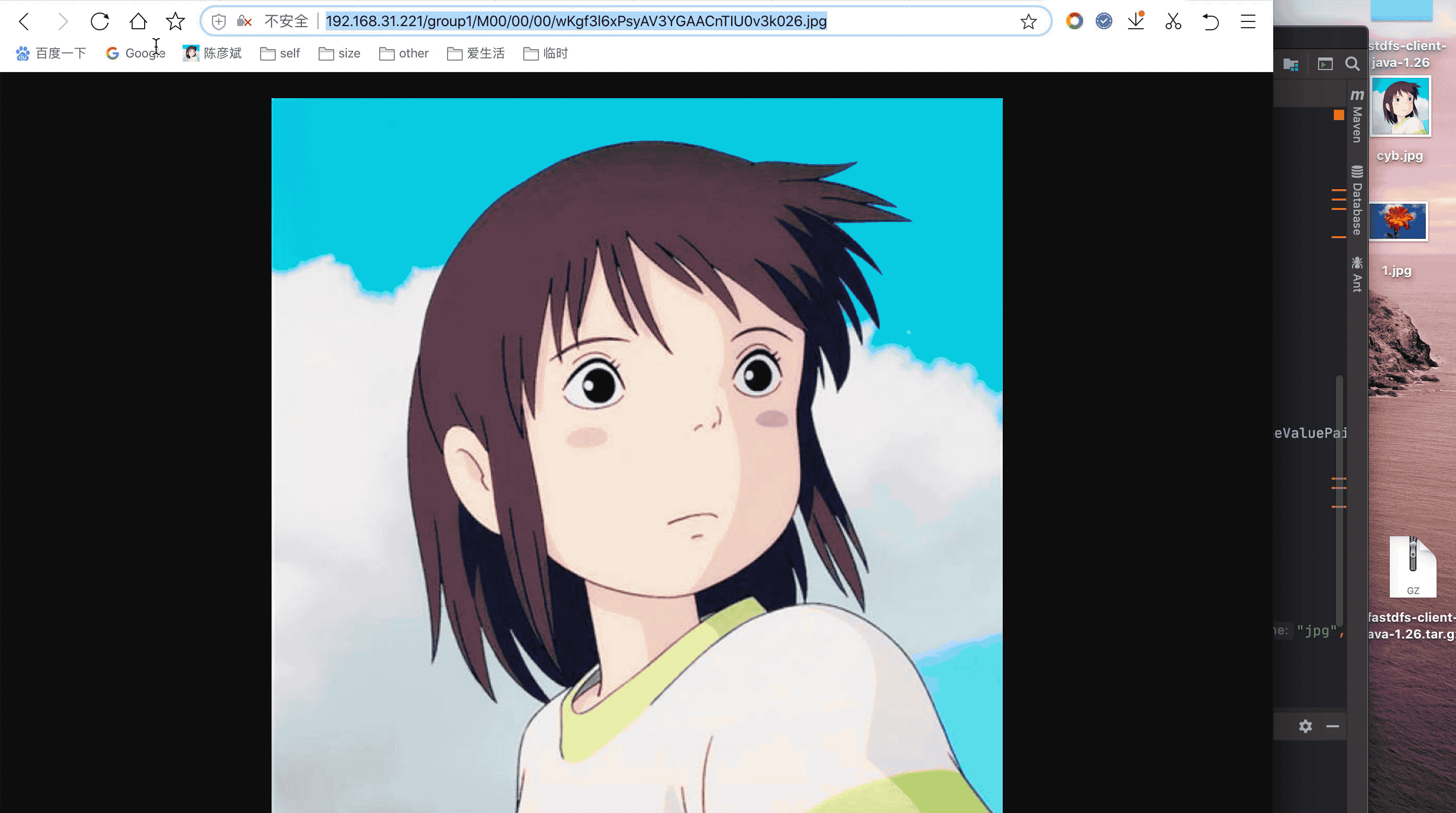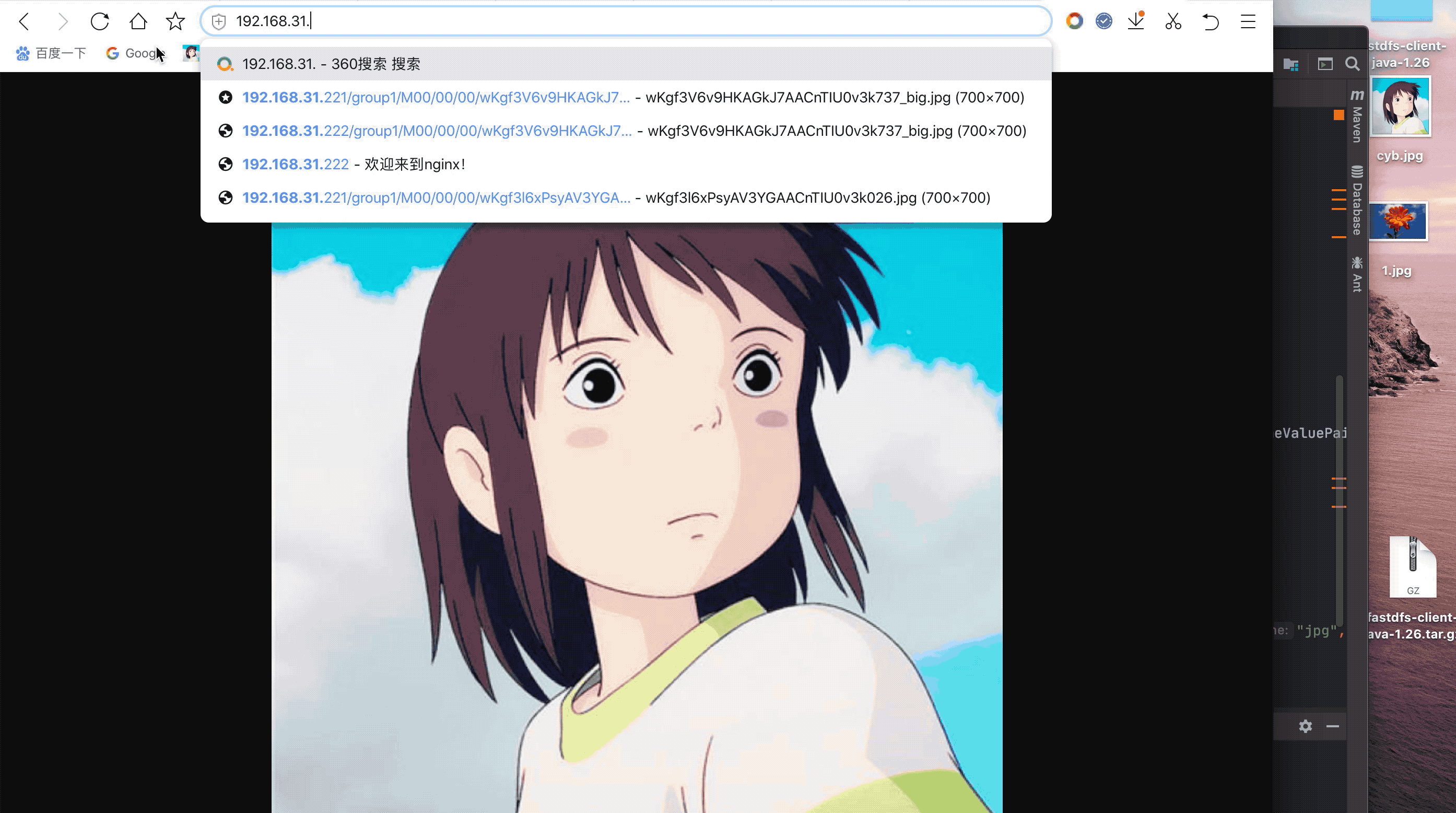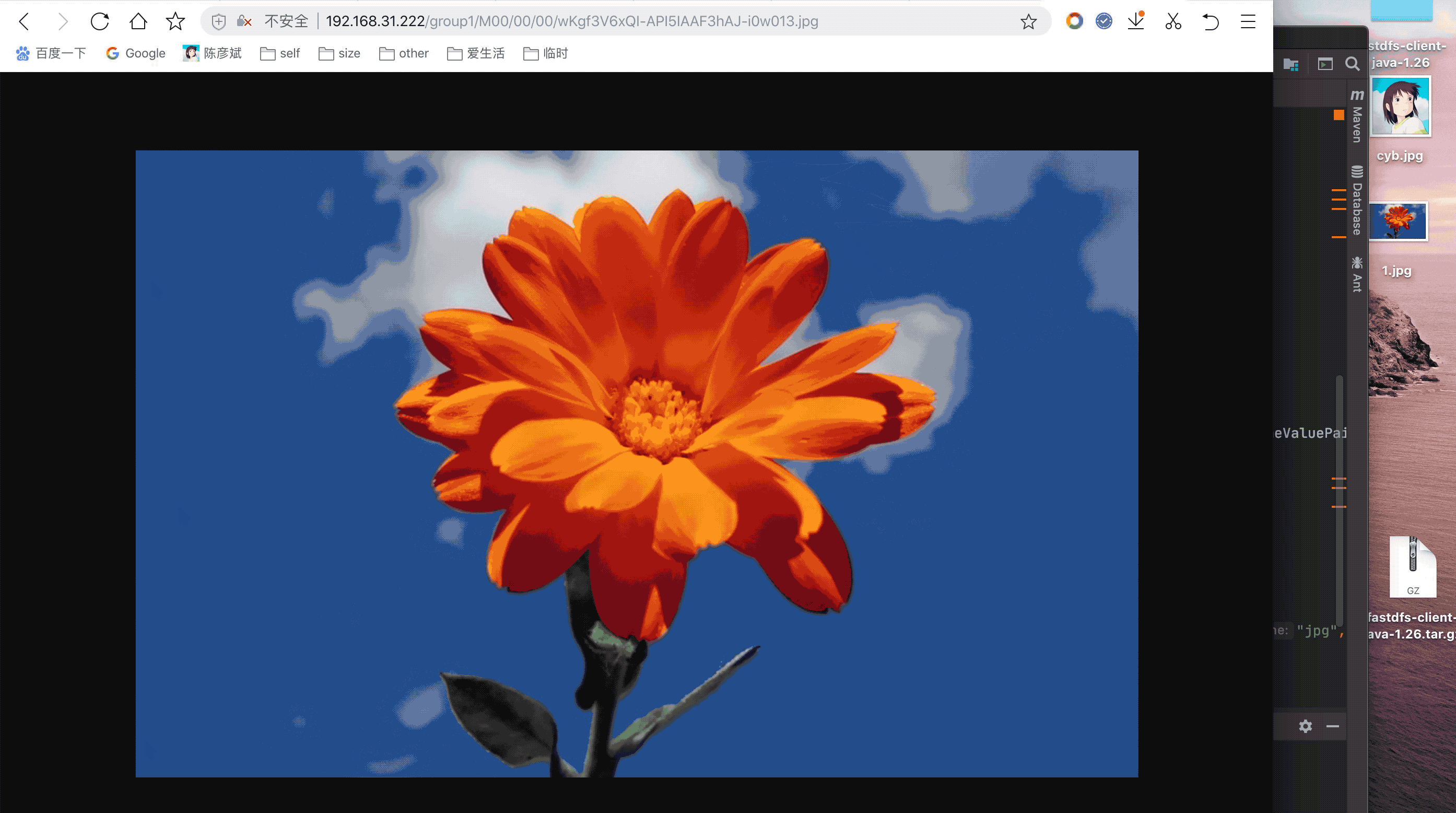
} public static void main(String[] args) {
try
{
uploadFile("/Users/chenyanbin/Desktop/1.jpg","jpg",null);
}
catch (Exception e){
e.printStackTrace();
}
}
}
注:这次我只写了一个上传的,他会返回一直String字符串,也就是文件存储的位置,前面在追加ip,拼成url,直接可以访问,这里的client还有其他API,自行查阅,client.API
测试
上传本地的1.jpg,然后通过ip+返回字符串,拼成url访问
项目与maven依赖源码下载
链接: https://pan.baidu.com/s/11kZfO_MRvwErnseWSVgSog 密码: d0pp
maven源码包,需要重新编译
合并存储(重要)
简介
在处理海量小文件问题上,文件系统处理性能会受到显著的影响,在读此书(IOPS)与吞吐量(Throughput)这两个指标上会有不少的下降。主要需要面对如下几个问题
- 元数据管理低效,磁盘文件系统中,目录项(dentry)、索引节点(inode)和数据(data)保存在介质的不同位置上。因此,访问一个文件需要经历至少3次独立的访问。这样,并发小文件访问就转变成了大量的随机访问,而这种访问广泛使用的磁盘来说是非常低效的
- 数据布局低效
- IO访问流程复杂,因此一种解决途径就是将小文件合并存储成大文件,使用seek来定位到大文件的指定位置来访问该小文件。
注:
FastDFS提供的合并存储功能,默认创建的大文件为64MB,然后在该大文件中存储很多小文件。大文件中容纳一个小文件的空间称为一个Slot,规定Slot最小值为256字节,最大为16MB,也就是小于256字节的文件也需要占用256字节,超过16MB的文件不会合并存储而是创建独立的文件。
合并存储配置
FastDFS提供了合并存储功能,所有的配置在tracker.conf文件之中,开启合并存储只需要设置比:use_trunk_file=true 和store_server=1
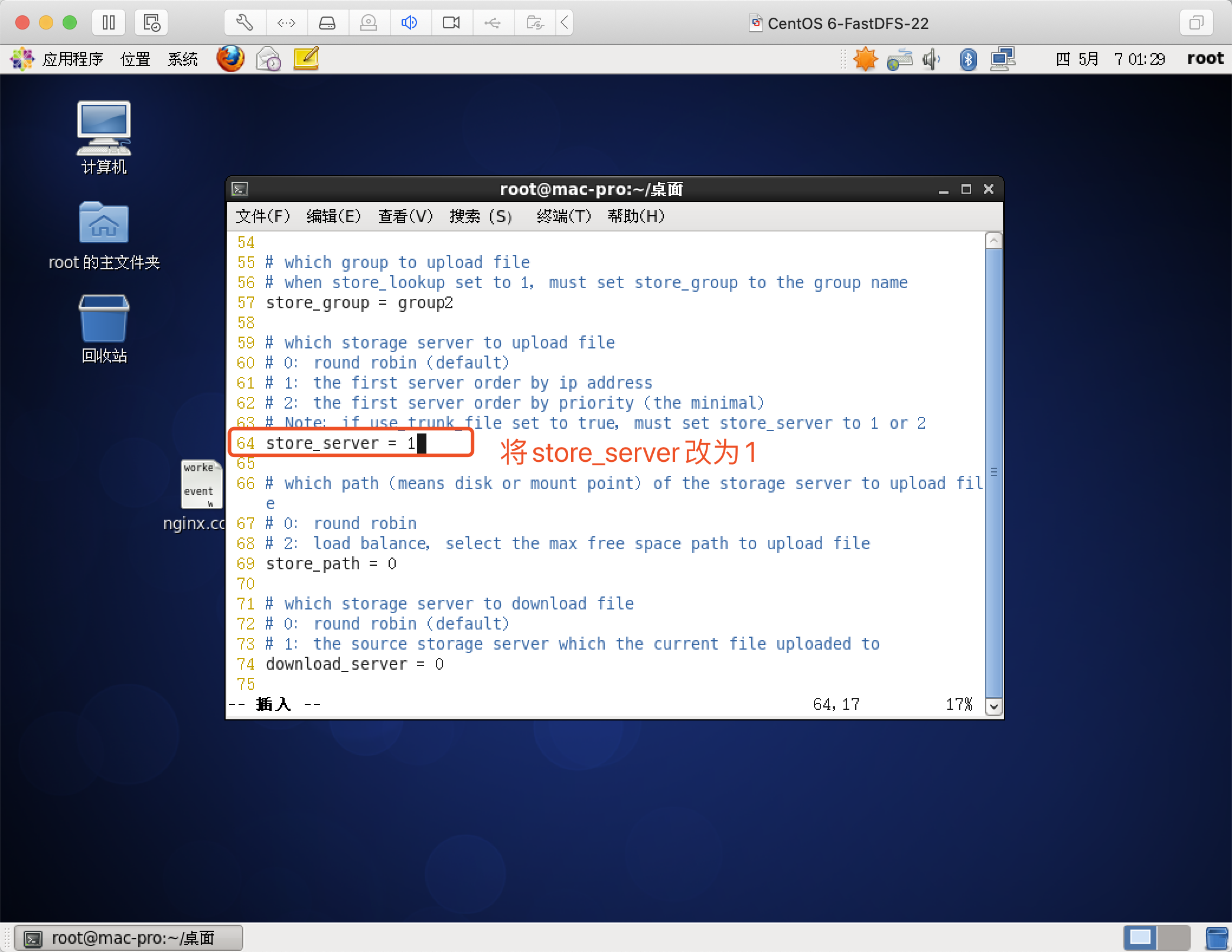
修改tracker.conf(修改的tracker服务器)
vim /etc/fdfs/tracker.conf
store_server改为1
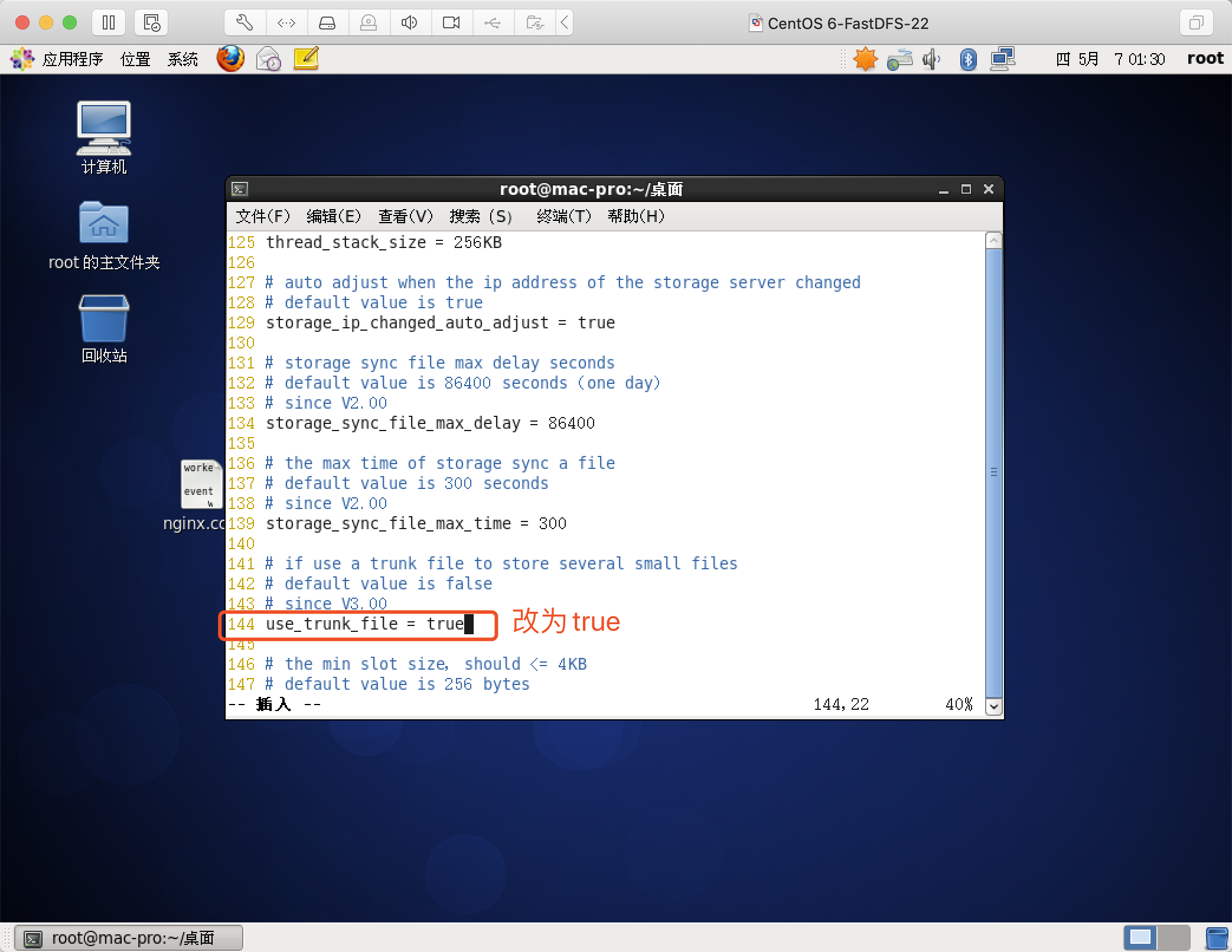
use_trunk_file改true
重启tracker
/usr/bin/fdfs_trackerd /etc/fdfs/tracker.conf restart
存储缩略图
FastDFS主从文件
应用背景
