Weka中数据挖掘与机器学习系列之Weka简介(二)
不多说,直接上干货!
Weka简介
Weka是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis)的英文字首缩写,官方网址为:http://www.cs.waikato.ac.nz/ml/weka,在该网站可以免费下载可运行软件和源代码,还可以获得说明文档、常见问题解答、数据集和其他文献等资源。Weka的发音类似新西兰本土一种不会飞的鸟,如下图所示,因此Weka系统使用该鸟作为其徽标。
Weka是新西兰怀卡托大学用Java开发的数据挖掘著名开源软件,该系统自1993年开始由新西兰政府资助,至今已经历了20年的发展,其功能已经十分强大和成熟。Weka集合了大量的机器学习和相关技术,受领域发展和用户需求所推动,代表了当今数据挖掘和机器学习领域的最高水平。
Weka是一种使用Java语言编写的数据挖掘机器学习软件,是GNU协议下分发的开源软件。Weka主要用于科研、教育和应用领域。
国内外很多著名大学都采用Weka作为数据挖掘和机器学习课程的实践工具。Weka还有另外一个名字叫作Pentaho Data Mining Community Edition(Pentaho数据挖掘社区版),此外,Pentaho的网站(http://weka.pentaho.com/)还维护一个称为Pentaho Data Mining Enterprise Edition(Pentaho数据挖掘企业版)的版本,它主要提供技术支持和管理升级。另一个用Java编写的著名数据挖掘工具RapidMiner通过Weka Extension(Weka扩展)支持Weka,以充分利用Weka的“约100个额外的建模方案,其中包括额外的决策树、规则学习器和回归估计器”,参见网址http://rapid-i.com/content/view/202/206/。
Weka历史
1992年末,新西兰怀卡托大学计算机科学系Ian Witten博士申请基金,1993年获新西兰政府资助,并于同年开发出接口和基础架构。次年发布了第一个Weka的内部版本,两年后,在1996年10月,第一个公开版本(Weka 2.1)发布。Weka早期版本主要采用C语言编写,1997年初,团队决定使用Java重新改写,并在1999年中期发布纯Java的Weka 3版本。选定Java来实现Ian Witten著作《Data Mining》的配套机器学习技术是有充分理由的,作为一个著名的面向对象的编程语言,Java允许用一个统一的接口来进行学习方案和方法的预处理和后处理。决定使用Java来替代C++或其他面向对象的语言,是因为Java编写的程序可以运行在绝大部分计算机上,而无须重新编译,更不需要修改源代码。已经测试过的平台包括Linux、Windows和Macintosh操作系统,甚至包括PDA。最后的可执行程序复制过来即可运行,完全绿色,不要求复杂安装。当然,Java也有其缺点,最大的问题是它在速度上有缺陷,执行一个Java程序比对应的C语言程序要慢上好几倍。综合来看,对于Weka来说,Java“一次编译,到处运行”的吸引力远远超出对性能的渴望。
