Python数据分析之双色球高频数据统计
Step1:基础数据准备(通过爬虫获取到),以下是从第一期03年双色球开奖号到今天的所有数据整理,截止目前一共2549期,balls.txt 文件内容如下 :
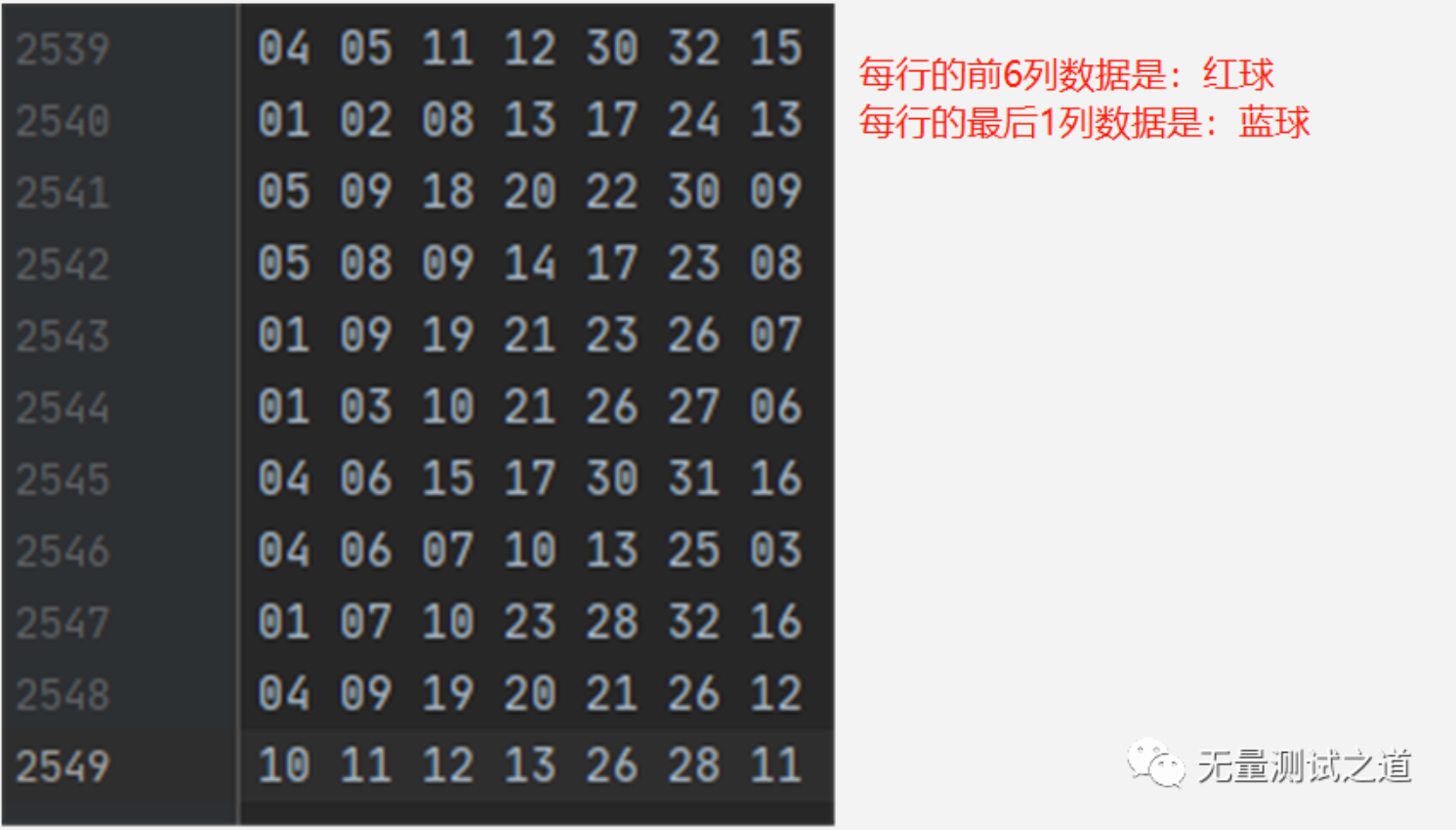
备注:想要现成数据的可以给我发邮件哟~
Step2: 分析数据特征和数据处理方式选择,直接上代码如下:
#导入Counter
from collections import Counter
def readfile():
red_lists=[]
blue_lists=[]
#打开文件并获取文件句柄
with open("./balls.txt", "r",encoding='utf-8') as fp:
#开始读取文件并返回一个list
list1=fp.readlines()
#遍历整个文件内容
for i in range(len(list1)):
#替换掉\n的字符再按空格分隔
list2=str(list1[i]).replace("\n","").split(" ")
for j in range(len(list2)):
if j==6:
#蓝球放入到blue_lists 列表中
blue_lists.append(list2[j])
else:
#红球放入到red_lists 列表中
red_lists.append(list2[j])
#Counter可以快速便捷的对某些对象做一些统计操作,这里是对列表里面的数据进行出现次数统计,返回一个tuple
red_count=Counter(red_lists)