使用FastDFS存储一个图片的多个分辨率的备份时,希望只记录源图的fileid,并能将其分辨率的图片与源图关联。可以使用从文件方法
解决办法
名词注解:主从文件是指文件ID有关联的文件,一个主文件可以对应多个从文件。
- 主文件ID=主文件名+主文件扩展名
- 从文件ID=主文件名+从文件后缀名(如:200*200)+从文件扩展名
流程说明
1、先上传主文件(既:源文件,得到主文件FID)
2、然后上传从文件(既:缩略图),指定主文件FID和从文件后缀名,上传后得到从文件FID
java客户端方式(不推荐)
package com.cyb.fdfs.client; import com.sun.tools.corba.se.idl.StringGen;
import org.csource.common.NameValuePair;
import org.csource.fastdfs.*; import java.net.URLDecoder; public class FastDFSClient2 {
private static TrackerClient trackerClient = null;
private static TrackerServer trackerServer = null;
private static StorageServer storageServer = null;
private static StorageClient1 client = null;
// fdfsClient的配置文件路径
private static String CONF_NAME = "/fdfs/fdfs_client.conf"; static {
try {
//配置恩建必须制定全路径
String confName = FastDFSClient2.class.getResource(CONF_NAME).getPath();
//配置文件全路径如果有中文,需要进行utf8转码
confName = URLDecoder.decode(confName, "utf8"); ClientGlobal.init(confName);
trackerClient = new TrackerClient();
trackerServer = trackerClient.getConnection();
storageServer = null;
client = new StorageClient1(trackerServer, storageServer);
} catch (Exception e) {
e.printStackTrace();
}
} /**
* 上传主文件
*
* @param filePath
* @return 主文件ID
* @throws Exception
*/
public static String uploadFile(String filePath) throws Exception {
String fileId = "";
String fileExtName = "";