截止到2013年2月,Weka最新的版本是3.7.8。博主本人,我采用的是weka-3-6-6jre-x64.exe。
Weka功能简介
Weka系统汇集了最前沿的机器学习算法和数据预处理工具,以便用户能够快速灵活地将已有的处理方法应用于新的数据集。它为数据挖掘的整个过程提供全面的支持,包括准备输入数据、统计评估学习方案、输入数据和学习效果的可视化。Weka除了提供大量学习算法之外,还提供了适应范围很广的预处理工具,用户通过一个统一界面操作各种组件,比较不同的学习算法,找出能够解决问题的最有效的方法。
Weka系统包括处理标准数据挖掘问题的所有方法:回归、分类、聚类、关联规则以及属性选择。分析要进行处理的数据是重要的一个环节,Weka提供了很多用于数据可视化和预处理的工具。输入数据可以有两种形式,第一种是以ARFF格式为代表的文件;另一种是直接读取数据库表。
使用Weka的方式主要有三种:第一种是将学习方案应用于某个数据集,然后分析其输出,从而更多地了解这些数据;第二种是使用已经学习到的模型对新实例进行预测;第三种是使用多种学习器,然后根据其性能表现选择其中的一种来进行预测。用户使用交互式界面菜单中选择一种学习方法,大部分学习方案都带有可调节的参数,用户可通过属性列表或对象编辑器修改参数,然后通过同一个评估模块对学习方案的性能进行评估。
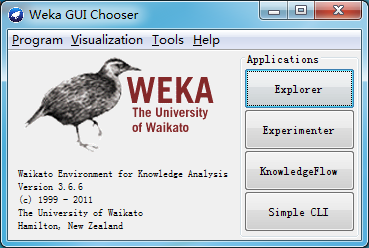
Weka主界面称为Weka GUI选择器,它通过右边的四个按钮提供四种主要的应用程序供用户选择,如下图所示,用鼠标单击按钮进入到相应的图形用户界面。

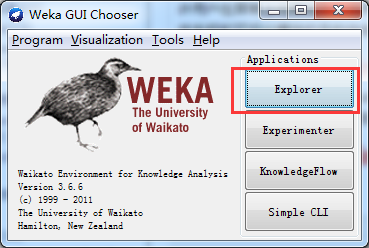
其中,Weka系统提供的最容易使用的图形用户接口称为探索者(Explorer)。通过选择菜单和填写表单,可以调用Weka的所有功能。例如,用户用鼠标仅仅单击几个按钮,就可以完成从ARFF文件中读取数据集,然后建立决策树的工作。
Weka界面十分友好,能适时地将不宜用的功能选项设置为不可选;将用户选项设计为表格方式以方便填写;当鼠标移动到界面工具上短暂停留时,会给出用法提示;对算法都给出较为合理的默认值,这样,帮助用户尽量少花精力进行配置就可取得较好的效果等。
分别瑞如下:
虽然探索者(Explorer)界面使用很方便,但它也存在一个缺陷,要求它将所需数据全部一次读进内存,一旦用户打开某个数据集,就会读取全部数据。因此,这种批量方式仅适合处理中小规模的问题。知识流刚好能够弥补这一缺陷。
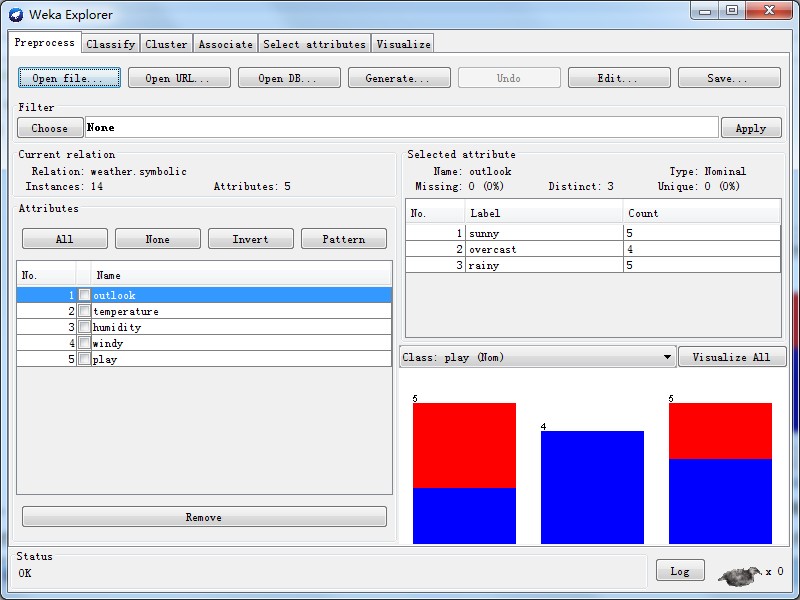
1)Explorer(探索者),系统提供的最容易使用的图像用户接口。通过选择菜单和填写表单,可以调用weka的所有功能。
虽然探索者界面使用很方便,但它也存在一个缺陷,要求它将所需数据全部一次读进内存,一旦用户打开某个数据集,就会读取全部数据。因此,这种批量方式仅适合处理中小规模的问题。而知识流刚好能够弥补这一缺陷。
