Node.js爬虫-爬取慕课网课程信息
第一次学习Node.js爬虫,所以这时一个简单的爬虫,Node.js的好处就是可以并发的执行
这个爬虫主要就是获取慕课网的课程信息,并把获得的信息存储到一个文件中,其中要用到cheerio库,它可以让我们方便的操作HTML,就像是用jQ一样
开始前,记得
npm install cheerio
为了能够并发的进行爬取,用到了Promise对象
//接受一个url爬取整个网页,返回一个Promise对象
function getPageAsync(url){
return new Promise((resolve,reject)=>{
console.log(`正在爬取${url}的内容`);
http.get(url,function(res){
let html = ''; res.on('data',function(data){
html += data;
}); res.on('end',function(){
resolve(html);
}); res.on('error',function(err){
reject(err);
console.log('错误信息:' + err);
})
});
})
}
在慕课网中,每个课程都有一个ID,我们事先要把想要获取课程的ID写到一个数组中,而且每个课程的地址都是一个相同的地址加上ID,所以我们只要把地址和ID拼接起来就是课程的地址
const baseUrl = 'http://www.imooc.com/learn/';
const baseNuUrl = 'http://www.imooc.com/course/AjaxCourseMembers?ids=';
//获取课程的ID
const videosId = [773,371];
为了使获取每个课程内容时并发执行,要使用Promise中的all方法
Promise
//当所有网页的内容爬取完毕
.all(courseArray)
.then((pages)=>{
//所有页面需要的内容
let courseData = []; //遍历每个网页提取出所需要的内容
pages.forEach((html)=>{
let courses = filterChapter(html);
courseData.push(courses);
}); //给每个courseMenners.number赋值
for(let i=0;i<videosId.length;i++){
for(let j=0;j<videosId.length;j++){
if(courseMembers[i].id +'' == videosId[j]){
courseData[j].number = courseMembers[i].numbers;
}
}
} //对所需要的内容进行排序
courseData.sort((a,b)=>{
return a.number > b.number;
}); //在重新将爬取内容写入文件中前,清空文件
fs.writeFileSync(outputFile,'###爬取慕课网课程信息###',(err)=>{
if(err){
console.log(err)
}
});
printfData(courseData);
});
在then方法中,pages是每个课程的HTML页面,我们还得从中提取出我们需要的信息,需要使用下面的函数
//接受一个爬取下来的网页内容,查找网页中需要的信息
function filterChapter(html){
const $ = cheerio.load(html); //所有章
const chapters = $('.chapter'); //课程的标题和学习人数
let title = $('.hd>h2').text();
let number = 0; //最后返回的数据
//每个网页需要的内容的结构
let courseData = {
'title':title,
'number':number,
'videos':[]
}; chapters.each(function(item){
let chapter = $(this);
//文章标题
let chapterTitle = Trim(chapter.find('strong').text(),'g'); //每个章节的结构