if (filePath.contains(".")) {
fileExtName = filePath.substring(filePath.lastIndexOf(".")+1);
} else {
return fileId;
}
try {
fileId = client.upload_file1(filePath, fileExtName, null);
} catch (Exception e) {
e.printStackTrace();
} finally {
trackerServer.close();
}
return fileId;
} /**
* 上传从文件
*
* @param masterFileId FastDFS服务器返回的主文件的fileid
* @param prefixName 从文件后缀名(如:_200*200)
* @param slaveFilePath 从文件所在路径(主从文件在本地都需要有对应的文件)
* @return
* @throws Exception
*/
public static String uploadSlaveFile(String masterFileId, String prefixName, String slaveFilePath) throws Exception { String slaveFileId = "";
String slaveFileExtName = "";
if (slaveFilePath.contains(".")) {
slaveFileExtName = slaveFilePath.substring(slaveFilePath.lastIndexOf(".") + 1);
} else {
return slaveFileId;
}
try {
slaveFileId = client.upload_file1(masterFileId, prefixName, slaveFilePath, slaveFileExtName, null);
} catch (Exception e) {
e.printStackTrace();
} finally {
trackerServer.close();
}
return slaveFileId;
} public static int download(String fileId, String localFile) throws Exception {
int result = 0;
//建立连接
TrackerClient tracker = new TrackerClient();
TrackerServer trackerServer = tracker.getConnection();
StorageServer storageServer = null;
StorageClient1 client = new StorageClient1(trackerServer, storageServer);
//上传文件
try {
