Hadoop---集群的搭建(仅主机模式)
Hadoop---集群的搭建
我有一个虚拟机是用来克隆的,里面设置了java环境,开启不启动防火墙的配置。
准备:
1.我的3个虚拟机:
hu_hadoop1(主+从):nameNode+dataNode+ResouceManager
hu_hadoop2(从):dataNode+nodeManager+secondaryNameNode(秘书)
hu_hadoop3(从):dataNode+nodeManager
这样的话就是有一主三从。

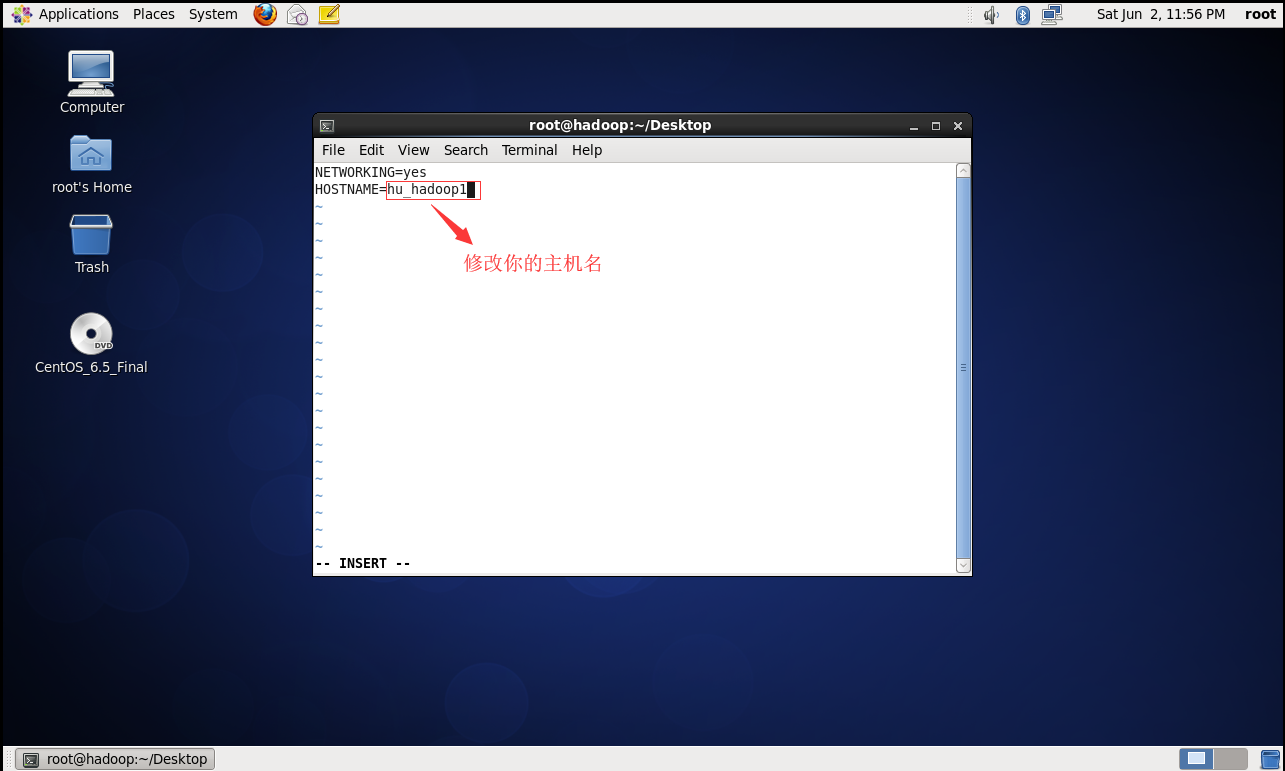
2.开机启动,修改配置文件:
完成后重启 init 6 (每台机器都做这样的配置)
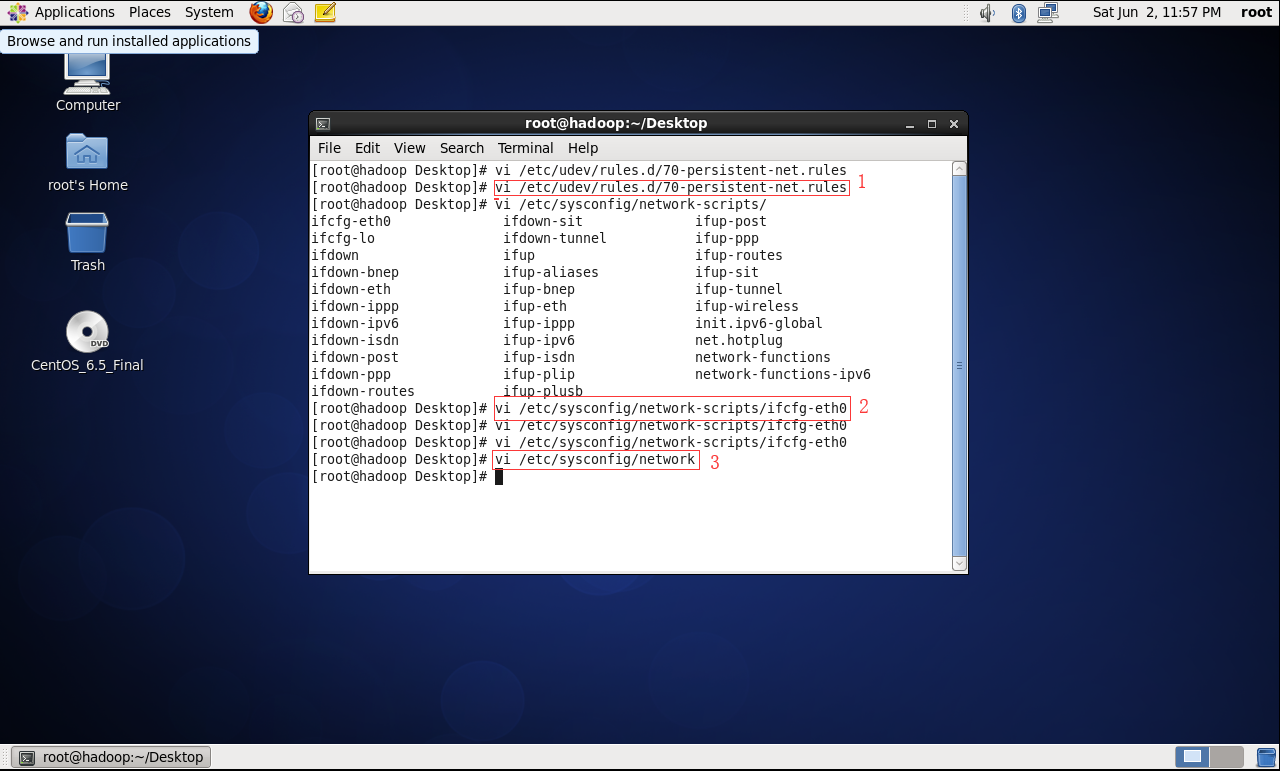
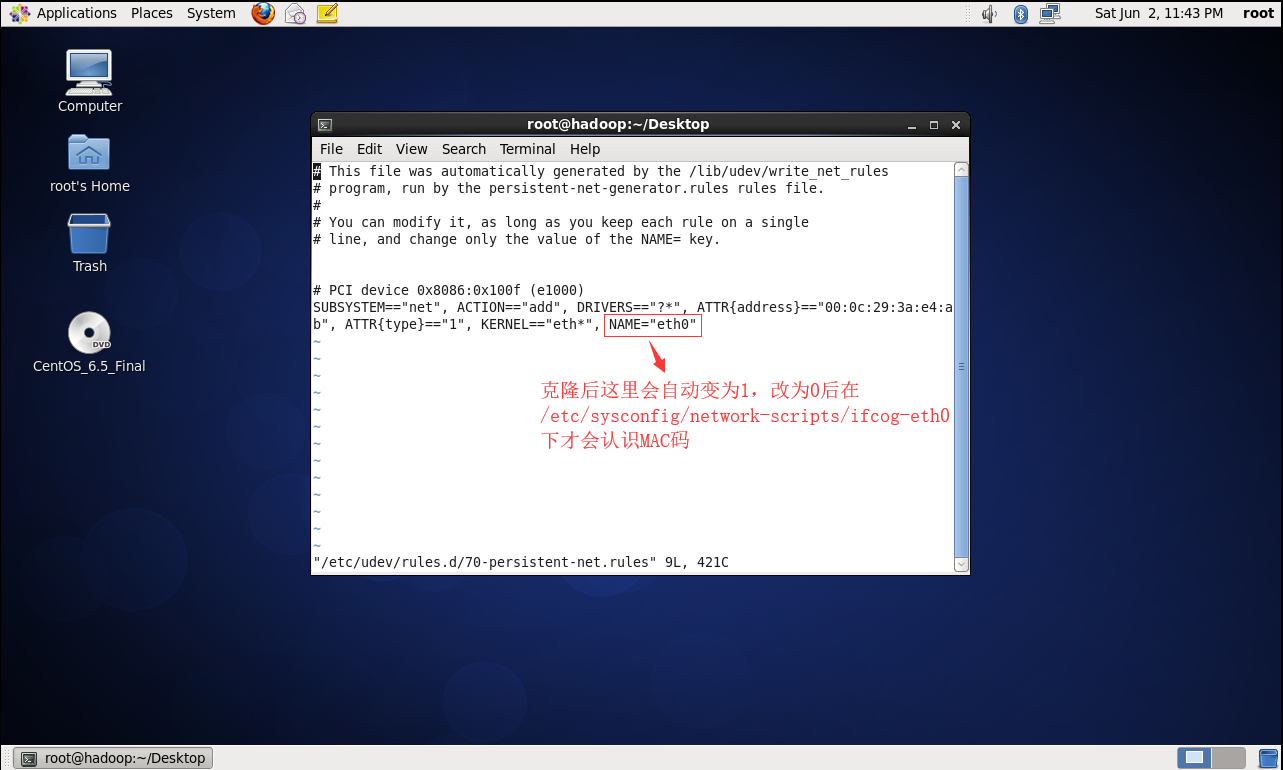
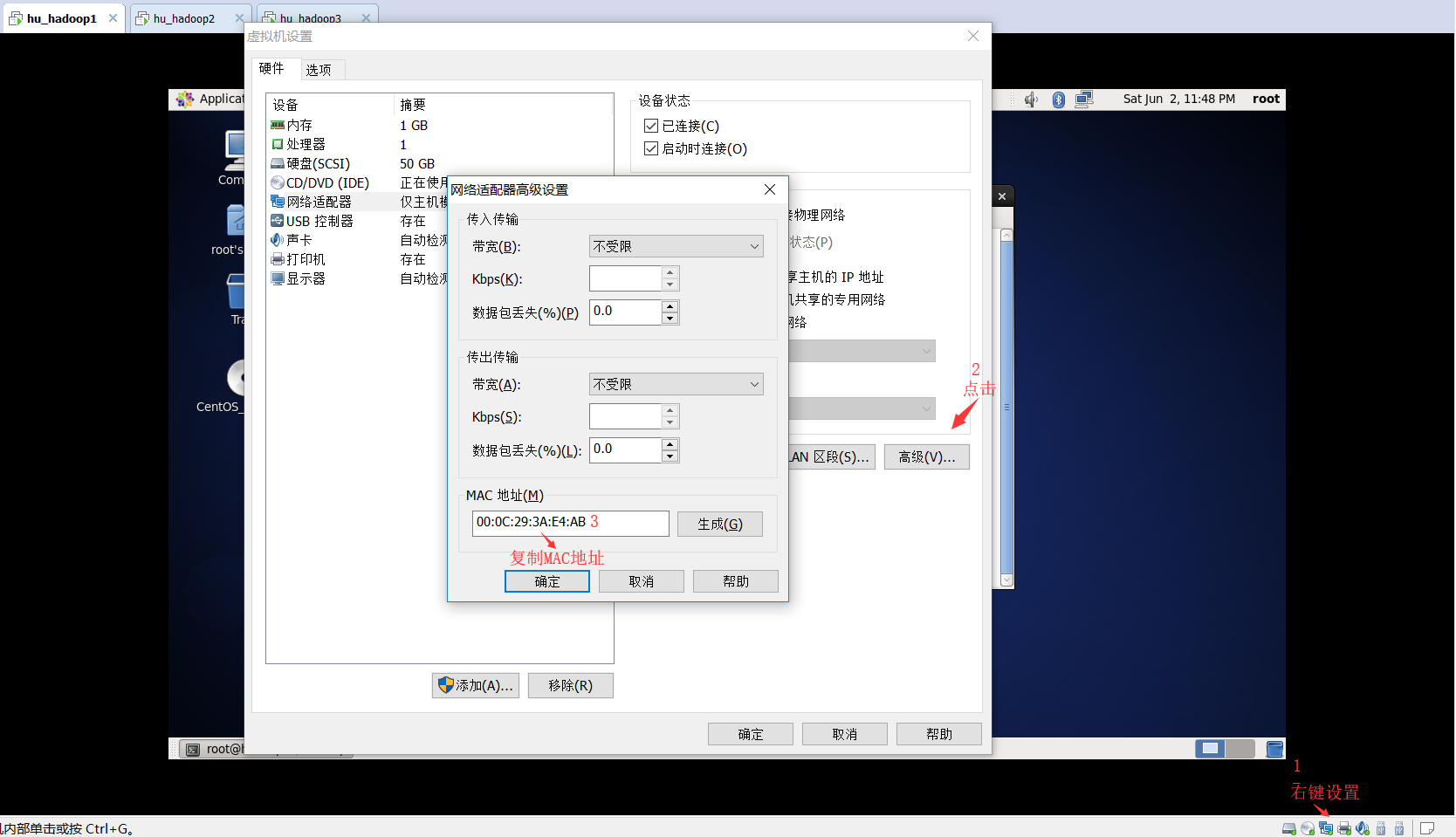
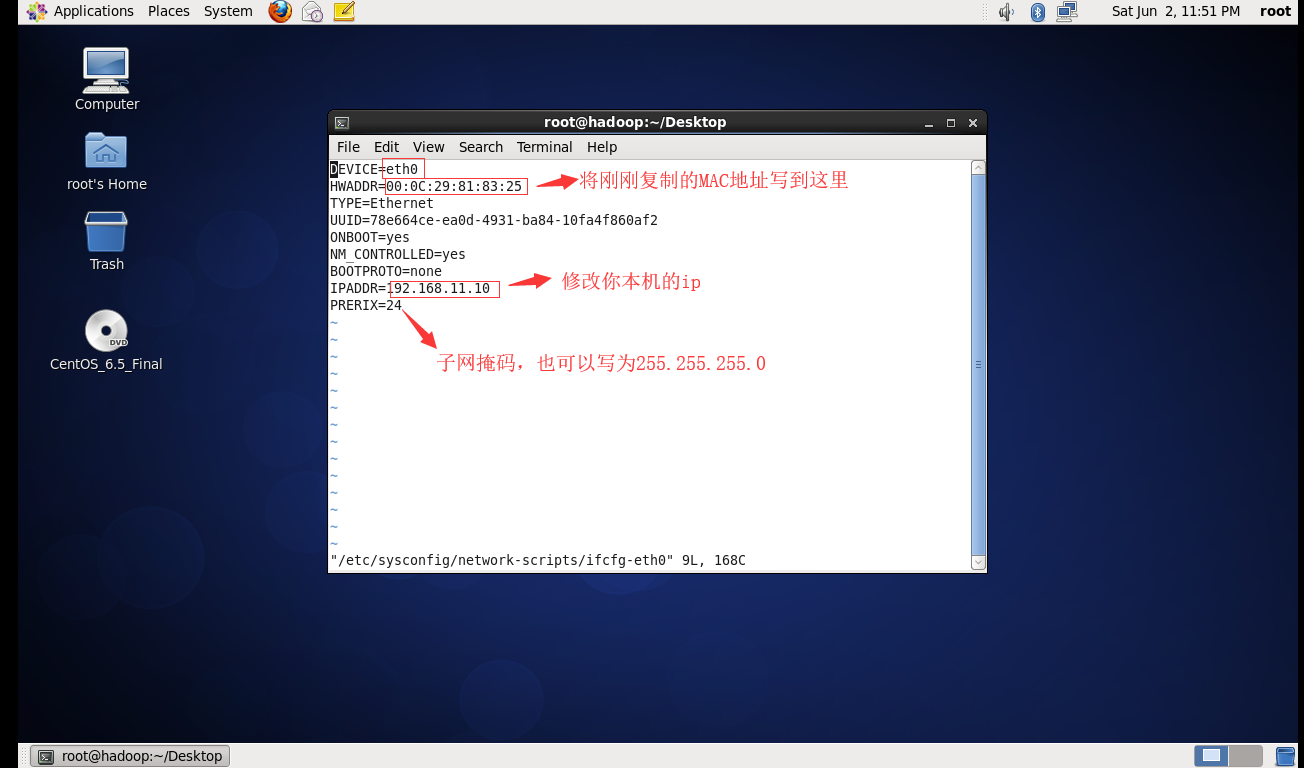
3.使用shell5连接三台机器:
https://www.cnblogs.com/meiLinYa/p/9125745.html(连接过程)
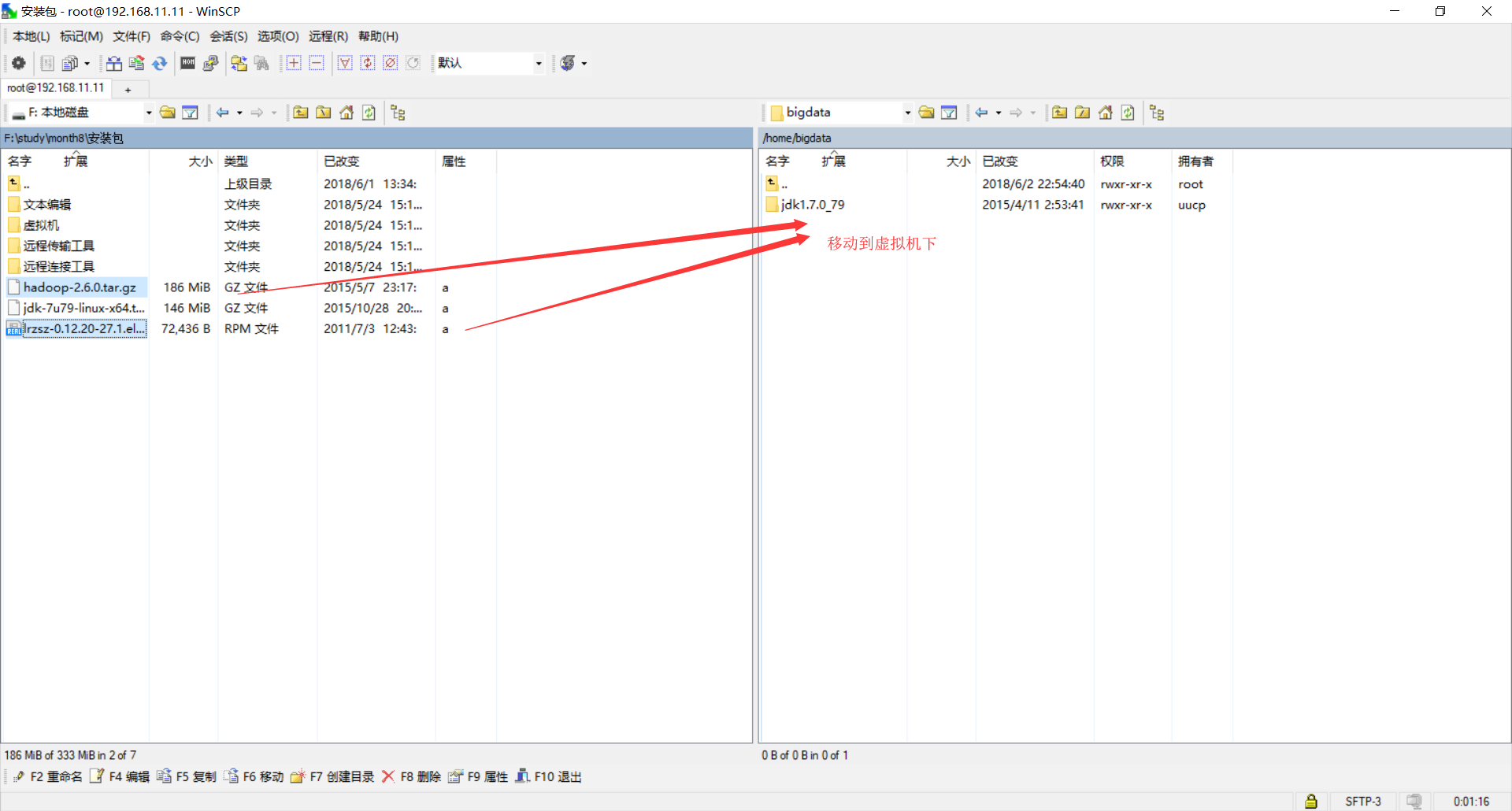
4.将压缩报放到Linux下:
开始配置集群:
hadoop环境的配置:
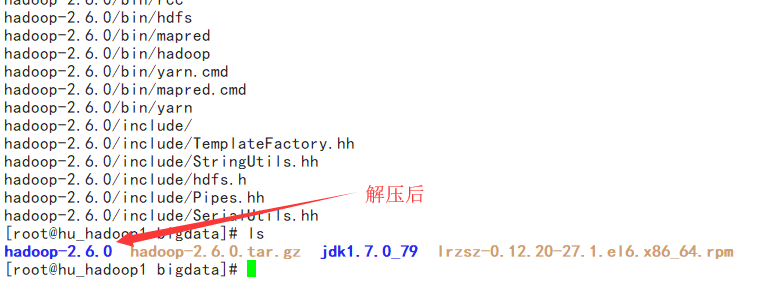
解压tar文件:tar -xzvf hadoop-2.6.0.tar.gz
配置hadoop环境:vi /etc/profile
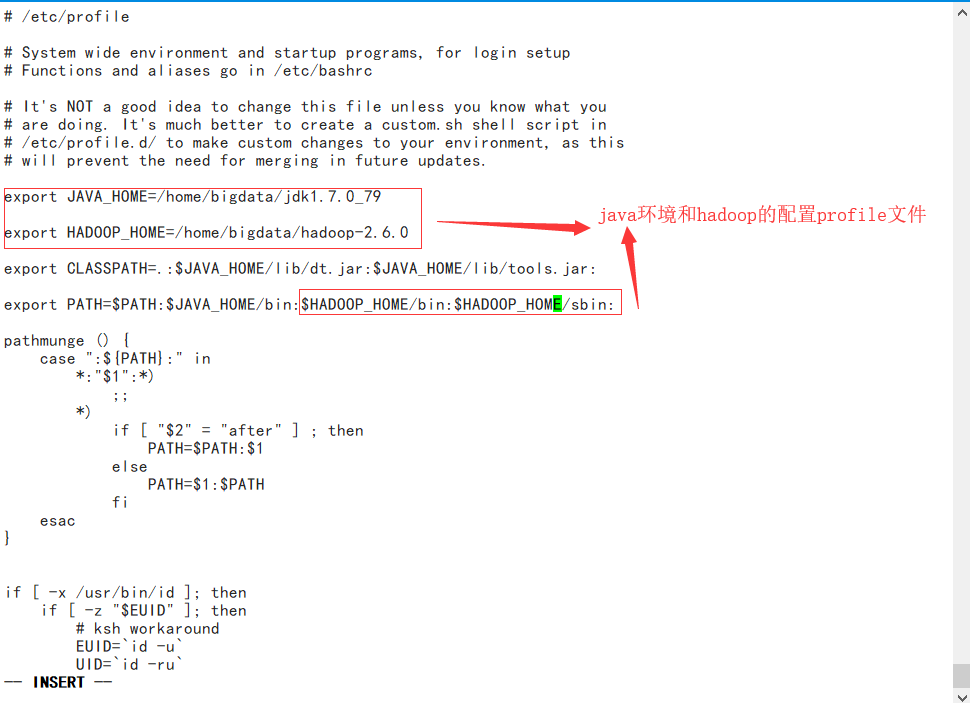
测试:

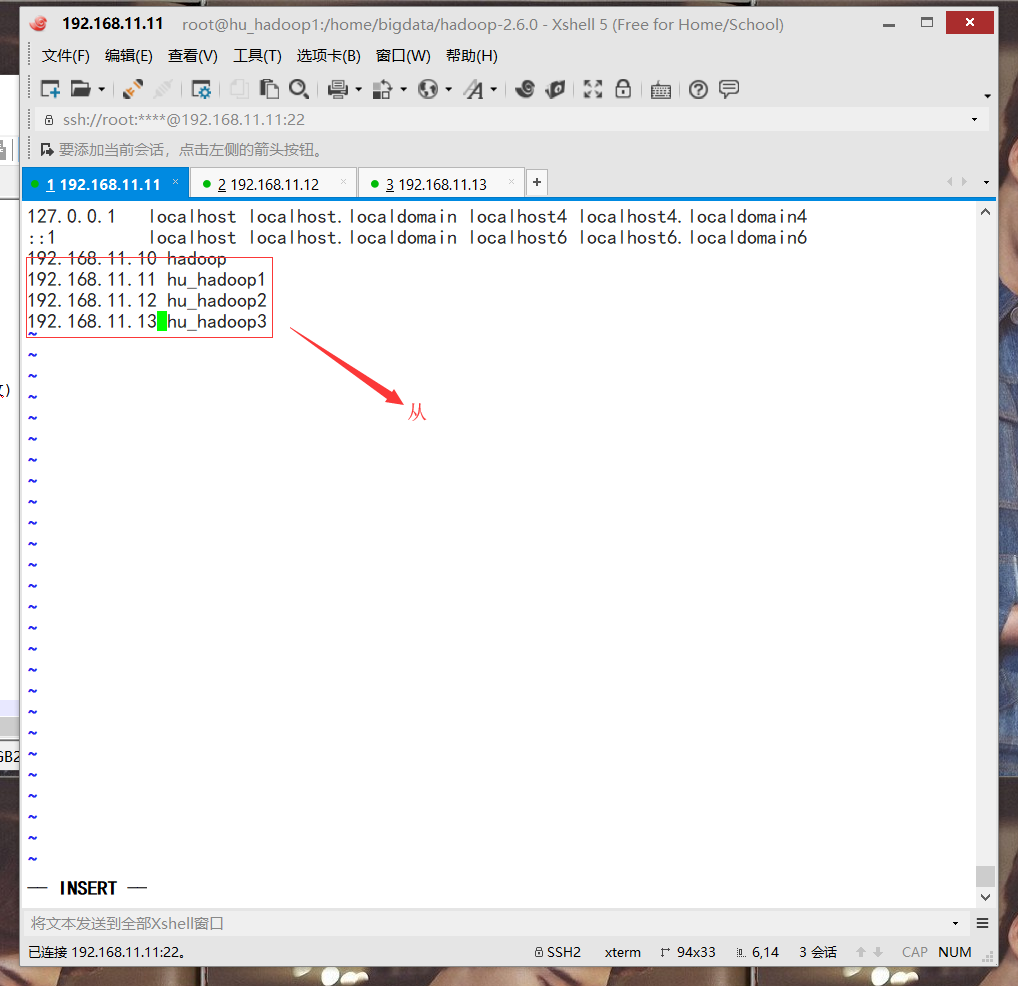
修改hosts文件时主可以认识从机:
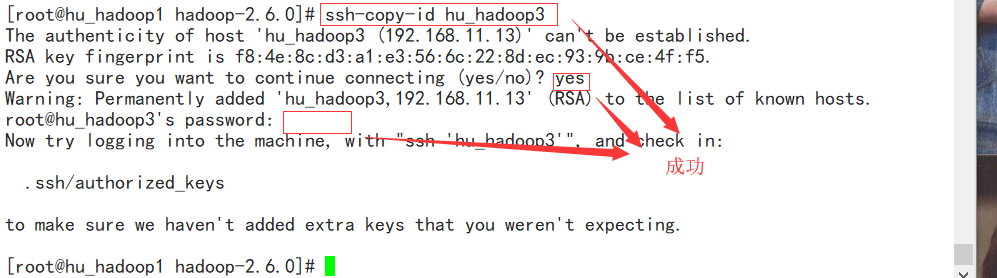
生成密钥使主机无条件不用输入密码访问从:修改hosts文件后 service network restat
ssh-keygen -t rsa 生产密钥
ssh-copy-id 从机名称

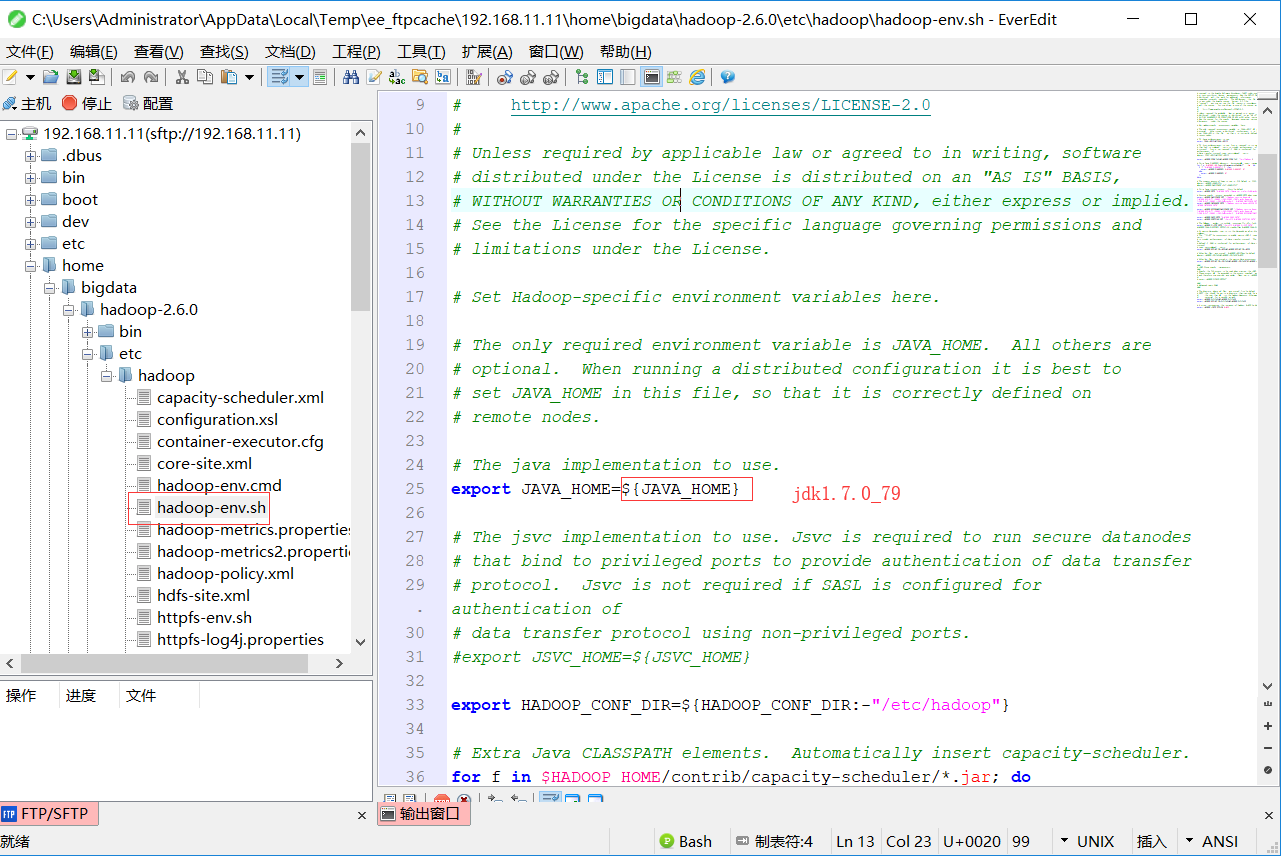
使用编辑器连接后修改Hadoop配置文件(修改6个配置文件):
1.hadoop-env.sh
2.core-site.xml
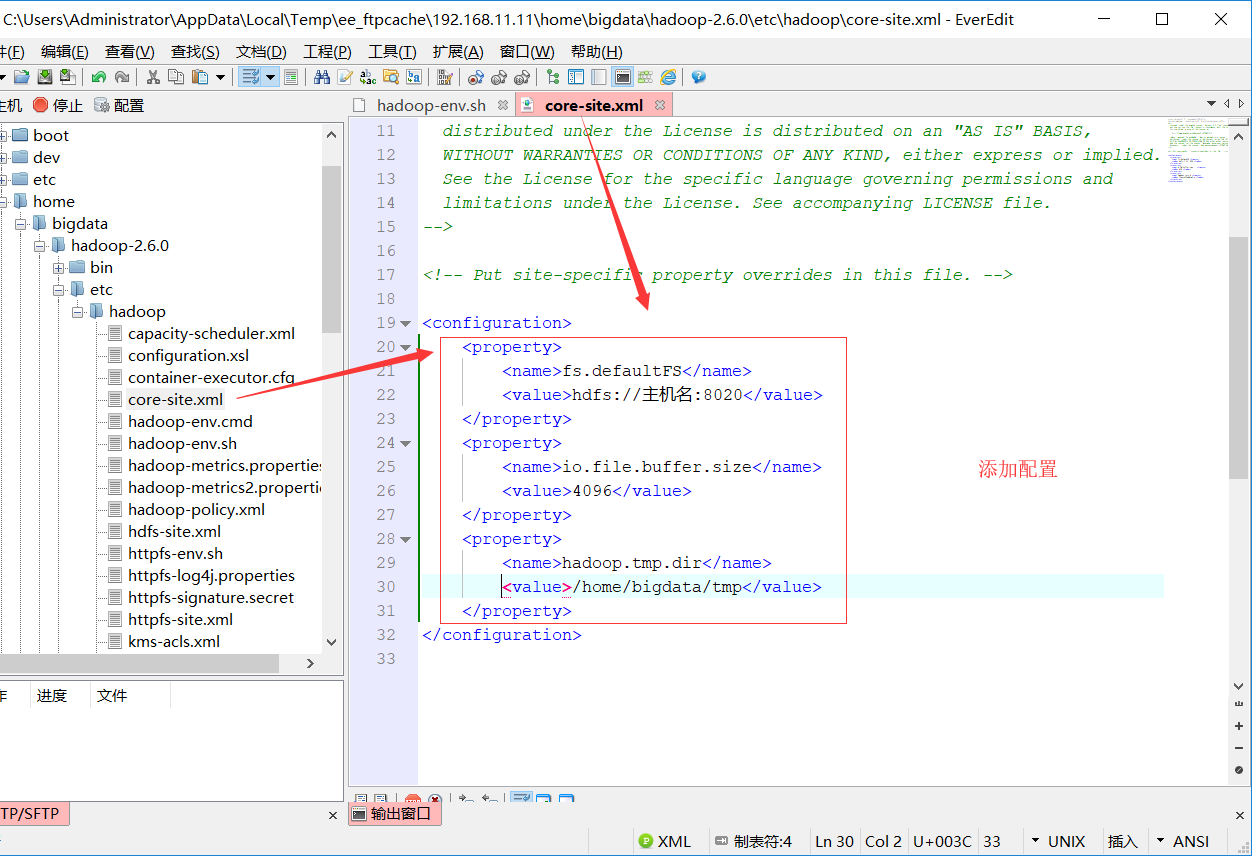
<property>
<name>fs.defaultFS</name>
