Scrapy项目 - 实现腾讯网站社会招聘信息爬取的爬虫设计
通过使Scrapy框架,进行数据挖掘和对web站点页面提取结构化数据,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求,使得我们的爬虫更强大、更高效。
熟悉掌握基本的网页和url分析,同时能灵活使用Xmind工具对Python爬虫程序(网络爬虫)流程图进行分析。同时,使用Weka 3.7工具,对所获取得到的数据进行数据挖掘分析操作。
一、项目分析
本次的实验内容要求使用scrapy框架,爬取腾讯招聘官网中网页(https://hr.tencent.com/position.php?&start=0)上所罗列的招聘信息,如:其中的职位名称、链接、职位类别、人数、地点和发布时间。并且将所爬取的内容保存输出为CSV和JSON格式文件,在python程序代码中要求将所输出显示的内容进行utf-8类型编码。
1. 网页分析
在本例实验开始之前,需要对所要求爬取的腾讯招聘网页进行网页分析,其中(https://hr.tencent.com/position.php?&start=0)的界面布局结构可如图2-1所示:
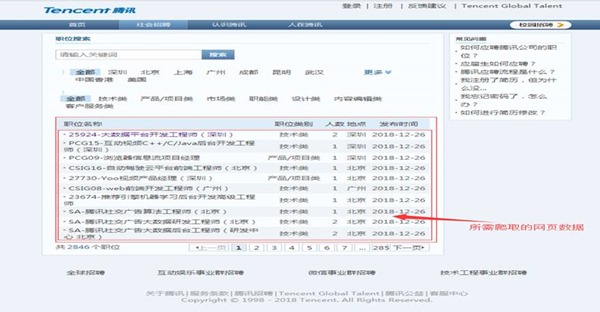
图1-1 所要爬取的信息页面布局
使用xpath_helper_2_0_2辅助工具,对其中招聘信息的职位名称、链接、职位类别、人数、地点和发布时间等信息内容进行xpath语法分析如下:
职位名称: //td[@class='l square']/a/text()
链 接: //td[@class='l square']/a/@href
职位类别://tr[@class='odd']/td[2]/text()|//tr[@class='even']/td[2]/text()
人 数://tr[@class='odd']/td[3]/text()|//tr[@class='even']/td[3]/text()
地 点://tr[@class='odd']/td[4]/text()|//tr[@class='even']/td[4]/text()
发布时间://tr[@class='odd']/td[5]/text()|//tr[@class='even']/td[5]/text()
2. url分析
scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量代码,就能够快速的抓取到数据内容。
首先程序将需要发送请求的url(requests)经ScrapyEngine(引擎)交给Scheduler(调度器)。在Scheduler(排序,入队)处理后,经ScrapyEngine,DownloaderMiddlewares交给Downloader,再向互联网发送请求,并接收下载响应(response)。
最后,将响应(response)经ScrapyEngine,SpiderMiddlewares(可选)交给Spiders的同时。Spiders处理response,提取数据并将数据经ScrapyEngine交给ItemPipeline保存,提取url重新经ScrapyEngine交给Scheduler进行下一个循环。直到无Url请求程序停止结束。
二、项目工具
实验软件:Python 3.7.1 、 JetBrains PyCharm 2018.3.2 、 其它辅助工具:略
三、项目过程
(一)使用Xmind工具对Python爬虫程序(网络爬虫)流程图进行分析,绘制如图3-1所示的程序逻辑框架图
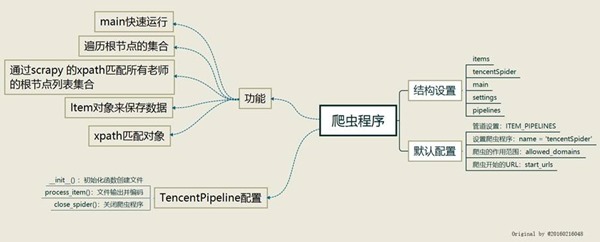
