Selenium(二):选择元素的基本方法
1. 选择元素的基本方法
对于百度搜索页面,如果我们想自动化输入爱编程的小灰灰,怎么做呢?
这就是在网页中,操控界面元素。
web界面自动化,要操控元素,首先需要选择界面元素 ,或者说定位界面元素
就是先告诉浏览器,你要操作哪个界面元素, 让它找到你要操作的界面元素。
我们必须要让浏览器先找到元素,然后才能操作元素。
1.1 查看元素的方法
对应web自动化来说,就是要告诉浏览器,你要操作的界面元素是什么。
那么,怎么告诉浏览器呢?
方法就是:告诉浏览器,你要操作的这个web元素的特征。
就是告诉浏览器,这个元素它有什么与众不同的地方,可以让浏览器一下子找到它。
元素的特征怎么查看?
可以使用浏览器的开发者工具栏帮我们查看、选择 web 元素。
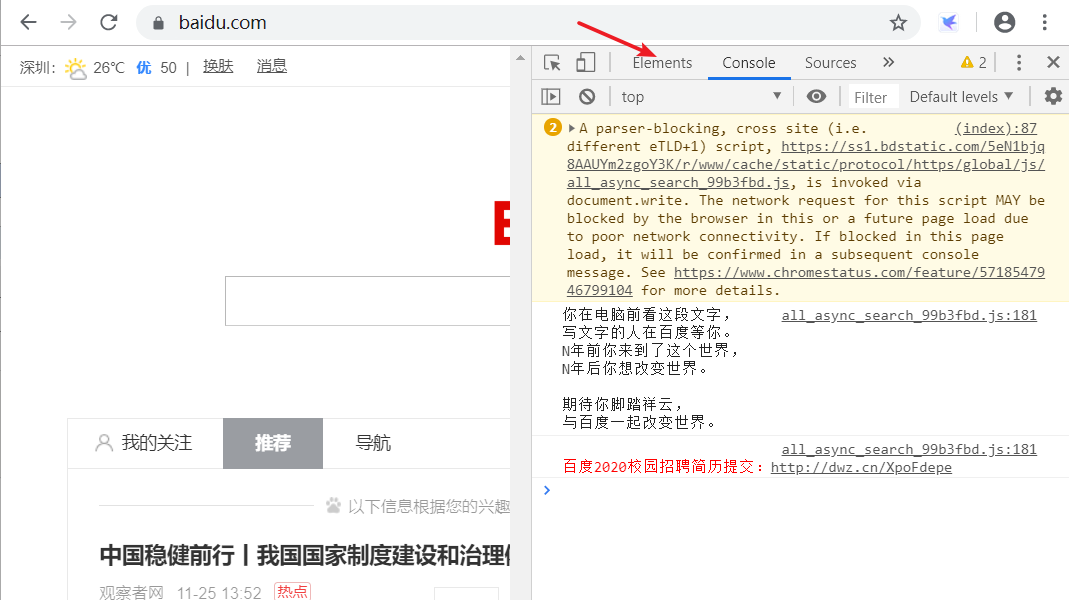
请大家用chrome浏览器访问百度,按F12后,点击下图箭头处的Elements标签,即可查看页面对应的HTML 元素
然后,再点击最左边的图标,如下所示

之后,鼠标在界面上点击哪个元素,就可以查看该元素对应的html标签了。
也可以直接在你想要查看的位置,右键选择检查,就可以直接定位到元素了。
1.2 根据元素的id属性选择元素
我们在input中,可以看到有一个属性叫id。

我们可以把id想象成元素的编号,是用来在html中标记该元素的。根据规范,如果元素有id属性,这个id必须是当前html中唯一的。
所以如果元素有id,根据id选择元素是最简单高效的方式。
这里,百度搜索框元素的id值为kw
下面的代码,可以自动化在浏览器中访问百度,并且在输入框中搜索爱编程的小灰灰。
大家可以运行一下看看。
from selenium import webdriver # 创建 WebDriver 对象,指明使用chrome浏览器驱动
wd = webdriver.Chrome(r'E:\webdrivers\chromedriver.exe') # 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
wd.get('https://www.baidu.com') # 根据id选择元素,返回的就是该元素对应的WebElement对象
element = wd.find_element_by_id('kw') # 通过该 WebElement对象,就可以对页面元素进行操作了
# 比如输入字符串到 这个 输入框里
element.send_keys('爱编程的小灰灰\n')
其中
wd = webdriver.Chrome(r'E:\webdrivers\chromedriver.exe')
前面讲过,driver赋值的是WebDriver类型的对象,我们可以通过这个对象来操控浏览器,比如打开网址、选择界面元素等。
下面的代码
wd.find_element_by_id('kw')
使用了 WebDriver对象的find_element_by_id方法。
这行代码运行时,就会发起一个请求,通过浏览器驱动转发给浏览器,告诉它,需要选择一个id为kw的元素。
浏览器找到id为kw的元素后,将结果通过浏览器驱动返回给自动化程序,所以find_element_by_id方法会返回一个WebElement 类型的对象。
这个WebElement对象可以看成是对应页面元素的遥控器。
我们通过这个WebElement对象,就可以操控对应的界面元素。
比如 :
调用这个对象的send_keys方法就可以在对应的元素中输入字符串,
调用这个对象的click方法就可以点击该元素。
1.3 根据class属性、tag名选择元素
1.3.1 根据class属性选择元素
web自动化的难点和重点之一,就是如何选择我们想要操作的web页面元素。
除了根据元素的id,我们还可以根据元素的class属性选择元素。
就像一个学生张三可以定义类型为中国人或者学生一样,中国人和学生都是张三的类型。
元素也有类型, class 属性就用来标志着元素类型。
html代码:
<body>
<div class="raise"><span>喜羊羊</span></div>
