大数据学习之Hadoop运行模式
一、Hadoop运行模式
(1)本地模式(默认模式):
不需要启用单独进程,直接可以运行,测试和开发时使用。
(2)伪分布式模式:
等同于完全分布式,只有一个节点。
(3)完全分布式模式:
多个节点一起运行。
1.1 本地运行Hadoop 案例
1.1.1 官方grep案例
1)创建在hadoop-2.7.6文件下面创建一个input文件夹
[root@master hadoop-2.7.6]# mkdir input
2)将hadoop的xml配置文件复制到input
[root@master hadoop-2.7.6]# cp etc/hadoop/*.xml input
3)执行share目录下的mapreduce程序
[root@master hadoop-2.7.6]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar grep input output 'dfs[a-z.]+'
4)查看输出结果
[root@master src]# cat output/*
1.2 伪分布式运行Hadoop案例
1.2.1 启动HDFS并运行MapReduce程序
1)分析:
(1)准备1台客户机
(2)安装jdk
(3)配置环境变量
(4)安装hadoop
(5)配置环境变量
(6)配置集群
(7)启动、测试集群增、删、查
(8)执行wordcount案例
2)执行步骤
需要配置hadoop文件如下
(1)配置集群
(a)配置:hadoop-env.sh
修改JAVA_HOME 路径:
export JAVA_HOME=/usr/java/jdk1.8.0_171-amd64
(b)配置:core-site.xml
|
<!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://slave1:9000</value> </property> <!-- 指定hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/src/hadoop-2.7.6/tmp</value> </property> |
(c)配置:hdfs-site.xml
|
<!-- 指定HDFS副本的数量 --> <property> <name>dfs.replication</name> <value>1</value> </property> |
(2)启动集群
(a)格式化namenode(第一次启动时格式化,以后就不要总格式化)
bin/hdfs namenode -format
(b)启动namenode
sbin/hadoop-daemon.sh start namenode
(c)启动datanode
sbin/hadoop-daemon.sh start datanode
(3)查看集群
(a)查看是否启动成功
使用jps命令查看进程
(b)查看产生的log日志
当前目录:/usr/local/src/hadoop-2.7.6/logs
(c)web端查看HDFS文件系统
http://localhost:50070/dfshealth.html#tab-overview
注意:如果不能查看,看如下帖子处理
http://www.cnblogs.com/zlslch/p/6604189.html
(4)操作集群
(a)在hdfs文件系统上创建一个input文件夹
[root@slave1 hadoop-2.7.6]# bin/hdfs dfs -mkdir -p /user/mapreduce/wordcount/input
(b)将测试文件内容上传到文件系统上
[root@slave1 hadoop-2.7.6]# bin/hdfs dfs -put wcinput/wc.input /user/mapreduce/wordcount/input/
(c)查看上传的文件是否正确
[root@slave1 hadoop-2.7.6]# bin/hdfs dfs -ls /user/mapreduce/wordcount/input/
[root@slave1 hadoop-2.7.6]# bin/hdfs dfs -cat /user/mapreduce/wordcount/input/wc.input
(d)运行mapreduce程序
[root@slave1 hadoop-2.7.6]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/mapreduce/wordcount/input/ /user/mapreduce/wordcount/output
(e)查看输出结果
命令行查看:
[root@slave1 hadoop-2.7.6]# bin/hdfs dfs -cat /user/atguigu/mapreduce/wordcount/output/*
也可浏览器查看 http://localhost:50070/dfshealth.html#tab-overview

(f)将测试文件内容下载到本地
[root@slave1 hadoop-2.7.6]# hadoop fs -get /user/mapreduce/wordcount/output/part-r-00000 ./wcoutput/
(g)删除输出结果
[root@slave1 hadoop-2.7.6]# hdfs dfs -rmr /user/mapreduce/wordcount/output
1.2.2 YARN上运行MapReduce 程序
1)分析:
(1)准备1台客户机
(2)安装jdk
(3)配置环境变量
(4)安装hadoop
(5)配置环境变量
(6)配置集群yarn上运行
(7)启动、测试集群增、删、查
(8)在yarn上执行wordcount案例
2)执行步骤
(1)配置集群
(a)配置yarn-env.sh
配置一下JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_171-amd64
(b)配置yarn-site.xml
|
<!-- reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop61</value> </property> |
(c)配置:mapred-env.sh
配置一下JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_171-amd64
(d)配置: (对mapred-site.xml.template重新命名为) mapred-site.xml
|
<!-- 指定mr运行在yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> |
(2)启动集群
(a)启动resourcemanager
sbin/yarn-daemon.sh start resourcemanager
(b)启动nodemanager
sbin/yarn-daemon.sh start nodemanager
(3)集群操作
(a)yarn的浏览器页面查看
http://192.168.110.61:8088/cluster
(b)删除文件系统上的output文件
bin/hdfs dfs -rm -R /user/mapreduce/wordcount/output
(c)执行mapreduce程序