blue_count=Counter(blue_lists)
#most_common可以用来统计列表或字符串中最常出现的元素并做排序,并返回一个list
k = red_count.most_common(len(red_count))
#输出出现频率最高的六个红球
print("the red ball:",k[:6])
l = blue_count.most_common(len(blue_count))
#输出出现频率最高的六个蓝球
print("the blue ball:",l[:6])
if __name__=="__main__":
readfile()
Step3:执行结果如下:

Step4:执行结果验证:
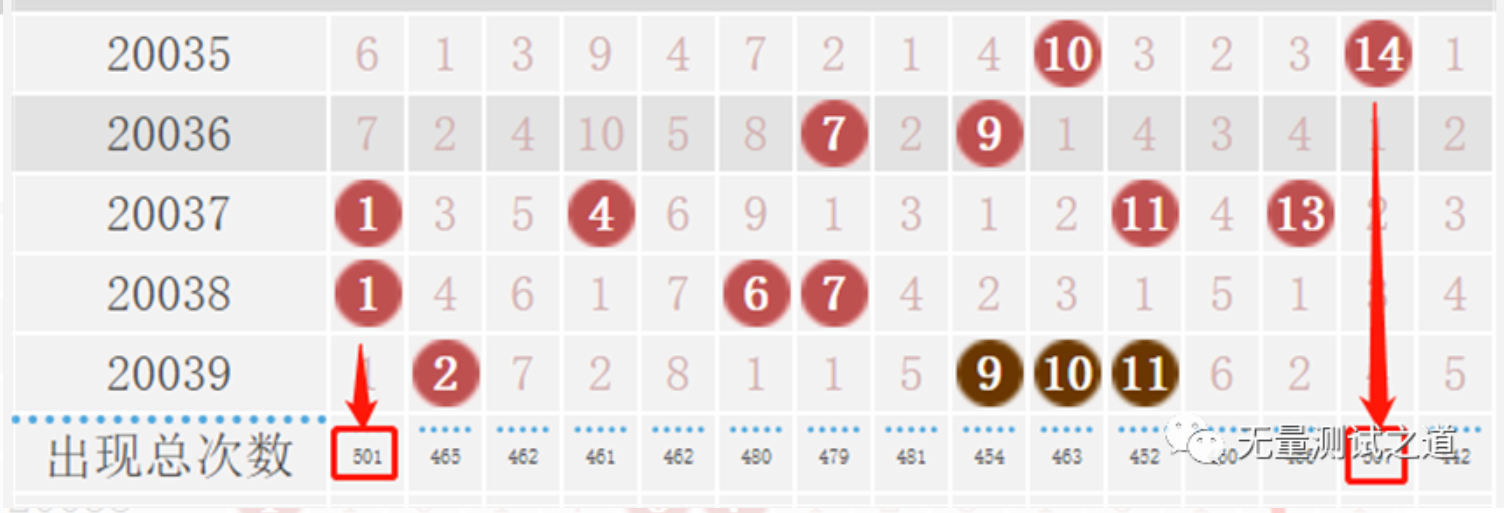
从官网获取的数据进行对比,一致性校验通过。
总结:python在数据处理方面有着非常强大的优势,其实早先用过Panda库也可以非常出色的完成双色球的数据统计,大家有兴趣的可以实验一下。
备注:我的个人公众号已正式开通,致力于测试技术的分享,包含:大数据测试、功能测试,测试开发,API接口自动化、测试运维、UI自动化测试等,微信搜索公众号:“无量测试之道”,或扫描下方二维码:

添加关注,一起共同成长吧。
Python数据分析之双色球高频数据统计的更多相关文章
- Python数据分析:大众点评数据进行选址
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:砂糖侠 如果你处于想学Python或者正在学习Python,Pyth ...
