关于在使用sparksql写程序是报错以及解决方案:org.apache.spark.sql.AnalysisException: Duplicate column(s): "name" found, cannot save to file.
说明:
spark --version : 2.2.0
我有两个json文件,分别是emp和dept:
emp内容如下:
{"name": "zhangsan", "age": 26, "depId": 1, "gender": "male", "salary": 20000}
{"name": "lisi", "age": 36, "depId": 2, "gender": "female", "salary": 8500}
{"name": "wangwu", "age": 23, "depId": 1, "gender": "male", "salary": 5000}
{"name": "zhaoliu", "age": 25, "depId": 3, "gender": "male", "salary": 7000}
{"name": "marry", "age": 19, "depId": 2, "gender": "female", "salary": 6600}
{"name": "Tom", "age": 36, "depId": 1, "gender": "female", "salary": 5000}
{"name": "kitty", "age": 43, "depId": 2, "gender": "female", "salary": 6000}
{"name": "Tony","age": 36,"depId": 4,"gender":"female","salary": 4030}
dept内容如下:
{"id": 1, "name": "Tech Department"}
{"id": 2, "name": "Fina Department"}
{"id": 3, "name": "HR Department"}
现在我需要通过sparksql将两个文件加载进来并做join,最后将结果保存到本地
下面是操作步骤:
1、初始化配置
val conf = new SparkConf().setMaster("local[2]").setAppName("Load_Data")
val sc = new SparkContext(conf)
val ssc = new sql.SparkSession.Builder()
.appName("Load_Data_01")
.master("local[2]")
.getOrCreate()
sc.setLogLevel("error") //测试环境为了少打印点日志,我将日志级别设置为error
2、将两个json文件加载进来
val df_emp = ssc.read.json("file:///E:\\javaBD\\BD\\json_file\\employee.json")
val df_dept = ssc.read.format("json").load("file:///E:\\javaBD\\BD\\json_file\\department.json")
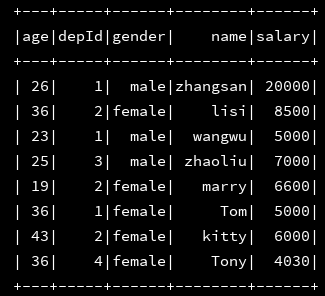
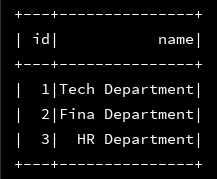
3、分别将加载进来的两个json文件打印出来,看看是否成功载入
df_emp.show()
df_dept.show()
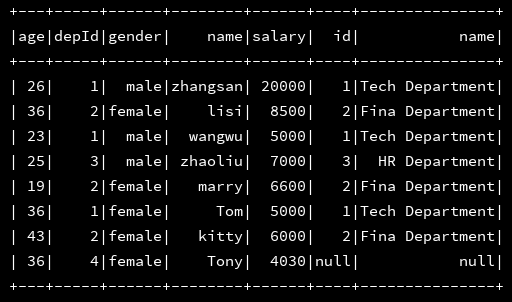
4、数据加载都没有问题,接下来二者进行join操作:
df_emp.join(df_dept,df_emp("depId") === df_dept("id"),"left").show()