<value>hdfs://hu-hadoop1:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/bigdata/tmp</value>
</property>
3.hdfs-site.xml
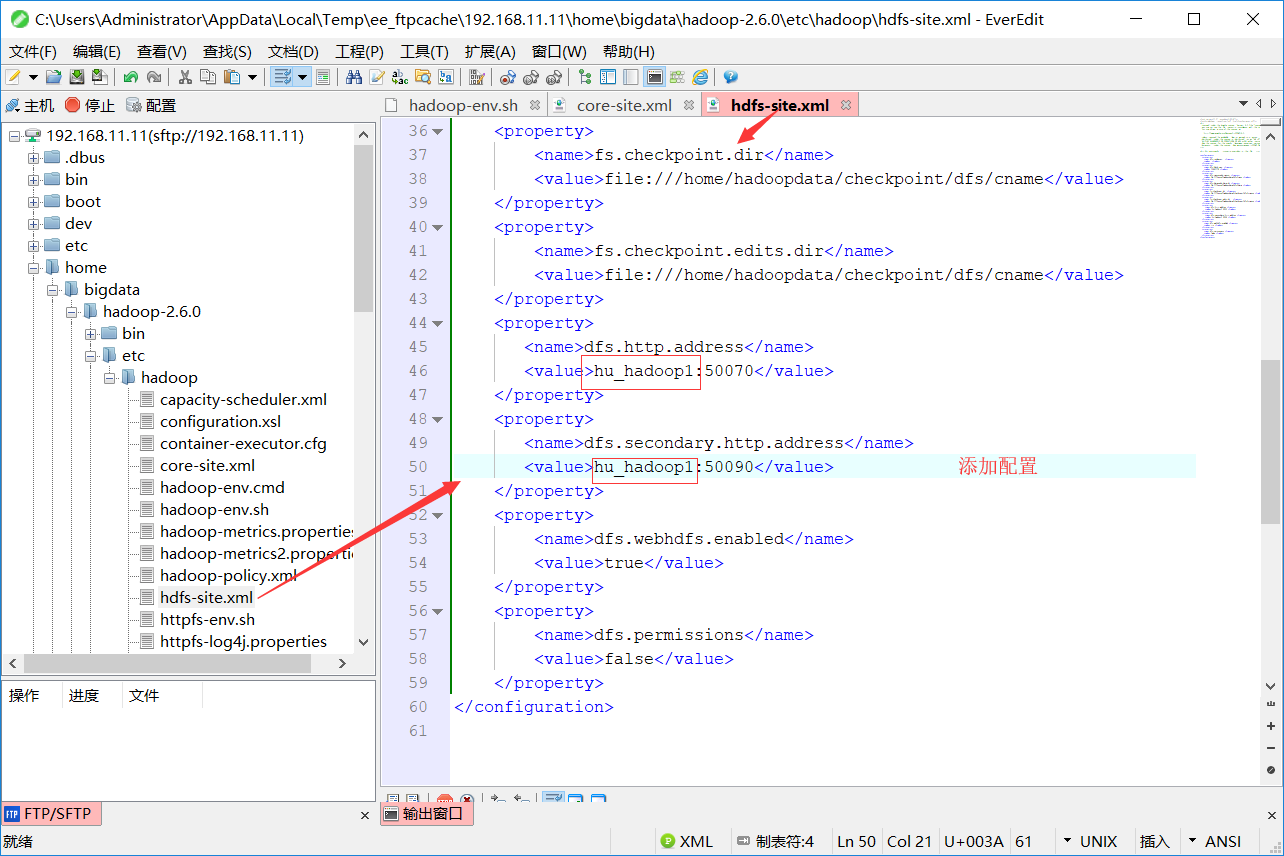
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.block.size</name>
<value></value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/hadoopdata/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/hadoopdata/dfs/data</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>file:///home/hadoopdata/checkpoint/dfs/cname</value>
</property>
<property>
<name>fs.checkpoint.edits.dir</name>
<value>file:///home/hadoopdata/checkpoint/dfs/cname</value>
</property>
<property>
<name>dfs.http.address</name>
<value>hu-hadoop1:</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>hu-hadoop2:</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
4.将 mapred-site.xml.template改为mapred-site.xml
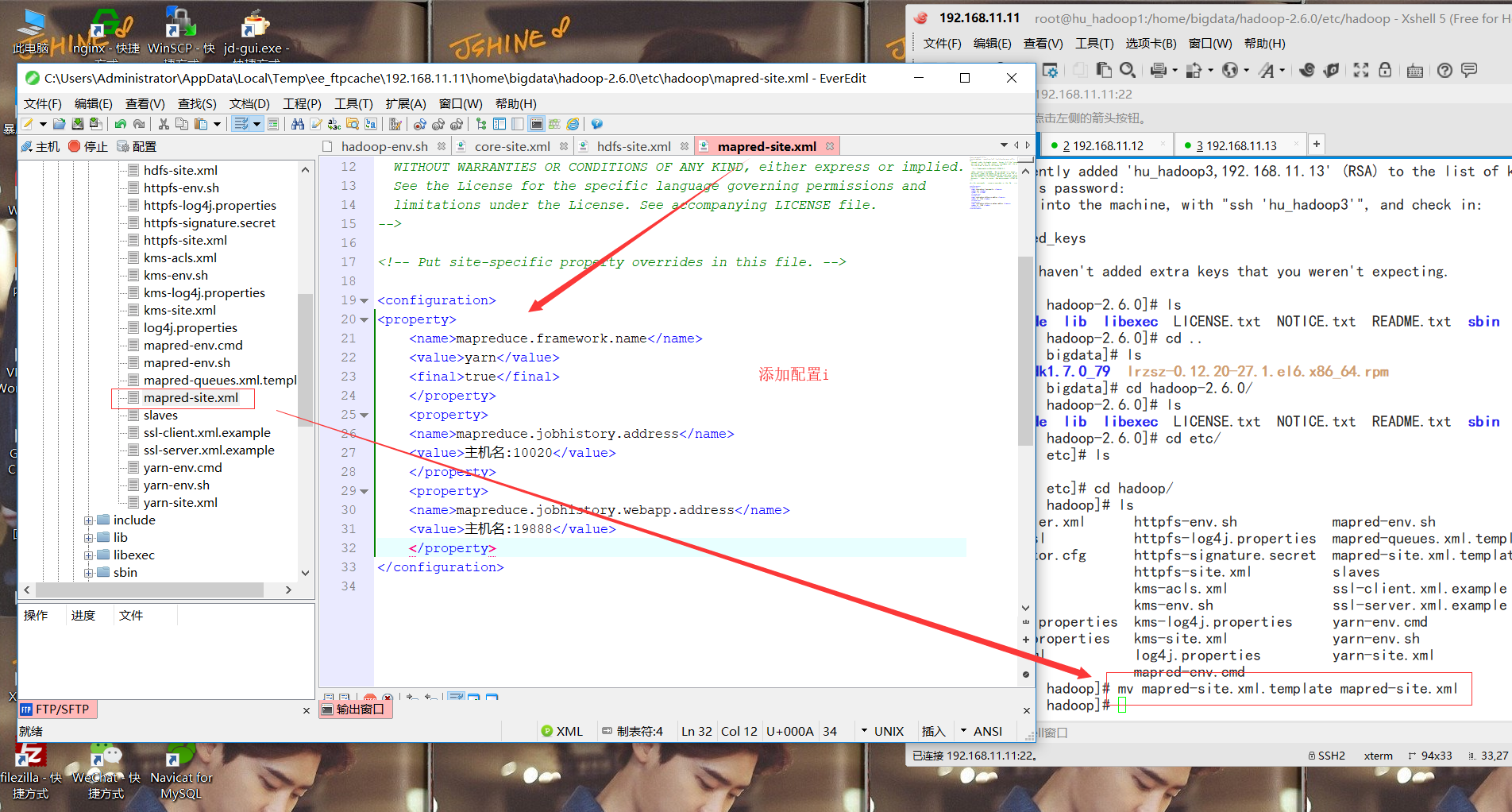
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hu-hadoop1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hu-hadoop1:19888</value>
</property>
5.yarn-site.cml
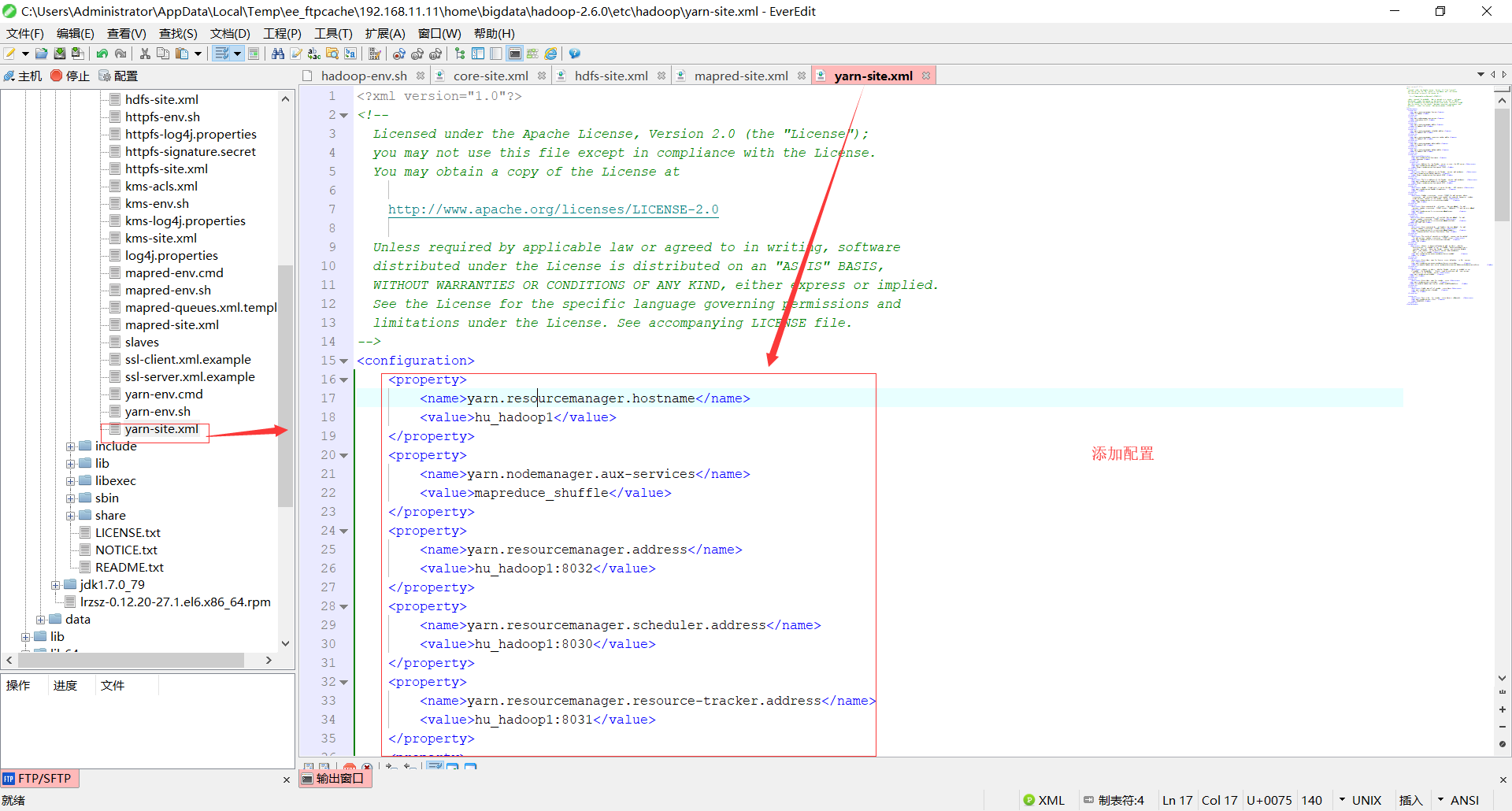
