Scrapy项目 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
通过使Scrapy框架,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,进行数据挖掘和对web站点页面提取结构化数据,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求,使得我们的爬虫更强大、更高效。
一、项目分析
豆瓣电影网页爬虫,要求使用scrapy框架爬取豆瓣电影 Top 250网页(https://movie.douban.com/top250?start=0)上所罗列上映电影的标题、主要信息、评分和电影简介等的信息,将所爬取的内容保存输出为CSV和JSON格式文件,在python程序代码中要求将所输出显示的内容进行utf-8类型编码。
1. 网页分析
对于本例实验,要求爬取的豆瓣电影 Top 250网页上的电影信息,显而易见,网页(https://movie.douban.com/top250?start=0)的页面布局结构可如图2-1所示:
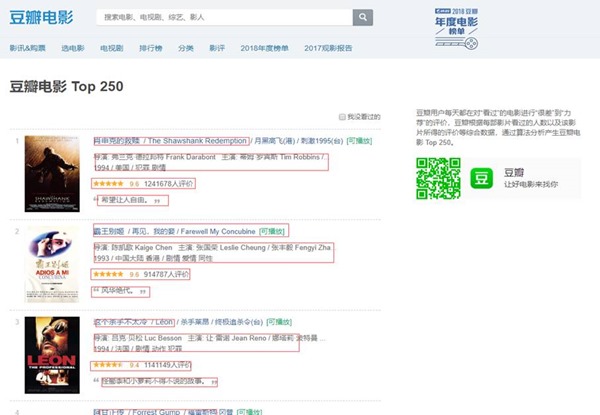
图1-1 所要爬取的信息页面布局
使用xpath_helper_2_0_2辅助工具,对其中上映电影的标题、主要信息、评分和电影简介等的信息内容进行xpath语法分析如下:
标题://div[@class='info']//span[@class='title'][1]/text()
信息://div[@class='info']//div[@class='bd']/p[@class='']/text()
评分:.//div[@class='bd']/div[@class='star']/span[@class='rating_num']/text()
简介://div[@class='info']//div[@class='bd']/p[@class='quote']/span/text()
2. url分析
获取url进行解析移交给scrapy,而对于request类,含有的参数 url 与callback回调函数为parse_details。出现搜索到的url不全,加上当前目录的url拼接,采用prase.urljoin(base,url),最后获取下一页url交给scrapy ,再用Request进行返回。
换句话说,Spiders处理response时,提取数据并将数据经ScrapyEngine交给ItemPipeline保存,提取url重新经ScrapyEngine交给Scheduler进行下一个循环。直到无Url请求程序停止结束。
二、项目工具
Python 3.7.1 、 JetBrains PyCharm 2018.3.2 其它辅助工具:略
三、项目过程
(一)使用Xmind工具对Python爬虫程序(网络爬虫)流程图进行分析,绘制如图3-1所示的程序逻辑框架图:
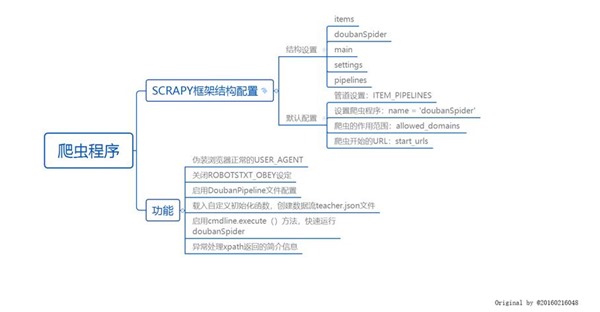
图3-1 程序逻辑框架图
(二)爬虫程序调试过程BUG描述(截图)
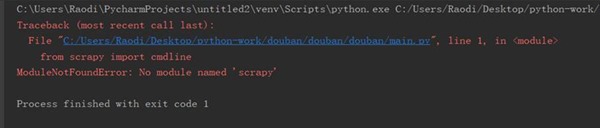
图3-2 爬虫程序BUG描述①
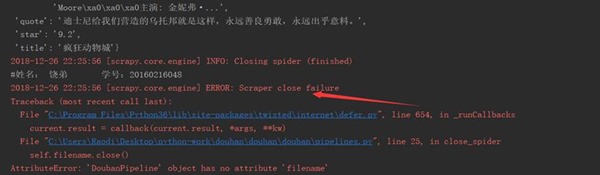
图3-3 爬虫程序BUG描述②
(三)爬虫运行结果
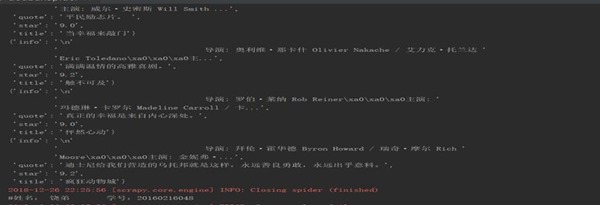
图3-4 爬虫程序输出运行结果1
图3-5 爬虫程序输出文件
四、项目心得
关于本例实验心得可总结如下:
1、 当Scrapy执行crawl命令报错:ModuleNotFoundError: No module named ***时,应该首先检查Project Interpreter是否为系统安装的python环境路径,如图4-1所示:
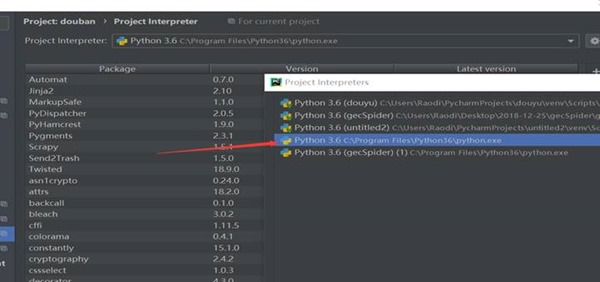
图4-1 检查Project Interpreter路径
2、 schelduler会按照一定的次序取出请求,经由引擎, 下载器中间键,发送给下载器dowmloader 这里的下载器中间键是设定在请求执行前,因此可以设定代理,请求头,cookie等
3、 spider打开某网页,获取到一个或者多个request,经由scrapy engine传送给调度器scheduler request特别多并且速度特别快会在scheduler形成请求队列queue,由scheduler安排执行
Scrapy项目 - 实现豆瓣 Top250 电影信息爬取的爬虫设计的更多相关文章
- Scrapy项目 - 源码工程 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
一.项目目录结构 spiders文件夹内包含doubanSpider.py文件,对于项目的构建以及结构逻辑,详见环境搭建篇. 二.项目源码 1.doubanSpider.py # -*- coding ...