result = client.download_file1(fileId, localFile);
} catch (Exception e) {
e.printStackTrace();
} finally {
trackerServer.close();
}
return result;
} public static void main(String[] args) {
try {
//上传主文件
String masterFileId=uploadFile("/Users/chenyanbin/Desktop/1.jpg");
System.out.println("主文件:"+masterFileId);
//下载上传成功的主文件
download(masterFileId,"/Users/chenyanbin/Desktop/11.jpg");
//第三个参数:待上传的从文件(由此可知道,还需要把之前的下载,在本地生成后,在上传)
String slaveFileId=uploadSlaveFile(masterFileId,"_120x120","/Users/chenyanbin/Desktop/2.jpg");
System.out.println("从文件:"+slaveFileId);
//下载上传成功的缩略图
download(slaveFileId,"/Users/chenyanbin/Desktop/22.jpg");
} catch (Exception e) {
e.printStackTrace();
}
}
}
Nginx生成缩略图(推荐)
image_filter模块
nginx_http_image_filter_module在nginx 0.7.54以后才出现的,用于对jpeg、gif和png图片进行转换处理(压缩、裁剪、旋转)。这个模块默认不被编译,所以要在编译nginx源码的时候,加入相关配置信息
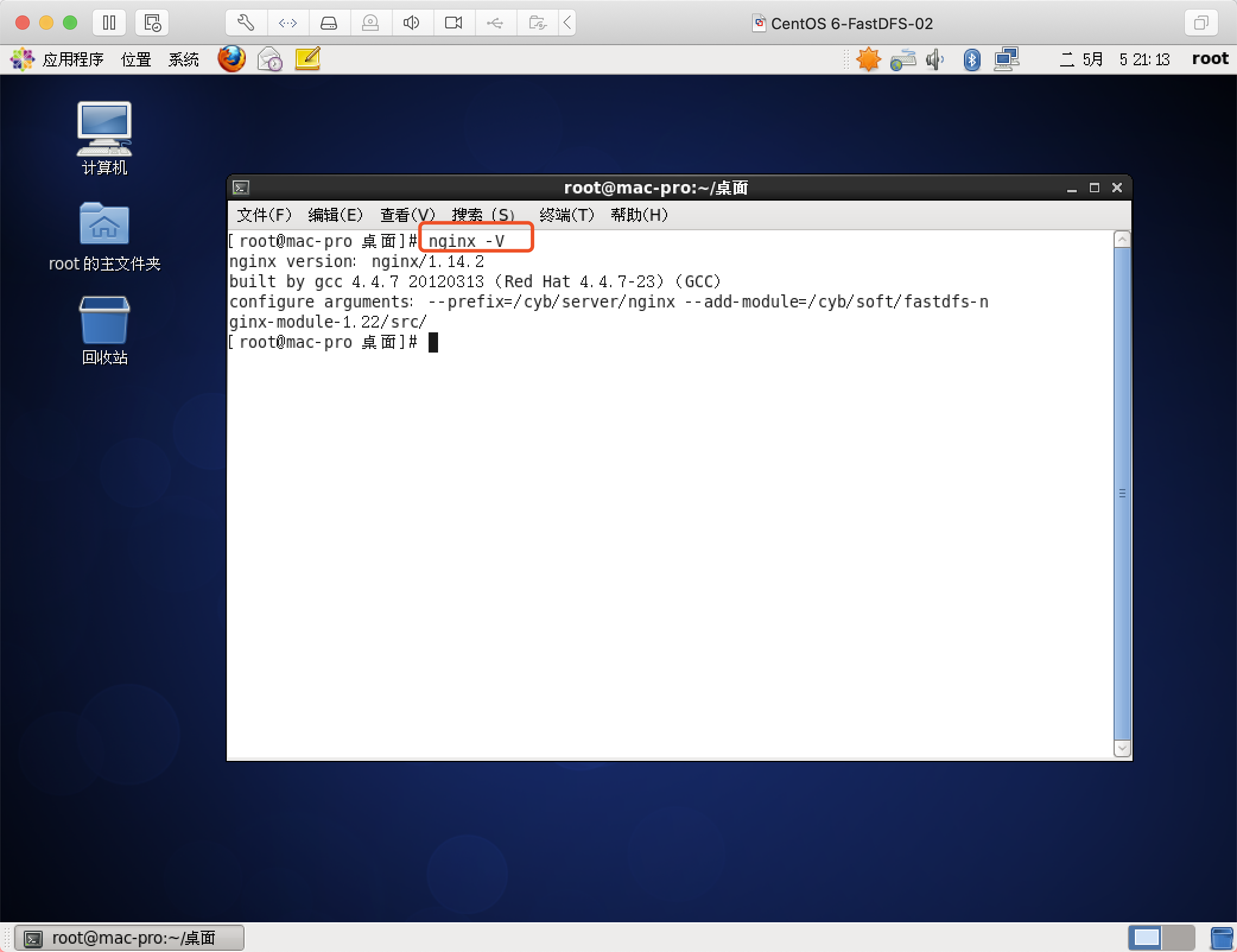
检测nginx模块安装情况
安装步骤
安装gd,HttpImageFilterModule模块需要依赖gd-devel的支持
yum -y install gd-devel
在原来模块基础上追加
--with-http_image_filter_module
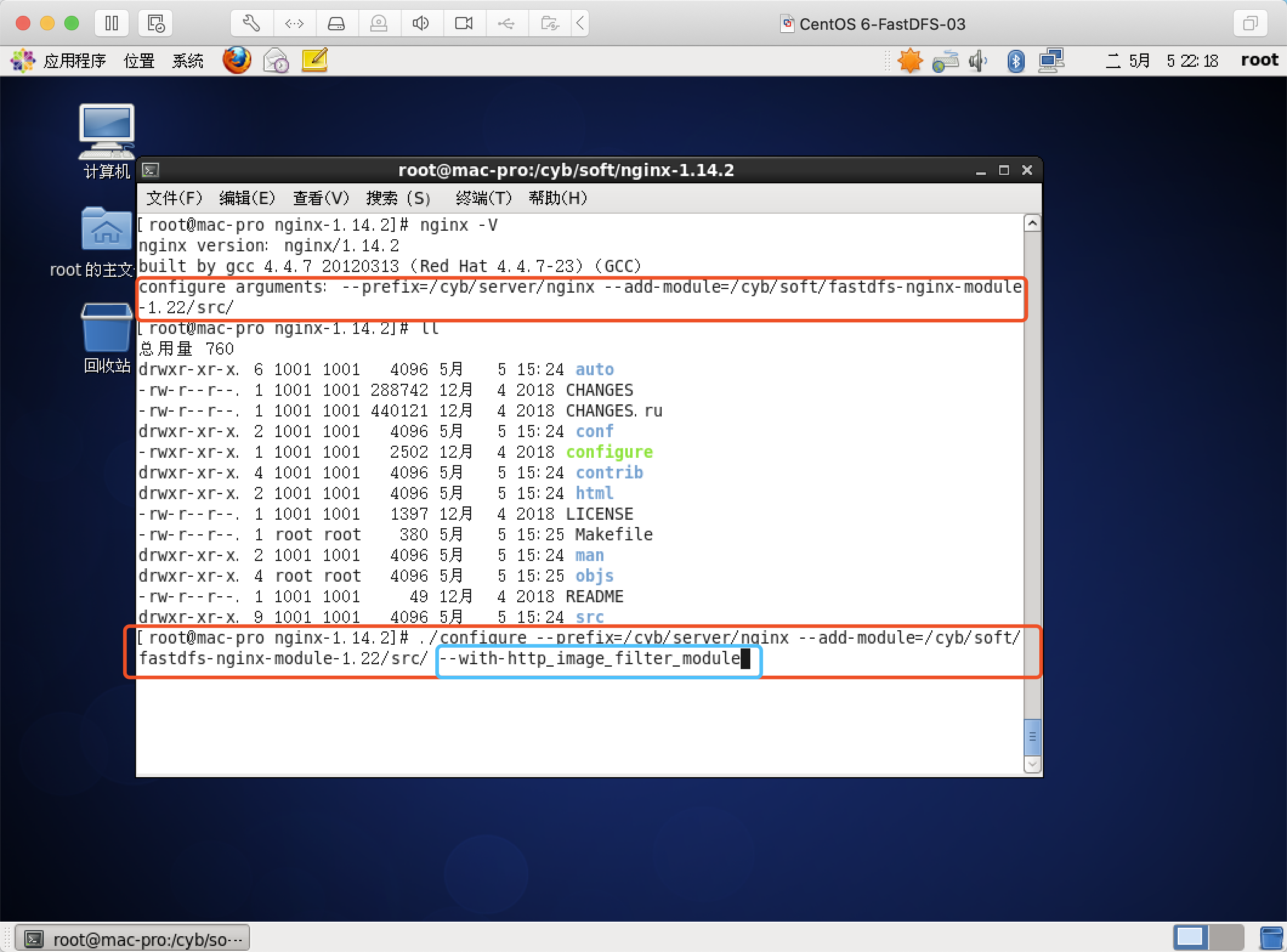
访问普通图片
需求,假设我们图片的真实路径是在本地/cyb/data/img/1.jpg,下面有狠毒ojpg格式的图片,我们希望通过访问/img/1_100x100.jpg这样的请求路径可以生成宽为100,高也为100的小图,并且请求的宽和高是可变的,那么这时候需要在nginx模块中拦截请求并返回转换后的小图,在对应server{}段中进行配置。
nginx.conf配置如下
location ~* /img/(.*)_(\d+)x(\d+)\.(jpg|gif|png)$ {
root /;
set $s $1;
set $w $2;
set $h $3;