实验者(Experimenter)界面用于帮助用户解答实际应用分类和回归技术中遇到的一个基本问题——对于一个已知问题,哪种方法及参数值能够取得最佳效果?通过Weka提供的实验者工作环境,用户可以比较不同的学习方案。尽管探索者界面也能通过交互完成这样的功能,但通过实验者界面,用户可以让处理过程实现自动化。实验者界面更加容易使用不同参数去设置分类器和过滤器,使之运行在一组数据集中,收集性能统计数据,实现重要的测试实验。
2)Experimenter(实验者),用于帮助用户解答实际应用分类和回归技术中遇到的一个基本问题-----对于一个已知问题,哪种方法及参数值能够取得最佳效果?尽管探索者界面也能通过交互完成这样的功能,但通过实验者界面,用户可以让处理过程实现自动化。实验者界面更加容易使用不同参数去设置分类器和过滤器,使之运行在一组数据集中,收集性能统计数据,实现重要的测试实验。
知识流(KnowledgeFlow)界面可以使用增量方式的算法来处理大型数据集,用户可以定制处理数据流的方式和顺序。知识流界面允许用户在屏幕上任意拖曳代表学习算法和数据源的图形构件,并以一定的方式和顺序组合在一起。也就是,按照一定顺序将代表数据源、预处理工具、学习算法、评估手段和可视化模块的各构件组合在一起,形成数据流。如果用户选取的过滤器和学习算法具有增量学习功能,那就可以实现大型数据集的增量分批读取和处理。
3)KnowledgeFlow(知识流),使用增量方式的算法来处理大型数据集,用户可以定制处理数据流的方式和顺序。按照一定顺序将代表数据源、预处理工具、学习算法、评估手段和可视化模块的各构件组合在一起,形成数据流。
简单命令行(Simple CLI)界面是为不提供自己的命令行界面的操作系统提供的,该简单命令行界面用于和用户进行交互,可以直接执行Weka命令。
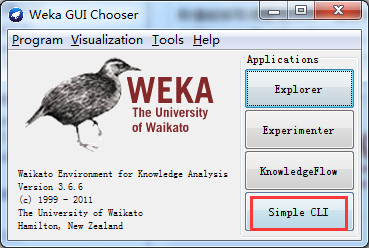
4)Simple CLI(简单命令行),这个界面是为不提供自己的命令行界面的操作系统提供的,该简单命令行界面用户和用户进行交互,可以直接执行weka命令。
Weka中数据挖掘与机器学习系列之Weka简介(二)的更多相关文章
- Weka中数据挖掘与机器学习系列之Weka Package Manager安装所需WEKA的附加算法包出错问题解决方案总结(八)
不多说,直接上干货! Weka中数据挖掘与机器学习系列之Weka系统安装(四) Weka中数据挖掘与机器学习系列之Weka3.7和3.9不同版本共存(七) 情况1 对于在Weka里,通过Weka P ...
- Weka中数据挖掘与机器学习系列之Weka系统安装(四)
能来看我这篇博客的朋友,想必大家都知道,Weka采用Java编写的,因此,具有Java“一次编译,到处运行”的特性.支持的操作系统有Windows x86.Windows x64.Mac OS X.L ...
- Weka中数据挖掘与机器学习系列之Weka3.7和3.9不同版本共存(七)
不多说,直接上干货! 为什么,我要写此博客,原因是(以下,我是weka3.7.8) 以下是,weka3.7.8的安装版本. Weka中数据挖掘与机器学习系列之Weka系统安装(四) 基于此,我安装最新 ...