5、这样结果也可以正常打印出来了,貌似是没有什么问题了,接下来直接就save就可以了呗,但是进行save的时候就报错了:
df_emp.join(df_dept,df_emp("depId") === df_dept("id"),"left").write.mode(SaveMode.Append).csv("file:///E:\\javaBD\\BD\\json_file\\rs")
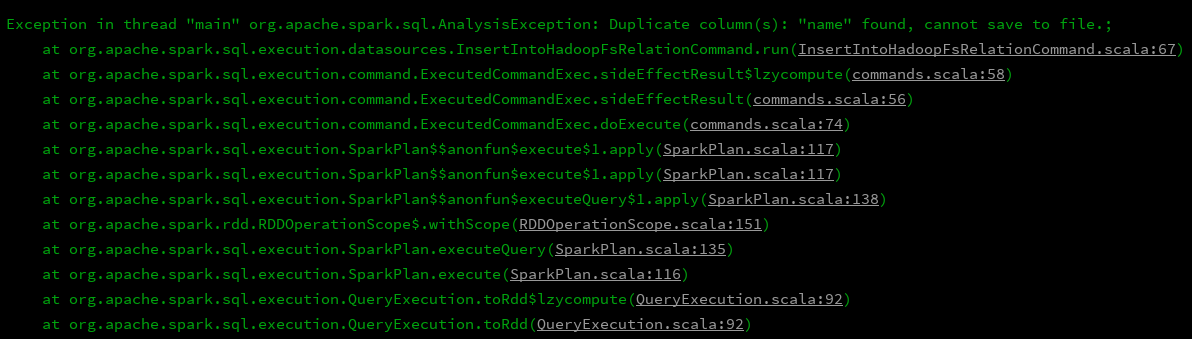
于是开始百度,找到了原因,论坛链接,大致的意思就是说,要保存的表中有相同的name字段,这样是不行的,那么解决方案就很明显了,让两个那么字段名称不相同么,那就分别给他们其别名呗,接下来开始修改代码:
1、初始化配置不变
2、读文件不变
3、跟别获取到两个DF(json文件加载加载进来之后就是两个DF)的列明,并进行分别设置别名
//分别拿出两张表的列名
val c_emp = df_emp.columns
val c_dept = df_dept.columns
//分别对两张表的别名进行设置
val emp = df_emp.select(c_emp.map(n => df_emp(n).as("emp_" + n)): _*)
val dept = df_dept.select(c_dept.map(n => df_dept(n).as("dept_" + n)): _*)
4、接着在进行保存,程序报错消失:
emp.join(dept,emp("emp_depId") === dept("dept_id"),"left").write.mode(SaveMode.Append).csv("file:///E:\\javaBD\\BD\\json_file\\rs")
这里的这个保存的路径说名一下:我是保存在windows本地,因为我配置了hadoop的环境变量,所以如果写本地需要这样写,如果去掉"file:///"的话,idea会认为是hdfs的路径,所有会报错路径找不到错误,如果要写入到hdfs的话,最好将地址写全:hdfs://namenode_ip:9000/file
程序没有报错,然后到指定目录下查看,文件是否写入:
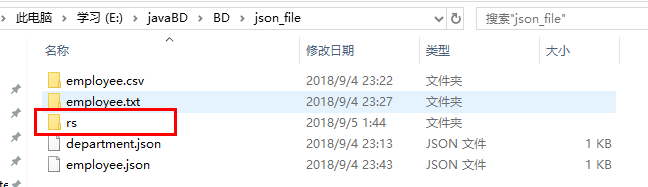
文件已经成功写入,over
关于在使用sparksql写程序是报错以及解决方案:org.apache.spark.sql.AnalysisException: Duplicate column(s): "name" found, cannot save to file.的更多相关文章
- Django(21)migrate报错的解决方案
前言 在讲解如何解决migrate报错原因前,我们先要了解migrate做了什么事情,migrate:将新生成的迁移脚本.映射到数据库中.创建新的表或者修改表的结构. 问题1:migrate怎么判断哪 ...
- vue-cesium中经纬度写反了,报错
vue-cesium中经纬度写反了,报错 [Vue warn]: Invalid prop: custom validator check failed for prop "position ...
- Spark程序编译报错error: object apache is not a member of package org
Spark程序编译报错: [INFO] Compiling 2 source files to E:\Develop\IDEAWorkspace\spark\target\classes at 156 ...
- 运行netcore2.2程序是报错
运行netcore2.2程序是报错 C:\myself\WuZhui\WuZhui\bin\Release\netcoreapp2.2>dotnet WuZhui.DLLError: An as ...