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hu-hadoop1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hu-hadoop1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hu-hadoop1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hu-hadoop1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hu-hadoop1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hu-hadoop1:8088</value>
</property>
<property>
<description></description>
<name>yarn.timeline-service.hostname</name>
<value>hu-hadoop1</value>
</property>
<property>
<description>Address for the Timeline server to start the RPC server.</description>
<name>yarn.timeline-service.address</name>
<value>${yarn.timeline-service.hostname}:10200</value>
</property> <property>
<description>The http address of the Timeline service web application.</description>
<name>yarn.timeline-service.webapp.address</name>
<value>${yarn.timeline-service.hostname}:8188</value>
</property> <property>
<description>The https address of the Timeline service web application.</description>
<name>yarn.timeline-service.webapp.https.address</name>
<value>${yarn.timeline-service.hostname}:8190</value>
</property> <property>
<description>Handler thread count to serve the client RPC requests.</description>
<name>yarn.timeline-service.handler-thread-count</name>
<value>10</value>
</property> <property>
<description>Enables cross-origin support (CORS) for web services where
cross-origin web response headers are needed. For example, javascript making
a web services request to the timeline server.</description>
<name>yarn.timeline-service.http-cross-origin.enabled</name>
<value>false</value>
</property> <property>
<description>Comma separated list of origins that are allowed for web
services needing cross-origin (CORS) support. Wildcards (*) and patterns
allowed</description>
<name>yarn.timeline-service.http-cross-origin.allowed-origins</name>
<value>*</value>
</property> <property>
<description>Comma separated list of methods that are allowed for web
services needing cross-origin (CORS) support.</description>
<name>yarn.timeline-service.http-cross-origin.allowed-methods</name>
<value>GET,POST,HEAD</value>
</property> <property>
<description>Comma separated list of headers that are allowed for web
services needing cross-origin (CORS) support.</description>
<name>yarn.timeline-service.http-cross-origin.allowed-headers</name>
