RocketMQ4.2 最佳实践之集群搭建
1. 集群物理部署结构

2. 消息落盘和Broker数据同步
2.1 消息落盘
- SYNC_FLUSH(同步刷盘):生产者发送的每一条消息,都在保存到磁盘成功后才回调告诉生产者成功。这种方式不会存在消息丢失的问题,但是有很大的磁盘IO开销,性能有一定影响
- ASYNC_FLUSH(异步刷盘):生产者发送的每一条消息并不是立即保存到磁盘,而是暂时缓存起来,然后就回调告诉生产者成功。随后再异步的将缓存数据保存到磁盘
- 定期将缓存中更新的数据进行落盘
- 当缓存中更新的数据条数达到某一设定值后进行落盘。这种方式会存在消息丢失(在还未来得及同步到磁盘的时候宕机),但是性能很好。默认是这种模式。
2.2 Broker数据同步机制
- 一种是master,即可以写也可以读,其brokerId=0,只能有一个
- 一种是slave,只允许读,其brokerId为非0
- Sync Broker(同步双写):生产者发送的每一条消息都至少同步复制到一个slave后,才返回告诉生产者成功,即“同步双写”
- Async Broker(异步复制):生产者发送的每一条消息只要写入master,就返回告诉生产者成功。然后再“异步复制”到slave
- 上述“2”只是说作为一个集群的最低配置数量,可以根据实际情况扩展
- 所有的刷盘操作全部默认为:ASYNC_FLUSH(异步刷盘)
3. 三种Broker集群方式优缺点
4. 双主集群搭建
5. 双主双从集群搭建
- Sync Broker(同步双写):当生产端生产消息后,主节点和从节点都收到消息,并把消息都同时写入到本地后,才会回复消息
- Async Broker(异步复制):当主节点将数据保存到本地后,直接返回成功的消息,不关系从节点是否写入成功
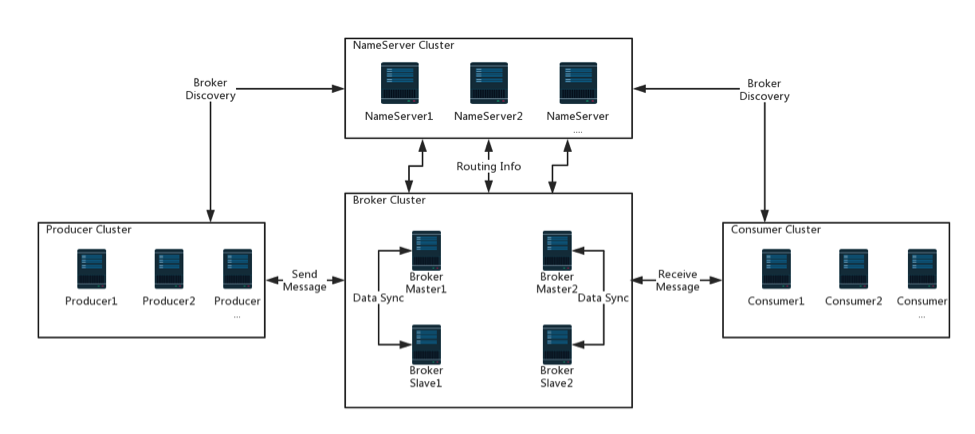
- 消息发送时已经进行了负载均衡,消息比较平均地落在了两个 Broker Set 上
- 在Broker运行时关掉 Broker Master1,Broker Master1 上还没有被消费的数据,会走 Broker Slave1被消费。消费完了再把 Broker Master1 启动,Master1 上没有被消费的数据不会被消费
- 在Broker运行时关掉 Broker Master1,之后的消息会被发到 Broker Master2 上
- 当Master1被加回来,Master1会重新成为主节点,并且与 Master2 还是有负载均衡效果
- Slave1 在 Master1 宕机期间,不会升级成为主节点
6. 参考资料
RocketMQ4.2 最佳实践之集群搭建的更多相关文章
- [转载] Redis集群搭建最佳实践
转载自http://blog.csdn.net/sweetvvck/article/details/38315149?utm_source=tuicool 要搭建Redis集群,首先得考虑下面的几个问 ...
- Redis集群搭建最佳实践
要搭建Redis集群.首先得考虑以下的几个问题; Redis集群搭建的目的是什么?或者说为什么要搭建Redis集群? Redis集群搭建的目的事实上也就是集群搭建的目的.全部的集群主要都是为了解决一个 ...