图3-1 程序逻辑框架图
(二)爬虫程序调试过程BUG描述(截图)
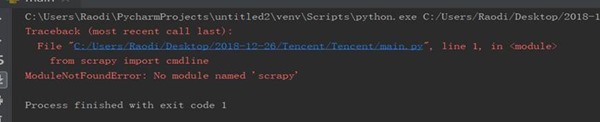
图3-2 爬虫程序BUG描述①

图3-3 爬虫程序BUG描述②
(三)爬虫运行结果
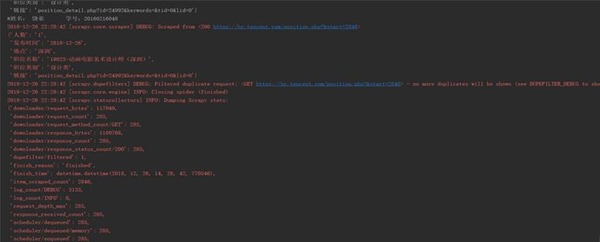
图3-4 爬虫程序输出运行结果1
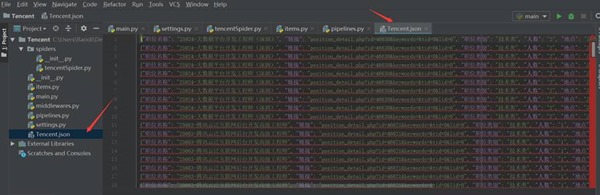
图3-5 爬虫程序输出文件
四、项目心得
关于本例实验心得可总结如下:
1、 解决图3-4的程序错误,只需在gec.py的文件中进行导入操作:from Tencent.items import TencentItem 即可。对于解决如图4-1所示的内容,请如图5-1所示:
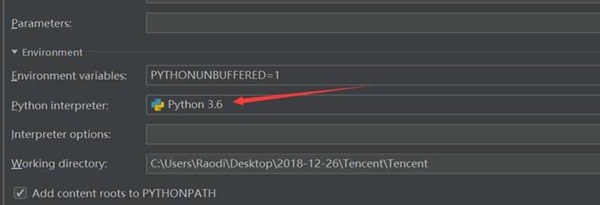
图4-1 程序错误纠正
2、 spider打开某网页,获取到一个或者多个request,经由scrapy engine传送给调度器scheduler request特别多并且速度特别快会在scheduler形成请求队列queue,由scheduler安排执行
3、 schelduler会按照一定的次序取出请求,经由引擎, 下载器中间键,发送给下载器dowmloader 这里的下载器中间键是设定在请求执行前,因此可以设定代理,请求头,cookie等
4、 下载下来的网页数据再次经过下载器中间键,经过引擎,经过爬虫中间键传送给爬虫spiders 这里的下载器中间键是设定在请求执行后,因此可以修改请求的结果 这里的爬虫中间键是设定在数据或者请求到达爬虫之前,与下载器中间键有类似的功能
5、 由爬虫spider对下载下来的数据进行解析,按照item设定的数据结构经由爬虫中间键,引擎发送给项目管道itempipeline 这里的项目管道itempipeline可以对数据进行进一步的清洗,存储等操作 这里爬虫极有可能从数据中解析到进一步的请求request,它会把请求经由引擎重新发送给调度器shelduler,调度器循环执行上述操作
Scrapy项目 - 实现腾讯网站社会招聘信息爬取的爬虫设计的更多相关文章
- Scrapy项目 - 数据简析 - 实现腾讯网站社会招聘信息爬取的爬虫设计
一.数据分析截图 本例实验,使用Weka 3.7对腾讯招聘官网中网页上所罗列的招聘信息,如:其中的职位名称.链接.职位类别.人数.地点和发布时间等信息进行数据分析,详见如下图: 图1-1 Weka ...
- Scrapy项目 - 项目源码 - 实现腾讯网站社会招聘信息爬取的爬虫设计
1.tencentSpider.py # -*- coding: utf-8 -*- import scrapy from Tencent.items import TencentItem #创建爬虫 ...
- Scrapy项目 - 实现斗鱼直播网站信息爬取的爬虫设计
要求编写的程序可爬取斗鱼直播网站上的直播信息,如:房间数,直播类别和人气等.熟悉掌握基本的网页和url分析,同时能灵活使用Xmind工具对Python爬虫程序(网络爬虫)流程图进行分析. 一.项目 ...
- Scrapy项目 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
通过使Scrapy框架,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,进行数据挖掘和对web站点页面提取结构化数据,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求 ...