<value>X-Requested-With,Content-Type,Accept,Origin</value>
</property> <property>
<description>The number of seconds a pre-flighted request can be cached
for web services needing cross-origin (CORS) support.</description>
<name>yarn.timeline-service.http-cross-origin.max-age</name>
<value>1800</value>
</property>
<property>
<description>Indicate to ResourceManager as well as clients whether
history-service is enabled or not. If enabled, ResourceManager starts
recording historical data that Timelien service can consume. Similarly,
clients can redirect to the history service when applications
finish if this is enabled.</description>
<name>yarn.timeline-service.generic-application-history.enabled</name>
<value>true</value>
</property> <property>
<description>Store class name for history store, defaulting to file system
store</description>
<name>yarn.timeline-service.generic-application-history.store-class</name>
<value>org.apache.hadoop.yarn.server.applicationhistoryservice.FileSystemApplicationHistoryStore</value>
</property>
<property>
<description>Indicate to clients whether Timeline service is enabled or not.
If enabled, the TimelineClient library used by end-users will post entities
and events to the Timeline server.</description>
<name>yarn.timeline-service.enabled</name>
<value>true</value>
</property> <property>
<description>Store class name for timeline store.</description>
<name>yarn.timeline-service.store-class</name>
<value>org.apache.hadoop.yarn.server.timeline.LeveldbTimelineStore</value>
</property> <property>
<description>Enable age off of timeline store data.</description>
<name>yarn.timeline-service.ttl-enable</name>
<value>true</value>
</property> <property>
<description>Time to live for timeline store data in milliseconds.</description>
<name>yarn.timeline-service.ttl-ms</name>
<value>6048000000</value>
</property>
6.slaves
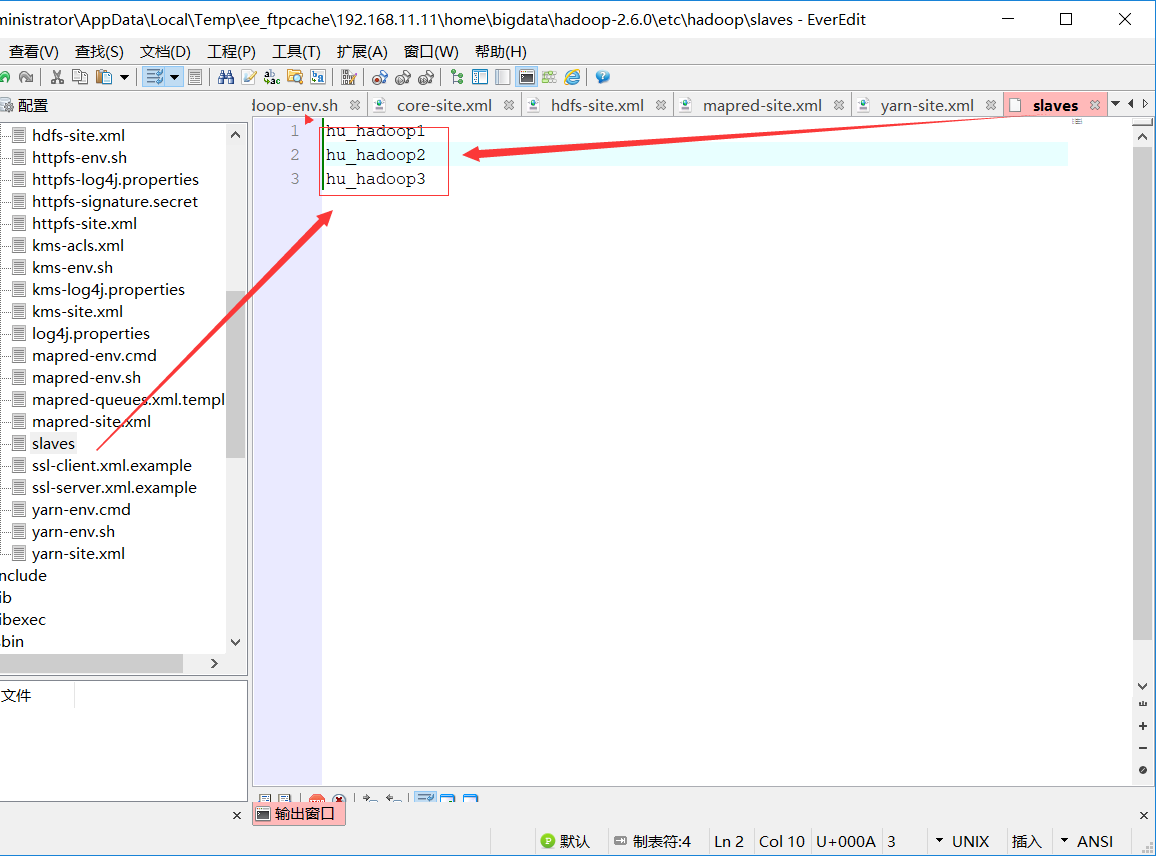
hu-hadoop1
hu-hadoop1
hu-hadoop2
hu-hadoop3
format nameNode:

将profile和hosts和hadoop-2.6.0发送给3个从机 scp hadoop2.6.0 从机名:/`pwd`

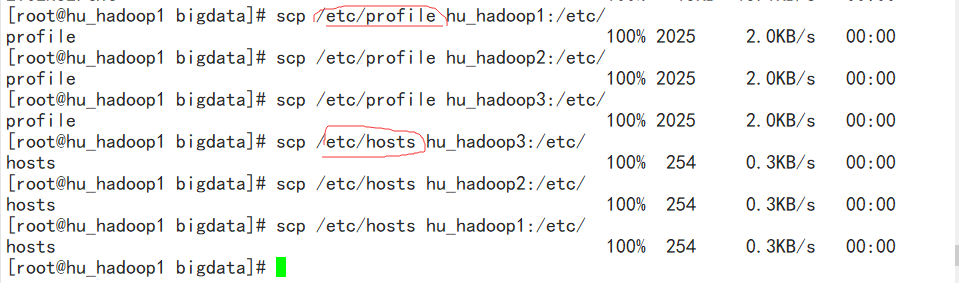
分别在从机上运行:source /etc/profile(刷新配置i文件)service network restart(从启网络服务)
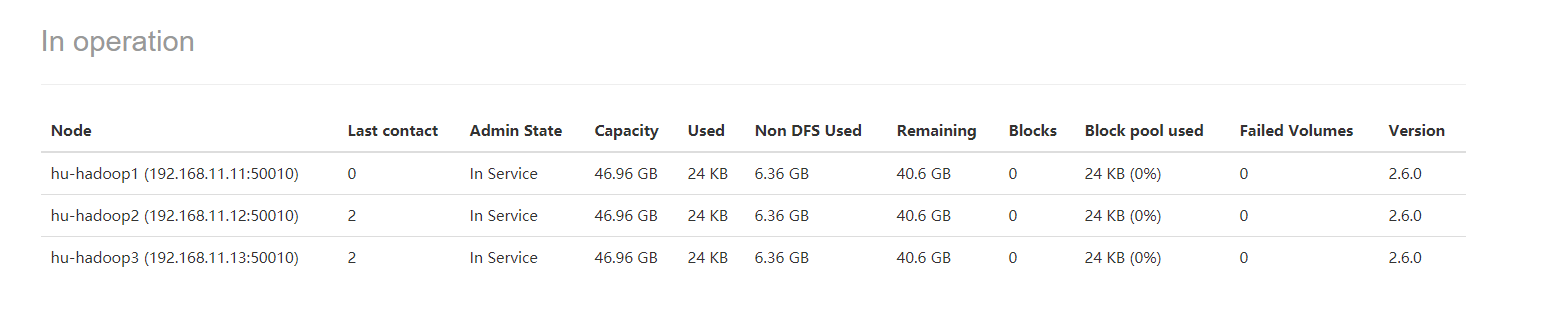
启动服务:start-all.sh 看网页效果(这里我报错了,原因时hostsname不能带有 “_” 所以我改个名字改为了hu-hadoop1)
192.168.11.11:50070
192.168.11.11:8088
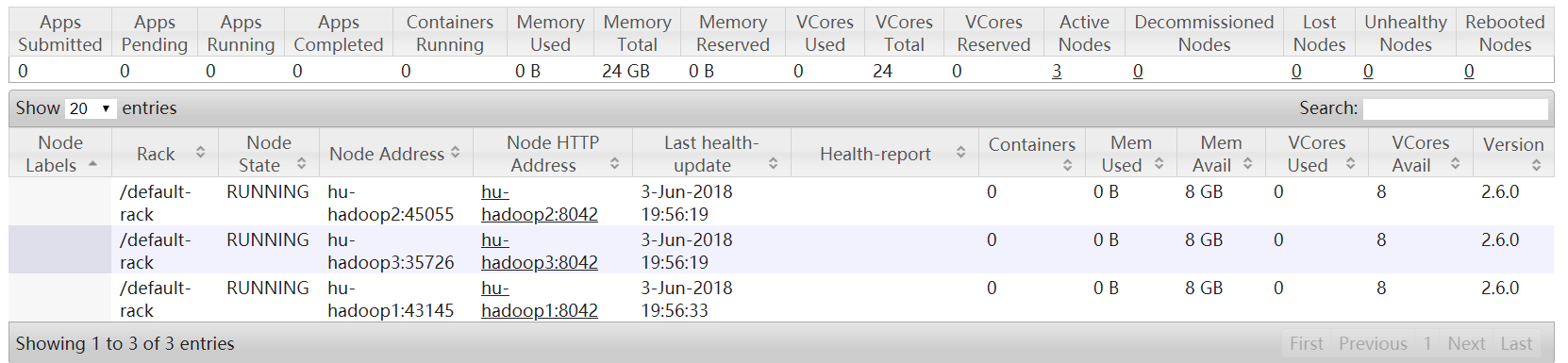
网页也可以展示出来!!就可以了
