大数据平台搭建 - cdh5.11.1 - hadoop集群安装
一、前言
由于线下测试的需要,需要在公司线下(测试)环境搭建大数据集群。
那么CDH是什么?
hadoop是一个开源项目,所以很多公司再这个基础上进行商业化,不收费的hadoop版本主要有三个,分别是:
(1)Apache,最原始的版本,所有发行版均基于这个版本进行改进
缺点:版本部署混乱,部署过程繁杂,升级过程繁杂,兼容性差,安全性差
(2)CDH版本,在Apache基础上,进行了封装,处理了不同版本的兼容问题。有用户管理界面
(3)Hotnowork版本。
由于公司测试环境的内存有限(8G),cloudera manager需要大量的内存运行服务,所以这里我们选择cdh的tar包安装的方式
二、集群准备
至少三台linux机器,我的配置是:
Linux软件版本:Red Hat Enterprise Linux Server release 6.8 (Santiago)
硬件配置:8核 8G内存120G磁盘空间
一下操作三台机器都需要
(1)所有的安装包都在普通用户下安装,所以要新增一个用户:
useradd hadoop
passwd hadoop
(2)设置普通用户hadoop的sudo权限(root用户)
chmod u+w /etc/sudoers
vi /etc/sudoers
(在首行加入)
hadoop ALL=(root)NOPASSWD:ALL
chmod u-w /etc/sudoers
(3)修改主机名(切换到普通hadoop用户)
sudo vi /etc/sysconfig/netword
(修改:)
HOSTNAME=hadoop001
(其他两台机器修改为hadoop002,hadoop003)
(4)Ip与主机名的映射
sudo vi /etc/hosts
(最末尾加入)
hadoop001 10.7.131.1
hadoop002 10.7.131.2
hadoop003 10.7.131.3
(5)关闭防火墙
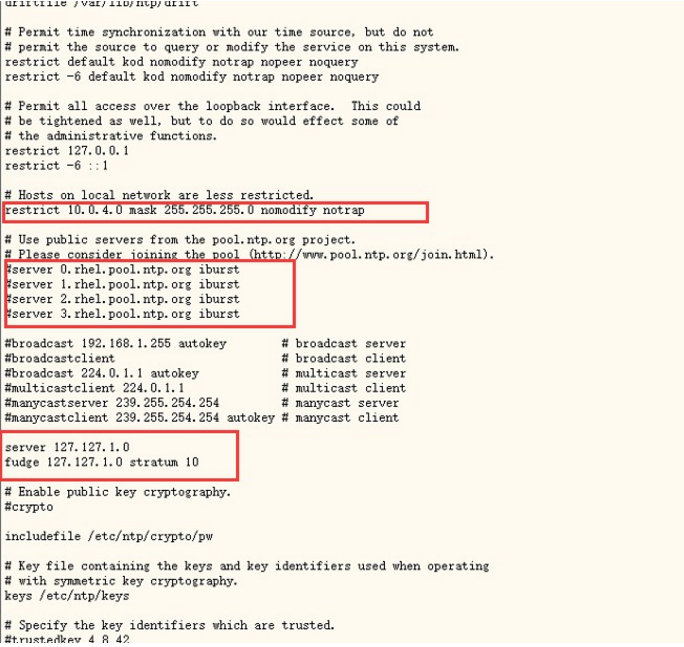
第一个红框处:
restrict 后面的变成机器的网段,比如目前的机器ip是10.7.131.1,那么就填入10.7.131.0
第二个红框处:
注释掉原来的
第三个红框处:
去掉两行注释
sudo vi /etc/sysconfig/ntpd
(首行加入)
SYNC_HWCLOCK=yes
启动ntpd服务
sudo service ntpd status
sudo service ntpd start
sudo chkconfig ntpd on
让hadoop001时间和国家授时中心保持同步(root用户)
三、安装hadoop
1.目录准备
在hadoop用户目录下,规划好目录
app 应用软件安装的地方
software 应用软件包
shell 运行的脚本
data 所有的数据
1.下载hadoop 安装包
http://archive.cloudera.com/cdh5/cdh/5/
所有大数据组件都可以从这里下载到
打开,找到hadoop-2.6.0-cdh5.11.1.tar.gz,下载到本地,并上传到服务器上/home/hadoop/software下
2.解压
tar -zxvf /home/hadoop/software/hadoop-2.6.0-cdh5.11.1.tar.gz -C /home/hadoop/app/
mv /home/hadoop/software/hadoop-2.6.0-cdh5.11.1.tar.gz hadoop
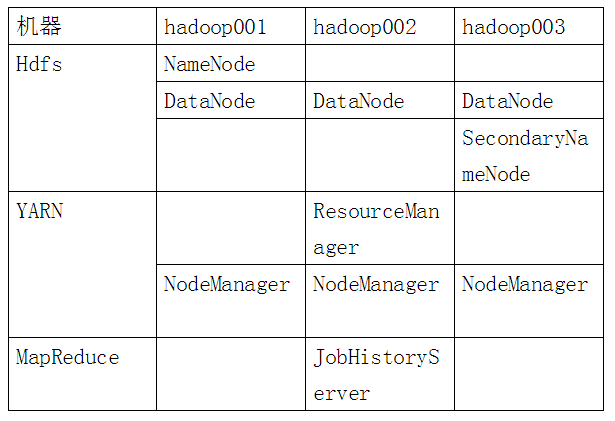
3.hadoop各组件规划
4.配置
1.创建hadoop临时目录
mkdir -p /home/hadoop/app/hadoop/tmp
2.修改hadoop-env.sh
export JAVA_HOME=/home/hadoop/app/jdk
3.修改core-site.xml(/home/hadoop/app/hadoop/etc/hadoop)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>4320</value>