- Scrapy项目 - 数据简析 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
一.数据分析截图(weka数据分析截图 ) 本例实验,使用Weka 3.7对豆瓣电影网页上所罗列的上映电影信息,如:标题.主要信息(年份.国家.类型)和评分等的信息进行数据分析,Weka 3.7数据分 ...
- Scrapy项目 - 实现斗鱼直播网站信息爬取的爬虫设计
要求编写的程序可爬取斗鱼直播网站上的直播信息,如:房间数,直播类别和人气等.熟悉掌握基本的网页和url分析,同时能灵活使用Xmind工具对Python爬虫程序(网络爬虫)流程图进行分析. 一.项目 ...
- Scrapy项目 - 实现腾讯网站社会招聘信息爬取的爬虫设计
通过使Scrapy框架,进行数据挖掘和对web站点页面提取结构化数据,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求 ...
- python 豆瓣top250电影的爬取
我们先看一下豆瓣的robot.txt 然后我们查看top250的网页链接和源代码 通过对比不难发现网页间只是start数字发生了变化. 我们可以知道电影内容都存在ol标签下的 div class属性为 ...
- Scrapy项目 - 数据简析 - 实现斗鱼直播网站信息爬取的爬虫设计
一.数据分析截图(weka数据分析截图 2-3个图,作业文字描述) 本次将所爬取的数据信息,如:房间数,直播类别和人气,导入Weka 3.7工具进行数据分析.有关本次的数据分析详情详见下图所示: ...
- Scrapy项目 - 数据简析 - 实现腾讯网站社会招聘信息爬取的爬虫设计
一.数据分析截图 本例实验,使用Weka 3.7对腾讯招聘官网中网页上所罗列的招聘信息,如:其中的职位名称.链接.职位类别.人数.地点和发布时间等信息进行数据分析,详见如下图: 图1-1 Weka ...
- Scrapy项目 - 项目源码 - 实现腾讯网站社会招聘信息爬取的爬虫设计
1.tencentSpider.py # -*- coding: utf-8 -*- import scrapy from Tencent.items import TencentItem #创建爬虫 ...
- requests爬取豆瓣top250电影信息
''' 1.爬取豆瓣top250电影信息 - 第一页: https://movie.douban.com/top250?start=0&filter= - 第二页: https://movie ...
随机推荐
- getline()与get()(c++学习笔记)
istream中的类(如cin)提供了一些面向行的类成员函数:getline()和get() 1.getline()函数 读取整行,使用回车键输入的换行符来确定输入结尾. 调用方法:cin.getli ...
- js获取Cookie,获取url参数
function getCookie(name) { var strCookie = document.cookie; var arrCookie = strCookie.split("; ...
- CentOS -- Zookeeper installation and configure
1 JDK 1.8 must installed first 2 Get Zookeeper package wget https://archive.apache.org/dist/zookeepe ...
- 🕸捕获与改写HTTPS请求
前言 本文站在 macOS 用户的角度下,分享一下对 HTTPS 进行请求拦截.对响应进行修改的经验. 要注意的是,本文介绍的工具虽然一定程度上对 Windows 用户也适用 ,但并非所有工具都是免费 ...
- 一行js代码实现时间戳转时间格式
javascript时间戳转换,支持自定义格式,可以显示年,月,周,日,时,分,秒多种形式的日期和时间. 推荐一个JavaScript常用函数库 jutils jutils - JavaScript常 ...
- Date与String之间相互转换
项目中经常用到,Date类型与String类型的转换,所以写个工具类 直接贴代码: package com.elite.isun.utils; import java.text.ParseExcept ...
- HibernateSynchronizer的安装与使用
HibernateSynchronizer的作用是自动生成hibernate配置文件,即hibernate.cfg.xml文件,映射文件,Plain Object类文件和一些基础数据库操作文件. 安装 ...
- HDU 6394 Tree 分块 || lct
Tree 题意: 给你一颗树, 每一个节点都有一个权值, 如果一个石头落在某个节点上, 他就会往上跳这个的点的权值步. 现在有2种操作, 1 把一个石头放在 x 的位置 询问有跳几次才跳出这棵树, 2 ...
- 主席树区间第K大
主席树的实质其实还是一颗线段树, 然后每一次修改都通过上一次的线段树,来添加新边,使得每次改变就改变logn个节点,很多节点重复利用,达到节省空间的目的. 1.不带修改的区间第K大. HDU-2665 ...
- codeforces 245 D. Restoring Table(位运算+思维)
题目链接:http://codeforces.com/contest/245/problem/D 题意:给出一个矩阵b,b[i][j]=a[i]&a[j],b[i][i]=-1.然后求a[i] ...