- Python 数据分析 - 索引和选择数据
loc,iloc,ix三者间的区别和联系 loc .loc is primarily label based, but may also be used with a boolean array. 就 ...
- python数据分析之csv/txt数据的导入和保存
约定: import numpy as np import pandas as pd 1 2 3 一.CSV数据的导入和保存 csv数据一般格式为逗号分隔,可在excel中打开展示. 示例 data1 ...
- Python数据分析之文本处理词频统计
1.项目背景: 原本计划着爬某房产网站的数据做点分析, 结果数据太烂了,链家网的数据干净点, 但都是新开楼盘,没有时间维度,分析意义不大. 学习的步伐不能ting,自然语言处理还的go on 2.分析 ...
- python数据分析第二版:数据加载,存储和格式
一:读取数据的函数 1.读取csv文件 import numpy as np import pandas as pd data = pd.read_csv("C:\\Users\\Admin ...
- Python数据分析之全球人口数据
这篇文章用pandas对全球的人口数据做个简单分析.我收集全球各国1960-2019年人口数据,包含男女和不同年龄段,共6个文件. pop_total.csv: 各国每年总人口 pop_female. ...
- Python 数据分析—第七章 数据归整:清理、转换、合并、重塑
一.数据库风格的Dataframe合并 import pandas as pd import numpy as np df1 = pd.DataFrame({'1key':['b','b','a',' ...
- 【python数据分析实战】电影票房数据分析(二)数据可视化
目录 图1 每年的月票房走势图 图2 年票房总值.上映影片总数及观影人次 图3 单片总票房及日均票房 图4 单片票房及上映月份关系图 在上一部分<[python数据分析实战]电影票房数据分析(一 ...
- 小白学 Python 数据分析(5):Pandas (四)基础操作(1)查看数据
在家为国家做贡献太无聊,不如跟我一起学点 Python 人生苦短,我用 Python 前文传送门: 小白学 Python 数据分析(1):数据分析基础 小白学 Python 数据分析(2):Panda ...
随机推荐
- python --字符串学习
一 转义字符 借用一个特殊的方法表示一系列不方便写出的内容,比如回车键,换行符,退格键 借助反斜杠字符,一旦出现反斜杠,则反斜杠后面一个或者几个字符表示已经不是原来的意思了 在字符串中,一旦出现了斜杠 ...
- SD实现原理学习,以及SD失效的问题解决
SD失效的问题可能解决方案: 1.有可能是图片的url地址不对,有可能浏览器可以打开,但是这个地址浏览器是做了处理的,所以浏览器能打开. 2.如果图片地址是Http,那么就需要关闭ATS. ATS ( ...
- Redux:Reducers
action只是描述了“发生了什么事情(导致state需要更新)”,但并不直接参与更新state的操作.state的更新由reducer函数执行. 其基本模式是:(state,action)=> ...
- vue中v-for索引不要用key
今天发现在给元素v-for渲染的时候,想给元素添加key特性存储索引,发现不奏效: <div class="apic" v-for="(pic,index) in ...
- js 获取table tr td内的select 和input text
$("#TableList tr").each(function () { //for (var i = 1; i <= AM_index; i ...
- POJ3169
题目链接:http://poj.org/problem?id=3169 AC思路: spfa算法. 设各牛的位置为x[ ]. 对于感情好的牛,即第2到ML+1行:A B D, 有x[B] - x[A] ...
- 【MySQL】索引的本质(B+Tree)解析
索引是帮助MySQL高效获取数据的排好序的数据结构. 索引数据结构 二叉树 红黑树 Hash表 B-Tree MySQL所使用为B+Tree (B-Tree变种) 非叶子节点不存储data,只存储索引 ...
- A + B Problem(hdu1000)
注意,认真读题目的Input要求,看看是输入一组测试数据还是输入多组测试数据.输入多组数据,不要忘记while(). #include<iostream> using namespace ...
- vue实现对文章列表的点赞
今天要做一个对文章点赞的功能,实现后的样式如下,点赞后的文章下面的大拇指图标会变红,并且点赞数加1 一开始分别遇到过两个问题:1.点文章中的一个赞,所有文章的赞全部变红了 2.点赞后,虽然当前文章的赞 ...
- 0512String类
String类 2. String类 2.1 字符串类型概述 又爱又恨!!! 爱: 字符串基本上就是数据的保存,传输,处理非常重要的一种手段. 恨: 解析过程非常烦人,需要掌握熟记很多方法,同时需要有 ...