<div class="raise"><span>美羊羊</span></div>
<div class="raise"><span>暖羊羊</span></div> <div class="wolf"><span>灰太狼</span></div>
<div class="wolf"><span>红太狼</span></div>
<div class="wolf"><span>小灰灰</span></div>
</body>
所有的羊元素都有个class属性值为raise。
所有的狼元素都有个class属性值为wolf。
如果我们要选择所有的狼,就可以使用方法find_elements_by_class_name。
注意element后面多了个s。
wd.find_elements_by_class_name('wolf')
注意:
find_elements_by_class_name方法返回的是找到的符合条件的所有元素 (这里有3个元素), 放在一个列表中返回。
而如果我们使用find_element_by_class_name (注意少了一个s) 方法,就只会返回第一个元素。
大家可以运行如下代码看看。(注意html文件的路径)
from selenium import webdriver # 创建WebDriver实例对象,指明使用chrome浏览器驱动
wd = webdriver.Chrome(r'E:\webdrivers\chromedriver.exe') # WebDriver 实例对象的get方法 可以让浏览器打开指定网址
wd.get('http://127.0.0.1:8020/day01/index.html') # 根据 class name 选择元素,返回的是一个列表
# 里面都是class属性值为wolf的元素对应的WebElement对象
elements = wd.find_elements_by_class_name('wolf') # 取出列表中的每个WebElement对象,打印出其text属性的值
# text属性就是该WebElement对象对应的元素在网页中的文本内容
for element in elements:
print(element.text)
首先,大家要注意:通过WebElement对象的text属性可以获取该元素在网页中的文本内容。
所以下面的代码,可以打印出element对应网页元素的文本 。
print(element.text)
如果我们把
elements = wd.find_elements_by_class_name('wolf')
去掉一个s,改为
element = wd.find_element_by_class_name('wolf')
print(element.text)
那么返回的就是第一个class属性为wolf的元素,也就是这个元素。
<div class="wolf"><span>灰太狼</span></div>
就像一个学生张三可以定义有多个类型: 中国人和学生,中国人和学生都是张三的类型。
元素也可以有类型,多个class类型的值之间用空格隔开,比如
<span class="chinese student">张三</span>
注意,这里span元素有两个class属性,分别是chinese和student,而不是一个名为chinese student的属性。
我们要用代码选择这个元素,可以指定任意一个class属性值,都可以选择到这个元素,如下
element = wd.find_elements_by_class_name('chinese')
或者
element = wd.find_elements_by_class_name('student')
而不能这样写
element = wd.find_elements_by_class_name('chinese student')
1.3.2 根据tag名选择元素
和class方法差不多的,我们可以通过方法find_elements_by_tag_name,选择所有的tag名为div的元素,如下所示
from selenium import webdriver
wd = webdriver.Chrome(r'E:\webdrivers\chromedriver.exe')
