hadoop-2.6.0源码编译
运行hadoop环境时,常常会出现这种提示
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
意思是无法加载本地native库。
这里就需要我们自己本地进行编译hadoop源码,用生成的文件来替换原有的native库。
下面就是我整理的hadoop编译流程
首先介绍一下我的环境
centos6.5
jdk-7u79-linux-x64.tar.gz
apache-maven-3.3.9-bin.tar.gz
protobuf-2.5.0.tar.gz
hadoop-2.6.0-cdh5.12.0-src.tar.gz
接下来就进行步骤介绍
第一步,安装jdk
解压
tar -zxvf jdk-7u79-linux-x64.tar.gz
环境变量
vi /etc/profile
#JAVA_HOME
export JAVA_HOME=/home/hadoop/jdk1..0_79
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
测试是否安装成功
source /etc/profile
java -version
第二步,安装maven
>>提君博客原创 http://www.cnblogs.com/tijun/ <<
解压
tar -zxvf apache-maven-3.3.9-bin.tar.gz
更改名称
mv apache-maven-3.3. maven339
环境变量
vi /etc/profile
#MAVEN_HOME
export MAVEN_HOME=/home/hadoop/maven339
export PATH=$MAVEN_HOME/bin:$PATH
测试是否安装成功
source /etc/profile
mvn -version
第三步,根据多次踩坑,准备编译时需要的安装
yum install gcc
yum intall gcc-c++
yum install make
或者是直接运行
yum install g++ autoconf automake libtool cmake zlib1g-dev pkg-config libssl-dev
第四步安装protoc
解压编译,逐步执行
tar -zxvf protobuf-2.5..tar.gz
cd protobuf-2.5.
./configure --prefix=/home/hadoop/protobuf250
make
make install
环境变量
vi /etc/profile
#PROTOC_HOME
export PROTOC_HOME=/home/hadoop/protobuf250
export PATH=$PROTOC_HOME/bin:$PATH
测试
source /etc/profile
protoc --version
第四步,编译hadoop
tar -zxvf hadoop-2.6.-cdh5.12.0-src.tar.gz
mv hadoop-2.6.-cdh5.12.0 hadoop260-src
cd hadoop-2.6.-src
mvn clean package -Dmaven.javadoc.skip=true -Pdist,native -DskipTests -Dtar
经过一段时间的等待,出现 build success ,说明编译成功。
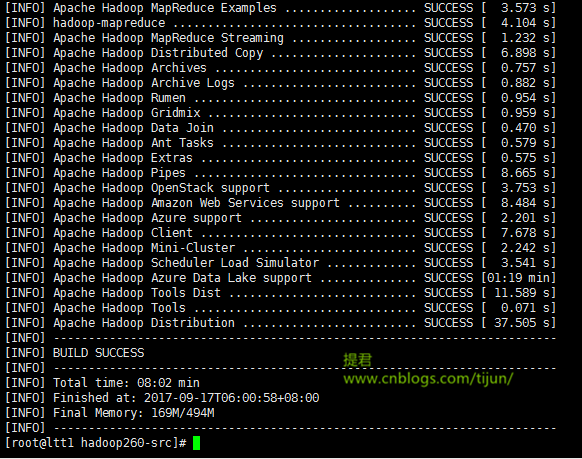
>>提君博客原创 http://www.cnblogs.com/tijun/ <<
编译源码生成的部分都在hadoop260-src/hadoop-dist/target/目录下
将编译后的native文件夹下的东西替换到原来的native目录
cp -r hadoop260-src/hadoop-dist/target/hadoop-2.6.-cdh5.12.0/lib/native/ /home/hadoop/hadoop260/lib/
同样,其他机器的文件同样替换
scp -r hadoop260-src/hadoop-dist/target/hadoop-2.6.-cdh5.12.0/lib/native/ hadoop@ltt2.bg.cn:/home/hadoop/hadoop260/lib/
..
..
..
注意:不同的linux环境,编译过程中会有不同,有可能会出一些编译过程的错误,我将再接下来的一篇文章中整理出来,供大家参考。
>>提君博客原创 http://www.cnblogs.com/tijun/ <<
hadoop-2.6.0源码编译的更多相关文章
- hadoop-1.2.0源码编译
以下为在CentOS-6.4下hadoop-1.2.0源码编译步骤. 1. 安装并且配置ant 下载ant,将ant目录下的bin文件夹加入到PATH变量中. 2. 安装git,安装autoconf, ...
