Scrapy项目 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
通过使Scrapy框架,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,进行数据挖掘和对web站点页面提取结构化数据,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求,使得我们的爬虫更强大、更高效。
一、项目分析
豆瓣电影网页爬虫,要求使用scrapy框架爬取豆瓣电影 Top 250网页(https://movie.douban.com/top250?start=0)上所罗列上映电影的标题、主要信息、评分和电影简介等的信息,将所爬取的内容保存输出为CSV和JSON格式文件,在python程序代码中要求将所输出显示的内容进行utf-8类型编码。
1. 网页分析
对于本例实验,要求爬取的豆瓣电影 Top 250网页上的电影信息,显而易见,网页(https://movie.douban.com/top250?start=0)的页面布局结构可如图2-1所示:
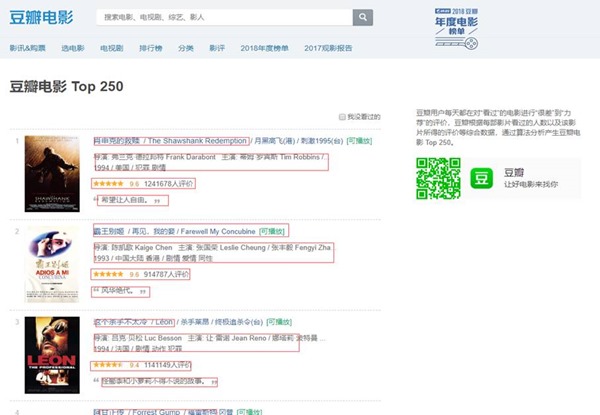
图1-1 所要爬取的信息页面布局
使用xpath_helper_2_0_2辅助工具,对其中上映电影的标题、主要信息、评分和电影简介等的信息内容进行xpath语法分析如下:
标题://div[@class='info']//span[@class='title'][1]/text()
信息://div[@class='info']//div[@class='bd']/p[@class='']/text()
评分:.//div[@class='bd']/div[@class='star']/span[@class='rating_num']/text()
简介://div[@class='info']//div[@class='bd']/p[@class='quote']/span/text()
2. url分析
获取url进行解析移交给scrapy,而对于request类,含有的参数 url 与callback回调函数为parse_details。出现搜索到的url不全,加上当前目录的url拼接,采用prase.urljoin(base,url),最后获取下一页url交给scrapy ,再用Request进行返回。
换句话说,Spiders处理response时,提取数据并将数据经ScrapyEngine交给ItemPipeline保存,提取url重新经ScrapyEngine交给Scheduler进行下一个循环。直到无Url请求程序停止结束。
二、项目工具
Python 3.7.1 、 JetBrains PyCharm 2018.3.2 其它辅助工具:略
三、项目过程
(一)使用Xmind工具对Python爬虫程序(网络爬虫)流程图进行分析,绘制如图3-1所示的程序逻辑框架图:
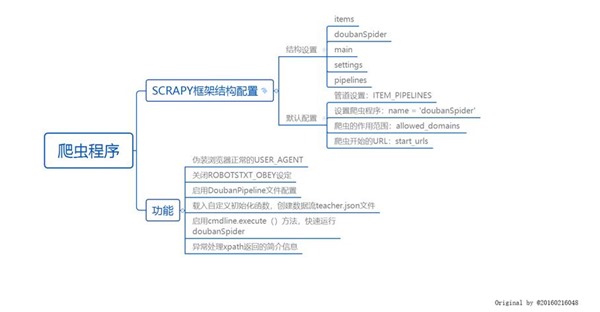
图3-1 程序逻辑框架图
(二)爬虫程序调试过程BUG描述(截图)
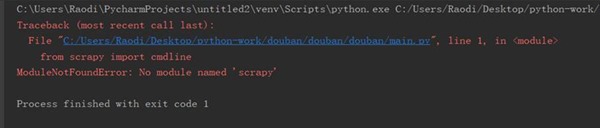