wd.get('http://127.0.0.1:8020/day01/index.html')
# 根据 tag name 选择元素,返回的是 一个列表
# 里面 都是 tag 名为 div 的元素对应的 WebElement对象
elements = wd.find_elements_by_tag_name('div')
# 取出列表中的每个 WebElement对象,打印出其text属性的值
# text属性就是该 WebElement对象对应的元素在网页中的文本内容
for element in elements:
print(element.text)
1.3.3 find_element和find_elements的区别
使用find_elements选择的是符合条件的所有元素,如果没有符合条件的元素,返回空列表。
使用find_element选择的是符合条件的第一个 元素, 如果没有符合条件的元素, 抛出 NoSuchElementException异常。
1.4 通过WebElement对象选择元素
不仅WebDriver对象有选择元素的方法,WebElement对象也有选择元素的方法。
WebElement对象也可以调用find_elements_by_xxx,find_element_by_xxx之类的方法。
WebDriver对象选择元素的范围是整个web页面,而WebElement对象选择元素的范围是该元素的内部。
html代码:
<div id='container'>
<span>内层11</span>
<span>内层12</span>
<span>内层13</span>
</div>
<div>
<span>内层21</span>
<span>内层22</span>
<span>内层23</span>
</div>
from selenium import webdriver
wd = webdriver.Chrome(r'E:\webdrivers\chromedriver.exe')
wd.get('http://127.0.0.1:8020/day01/index.html')
element = wd.find_element_by_id('container')
# 限制 选择元素的范围是 id 为 container 元素的内部。
spans = element.find_elements_by_tag_name('span')
for span in spans:
print(span.text)
输出结果就只有

1.5 等待界面元素出现
在我们进行网页操作的时候,有的元素内容不是可以立即出现的,可能会等待一段时间。
比如百度搜索一个词语,我们点击搜索后,浏览器需要把这个搜索请求发送给百度服务器, 百度服务器进行处理后,把搜索结果返回给我们。
所以,从点击搜索到得到结果,需要一定的时间,只是通常百度服务器的处理比较快,我们感觉好像是立即出现了搜索结果。
百度搜索的每个结果对应的界面元素,其ID分别是数字 1, 2 ,3, 4...
如下:

那么我们可以试试用如下代码,来将第一个搜索结果里面的文本内容打印出来。
from selenium import webdriver
wd = webdriver.Chrome(r'E:\webdrivers\chromedriver.exe')
wd.get('https://www.baidu.com')
element = wd.find_element_by_id('kw')
element.send_keys('爱编程的小灰灰\n')
# id 为 1 的元素 就是第一个搜索结果
element = wd.find_element_by_id('')
# 打印出 第一个搜索结果的文本字符串
print (element.text)
如果大家去运行一下,就会发现有如下异常抛出
selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element: {"method":"id","selector":""}
NoSuchElementException的意思就是在当前的网页上找不到该元素,找不到id为1的元素。
为什么呢?