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/mapreduce/wordcount/input /user/mapreduce/wordcount/output
(d)查看运行结果
bin/hdfs dfs -cat /user/mapreduce/wordcount/output/*
1.3 完全分布式部署Hadoop
1. 分析:
1)准备3台客户机(关闭防火墙、静态ip、主机名称)
2)安装jdk
3)配置环境变量
4)安装hadoop
5)配置环境变量
6)安装ssh
7)配置集群
8)启动测试集群
2. 虚拟机准备
参考https://www.cnblogs.com/singlecodeworld/p/9524369.html
3.SSH无密码登录
参考https://www.cnblogs.com/singlecodeworld/p/9547866.html
4. 配置集群
1)集群部署规划
| hadoop61 | hadoop62 | hadoop63 | |
|
HDFS |
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN | NodeManager |
ResourceManager NodeManager |
NodeManager |
2)配置文件
(1)配置core-site.xml
|
<!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop61:9000</value> </property> <!-- 指定hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.6/tmp</value> </property> |
(2)Hdfs
配置hadoop-env.sh
| export JAVA_HOME=/usr/java/jdk1.8.0_171-amd64 |
配置hdfs-site.xml
|
<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop63:50090</value> </property> </configuration> |
配置slaves
[gaokang@hadoop61 hadoop]$ vi slaves
|
hadoop61 hadoop62 hadoop63 |
(3)yarn
配置yarn-env.sh
[gaokang@hadoop61 hadoop]$ vi yarn-env.sh
| export JAVA_HOME=/opt/module/jdk1.8.0_144 |
配置yarn-site.xml
[gaokang@hadoop61 hadoop]$ vi yarn-site.xml
|
<configuration> <!-- reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop62</value> </property> </configuration> |
(4)mapreduce
配置mapred-env.sh
[gaokang@hadoop61 hadoop]$ vi mapred-env.sh
| export JAVA_HOME=/opt/module/jdk1.8.0_144 |
配置mapred-site.xml
[gaokang@hadoop61 hadoop]$ vi mapred-site.xml
|
<configuration> <!-- 指定mr运行在yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> |
3)在集群上分发以上所有文件
[gaokang@hadoop61 hadoop]$ scp * gaokang@hadoop62:/usr/local/src/hadoop-2-7-6/etc/hadoop
[gaokang@hadoop61 hadoop]$ scp * gaokang@hadoop63:/usr/local/src/hadoop-2-7-6/etc/hadoop
5.集群启动及测试
1)启动集群
(0)如果集群是第一次启动,需要格式化namenode
[gaokang@hadoop61 hadoop-2.7.6]$ bin/hdfs namenode -format
(1)启动HDFS:
[gaokang@hadoop61 hadoop-2.7.6]$ sbin/start-dfs.sh
//查看启动进程
[gaokang@hadoop61 hadoop-2.7.6]$ jps
[gaokang@hadoop62 hadoop-2.7.6]$ jps
[gaokang@hadoop63 hadoop-2.7.6]$ jps
(2)启动yarn
[gaokang@hadoop61 hadoop-2.7.6]$ sbin/start-yarn.sh
注意:Namenode和ResourceManger如果不是同一台机器,不能在NameNode上启动 yarn,应该在ResouceManager所在的机器上启动yarn。
2)集群基本测试
(1)上传文件到集群
[gaokang@hadoop61 hadoop-2.7.6]$ bin/hdfs dfs -mkdir -p /user/data
[gaokang@hadoop61 hadoop-2.7.6]$ bin/hdfs dfs -put etc/hadoop/*-site.xml /user/data
(2)上传文件后查看文件存放在什么位置
进入临时数据目录
[gaokang@hadoop61 hadoop-2.7.6]$ cd tmp/dfs/data/current/BP-1951657529-192.168.110.61-1535407736174/current/finalized/subdir0/subdir0
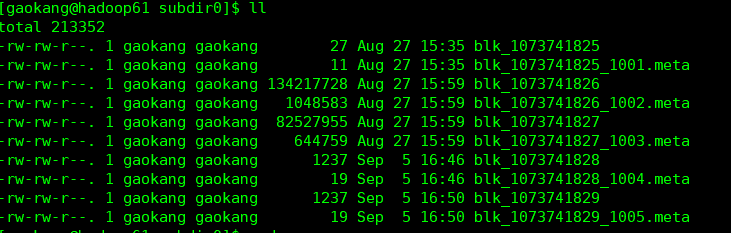
(3)拼接,将多个文件拼接成一个文件

(4)下载
[gaokang@hadoop61 hadoop-2.7.6]$ bin/hadoop fs -get /usr/data/hadoop-2.7.6.tar.gz
6、Hadoop启动停止方式
1)各个服务组件逐一启动
(1)分别启动hdfs组件
sbin/hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode
(2)启动yarn
sbin/yarn-daemon.sh start|stop resourcemanager|nodemanager
2)各个模块分开启动(配置ssh是前提)常用
(1)整体启动/停止hdfs
sbin/start-dfs.sh
sbin/stop-dfs.sh
(2)整体启动/停止yarn
sbin/start-yarn.sh
sbin/stop-yarn.sh
3)全部启动(不建议使用)
sbin/start-all.sh
sbin/stop-all.sh
大数据学习之Hadoop运行模式的更多相关文章
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 大数据学习之hadoop伪分布式集群安装(一)公众号undefined110
hadoop的基本概念: Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速运算和存储. Hadoo ...