- Weka中数据挖掘与机器学习系列之Exploer界面(七)
不多说,直接上干货! Weka的Explorer(探索者)界面,是Weka的主要图形化用户界面,其全部功能都可通过菜单选择或表单填写进行访问.本博客将详细介绍Weka探索者界面的图形化用户界面.预处理 ...
- Weka中数据挖掘与机器学习系列之基本概念(三)
数据挖掘和机器学习 数据挖掘和机器学习这两项技术的关系非常密切.机器学习方法构成数据挖掘的核心,绝大多数数据挖掘技术都来自机器学习领域,数据挖掘又向机器学习提出新的要求和任务. 数据挖掘就是在数据中寻 ...
- Weka中数据挖掘与机器学习系列之为什么要写Weka这一系列学习笔记?(一)
本人正值科研之年,同时也在使用Weka来做相关数据挖掘和机器学习的论文工作. 为了记录自己的学习历程,也便于分享和带领入门的你们.废话不多说,直接上干货!
- Weka中数据挖掘与机器学习系列之数据格式ARFF和CSV文件格式之间的转换(五)
不多说,直接上干货! Weka介绍: Weka是一个用Java编写的数据挖掘工具,能够运行在各种平台上.它不仅提供了可以直接用于数据挖掘的软件,还提供了src代码,使用者可以修改源代码,进行二次开发. ...
- 机器学习 数据挖掘 推荐系统机器学习-Random Forest算法简介
Random Forest是加州大学伯克利分校的Breiman Leo和Adele Cutler于2001年发表的论文中提到的新的机器学习算法,可以用来做分类,聚类,回归,和生存分析,这里只简单介绍该 ...
- 用WEKA进行数据挖掘
学习于IBM教学文档 数据挖掘学习与weka使用 第二部 分分类和集群 分类 vs. 群集 vs. 最近邻 在我深入探讨每种方法的细节并通过 WEKA 使用它们之前,我想我们应该先理解每个模型 - 每 ...
随机推荐
- 微信小程序 上传图的功能
首先选择图片,然后循环,再就是在点击发布的时候循环图片地址赋值,包括删除命令 js代码: //选择图片 uploadImgAdd: function(e) { var imgs = this.data ...
- thinkphp5 编辑时 唯一验证 解决办法
若定义了相关的验证规则,如: namespace app\seller\validate; use think\Validate; class Goodsmtag extends Validate { ...
- javascript取前n天的日期两种方法
方法一: var d = new Date(); d = new Date(d.getFullYear(),d.getMonth(),d.getDate()-n); 方法二: var now = ne ...
- HDU——T 1507 Uncle Tom's Inherited Land*
http://acm.hdu.edu.cn/showproblem.php?pid=1507 Time Limit: 2000/1000 MS (Java/Others) Memory Limi ...
- Qt之QTemporaryFile
简述 QTemporaryFile类是操作临时文件的I/O设备. QTemporaryFile用于安全地创建一个独一无二的临时文件.临时文件通过调用open()来创建,并且名称是唯一的(即:保证不覆盖 ...
- hadoop-01-ssh无密登录配置
1,分配master机器2台,slave机器5台: 2,在全部机器上面配置/etc/hosts设置 3,全部机器上面进行ntp设置:TODO 4,在master机器上面: 不要用root登录 1) s ...
- js 动画1
div速度 运动: 代码例如以下: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" " ...
- [Transducer] Lazyness in Transduer
Transducers remove the requirement of being lazy to optimize for things like take(10). However, it c ...
- MongoDB查询、索引和聚合
初始化mongodb数据库 > use deng switched to db deng > db.createCollection("jingdong") #无參数 ...
- POJ 2570 Fiber Network(最短路 二进制处理)
题目翻译 一些公司决定搭建一个更快的网络.称为"光纤网". 他们已经在全世界建立了很多网站.这 些网站的作用类似于路由器.不幸的是,这些公司在关于网站之间的接线问题上存在争论,这样 ...