- Scrapy项目 - 数据简析 - 实现斗鱼直播网站信息爬取的爬虫设计
一.数据分析截图(weka数据分析截图 2-3个图,作业文字描述) 本次将所爬取的数据信息,如:房间数,直播类别和人气,导入Weka 3.7工具进行数据分析.有关本次的数据分析详情详见下图所示: ...
- Scrapy项目 - 源码工程 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
一.项目目录结构 spiders文件夹内包含doubanSpider.py文件,对于项目的构建以及结构逻辑,详见环境搭建篇. 二.项目源码 1.doubanSpider.py # -*- coding ...
- Scrapy项目 - 数据简析 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
一.数据分析截图(weka数据分析截图 ) 本例实验,使用Weka 3.7对豆瓣电影网页上所罗列的上映电影信息,如:标题.主要信息(年份.国家.类型)和评分等的信息进行数据分析,Weka 3.7数据分 ...
- Scrapy案例02-腾讯招聘信息爬取
目录 1. 目标 2. 网站结构分析 3. 编写爬虫程序 3.1. 配置需要爬取的目标变量 3.2. 写爬虫文件scrapy 3.3. 编写yield需要的管道文件 3.4. setting中配置请求 ...
- Scrapy项目 - 实现百度贴吧帖子主题及图片爬取的爬虫设计
要求编写的程序可获取任一贴吧页面中的帖子链接,并爬取贴子中用户发表的图片,在此过程中使用user agent 伪装和轮换,解决爬虫ip被目标网站封禁的问题.熟悉掌握基本的网页和url分析,同时能灵活使 ...
随机推荐
- python 21 面向对象
目录 1. 面向对象初步认识 2. 面向对象的结构 3. 从类名的角度研究类 3.1 类名操作类中的属性 3.2 类名调用类中的方法 4. 从对象的角度研究类 4.1 类名() 4.2 对象操作对象空 ...
- 关卡界面中个人信息随解锁关卡的移动(CocosCreator)
推荐阅读: 我的CSDN 我的博客园 QQ群:704621321 1.功能描述 在关卡很多的游戏里面,我们一般使用滑动来向玩家展示所有的关卡,为了清楚的让用户看到自己当前所在的关卡, ...
- Gym 101510C
题意略. 思路: 由于xi的选取是任意的,所以我们不用去理会题目中的xi数列条件.主要是把关注点放在长度为L的线段覆盖至少k个整数这个条件上. 像这种取到最小的合法解的问题,我们应该要想到使用二分法来 ...
- Leetcode之二分法专题-240. 搜索二维矩阵 II(Search a 2D Matrix II)
Leetcode之二分法专题-240. 搜索二维矩阵 II(Search a 2D Matrix II) 编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target.该矩阵 ...
- parseInt和Number的应用区别
parseInt() 和 Number()的应用区别 这两个函数最多的应用就是把一个字符串转换成数据类型. 1.parseInt() parseInt()函数将给定的字符串以指定的基数解析为整数 语法 ...
- Django之使用中间件解决前后端同源策略问题
问题描述 前端时间在公司的时候,要使用angular开发一个网站,因为angular很适合前后端分离,所以就做了一个简单的图书管理系统来模拟前后端分离. 但是在开发过程中遇见了同源策略的跨域问题,页面 ...
- 漫话:如何给女朋友解释什么是"锟斤拷"?
漫话:如何给女朋友解释什么是"锟斤拷"? 周末女朋友出去逛街了,我自己一个人在家看综艺节目,突然,女朋友给我打来电话. 过了一会,女朋友回来了,她拿出手机,给我看了她在超市拍的 ...
- HAOI2006 (洛谷P2341)受欢迎的牛 题解
HAOI2006 (洛谷P2341)受欢迎的牛 题解 题目描述 友情链接原题 每头奶牛都梦想成为牛棚里的明星.被所有奶牛喜欢的奶牛就是一头明星奶牛.所有奶 牛都是自恋狂,每头奶牛总是喜欢自己的.奶牛之 ...
- 2018中国大学生程序设计竞赛 - 网络选拔赛 hdu Find Integer 数论
Find Integer Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Tota ...
- JOBDU 1140 八皇后
题目1140:八皇后 时间限制:1 秒 内存限制:32 兆 特殊判题:否 提交:1064 解决:665 题目描述: 会下国际象棋的人都很清楚:皇后可以在横.竖.斜线上不限步数地吃掉其他棋子.如何将8个 ...