- 大数据学习笔记——Hadoop编程实战之Mapreduce
Hadoop编程实战——Mapreduce基本功能实现 此篇博客承接上一篇总结的HDFS编程实战,将会详细地对mapreduce的各种数据分析功能进行一个整理,由于实际工作中并不会过多地涉及原理,因此 ...
- 大数据学习笔记——Hadoop高可用完全分布式模式完整部署教程(包含zookeeper)
高可用模式下的Hadoop集群搭建 本篇博客将会在之前写过的Linux的完整部署的基础上进行,暂时不会涉及到伪分布式或者完全分布式模式搭建,由于HA模式涉及到的配置文件较多,维护起来也较为复杂,相信学 ...
- 大数据学习之Hadoop环境搭建
一.Hadoop的优势 1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理. 2)高扩展性:在集群间分配任务数据,可方便的 ...
- 大数据学习笔记——Hadoop编程之SequenceFile
SequenceFile(Hadoop序列文件)基础知识与应用 上篇编程实战系列中本人介绍了基本的使用HDFS进行文件读写的方法,这一篇将承接上篇重点整理一下SequenceFile的相关知识及应用 ...
- 【大数据系列】hadoop单机模式安装
一.添加用户和用户组 adduser hadoop 将hadoop用户添加进sudo用户组 sudo usermod -G sudo hadoop 或者 visudo 二.安装jdk 具体操作参考:c ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
随机推荐
- 轻松应对IDC机房带宽突然暴涨问题
轻松应对IDC机房带宽突然暴涨问题! 1[提出问题] [实际案例一] 凌晨3:00点某公司(网站业务)的一个IDC机房带宽流量突然从平时高峰期150M猛增至1000M,如下图: 该故障的影响:直接导致 ...
- Ubuntu桌面显示超大,现在显示不全
按住alt可以自由拖动窗口或者滚动鼠标滚动轮,整体放大缩小桌面把窗口拖动到显示设置然后调整菜单和标题栏缩放比例
- javascript中简单提示框
CSS部分 .help-tip{ width: 340px; border:1px solid #A0A0A0; background-color: #F8F8F8; border-radius: 5 ...
- ORM的补充
之前学习的orm的操作类似: create delete update filter/all exclude values values_list get first last order_by 补充 ...
- mysql那些招
show table status mysql官方文档在 http://dev.mysql.com/doc/refman/5.1/en/show-table-status.html 这里的rows行是 ...
- Redis 在Golang中使用遇到的坑
1.从lua脚本传回到go那边的数字是string类型 2.hincrby 返回当前值的计算结果(即存放到redis中的值) 3.hset 一个不存在的key,返回什么呢?即设置失败返回什么错误?(会 ...
- 准备你的 In-app Billing 程序
准备好你的内购应用 在开始使用 In-app Billing 服务之前,你需要先把包含 In-app Billing Version 3 API 的库添加到你的Android工程中.你还需要设置你的应 ...
- 模拟代理安装---User-Agent Switcher for Chrome安装
模拟代理安装: 1. 百度User-Agent Switcher for Chrome进行下载 2. 直接安装 1. 进入扩展程序界面 2. 拖动插件进行安装 3.安装成功后会显示一个插件标志,里面可 ...
- Java并发案例02---生产者消费者问题
package example; import java.util.LinkedList; import java.util.concurrent.TimeUnit; public class MyC ...
- x-frame-options、iframe与iframe的一些操作
iframe的子操作父窗口,父操作子窗口: test.php: <!DOCTYPE html> <html> <head> <title>test< ...