图3-2 爬虫程序BUG描述①
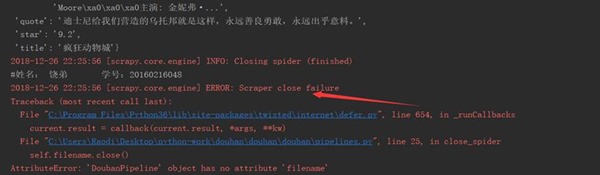
图3-3 爬虫程序BUG描述②
(三)爬虫运行结果
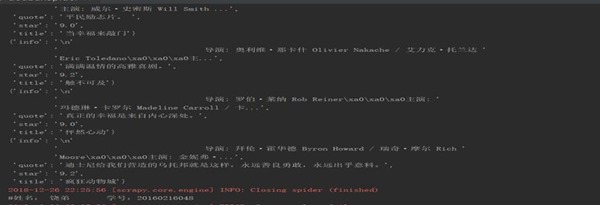
图3-4 爬虫程序输出运行结果1
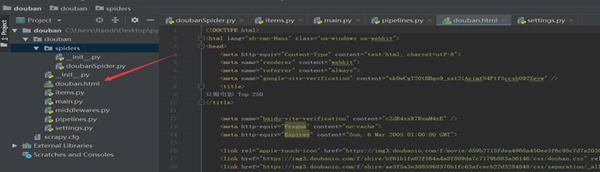
图3-5 爬虫程序输出文件
四、项目心得
关于本例实验心得可总结如下:
1、 当Scrapy执行crawl命令报错:ModuleNotFoundError: No module named ***时,应该首先检查Project Interpreter是否为系统安装的python环境路径,如图4-1所示:
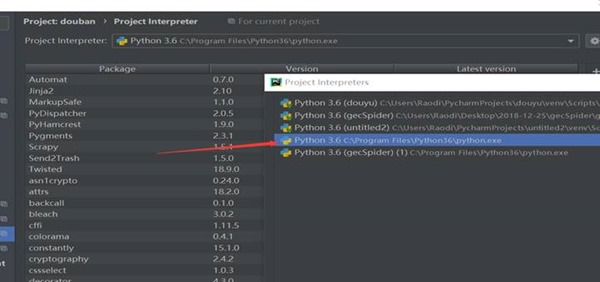
图4-1 检查Project Interpreter路径
2、 schelduler会按照一定的次序取出请求,经由引擎, 下载器中间键,发送给下载器dowmloader 这里的下载器中间键是设定在请求执行前,因此可以设定代理,请求头,cookie等
3、 spider打开某网页,获取到一个或者多个request,经由scrapy engine传送给调度器scheduler request特别多并且速度特别快会在scheduler形成请求队列queue,由scheduler安排执行
Scrapy项目 - 实现豆瓣 Top250 电影信息爬取的爬虫设计的更多相关文章
- Scrapy项目 - 源码工程 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
一.项目目录结构 spiders文件夹内包含doubanSpider.py文件,对于项目的构建以及结构逻辑,详见环境搭建篇. 二.项目源码 1.doubanSpider.py # -*- coding ...
- Scrapy项目 - 数据简析 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
一.数据分析截图(weka数据分析截图 ) 本例实验,使用Weka 3.7对豆瓣电影网页上所罗列的上映电影信息,如:标题.主要信息(年份.国家.类型)和评分等的信息进行数据分析,Weka 3.7数据分 ...
- Scrapy项目 - 实现斗鱼直播网站信息爬取的爬虫设计
要求编写的程序可爬取斗鱼直播网站上的直播信息,如:房间数,直播类别和人气等.熟悉掌握基本的网页和url分析,同时能灵活使用Xmind工具对Python爬虫程序(网络爬虫)流程图进行分析. 一.项目 ...
- Scrapy项目 - 实现腾讯网站社会招聘信息爬取的爬虫设计
通过使Scrapy框架,进行数据挖掘和对web站点页面提取结构化数据,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求 ...
- python 豆瓣top250电影的爬取
我们先看一下豆瓣的robot.txt 然后我们查看top250的网页链接和源代码 通过对比不难发现网页间只是start数字发生了变化. 我们可以知道电影内容都存在ol标签下的 div class属性为 ...