- hadoop-2.6.0源码编译问题汇总
在上一篇文章中,介绍了hadoop-2.6.0源码编译的一般流程,因个人计算机环境的不同, 编译过程中难免会出现一些错误,下面是我编译过程中遇到的错误. 列举出来并附上我解决此错误的方法,希望对大家有 ...
- Spark1.0.0 源码编译和部署包生成
问题导读:1.如何对Spark1.0.0源码编译?2.如何生成Spark1.0的部署包?3.如何获取包资源? Spark1.0.0的源码编译和部署包生成,其本质只有两种:Maven和SBT,只不过针对 ...
- ambari 2.5.0源码编译安装
参考:https://www.ibm.com/developerworks/cn/opensource/os-cn-bigdata-ambari/index.html Ambari 是什么 Ambar ...
- 使用Maven将Hadoop2.2.0源码编译成Eclipse项目
编译环境: OS:RHEL 6.3 x64 Maven:3.2.1 Eclipse:Juno SR2 Linux x64 libprotoc:2.5.0 JDK:1.7.0_51 x64 步骤: 1. ...
- hadoop-2.0.0-mr1-cdh4.2.0源码编译总结
准备编译hadoop-2.0.0-mr1-cdh4.2.0的同学们要谨慎了.首先看一下这篇文章: Hadoop作业提交多种方案 http://www.blogjava.net/dragonHadoop ...
- 基于cdh5.10.x hadoop版本的apache源码编译安装spark
参考文档:http://spark.apache.org/docs/1.6.0/building-spark.html spark安装需要选择源码编译方式进行安装部署,cdh5.10.0提供默认的二进 ...
- Spark2.0.0源码编译
Hive默认使用MapReduce作为执行引擎,即Hive on mr,Hive还可以使用Tez和Spark作为其执行引擎,分别为Hive on Tez和Hive on Spark.由于MapRedu ...
- Ubantu16.04进行Android 8.0源码编译
参考这篇博客 经过测试,8.0源码下载及编译之后,占用100多G的硬盘空间,尽量给ubantu系统多留一些硬盘空间,如果后续需要在编译好的源码上进行开发,需要预留更多的控件,为了防止后续出现文件权限问 ...
- jmeter4.0 源码编译 二次开发
准备: 1.jmeter4.0源码 - apache-jmeter-4.0_src.zip 2.IDE Eclipse - Oxygen.3 Release (4.7.3) 3.JDK - 1.8.0 ...
随机推荐
- 使用Jetty运行Java Web项目(Maven)
目前流行的两款IDE: Eclipse和IntelliJ IDEA 2. IntelliJ IDEA
- eclipse的xml文件提示templates的模板.md
eclipse的xml文件提示templates的模板 <?xml version="1.0" encoding="UTF-8" standalone=& ...
- VMware Workstation 12 Pro 之安装林耐斯CentOS X64系统
VMware Workstation 12 Pro 之安装林耐斯CentOS X64系统... -------------- --------------------------- --------- ...
- php Yii2 报错unexpected '}'
报错unexpected '}'一般是缺少":"导致的
- ABP+AdminLTE+Bootstrap Table权限管理系统第二节--在ABP的基础做数据库脚本处理
返回总目录:ABP+AdminLTE+Bootstrap Table权限管理系统一期 第一点,上一篇文章中我们讲到codefirst中一些问题包括如图,codefirst在每次执行命令的时候会生成新的 ...
- js获取ip地址,操作系统,浏览器版本等信息,可兼容
这次呢,说一下使用js获取用户电脑的ip信息,刚开始只是想获取用户ip,后来就顺带着获取了操作系统和浏览器信息. 先说下获取用户ip地址,包括像ipv4,ipv6,掩码等内容,但是大部分都要根据浏览器 ...
- Idea下载后初始配置(windows环境下)
专业版的intellij可以免费试用30天.为了以后开发方便,咱们需要下载专业版进行破解. 一.破解 安装过程中有个界面如下,咱们选择License server填上http://idea.itebl ...
- 为什么a标签中使用img后,高度多了几个像素?
<li><a href="#"><img src="images/audio.jpg" alt="">& ...
- vue系列之动态路由【原创】
开题 最近用vue来构建了一个小项目,由于项目是以iframe的形式嵌套在别的项目中的,所以对于登录的验证就比较的麻烦,索性后端大佬们基于现在的问题提出了解决的方案,在看到他们的解决方案之前,我先画了 ...
- 高性能消息队列 CKafka 核心原理介绍(上)
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~ 作者:闫燕飞 1.背景 Ckafka是基础架构部开发的高性能.高可用消息中间件,其主要用于消息传输.网站活动追踪.运营监控.日志聚合.流式 ...