- 【原创 Hadoop&Spark 动手实践 5】Spark 基础入门,集群搭建以及Spark Shell
Spark 基础入门,集群搭建以及Spark Shell 主要借助Spark基础的PPT,再加上实际的动手操作来加强概念的理解和实践. Spark 安装部署 理论已经了解的差不多了,接下来是实际动手实 ...
- Ocelot+Consul 集群搭建实践
博客园已经有很多大神写过consul集群搭建了.大家都在玩,那我也不能托后退呢 不过自己研究下还是好的.毕竟每个人遇到的问题的不同 研究过才能说自己玩过consul,文章有部分名词解释是收集网络 Co ...
- 【实践】Matlab2016a的mdce集群搭建
Matlab R2016a的mdce集群搭建 1.解压文件Matlab_R2016b_win64.iso. 文件下载地址:链接:https://pan.baidu.com/s/1mjJOaHa 密码: ...
- 【Oracle 集群】Linux下Oracle RAC集群搭建之Oracle DataBase安装(八)
Oracle 11G RAC数据库安装(八) 概述:写下本文档的初衷和动力,来源于上篇的<oracle基本操作手册>.oracle基本操作手册是作者研一假期对oracle基础知识学习的汇总 ...
- RabbitMQ3.6.3集群搭建+HAProxy1.6做负载均衡
目录 [TOC] 1.基本概念 1.1.RabbitMQ集群概述 通过 Erlang 的分布式特性(通过 magic cookie 认证节点)进行 RabbitMQ 集群,各 RabbitMQ 服 ...
- RabbitMQ3.6.3集群搭建+HAProxy1.6做负载均衡
目录 目录 1.基本概念 1.1.RabbitMQ集群概述 1.2.软件负载均衡器HAProxy 2.RabbitMQ的配置步骤 2.1.安装 Erlang.RabbitMQ 2.2.修改 /etc/ ...
- 【转】【Oracle 集群】Linux下Oracle RAC集群搭建之Oracle DataBase安装(八)
原文地址:http://www.cnblogs.com/baiboy/p/orc8.html 阅读目录 目录 数据库安装 参考文献 相关文章 Oracle 11G RAC数据库安装(八) 概述:写 ...
随机推荐
- Linux系统学习之Ln(软连接和硬链接)
可简单理解为,软连接:创建的软连接文件是源文件的快捷方式,删除创建的软连接文件,源文件不受影响,连接消失. 硬链接:两个连体的文件,修改其中一个文件,另外一个文件也会随之更改:删除其中一个文件,另外一 ...
- Nodejs 发送邮件 激活邮箱
1. 安装nodemailer npm install nodemailer 项目中引入nodemailer var nodemailer = require('nodemailer'); 2.QQ邮 ...
- One layer SoftMax Classifier, "Handwriting recognition"
import lib needed¶ In [1]: from PIL import Image import numpy as np import matplotlib.pyplot as ...
- 什么是VR中的vection?
Vection是VR领域的一个专有名词,其义指“在虚拟现实中给人带来‘移动’(self-motion)感觉的认知因素”1.也就是说,vection就是指那些给玩家带来“我正在这个虚拟环境中移动”这种感 ...
- MongoDB 学习笔记之 入门安装和配置
下载MongoDB: 下载解压即可使用. 为了启动方便和统一管理, 在Mongo根目录下建立/data, /logs, /conf文件夹. 在conf文件夹下建立mongodb.conf 文件,基本配 ...
- 每个新手程序员都必须知道的Python技巧
当下,Python 比以往的任何时候都更加流行,人们每天都在实践着 Python 是多么的强大且易用. 我从事 Python 编程已经有几年时间了,但是最近6个月才是全职的.下面列举的这些事情,是我最 ...
- Flutter学习笔记(29)--Flutter如何与native进行通信
如需转载,请注明出处:Flutter学习笔记(29)--Flutter如何与native进行通信 前言:在我们开发Flutter项目的时候,难免会遇到需要调用native api或者是其他的情况,这时 ...
- BUUCTF刷题记录(Web方面)
WarmUp 首先查看源码,发现有source.php,跟进看看,发现了一堆代码 这个原本是phpmyadmin任意文件包含漏洞,这里面只不过是换汤不换药. 有兴趣的可以看一下之前我做的分析,http ...
- 在我的新书里,尝试着用股票案例讲述Python爬虫大数据可视化等知识
我的新书,<基于股票大数据分析的Python入门实战>,预计将于2019年底在清华出版社出版. 如果大家对大数据分析有兴趣,又想学习Python,这本书是一本不错的选择.从知识体系上来看, ...
- Docker 安装Oracle
1.使用docker 命令搜索oracle 镜像,前提是已安装了Docker docker search oracle 2.下载相应版本的oracle 镜像 docker pull sath89/o ...