let chapterdata = {
'chapterTitle':chapterTitle,
'video':[]
}; //一个网页中的所有视频
let videos = chapter.find('.video').children('li');
videos.each(function(item){
//视频标题
let videoTitle = Trim($(this).find('a.J-media-item').text(),'g');
//视频ID
let id = $(this).find('a').attr('href').split('video/')[1];
chapterdata.video.push({
'title':videoTitle,
'id':id
})
}); courseData.videos.push(chapterdata); }); return courseData;
}
注意:在上面中将课程的学习人数设置为了0是因为学习课程人数是用Ajax动态获取,所以我在后面写了方法专门获取学习课程人数,其中用到的Trim()方法是去除文本中的空格
获取学习课程的人数:
//获取上课人数
function getNumber(url){ let datas = ''; http.get(url,(res)=>{
res.on('data',(chunk)=>{
datas += chunk;
}); res.on('end',()=>{
datas = JSON.parse(datas);
courseMembers.push({'id':datas.data[0].id,'numbers':parseInt(datas.data[0].numbers,10)});
});
});
}
这样就将想获取课程的学习人数都添加到了courseMembers数组中,在最后将学习课程的人数在赋值给相对应的课程
//给每个courseMenners.number赋值
for(let i=0;i<videosId.length;i++){
for(let j=0;j<videosId.length;j++){
if(courseMembers[i].id +'' == videosId[j]){
courseData[j].number = courseMembers[i].numbers;
}
}
}
我们获取到了数据,就要把它按照一定的格式存到一个文件中
//写入文件
function writeFile(file,string) {
fs.appendFileSync(file,string,(err)=>{
if(err){
console.log(err);
}
})
} //打印信息
function printfData(coursesData){ coursesData.forEach((courseData)=>{
// console.log(`${courseData.number}人学习过${courseData.title}\n`);
writeFile(outputFile,`\n\n${courseData.number}人学习过${courseData.title}\n\n`); courseData.videos.forEach(function(item){
let chapterTitle = item.chapterTitle;
// console.log(chapterTitle + '\n');
writeFile(outputFile,`\n ${chapterTitle}\n`); item.video.forEach(function(item){
// console.log(' 【' + item.id + '】' + item.title + '\n');
writeFile(outputFile,` 【${item.id}】 ${item.title}\n`);
})
}); }); }
最后获取到的数据:
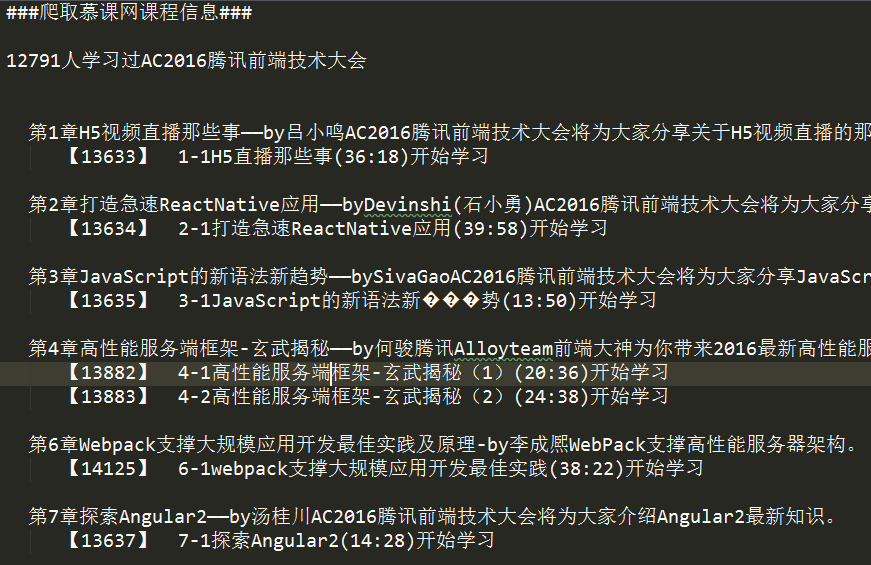
源码:
/**
* Created by hp-pc on 2017/6/7 0007.