- 新手常见的python报错及解决方案
此篇文章整理新手编写代码常见的一些错误,有些错误是粗心的错误,但对于新手而已,会折腾很长时间才搞定,所以在此总结下我遇到的一些问题.希望帮助到刚入门的朋友们.后续会不断补充. 目录 1.NameErr ...
- 关于mybatis的xml文件中使用 >= 或者 <= 号报错的解决方案
当我们需要通过xml格式处理sql语句时,经常会用到< ,<=,>,>=等符号,但是很容易引起xml格式的错误,这样会导致后台将xml字符串转换为xml文档时报错,从而导致程序 ...
- 报错:SQLSTATE[23000]: Integrity constraint violation: 1062 Duplicate entry 'admin' for key 'username'
在提交注册信息的时候报错:SQLSTATE[23000]: Integrity constraint violation: 1062 Duplicate entry 'admin' for key ' ...
- 关于Entity Framework中的Attached报错相关解决方案的总结
关于Entity Framework中的Attached报错的问题,我这里分为以下几种类型,每种类型我都给出相应的解决方案,希望能给大家带来一些的帮助,当然作为读者的您如果觉得有不同的意见或更好的方法 ...
- Mysql only_full_group_by以及其他关于sql_mode原因报错详细解决方案
Mysql only_full_group_by以及其他关于sql_mode原因报错详细解决方案 网上太多相关资料,但是抄袭严重,有的讲的也是之言片语的,根本不连贯(可能知道的人确实不想多说) 我总共 ...
随机推荐
- 【Python55--爬虫:代理】
一.反爬虫之隐藏 1.网站检查访问的是正常用户还是程序,关键在于User-Agent 1).第一种方法:采用header --修改header(两种方法): --> 在Request之前通过h ...
- topcoder srm 470 div1
problem1 link 首先预处理在已选字母的状态为$state$时是否可达. 然后就是按照题目进行dp.设$f[i]$表示已选字母集合为$i$时的结果. 每次可以根据$i$中含有的字母是奇数还是 ...
- FireMonkey 源码学习(2)
三.TControl FireMonkey重写了TControl的代码,实现了众多接口,如下图: 基类上实现了众多功能,这里不详细描述. 四.TEdit 编辑框是从TControl—TStyledCo ...
- P2596 [ZJOI2006]书架
思路 一开始写fhq-treap 感觉越写越感觉splay好些,就去splay 然后维护序列 注意前驱后继的不存在的情况 但不用插入虚拟节点(那插入岂不太麻烦) 跑的真慢的一批,splay太多了 错误 ...
- (转)Shiro学习
(二期)13.权限框架shiro讲解 [课程13]自定义Realm.xmind36.8KB [课程13]用户授权流程.xmind0.2MB [课程13]shiro简介.xmind0.3MB [课程13 ...
- c# 之系统环境安装
在重装系统后,对一些原有软件进行了卸载,不知道是什么原因总是提示vs2015 需安装IE10,但是又碰到ie10的一些插件不适合此系统.网上介绍的vs修复没有任何作用 最后找到方法是:重装系统,然后不 ...
- iframe初始化属性
<iframe id="user" src="xxx.html" frameborder="0" width="" ...
- Unity3D学习笔记(三十五):Shader着色器(2)- 顶点片元着色器
Alpha测试 AlphaTest Great:大于 AlphaTest Less:小于 AlphaTest Equal:等于 AlphaTest GEqual:大于等于 AlphaTest LEqu ...
- 2-4、nginx特性及基础概念-nginx web服务配置详解
Nginx Nginx:engine X 调用了libevent:高性能的网络库 epoll():基于事件驱动event的网络库文件 Nginx的特性: 模块化设计.较好扩展性(不支持模块动态装卸载, ...
- iPhone 尺寸 iPhonex
http://tool.lanrentuku.com/guifan/ui.html 这是本人复制的链接,,如有不适用,,请;联系本人删除链接,,谢谢. iPhone x尺寸 1125x2436@3x ...