huhu_k: 越是没有人爱越要爱自己。
Hadoop---集群的搭建(仅主机模式)的更多相关文章
- hadoop集群的搭建
hadoop集群的搭建 1.ubuntu 14.04更换成阿里云源 刚刚开始我选择了nat模式,所有可以连通网络,但是不能ping通,我就是想安装一下mysql,因为安装手动安装mysql太麻烦了,然 ...
- Hadoop集群环境搭建步骤说明
Hadoop集群环境搭建是很多学习hadoop学习者或者是使用者都必然要面对的一个问题,网上关于hadoop集群环境搭建的博文教程也蛮多的.对于玩hadoop的高手来说肯定没有什么问题,甚至可以说事“ ...
- hadoop集群的搭建(分布式安装)
集群 计算机集群是一种计算机系统,他通过一组松散集成的计算机软件和硬件连接起来高度紧密地协同完成计算工作. 集群系统中的单个计算机通常称为节点,通常通过局域网连接. 集群技术的特点: 1.通过多台计算 ...
- hadoop集群环境搭建准备工作
一定要注意hadoop和linux系统的位数一定要相同,就是说如果hadoop是32位的,linux系统也一定要安装32位的. 准备工作: 1 首先在VMware中建立6台虚拟机(配置默认即可).这是 ...
- Hadoop —— 集群环境搭建
一.集群规划 这里搭建一个3节点的Hadoop集群,其中三台主机均部署DataNode和NodeManager服务,但只有hadoop001上部署NameNode和ResourceManager服务. ...
- Hadoop 学习之路(五)—— Hadoop集群环境搭建
一.集群规划 这里搭建一个3节点的Hadoop集群,其中三台主机均部署DataNode和NodeManager服务,但只有hadoop001上部署NameNode和ResourceManager服务. ...
- Hadoop 系列(五)—— Hadoop 集群环境搭建
一.集群规划 这里搭建一个 3 节点的 Hadoop 集群,其中三台主机均部署 DataNode 和 NodeManager 服务,但只有 hadoop001 上部署 NameNode 和 Resou ...
- Hadoop集群初步搭建:
自己整理了一下Hadoop集群简易搭建的过程,感谢尚观科技贾老师的授课和指导! 基本环境要求:能联网电脑一台:装有Centos系统的VMware虚拟机:Xmanager Enterprise 5软件. ...
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
随机推荐
- 用命令bat打开某个文件或文件夹