set $t $4;
image_filter resize $w $h;
image_filter_buffer 10M;
rewrite ^/img/(.*)$ /cyb/data/img/$s.$t break;
}
旋转:image_filter_rotate 度数;
image_filter rotate 90; --旋转90度
image_filter rotate 180; --旋转180度 裁剪:image_filter crop width height;
image_filter crop 120 60; --裁剪成宽120,高60
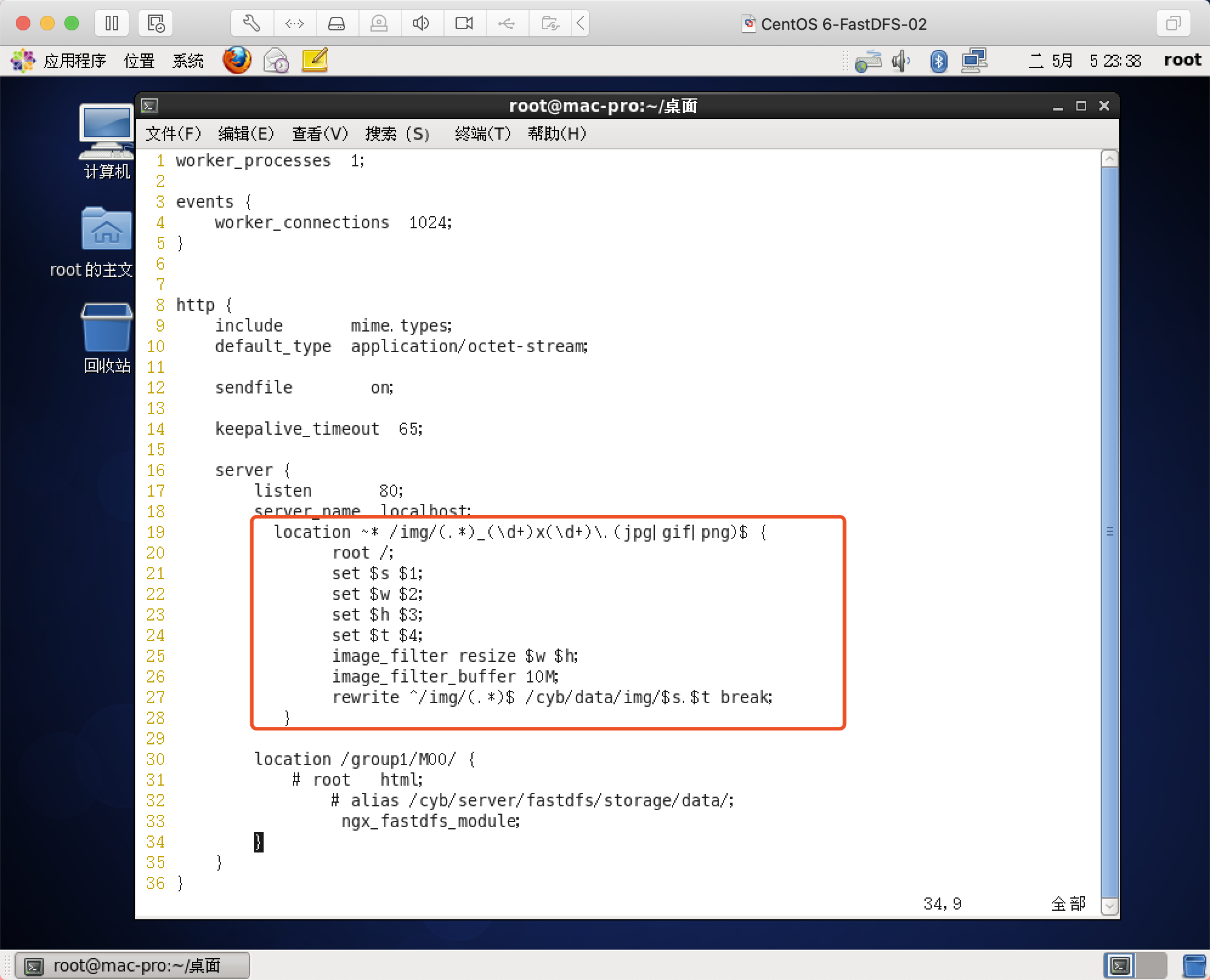
然后在/cyb/data/img/下存放一张图片
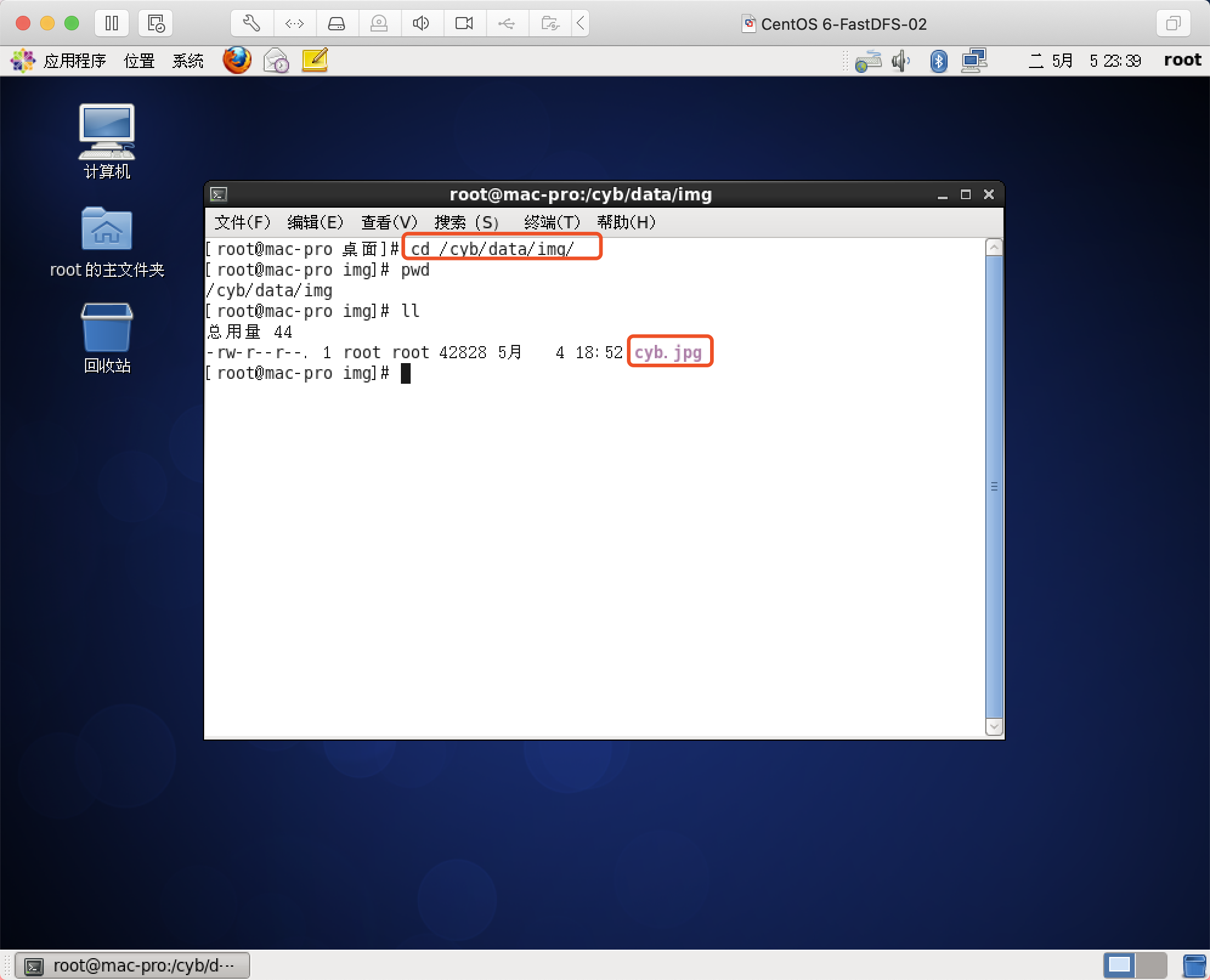
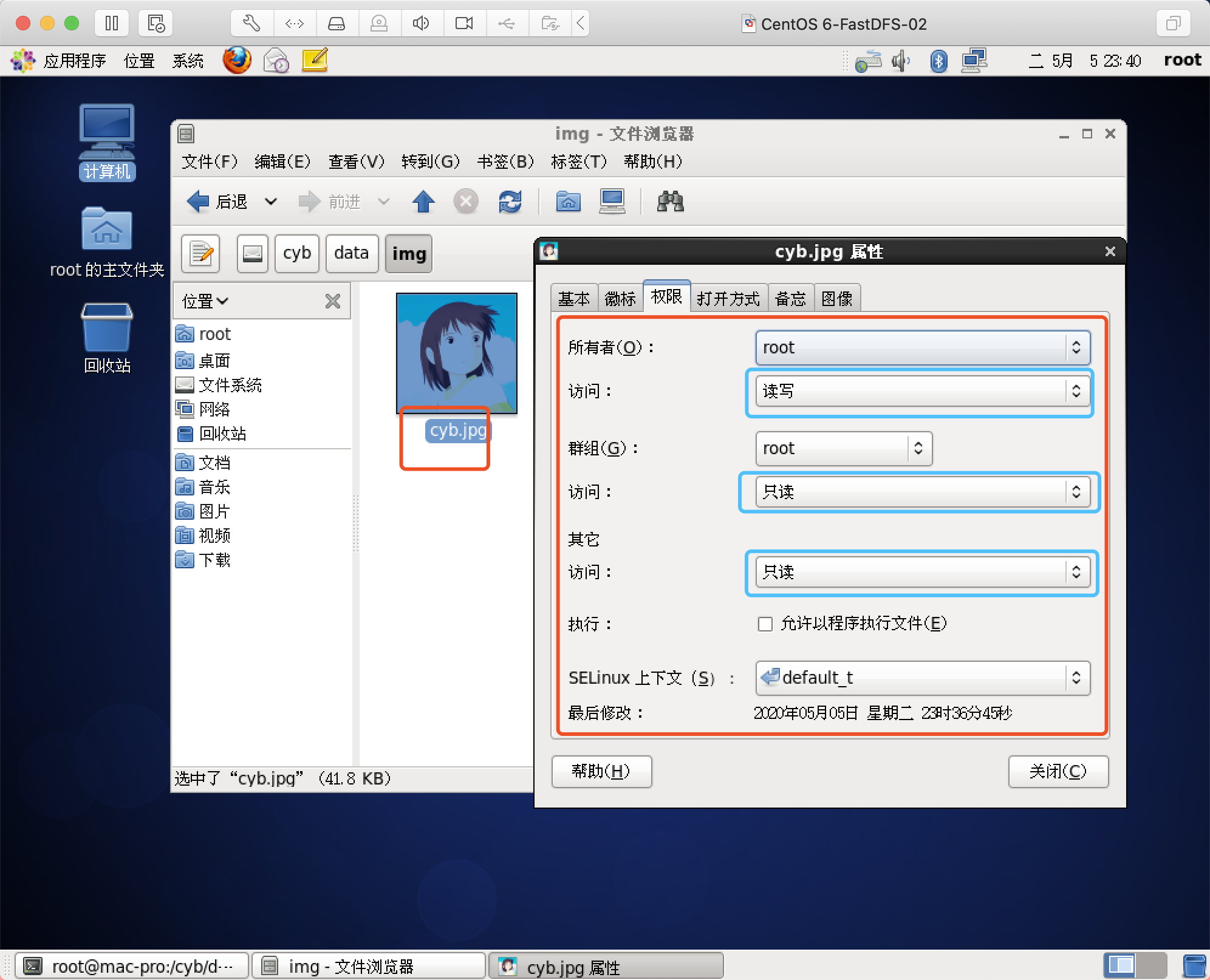
注意:该图片一定要有读取权限,要不然nginx是读取不到的!!!
关闭nginx,并重启(平滑重启没用)
nginx -s stop
nginx
测试(普通图片)
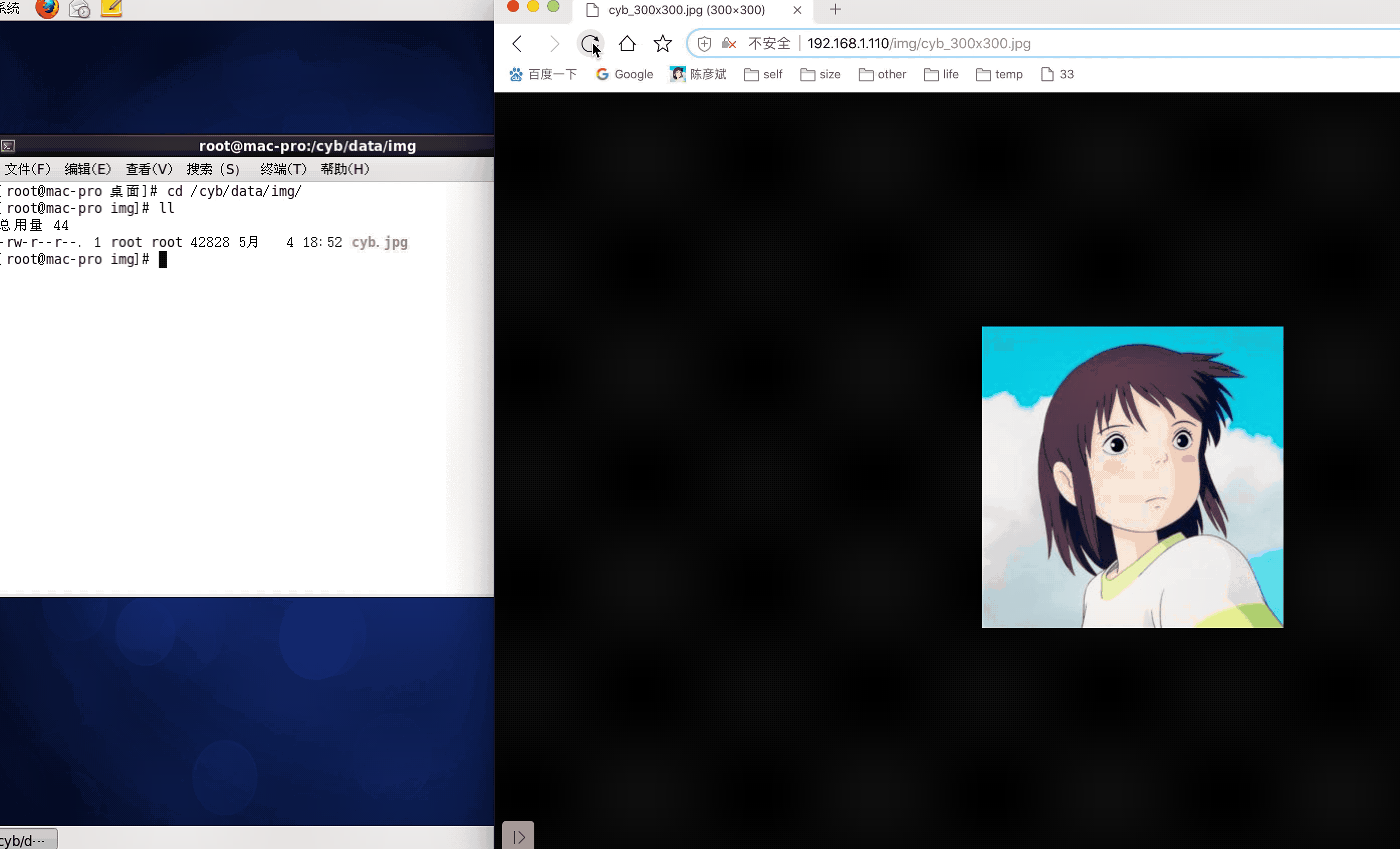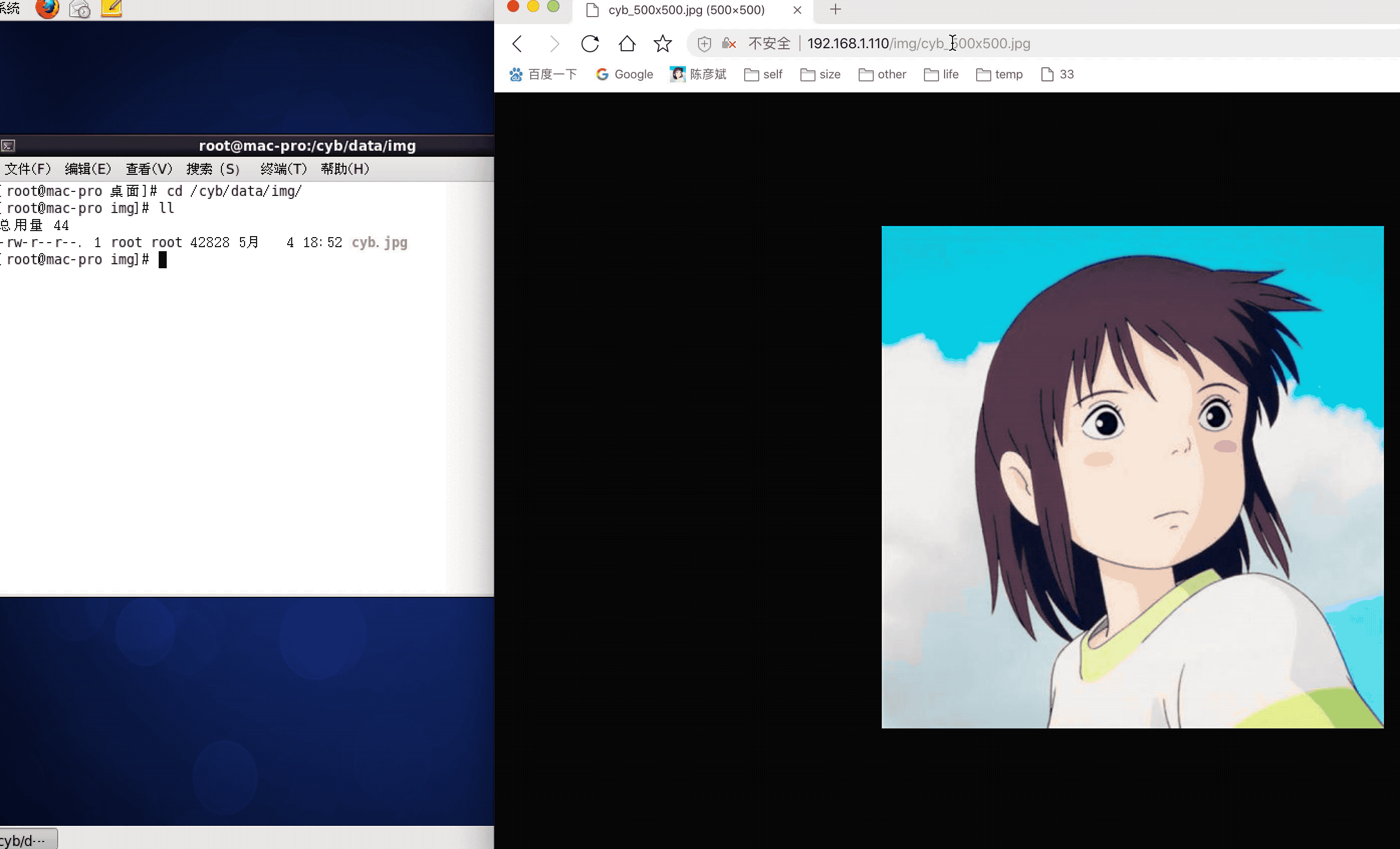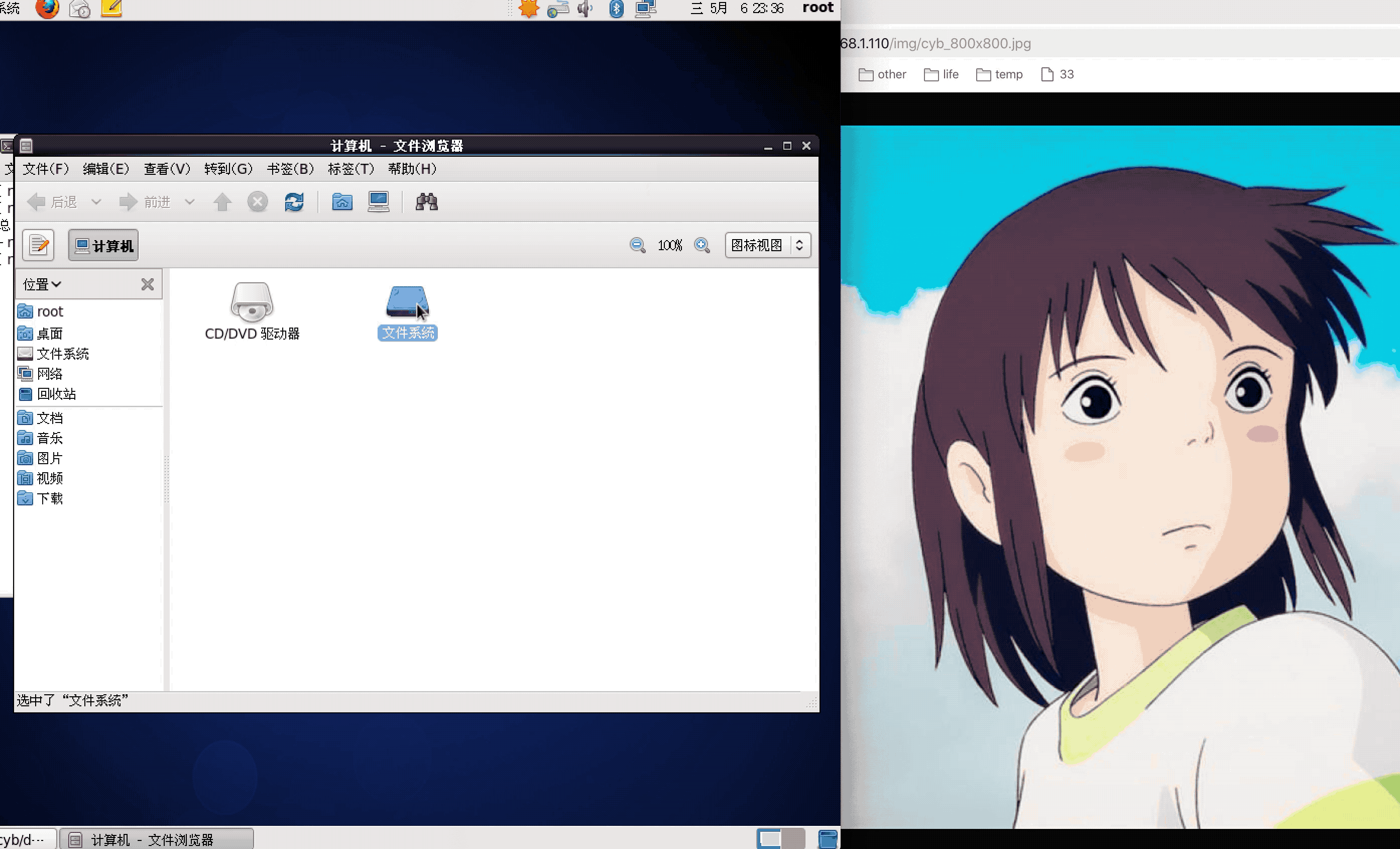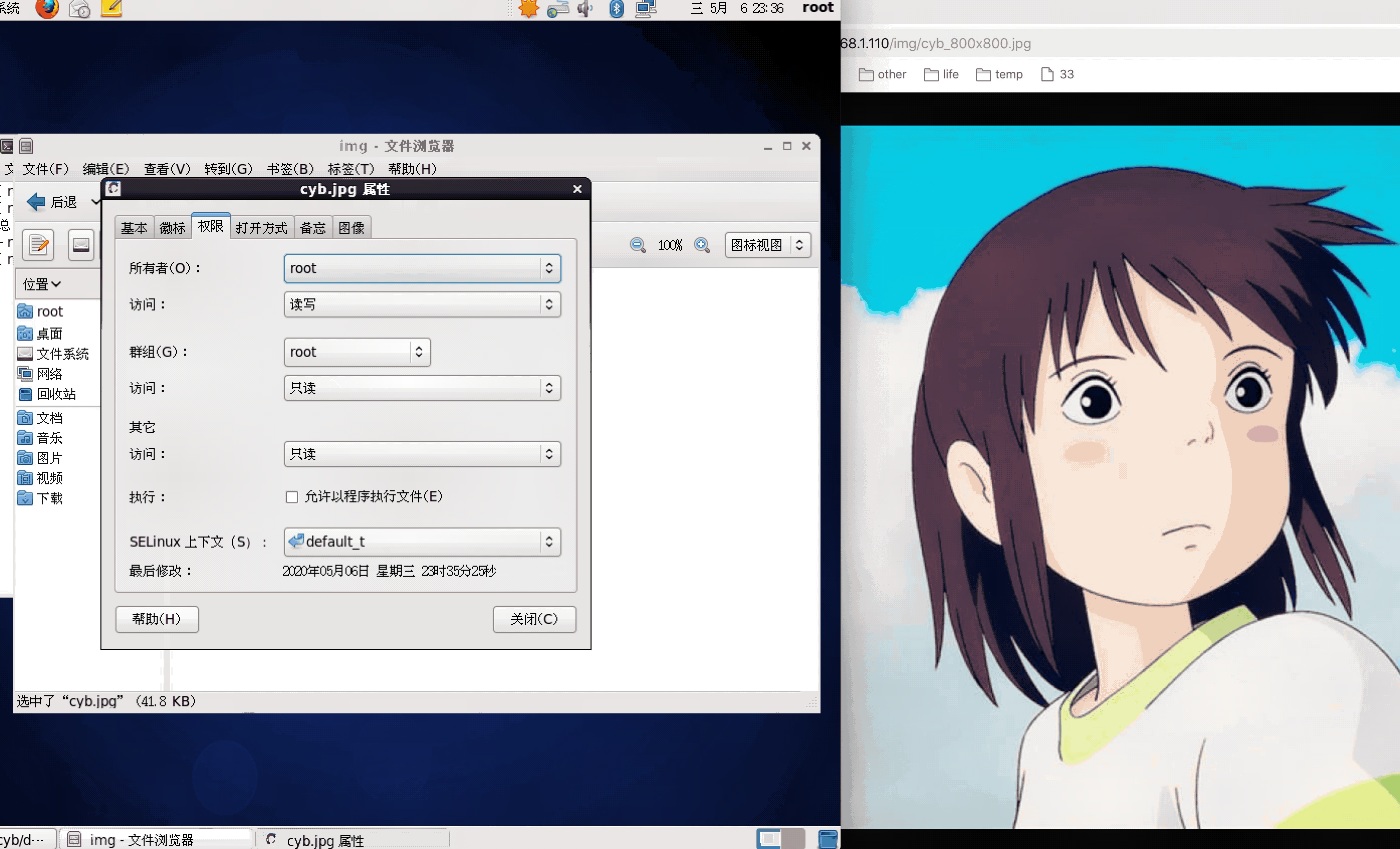
访问FastDFS图片
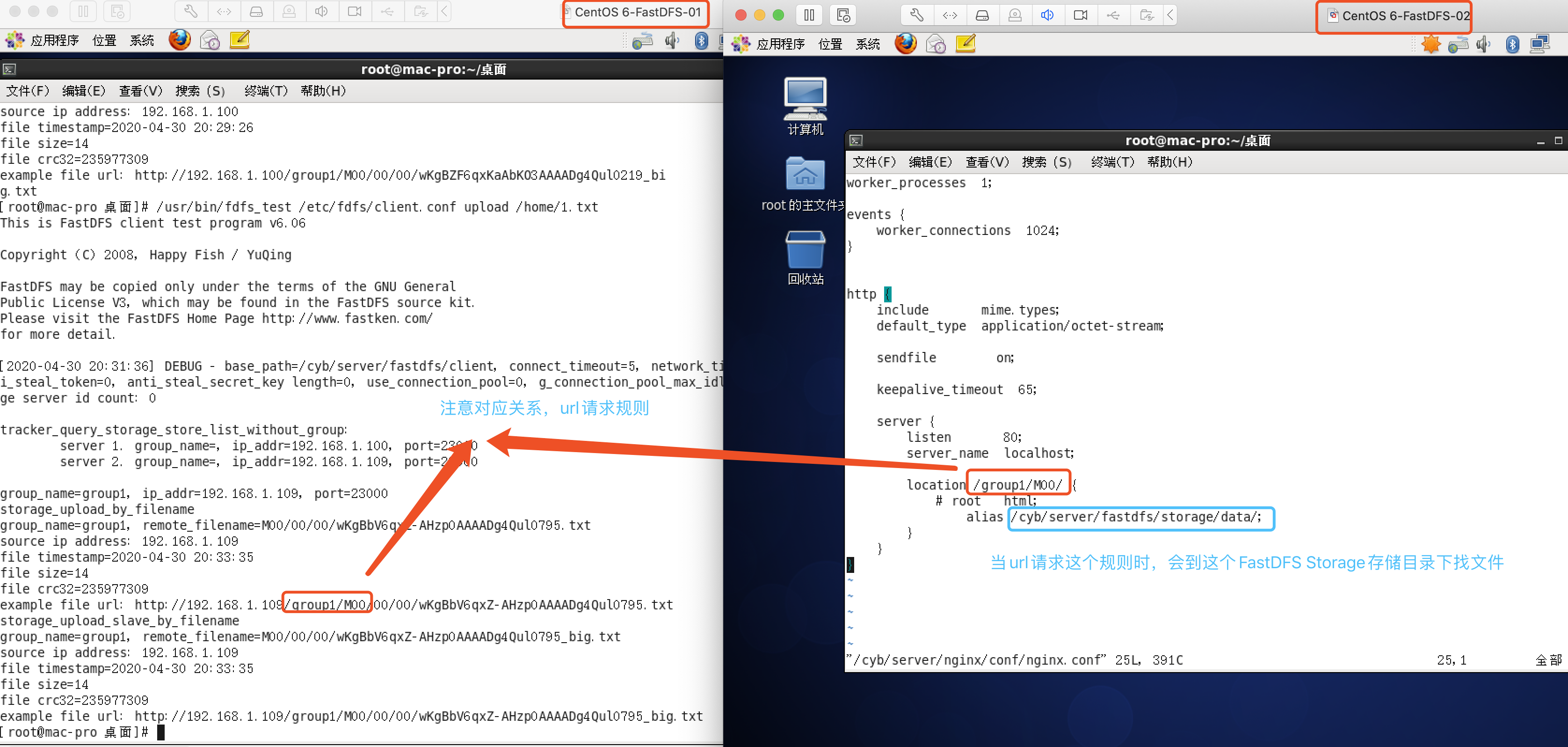
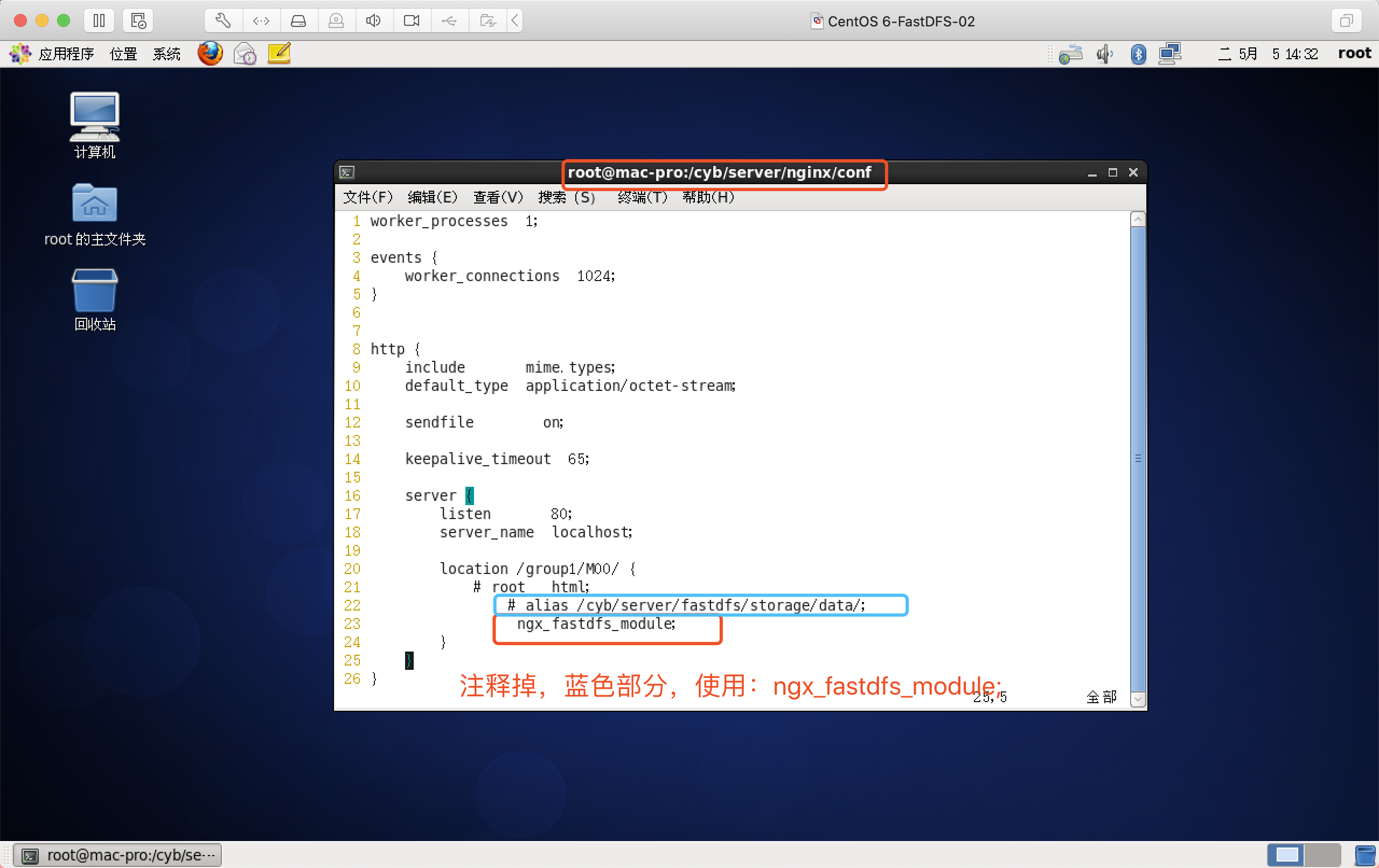
location ~ group1/M00/(.+)_(\d+)x(\d+)\.(jpg|gif|png){
# 设备别名(类似于root的用法)
alias /cyb/server/fastdfs/storage/data/;
# fastdfs中的ngx_fastdfs_module模块
ngx_fastdfs_module;
set $w $2;
set $h $3;
if ($w != "0"){
rewrite group1/M00(.+)_(\d+)x(\d+)\.(jpg|gif|png)$ group1/M00$1.$4 break;
}
if ($h != "0"){
rewrite group1/M00(.+)_(\d+)x(\d+)\.(jpg|gif|png)$ group1/M00$1.$4 break;
}
# 根据给定长宽生成缩略图
image_filter resize $w $h;
# 原图最大2M,要裁剪的图片超过2M返回415错误,需要调节参数image_filter_buffer
image_filter_buffer 2M;
}
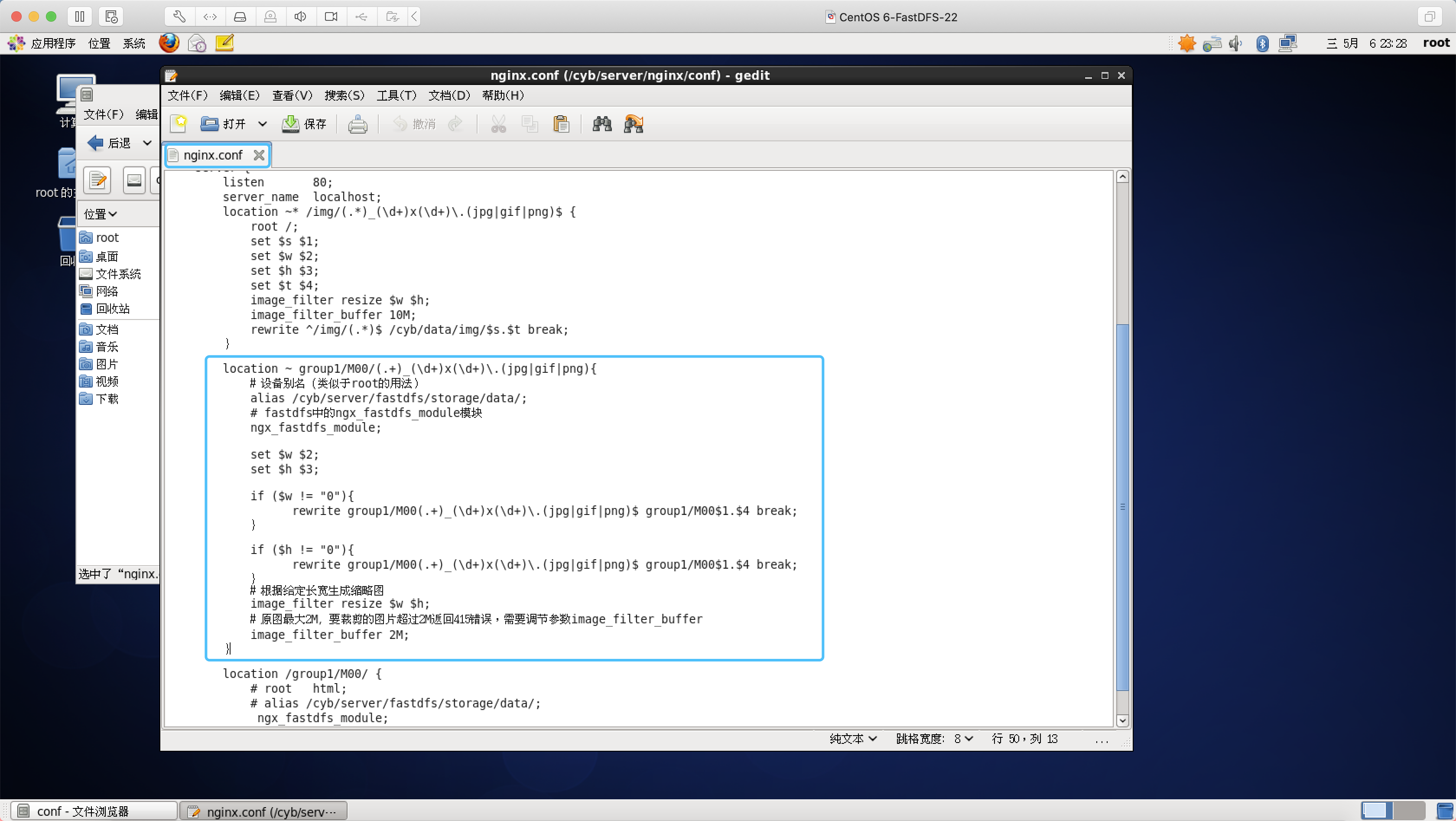
测试(FastDFS图片)