</property>
<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
</configuration>
3.修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop002:50090</value>
</property>
</configuration>
4.修改mapred-env.sh
同样是修改jdk
export JAVA_HOME=/home/hadoop/app/jdk
5.修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop002:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop002:19888</value>
</property>
</configuration>
6.修改yarn-env.sh
if [ "$JAVA_HOME" != "" ]; then
#echo "run java in $JAVA_HOME"
JAVA_HOME=/home/hadoop/app/jdk
fi
7.修改yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop002</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>4</value>
</property>
<!--下面两个配置使日志聚集功能,使日志上传到hdfs上-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>640800</value>
</property>
</configuration>
8.格式化hdfs文件系统
bin/hdfs namenode -format
9.启动hdfs
sbin/start-dfs.sh
10.验证
jps
11.启动yarn
sbin/start-yarn.sh
12.启动jobhistoryserver,运行oozie任务的时候,需要
sbin/mr-jobhistory-daemon.sh start historyserver
12.hdfs web界面访问
hadoop001:50070
13.yarn web界面访问
hadoop002:8088
大数据平台搭建 - cdh5.11.1 - hadoop集群安装的更多相关文章
- 大数据平台搭建 - cdh5.11.1 - hbase集群搭建
一.简介 HBase是一种构建在HDFS之上的分布式.面向列的存储系统.在需要实时读写.随机访问超大规模数据集时,可以使用HBase. 尽管已经有许多数据存储和访问的策略和实现方法,但事实上大多数解决 ...
- 大数据平台搭建 - cdh5.11.1 - oozie安装
一.简介 oozie是hadoop平台开源的工作流调度引擎,用来管理hadoop作业,属于web应用程序,由oozie server 和oozie client构成. oozie server运行与t ...
- 大数据平台搭建 - cdh5.11.1 - hue安装及集成其他组件
一.简介 hue是一个开源的apache hadoop ui系统,由cloudear desktop演化而来,最后cloudera公司将其贡献给了apache基金会的hadoop社区,它基于pytho ...
- 大数据平台搭建 - cdh5.11.1 - spark源码编译及集群搭建
一.spark简介 Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎,Spark 是一种与 hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同 ...
- 大数据平台搭建 - cdh5.11.1 - hive客户端安装
一.简介 hive是基于hadoop的一种数据仓库工具,可以将结构化的文件映射成为数据库的一张表,并提供简单sql查询功能,底层实现是转化为MapReduce任务计算. 二.安装 (1)下载 从cdh ...