- Scrapy项目 - 数据简析 - 实现斗鱼直播网站信息爬取的爬虫设计
一.数据分析截图(weka数据分析截图 2-3个图,作业文字描述) 本次将所爬取的数据信息,如:房间数,直播类别和人气,导入Weka 3.7工具进行数据分析.有关本次的数据分析详情详见下图所示: ...
- Scrapy项目 - 数据简析 - 实现腾讯网站社会招聘信息爬取的爬虫设计
一.数据分析截图 本例实验,使用Weka 3.7对腾讯招聘官网中网页上所罗列的招聘信息,如:其中的职位名称.链接.职位类别.人数.地点和发布时间等信息进行数据分析,详见如下图: 图1-1 Weka ...
- Scrapy项目 - 项目源码 - 实现腾讯网站社会招聘信息爬取的爬虫设计
1.tencentSpider.py # -*- coding: utf-8 -*- import scrapy from Tencent.items import TencentItem #创建爬虫 ...
- requests爬取豆瓣top250电影信息
''' 1.爬取豆瓣top250电影信息 - 第一页: https://movie.douban.com/top250?start=0&filter= - 第二页: https://movie ...
随机推荐
- 人员考勤,MySQLl数据库一个表自动生成3表筛选人员迟到早退缺勤
前言:漂亮的人事小姐姐找我帮忙弄考勤:由于人员考勤和门禁一起,打卡记录太多,打卡机只能导出一个打卡Excel总表,不容易人工筛选. Excel表的格式是这样的:(这里101代替真实人名) 实现目标: ...
- Leetcode之深度优先搜索&回溯专题-491. 递增子序列(Increasing Subsequences)
Leetcode之深度优先搜索&回溯专题-491. 递增子序列(Increasing Subsequences) 深度优先搜索的解题详细介绍,点击 给定一个整型数组, 你的任务是找到所有该数组 ...
- 11 python与redis交互
安装:pip install redis 导入模块:from redis import * 创建StrictRedis 通过init创建对象,指定参数host.port与指定的服务器和端口连接. ho ...
- vue+vscode+nodejs 开发环境搭建
nodejs安装配置 1.下载 地址:https://nodejs.org/en/ 2.默认安装 安装完成后,执行npm -v 出现版本号则表示安装成功. 3.配置 在node安装目录下新建两个文件夹 ...
- 网页播放摄像头视频一种新的实现方式(非ocx方式)
前言 出于安全性考虑,浏览器对网页调用本地资源做了诸多限制.单纯的js是不能调用本地摄像头的,最常用的解决方案是通过ocx来实现.ocx是IE浏览器的扩展插件,并不是通用标准,很多浏览器并不支持ocx ...
- codeforces 688 E. The Values You Can Make(01背包+思维)
题目链接:http://codeforces.com/contest/688/problem/E 题解:设dp[s1][s2]表示s1状态下出现s2是否合理.那么s1显然可以更具01背包来得到状态.首 ...
- 天梯杯 PAT L2-001. 紧急救援 最短路变形
作为一个城市的应急救援队伍的负责人,你有一张特殊的全国地图.在地图上显示有多个分散的城市和一些连接城市的快速道路.每个城市的救援队数量和每一条连接两个城市的快速道路长度都标在地图上.当其他城市有紧急求 ...
- Springboot2.x 自动创建表并且执行初始化数据
1.使用springboot jdbc初始化数据库 项目结构 schema.sql drop table if exists user; create table user (id bigint(20 ...
- Mysql高手系列 - 第7篇:玩转select条件查询,避免踩坑
这是Mysql系列第7篇. 环境:mysql5.7.25,cmd命令中进行演示. 电商中:我们想查看某个用户所有的订单,或者想查看某个用户在某个时间段内所有的订单,此时我们需要对订单表数据进行筛选,按 ...
- 013 turtle程序语法元素分析
目录 一.概述 二.库引用与import 2.1 库引用 2.2 使用from和import保留字共同完成库引用 2.3 两种库引用方法比较 2.4 使用import和as保留字共同完成库引用 三.t ...