*/
const http = require('http');
const fs = require('fs');
const cheerio = require('cheerio');
const baseUrl = 'http://www.imooc.com/learn/';
const baseNuUrl = 'http://www.imooc.com/course/AjaxCourseMembers?ids=';
//获取课程的ID
const videosId = [773,371];
//输出的文件
const outputFile = 'test.txt';
//记录学习课程的人数
let courseMembers = []; //去除字符串中的空格
function Trim(str,is_global)
{
let result;
result = str.replace(/(^\s+)|(\s+$)/g,"");
if(is_global.toLowerCase()=="g")
{
result = result.replace(/\s/g,"");
}
return result;
} //接受一个url爬取整个网页,返回一个Promise对象
function getPageAsync(url){
return new Promise((resolve,reject)=>{
console.log(`正在爬取${url}的内容`);
http.get(url,function(res){
let html = ''; res.on('data',function(data){
html += data;
}); res.on('end',function(){
resolve(html);
}); res.on('error',function(err){
reject(err);
console.log('错误信息:' + err);
})
});
})
} //接受一个爬取下来的网页内容,查找网页中需要的信息
function filterChapter(html){
const $ = cheerio.load(html); //所有章
const chapters = $('.chapter'); //课程的标题和学习人数
let title = $('.hd>h2').text();
let number = 0; //最后返回的数据
//每个网页需要的内容的结构
let courseData = {
'title':title,
'number':number,
'videos':[]
}; chapters.each(function(item){
let chapter = $(this);
//文章标题
let chapterTitle = Trim(chapter.find('strong').text(),'g'); //每个章节的结构
let chapterdata = {
'chapterTitle':chapterTitle,
'video':[]
}; //一个网页中的所有视频
let videos = chapter.find('.video').children('li');
videos.each(function(item){
//视频标题
let videoTitle = Trim($(this).find('a.J-media-item').text(),'g');
//视频ID
let id = $(this).find('a').attr('href').split('video/')[1];
chapterdata.video.push({
'title':videoTitle,
'id':id
})
}); courseData.videos.push(chapterdata); }); return courseData;
} //获取上课人数
function getNumber(url){ let datas = ''; http.get(url,(res)=>{
res.on('data',(chunk)=>{
datas += chunk;
}); res.on('end',()=>{
datas = JSON.parse(datas);
courseMembers.push({'id':datas.data[0].id,'numbers':parseInt(datas.data[0].numbers,10)});
});
});
} //写入文件
function writeFile(file,string) {
fs.appendFileSync(file,string,(err)=>{
if(err){
console.log(err);
}
})
} //打印信息
function printfData(coursesData){ coursesData.forEach((courseData)=>{
// console.log(`${courseData.number}人学习过${courseData.title}\n`);
writeFile(outputFile,`\n\n${courseData.number}人学习过${courseData.title}\n\n`); courseData.videos.forEach(function(item){
let chapterTitle = item.chapterTitle;
// console.log(chapterTitle + '\n');
writeFile(outputFile,`\n ${chapterTitle}\n`); item.video.forEach(function(item){
// console.log(' 【' + item.id + '】' + item.title + '\n');
writeFile(outputFile,` 【${item.id}】 ${item.title}\n`);
})
}); }); } //所有页面爬取完后返回的Promise数组
let courseArray = []; //循环所有的videosId,和baseUrl进行字符串拼接,爬取网页内容
videosId.forEach((id)=>{
//将爬取网页完毕后返回的Promise对象加入数组
courseArray.push(getPageAsync(baseUrl + id));
//获取学习的人数
getNumber(baseNuUrl + id);
}); Promise
//当所有网页的内容爬取完毕
.all(courseArray)
.then((pages)=>{
//所有页面需要的内容
let courseData = []; //遍历每个网页提取出所需要的内容
pages.forEach((html)=>{
let courses = filterChapter(html);
courseData.push(courses);
}); //给每个courseMenners.number赋值
for(let i=0;i<videosId.length;i++){
for(let j=0;j<videosId.length;j++){
if(courseMembers[i].id +'' == videosId[j]){
courseData[j].number = courseMembers[i].numbers;
}
}
} //对所需要的内容进行排序
courseData.sort((a,b)=>{
return a.number > b.number;
}); //在重新将爬取内容写入文件中前,清空文件
fs.writeFileSync(outputFile,'###爬取慕课网课程信息###',(err)=>{
if(err){
console.log(err)
}
});
printfData(courseData);
});
Node.js爬虫-爬取慕课网课程信息的更多相关文章
- 养只爬虫当宠物(Node.js爬虫爬取58同城租房信息)
先上一个源代码吧. https://github.com/answershuto/Rental 欢迎指导交流. 效果图 搭建Node.js环境及启动服务 安装node以及npm,用express模块启 ...
- Node.js 爬虫爬取电影信息
Node.js 爬虫爬取电影信息 我的CSDN地址:https://blog.csdn.net/weixin_45580251/article/details/107669713 爬取的是1905电影 ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- python爬虫:爬取慕课网视频
前段时间安装了一个慕课网app,发现不用注册就可以在线看其中的视频,就有了想爬取其中的视频,用来在电脑上学习.决定花两天时间用学了一段时间的python做一做.(我的新书<Python爬虫开发与 ...
