python爬取斗图网中的 “最新套图”和“最新表情”
 1.分析斗图网
1.分析斗图网
斗图网地址:http://www.doutula.com
网站的顶部有这两个部分:

先分析“最新套图”

发现地址栏变成了这个链接,我们在点击第二页

可见,每一页的地址栏只有后面的page不同,代表页数;这样请求的地址就可以写了。
2.寻找表情包
然后就要找需要爬取的表情包链接了。我用的是chrome浏览器,F12进入开发者模式。
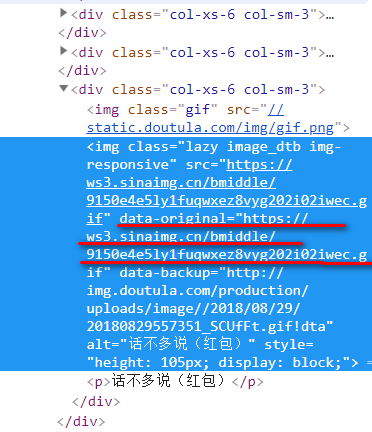
找到图片对应的img元素,发现每个Img元素的class都是相同的。data-original属性对应的地址,就是我们要下载的图片。alt属性就是图片的名字。
对于”最新表情“的页面,同样也是如此。
3.编写代码
元素都找到了,可以上代码了:
#coding=utf-8
import requests
from lxml import etree
from urllib import request
from time import sleep
import socket
import re socket.setdefaulttimeout(20) headers = {}
headers["User-Agent"] = "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0"
headers["Host"] = "www.doutula.com"
headers["Accept"] = "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"
headers["Accept-Language"] = "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2"
headers["Accept-Encoding"] = "gzip, deflate"
headers["Connection"] = "close"
headers["Upgrade-Insecure-Requests"] = "" def get_url(page):
# 最新套图580页
url = "http://www.doutula.com/article/list/?page=" + str(page)
# 最新表情1855页
# url = "http://www.doutula.com/photo/list/?page=" + str(page)
response = requests.get(url, headers=headers)
html = response.text
selector = etree.HTML(html)
# print(html)
# 最新套图xpath
img_url = selector.xpath('//img[@class="lazy image_dtb img-responsive"]/@data-original')
img_name = selector.xpath('//img[@class="lazy image_dtb img-responsive"]/@alt')
# 最新表情xpath
# img_url = selector.xpath('//img[@style="width: 100%; height: 100%;"]/@data-original')
# img_name = selector.xpath('//img[@style="width: 100%; height: 100%;"]/@alt')
img_name = name_filter(img_name)
for img in img_url:
id = img_url.index(img)
get_img(id, img, img_name)
response.close() def get_img(id, img, img_name):
"""
request.urlretrieve: 保存链接地址的文件
"""
global j
try:
if img[-3:] == 'dta':
if img[-7:-4] == 'gif':
request.urlretrieve(img, 'E:\\pictures\\%s.gif' % img_name[id])
elif img[-7:-4] == 'png':
request.urlretrieve(img, 'E:\\pictures\\%s.png' % img_name[id])
else:
request.urlretrieve(img, 'E:\\pictures\\%s.jpg' % img_name[id])
elif img[-3:] == 'gif':
request.urlretrieve(img, 'E:\\pictures\\%s.gif' % img_name[id])
elif img[-3:] == 'png':
request.urlretrieve(img, 'E:\\pictures\\%s.png' % img_name[id])
else:
request.urlretrieve(img, 'E:\\pictures\\%s.jpg' % img_name[id])
print("下载第%d张表情包" % j + img)
except Exception as ex: # urlopen error time out
print(str(ex))
j += 1 def name_filter(img_name):
"""
过滤文件名中的特殊字符
"""
newlist = []
for im in img_name:
im = re.sub(r'\?', '', str(im)) # / \
newlist.append(im)
return newlist if __name__ == '__main__': j = 1
for page in range(1, 581):
print("第%s页" % page)
while True:
try:
get_url(page)
break
except Exception as e:
print(str(e))
sleep(5)
sleep(10)
4.运行结果
爬了两天,可能代码中的sleep时间有点长,服务器那边也老是断开连接。