Nginx Image缩略图 模块
- 该模块主要功能是对请求的图片进行缩略/水印处理,支持文字水印和图片水印
- 支持自定义字体,文字大小,水印透明度,水印位置
- 支持jpeg/png/gif(Gif生成后变成静态图片)
安装nginx image模块
编译nginx前,请确认是否安装过libcurl-dev libgd2-dev libpcre-dev依赖库
yum install -y dg-devel pcre-devel libcurl-devel
下载nginx image模块
https://github.com/oupula/ngx_image_thumb/archive/master.zip
解压
tar -zxvf ngx_image_thumb-master.zip
执行configure

编译与安装
make && make install
修改nginx.conf配置
location /img/ {
root /cyb/data/;
# 开启压缩功能
image on;
# 是否不生成图片而直接处理后输出
image_output on;
image_water on;
# 水印类型:0为图片水印,1为文字水印
image_water_type 0;
#水印出现位置
image_water_pos 9;
# 水印透明度
image_water_transparent 80;
# 水印文件
image_water_file "/cyb/data/logo.png";
}
关闭并重启nginx
nginx -s stop
nginx
访问普通图片
- 源图片:192.168.1.109/img/cyb.jpg
- 压缩图片:192.168.1.109/img/cyb.jpg!c300x200.jpg
其中c是生成图片缩略图的参数,300是生成的缩略图的宽,200是高
参数说明:
一共可以生成四种不同类型的缩略图
C:参数按照请求宽高比例从图片高度 10% 处开始截取图片,然后缩放/放大指定尺寸(图片缩略图大小等于请求的宽高) m:参数按请求宽高比例居中截取图片,然后缩放/放大到指定尺寸(图片缩略图大小等于请求的宽高) t:参数按请求宽高比例按比例缩放/放大到指定尺寸(图片缩略图大小可能小于请求的宽高) w:参数按请求宽高比例缩放/放大到指定尺寸,空白处填充白色背景色(图片缩略图大小等于请求的宽高)
测试(普通图片)
细心的小伙伴发现,水印没有出现,术印出没出来有个阈值:600x600(版本不同,阈值可能不同)
访问FastDFS图片
location /group1/M00/ {
alias /cyb/server/fastdfs/storage/data/;
image on;
image_output on;
image_jpeg_quality 75;
image_water on;
image_water_type 0;
image_water_pos 9;
image_water_transparent 80;
image_water_file "/cyb/data/logo.png";