- 手把手教你用Node.js爬虫爬取网站数据
个人网站 https://iiter.cn 程序员导航站 开业啦,欢迎各位观众姥爷赏脸参观,如有意见或建议希望能够不吝赐教! 开始之前请先确保自己安装了Node.js环境,还没有安装的的童鞋请自行百度 ...
- node.js爬虫爬取拉勾网职位信息
简介 用node.js写了一个简单的小爬虫,用来爬取拉勾网上的招聘信息,共爬取了北京.上海.广州.深圳.杭州.西安.成都7个城市的数据,分别以前端.PHP.java.c++.python.Androi ...
- node js 爬虫爬取静态页面,
先打一个简单的通用框子 //根据爬取网页的协议 引入对应的协议, http||https var http = require('https'); //引入cheerio 简单点讲就是node中的jq ...
- node:爬虫爬取网页图片
代码地址如下:http://www.demodashi.com/demo/13845.html 前言 周末自己在家闲着没事,刷着微信,玩着手机,发现自己的微信头像该换了,就去网上找了一下头像,看着图片 ...
- Python爬虫项目--爬取自如网房源信息
本次爬取自如网房源信息所用到的知识点: 1. requests get请求 2. lxml解析html 3. Xpath 4. MongoDB存储 正文 1.分析目标站点 1. url: http:/ ...
随机推荐
- 读书笔记 effctive c++ Item 52 如果你实现了placement new,你也要实现placement delete
1. 调用普通版本的operator new抛出异常会发生什么? Placement new和placement delete不是C++动物园中最常遇到的猛兽,所以你不用担心你对它们不熟悉.当你像下面 ...
- Android性能优化——之防止内存泄露
又是好久没有写博客了,一直都比较忙,最近终于有时间沉淀和整理一下最近学到和解决的一些问题. 最近进行技术支持的时候,遇到了几个崩溃的问题,都是OOM异常,一般OOM异常给人的感觉应该是加载大图片造成的 ...
- C++ STL学习之容器set和multiset (补充材料)
一.set和multiset基础 set和multiset会根据特定的排序准则,自动将元素进行排序.不同的是后者允许元素重复而前者不允许. 需要包含头文件: #include <set> ...
- C#代码将html样式文件转为Word文档
首先有个这样的需求,将以下网页内容下载为Word文件. html代码: <div class="modal-body"> <div style=" ...
- My SQL数据库的安装与配置
MySQL是一个关系型数据库管理系统.MySQL所使用的 SQL 语言是用于访问数据库的最常用标准化语言 MySQL 软件采用了双授权政策,分为社区版和商业版,由于其体积小.速度快.总体拥有成本低,尤 ...
- 高性能日志类KLog(已开源代码)
项目开源地址:https://github.com/ihambert/KLog 上回介绍了超简易日志类,但他有诸多的局限性,注定了不能作为一个网站的日志类. 那什么样的日志类才能用于网站呢.首先来假 ...
- #include<> 和#include“”的区别
1.< >引用的是编译器的类库路径里面的头文件2." "引用的是程序目录的相对路径中的头文件,在程序目录的相对路径中找不到该头文件时会继续在类库路径里搜寻该头文件 ...
- javascript的null 和undifined
null表示一个对象,或者变量的值为空,undifined 表示声明了一个对象(变量),没有给他初始化或者压根儿就没有声明这个对象(变量). 1.null 是JavaScript关键字 undifin ...
- 关于获取URL中传值的解决方法
在我们页面的URL中包含着很多信息,包括域名,协议等等这里就不一一介绍了),对于我们开发者而言,使用比较多的就是页面之间的传值.为什么要页面传值呢?很简单,当你在浏览一个商品页面的时候你要看到一个商品 ...
- java线程(二)
线程范围变量 我们知道线程在cpu上的使用权并不是长时间的,因为计算机的cpu只有一个,而在计算上运行的进程有很多,线程就更不用说了,所以cpu只能通过调度来上多个线程轮流占用cpu资源运行,且为了保 ...