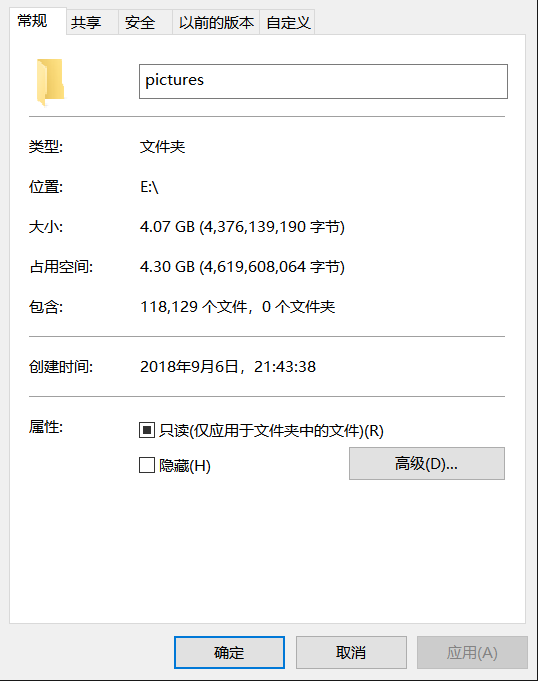
数据有些偏差,可能下载的过程网络的问题导致的。
5.总结
编码过程中,对于异常处理的思考,还需要多提高;有许多会出现问题的地方,都没有考虑到。
python爬取斗图网中的 “最新套图”和“最新表情”的更多相关文章
- Python爬取中国天气网
Python爬取中国天气网 基于requests库制作的爬虫. 使用方法:打开终端输入 “python3 weather.py 北京(或你所在的城市)" 程序正常运行需要在同文件夹下加入一个 ...
- python爬取天气后报网
前言 大二下学期的大数据技术导论课上由于需要获取数据进行分析,我决定学习python爬虫来获取数据.由于对于数据需求量相对较大,我最终选择爬取 天气后报网,该网站可以查询到全国各地多年的数据,而且相对 ...
- (python爬取小故事网并写入mysql)
前言: 这是一篇来自整理EVERNOTE的笔记所产生的小博客,实现功能主要为用广度优先算法爬取小故事网,爬满100个链接并写入mysql,虽然CS作为双学位已经修习了三年多了,但不仅理论知识一般,动手 ...
- python爬取千库网
url:https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/ 有水印 但是点进去就没了 这里先来测试是否有反爬虫 import requests ...
- Python爬取 斗图表情,让你成为斗图大佬
话不多说,上结果(只爬了10页内容) 上代码:(可直接运行) 用到Xpath #encoding:utf-8 # __author__ = 'donghao' # __time__ = 2018/ ...
- 适合初学者的Python爬取链家网教程
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: TinaLY PS:如有需要Python学习资料的小伙伴可以加点击下 ...
- Python爬取中国票房网所有电影片名和演员名字,爬取齐鲁网大陆所有电视剧名称
爬取CBO中国票房网所有电影片名和演员名字 # -*- coding: utf-8 -*- # 爬取CBO中国票房网所有电影片名 import json import requests import ...
- Python 爬取煎蛋网妹子图片
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Date : 2017-08-24 10:17:28 # @Author : EnderZhou (z ...
- Python爬取中国知网文献、参考文献、引证文献
前两天老师派了个活,让下载知网上根据高级搜索得到的来源文献的参考文献及引证文献数据,网上找了一些相关博客,感觉都不太合适,因此特此记录,希望对需要的人有帮助. 切入正题,先说这次需求,高级搜索,根据中 ...
随机推荐
- map详解<一>
首先了解下pair工具类: 这个类在头文件<utility>,功能:将俩个类型可能不一样的值组合在一起.,通过first和second来访问这两个值.还定义了operator == 和op ...
- C#流概述
C#流概述 .NET Framework使用“流”来支持读取或写入文件.可以将流视为一组连续的一维数据,包含开头和结尾,并且其中的游标指示了流的当前位置. 1.流操作 流中包含的数据可能来自内存.文件 ...
- codeforces472D
Design Tutorial: Inverse the Problem CodeForces - 472D 给你了一个 n × n最短距离矩阵.(即矩阵中dis[u][v]为u点到v点的最短距离), ...
- 搞懂JVM类加载机制
有这样一道面试题: class Singleton{ private static Singleton singleton = new Singleton(); public static int v ...
- 关于日期的一些常用方法的封装——dates.js
针对自己在日常用到的一些日期方法,整理成一个js日期插件,插件定义了一个dates全局对象,继承了Date函数,相当于在Date函数上做了一些扩展. 这个插件会不断更新,所有我之后用到的关于日期的自定 ...
- echo图片延迟加载js
插件描述:和 Lazy Load 一样,Echo.js 也是一个用于图像延迟加载 JavaScript.不同的是 Lazy Load 是基于 jQuery 的插件,而 Echo.js 不依赖于 jQu ...
- 深入理解JVM与GC回收
JVM内存模型 java虚拟机在执行java程序的过程中会把它所管理的内存划分为不同的若干个不同的的数据区域,这些区域都有各自的用途,以及创建和销毁的时间,有的区域随着虚拟机的进程的启动而存在,有些区 ...
- Java中的集合框架-Collections和Arrays
上一篇<Java中的集合框架-Map>把集合框架中的键值对容器Map中常用的知识记录了一下,本节记录一下集合框架的两个工具类Collections和Arrays 一,Collections ...
- Token ,Cookie和Session的区别
在做接口测试时,经常会碰到请求参数为token的类型,但是可能大部分测试人员对token,cookie,session的区别还是一知半解. Cookie cookie 是一个非常具体的东西,指的就是浏 ...
- T-SQL查询:WITH AS 递归计算某部门的所有上级机构或下级机构
drop table #Area; CREATE TABLE #Area ( id INT NOT NULL, city_name NVARCHAR(100) NOT NULL, parent_id ...