打开文件或文件夹可以用start命令,start命令会根据文件关联的程序自动调用关联的程序打开文件和文件夹. 可以用记事本写如下命令,之后改扩展名为.bat即可 打开文件夹 start "& ...
- 【BZOJ】3209: 花神的数论题
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id=3209 显然是按照二进制位进行DP. 考虑预处理$F[i][j]$表示到了二进制的第$i$位 ...
- 【BZOJ】2734: [HNOI2012]集合选数
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id=2734 考虑$N=4$的情况: \begin{bmatrix} 1&3 &X ...
- C++图形开发相关
1. WxWidgets 2. GTK+ 3. U++ Framework 4. QT
- MD5加密与Hash加密
一.Md5加密 MD5算法具有以下特点: 1.压缩性:任意长度的数据,算出的MD5值长度都是固定的. 2.容易计算:从原数据计算出MD5值很容易. 3.抗修改性:对原数据进行任何改动,哪怕只修改1个字 ...
- python类与类的关系
类与类之间的关系(依赖关系,大象与冰箱是依赖关系) class DaXiang: def open(self, bx): # 这里是依赖关系. 想执行这个动作. 必须传递一个bx print(&quo ...
- vuex中的辅助函数 mapState,mapGetters, mapActions, mapMutations
1.导入辅助函数 导入mapState可以调用vuex中state的数据 导入mapMutations可以调用vuex中mutations的方法 四个辅助函数 各自对应自己在vuex上的自己 2.ma ...
- Wiener’s attack python
题目如下: 在不分解n的前提下,求d. 给定: e = 140586954170153340715880103465867497905399132874997078029388987191993846 ...
- 修改Anaconda中的Jupyter Notebook默认工作路径
这二天,安装了anaconda想更改jupyter的工作路径,在网上找了一下 方式1. 打开Windows的cmd,在cmd中输入jupyter notebook --generate-config如 ...
- Python Selenium 文件下载
Python Selenium 进UI自动化测试时都会遇到文件上传和下载的操作,下面介绍一下文件下载的操作 这里介绍使用FireFox浏览器进行文件下载的操作. 1.设置文件默认下载地址 如下图,fi ...