因为我们的代码执行的速度比百度服务器响应的速度快。
百度还没有来得及返回搜索结果,我们就执行了如下代码
element = wd.find_element_by_id('')
在那短暂的瞬间,网页上是没有用id为1的元素的(因为还没有搜索结果呢)。自然就会报告错误id为1的元素不存在了。
那么怎么解决这个问题呢?
相信很多人都能想到,就是在点击搜索后,用sleep来等待几秒钟,等百度服务器返回结果后,再去选择id为1的元素,就像下面这样
from selenium import webdriver
wd = webdriver.Chrome(r'E:\webdrivers\chromedriver.exe')
wd.get('https://www.baidu.com')
element = wd.find_element_by_id('kw')
element.send_keys('爱编程的小灰灰\n')
# 等待 2 秒
from time import sleep
sleep(2)
# 2 秒 过后,再去搜索
element = wd.find_element_by_id('')
# 打印出 第一个搜索结果的文本字符串
print (element.text)
大家可以运行一下,基本是可以的,不会再报错了。
但是,这样的方法有一个很大的问题,就是设置等待多长的时间合适呢?
这次百度网站反应可能比较快,我们等了一秒钟就可以了。
但是谁知道下次他的反应是不是还这么快呢?百度也曾经出现过服务器瘫痪的事情。
可能有的人说,我干脆sleep比较长的时间,等待 20 秒,总归可以了吧?
这样也有很大问题,假如一个自动化程序里面需要10次等待,就要花费 200秒。而可能大部分时间,服务器反映都是很快的,根本不需要等20秒,这样就造成了大量的时间浪费了。
Selenium提供了一个更合理的解决方案,是这样的:
当发现元素没有找到的时候,并不立即返回找不到元素的错误。
而是周期性(每隔半秒钟)重新寻找该元素,直到该元素找到,或者超出指定最大等待时长,这时才抛出异常(如果是find_elements之类的方法,则是返回空列表)。
Selenium的Webdriver对象有个方法叫implicitly_wait
该方法接受一个参数,用来指定最大等待时长。
如果我们加入如下代码
wd.implicitly_wait(10)
那么后续所有的find_element或者find_elements之类的方法调用都会采用上面的策略:
如果找不到元素,每隔半秒钟再去界面上查看一次,直到找到该元素,或者过了10秒最大时长。
这样,我们的百度搜索的例子的最终代码如下
from selenium import webdriver wd = webdriver.Chrome() # 设置最大等待时长为 10秒
wd.implicitly_wait(10) wd.get('https://www.baidu.com') element = wd.find_element_by_id('kw') element.send_keys('爱编程的小灰灰\n') element = wd.find_element_by_id('') print (element.text)
大家再运行一下,可以发现不会有错误了。
Selenium(二):选择元素的基本方法的更多相关文章
- <自动化测试>之<selenium API 查找元素操作底层方法>
搜罗了一些查找元素的除标准语句外,另外的语句使用方法,摘自 开源中国 郝云鹏driver = webdriver.Chrome(); 打开测试页面 driver.get( "http://b ...
- selenium自动化之元素定位方法
在使用selenium webdriver进行元素定位时,有8种基本元素定位方法(注意:并非只有8种,总共来说,有16种). 分别介绍如下: 1.name定位 (注意:必须确保name属性值在当前ht ...
- 使用Selenium对网页元素进行定位的诸种方法
使用Selenium进行自动化操作,首先要做的就是通过webdriver的get()方法打开一个URL链接. 在打开链接,完成页面加载之后,就可以通过Selenium提供的接口,在页面上进行各种操作了 ...
- selenium常见的元素定位方法
一.获取元素 1)通过谷歌浏览器自动的工具访问百度首页,我们可以看到,页面上的元素都是由一行行的代码组成的,它们之间有层级地组织起来,每个元素之间都有不同的标签和值,我们可以通过这些不同的标签和值来找 ...