# 配置一个不存在的图片地址,防止查看缩略图时照片不存在,服务器响应慢
# image_backend_server http://www.baidu.com/img/baidu_jpglogo3.gif
}
测试(FastDFS图片)
从入门到精通(分布式文件系统架构)-FastDFS,FastDFS-Nginx整合,合并存储,存储缩略图,图片压缩,Java客户端的更多相关文章
- 从零搭建分布式文件系统MinIO比FastDFS要更合适
前两天跟大家分享了一篇关于如何利用FastDFS组件来自建分布式文件系统的文章,有兴趣的朋友可以阅读下<用asp.net core结合fastdfs打造分布式文件存储系统>.通过留言发现大 ...
- Hadoop分布式文件系统架构部署
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任.http://wgkgood.blog.51cto.com/1192594/1332340 前言 ...
- [转]分布式文件系统FastDFS架构剖析
[转]分布式文件系统FastDFS架构剖析 http://www.programmer.com.cn/4380/ 文/余庆 FastDFS是一款类Google FS的开源分布式文件系统,它用纯C语言实 ...
- 【转】分布式文件系统FastDFS架构剖析
FastDFS是一款类Google FS的开源分布式文件系统,它用纯C语言实现,支持Linux.FreeBSD.AIX等UNIX系统.它只能通过专有API对文件进行存取访问,不支持POSIX接口方式, ...
- 网站文件系统发展&&分布式文件系统fastDFS
网站文件系统发展 1.单机时代的图片服务器架构 初创时期由于时间紧迫,开发人员水平也很有限等原因.所以通常就直接在website文件所在的目录下,建立1个upload子目录,用于保存用户上传的图片文件 ...
- 分布式文件系统FastDFS原理介绍
在生产中我们一般希望文件系统能帮我们解决以下问题,如:1.超大数据存储:2.数据高可用(冗余备份):3.读/写高性能:4.海量数据计算.最好还得支持多平台多语言,支持高并发. 由于单台服务器无法满足以 ...
- 分布式文件系统FastDFS详解
上一篇文章<一次FastDFS并发问题的排查经历>介绍了一次生产排查并发问题的经历,可能有些人对FastDFS不是特别的了解,因此计划写几篇文章完整的介绍一下这个软件. 为什么要使用分布式 ...
- 高可用高性能分布式文件系统FastDFS实践Java程序
在前篇 高可用高性能分布式文件系统FastDFS进阶keepalived+nginx对多tracker进行高可用热备 中已介绍搭建高可用的分布式文件系统架构. 那怎么在程序中调用,其实网上有很多栗子, ...
- FastDFS 分布式文件系统部署实战及基本使用