- 流式大数据计算实践(2)----Hadoop集群和Zookeeper
一.前言 1.上一文搭建好了Hadoop单机模式,这一文继续搭建Hadoop集群 二.搭建Hadoop集群 1.根据上文的流程得到两台单机模式的机器,并保证两台单机模式正常启动,记得第二台机器core ...
- [大数据学习研究] 错误排查,Hadoop集群部分DataNode不能启动
错误现象 不知道什么原因,今天发现我的hadoop集群启动后datanode只有一台了,我的集群本来有三台的,怎么只剩一台了呢? 用jps命令检查一下,发现果然有两台机器的DataNode没有启动. ...
- 大数据学习系列(7)-- hadoop集群搭建
1.配置ssh免登陆 #进入到我的home目录 cd ~/.ssh ssh-keygen -t rsa 执行完这个命令后,会生成两个文件id_rsa(私钥).id_rsa.pub(公钥) 将公钥拷贝到 ...
- Spark项目之电商用户行为分析大数据平台之(二)CentOS7集群搭建
一.CentOS7集群搭建 1.1 准备3台centos7的虚拟机 IP及主机名规划如下: 192.168.123.110 spark1192.168.123.111 spark2192.168.12 ...
随机推荐
- ABP 配置全局数据过滤器 II
第一篇 那种写法有些复杂, 简单办法是直接注入 切换到 ***.EntityFramework 项目 在Uow 里面创建 ***EfUnitOfWork.cs 类 public class Coope ...
- 基于SpringBoot从零构建博客网站 - 分页显示文章列表功能
显示文章列表一般都是采用分页显示,比如每页10篇文章显示.这样就不用每次就将所有的文章查询出来,而且当文章数量特别多的时候,如果一次性查询出来很容易出现OOM异常. 后台的分页插件采用的是mybati ...
- 定时清理docker私服镜像
定时清理docker私服镜像 使用CI构建docker镜像进行发布极大促进了大家的版本发布效率,于是镜像仓库也就急速膨胀.为了缓解磁盘压力,我们需要设置一些清理策略. 对于不同docker镜像的清理策 ...
- 登录cookies
cookie Cookie 是指某些网站服务器为了辨别用户身份和进行Session跟踪,而储存在用户浏览器上的文本文件,Cookie可以保持登录信息到用户下次与服务器的会话./p> cookie ...
- Delegate,Block,Notification, KVC,KVO,Target-Action
Target-Action: 目标-动作机制,所有的UIControl及子类都是这个机制:原理:在对象产生某个事件的特定时刻,给一个对象发送一个消息:类内部target去执行action方法 Dele ...
- 记录一则AIX使用裸设备安装OracleRAC的问题
需求背景:在AIX6.1上安装Oracle 10g RAC,一线工程师反馈节点2运行root脚本无法成功,跟进排查发现实际上底层存储磁盘的准备工作就存在问题. 客户要求底层存储选用裸设备方式,所以必须 ...
- python 38 线程队列与协程
目录 1. 线程队列 1.1 先进先出(FIFO) 1.2 后进先出(LIFO)堆栈 1.3 优先级队列 2. 事件event 3. 协程 4. Greenlet 模块 5. Gevent模块 1. ...
- ionic 技术要点
1.当遇到数据模型改变了,但是页面渲染的数据却没有改变的时候,尝试执行 $scope.$apply(): 2.时间的定义及监听: 定义事件 showNewMsg并从scope往下广播: $scope. ...
- unity_UGUI养成之路02
1.技能的冷确效果 2.背包的分页效果 1创建背包的总面板,并添加ToggleGroup组件 2.物品面板的实现 3.背包分页的实现 注意:添加了Toggle组件的游戏对象不能再添加button组件. ...
- DOM选择器之元素选择器
DOM中元素选择器 在DOM中我们可以将元素选择器分为两类:1.元素节点选择器:2.其它节点选择器.通过选择器选择HTML中的元素以对其进行操作,以此实现用JS对页面的操作. 一.元素节点选择器 1. ...