- D3.js 其他选择元素方法
在上一节中,已经讲解了 select 和 selectAll,以及选择集的概念.本节具体讲解这两个函数的用法. 假设在 body 中有三个段落元素: <p>Apple</p> ...
- Selenium(三):操控元素的基本方法
1. 操控元素的基本方法 选择到元素之后,我们的代码会返回元素对应的 WebElement对象,通过这个对象,我们就可以操控元素了. 操控元素通常包括: 点击元素 在元素中输入字符串,通常是对输入框这 ...
- Selenium 八种元素定位方法
前言: 我们在做WEB自动化时,最根本的就是操作页面上的元素,首先我们要能找到这些元素,然后才能操作这些元素.工具或代码无法像我们测试人员一样用肉眼来分辨页面上的元素.那么我们怎么来定位他们呢? 在学 ...
- Python3 Selenium自动化web测试 ==> 第二节 页面元素的定位方法 <上>
前置步骤: 上一篇的Python单元测试框架unittest,我认为相当于功能测试测试用例设计中的用例模板,在自动化用例的设计过程中,可以封装一个模板,在新建用例的时候,把需要测试的步骤添加上去即可: ...
- selenium之元素定位的方法(一)
WebDriver 对象有多种方法用于在页面中寻找元素.他们被分成find_element_*和find_elements_*方法.find_element_*方法返回一个WebElement对象,代 ...
随机推荐
- JavaScript动画实例:旋转的圆球
1.绕椭圆轨道旋转的圆球 在Canvas画布中绘制一个椭圆,然后在椭圆上绘制一个用绿色填充的实心圆.之后每隔0.1秒刷新,重新绘制椭圆和实心圆,重新绘制时,实心圆的圆心坐标发生变化,但圆心坐标仍然位于 ...
- 百万级高并发mongodb集群性能数十倍提升优化实践
背景 线上某集群峰值TPS超过100万/秒左右(主要为写流量,读流量很低),峰值tps几乎已经到达集群上限,同时平均时延也超过100ms,随着读写流量的进一步增加,时延抖动严重影响业务可用性.该集群采 ...
- sql手工注入1
手工注入常规思路 1.判断是否存在注入,注入是字符型还是数字型 2.猜解 SQL 查询语句中的字段数 3.确定显示的字段顺序 4.获取当前数据库 5.获取数据库中的表 6.获取表中的字段名 7.查询到 ...
- mysql-magic 从dump中获取MySQL的明文密码
项目地址: https://github.com/hc0d3r/mysql-magic 安装: git clone --recurse-submodules https://github.com/hc ...
- 「SAP技术」SAP MM 明明有维护源清单,还是不能下PO?
SAP MM 明明有维护源清单,还是不能下PO? 下午收到用户报错说,创建采购订单失败,报错 :Material ### not included in source list despite sou ...
- Linux中防火墙命令
#启动 systemctl start firewalld #开机启动 systemctl enable firewalld #停止 systemctl stop firewalld #禁 ...
- 代码管理平台之svn
yum install -y subversion(server和client均安装subversion) configure svn:[root@node01 ~]# mkdir -p /data/ ...
- python3实现栈的逻辑
python的队列中本身有很多方法 大家可以看下我的这篇博客,对python的队列的常用方法有简单的介绍 https://www.cnblogs.com/bainianminguo/p/7420685 ...
- 如何提高 PHP 代码的质量?第三:端到端 / 集成测试
在本系列的最后一部分,是时候设置端到端 / 集成测试环境,并确保我们已经准备好检查我们工作的质量. 在本系列的前几部分中,我们建立了一个构建工具,一些静态代码分析器,并开始编写单元测试. 为了使我们的 ...
- django找不到模板的错误处理django.template.exceptions.TemplateDoesNotExist: blog/list.html
错误提示如下图: 程序出错对于程序员而言是最常见的,一般解决的要点是看清错误提示(读懂英文很重要) 根据错误提示 blog\list.html这个文件不存在,也就是没找到资源 这个时候需要去检查有没有 ...