FastDFS 分布式文件系统部署实战及基本使用 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. FastDFS是一个开源的高性能分布式文件系统.它的主要功能包括:文件存储,文件同步 ...
随机推荐
- Python爬虫 ---scrapy框架初探及实战
目录 Scrapy框架安装 操作环境介绍 安装scrapy框架(linux系统下) 检测安装是否成功 Scrapy框架爬取原理 Scrapy框架的主体结构分为五个部分: 它还有两个可以自定义下载功能的 ...
- 采用TuesPechkin生成Pdf
1.需求 前段时间有个需求,要求把网页生成pdf,找了各种插件,才决定使用这个TuesPechkin,这个是后台采用C#代码进行生成 2.做法 我要做的是一个比较简单的页面,采用MVC绑定,数据动态加 ...
- MyBatis通用 Mapper4使用小结
官网地址: http://www.mybatis.tk/ https://gitee.com/free 1.使用springboot,添加依赖: 使用tk的mybatis后不需要引用官方原生的myba ...
- 跨域cookies 共享
这是由于,本地调试.涉及到cookies的问题 想要跨域使用的问题 vue 中的mian.js中放入下面代码 import axios from 'axios' axios.defaults.with ...
- 使用snapjs实现svg路径描边动画
一,snap.svg插件在近几天,突然接到一个需求,内容是要在网页上写一个路径的动画,还需要可以随意控制动画的速度,开始于结束,本来是一个图片可以解决的问题,结果就这样变难了呀,在网上查一会之后,突然 ...
- 复习python的__call__ __str__ __repr__ __getattr__函数 整理
class Www: def __init__(self,name): self.name=name def __str__(self): return '名称 %s'%self.name #__re ...
- mysql定期任务
进来开发项目时遇到一个问题,就是每一周需要清理服务器数据库数据.现在我就来记录一下用Navicat for MySQL 来实现定时任务. 1.启动Navicat for MySQL,新建数据库连接,打 ...
- Hash记录字符串
Hash记录字符串模板: mod常常取1e9+7,base常常取299,,127等等等....有的题目会卡Hash,因为可能会有两个不同的Hash但却有相通的Hash值...这个时候可以用双Hash来 ...
- GCD - Extreme (II) UVA - 11426 欧拉函数与gcd
题目大意: 累加从1到n,任意两个数的gcd(i,j)(1=<i<n&&i<j<=n). 题解:假设a<b,如果gcd(a,b)=c.则gcd(a/c,b ...
- 手写一个简单的HashMap
HashMap简介 HashMap是Java中一中非常常用的数据结构,也基本是面试中的"必考题".它实现了基于"K-V"形式的键值对的高效存取.JDK1.7之前 ...